I don't understand why people think this is a great response. They know how their routing works, just say so. It can't be that hard to give a basic overview of it before they release a more comprehensive post.
As for the comment "Improving our documentation and website to accurately reflect our product". That is a very round about way of saying "our website indicates our service does things that it does not" which is a VERY bad thing. People are paying for this service based on what Heroku claims it does.
If the website has been inaccurate for years, that is false advertising and really a bigger problem than they are giving credit to.
If anything, I am more disappointed now that I have read this response, it has not appeased anything.
Documentation discrepancies happen. I've seen them with pretty much every platform I've worked on.
Just yesterday, I found a critical discrepancy between the ActionScript documentation and the actual behaviour of the ActionScript compiler, costing my team a day of work. (I tried to report the issue to Adobe, but the Adobe Bug Reporting System was down. Perhaps they need a Bug Reporting System for the Bug Reporting System.)
I think it's pretty heroic (yeah, pun) for Heroku to own their mistake, make the changes they've proposed, and accept the fire we've been pouring on them. They could have easily tried to weasel their way out of this, or attack the claims (Tesla/NYT comes to mind). Instead, they've accepted their own wrongdoing, and have pledged to make it right.
Who cares if the explanation comes today or tomorrow? Give them a few more hours to make sure their new round of technical claims are accurate, since such accuracy is exactly what's at issue.
In answer to "who cares if the explanation comes today or tomorrow", I care if the explanation comes today or tomorrow. I use Heroku and have hit scaling issues in the last few weeks very similar to this. More information on what is going on behind the scenes will help me immediately.
As for discrepancy in documentation, this is one of the most major parts of their infrastructure and directly relates to how well applications scale. To claim they have intelligent routing and then not having so, that is completely misleading and not just a minor documentation discrepancy. This isn't a tech document that got out of date, this is straight from their main "how it works" page... http://www.heroku.com/how/scale. Read the bit on routing.
Well, for marketing purposes, random doesn't sound as impressive as intelligent. It's a discrepancy but it does appear to be disclosed.
On the page you link to, it says: "Incoming web traffic is automatically routed to web dynos, with intelligent distribution of load instantly as you scale."
When you click on "Read more about routing..." it says: "Request distribution - The routing mesh uses a random selection algorithm for HTTP request load balancing across web processes." https://devcenter.heroku.com/articles/http-routing
I'm really confused where people are coming up with the idea that the word "intelligent" is somehow a synonym for "queueing". That doesn't make any sense to me.
The intelligent part of it is that it knows which servers and ports your application is running on as dynos come and go, and the routers is updated in near real time to reflect these changes. Since dynos move about frequently, and there are a great many of them starting and stopping per second, this requires much more intelligence than you probably think.
It may sound more impressive, but it's simply wrong. It's not even ambiguous.
If they had said some thing like "with advanced algorithmic distribution of load instantly as you scale", its wishy-washy enough that its technically correct and those that need to know exactly how it does it will need to go and look at the docs.
As it is, intelligent distribution tells those that need to know that the distribution of load is based on intelligence gathered from the system, so they may not look farther. And it's simply not true.
@bitcartel (not sure why I couldn't reply to your comment)... I believe from my discussions with Heroku that the "random selection algorithm" is also not true.
FYI, this is probably because you saw his comment at around 0-1 minutes. If you click on "link", you'll get the Reply form... or refresh after a minute or two and the "reply" link will be available.
The thing that makes me nervous is Heroku obviously knew about this issue, yet they chose to do nothing about it until they were called out on it by a high-visibility customer.
Developers are smart and capable people, but boy, what spoiled brats we are.
> It can't be that hard to give a basic overview of it before they release a more comprehensive post
Well, actually it is very hard to give a basic overview of anything complicated, without leaving your readership with their heads scratching. The person that wrote the blog post might not even understand the whole stack to be in the position of giving that overview and if he did, you'd probably be here bitching about factual errors.
> People are paying for this service based on what Heroku claims it does
Dude, this is a service used by developers and devops. You aren't meant to trust what they say. You are meant to measure and see for yourself if Heroku fulfils your needs or not. You know, how the author of the original blog post did it. And don't get me wrong, because I would agree with you, except for the fact that their website is not lying about what they provide. It's just out of date, sometimes describing details of the now deprecated Bamboo stack, a stack which also suffered through deprecation ... but hey, errors happen, we are human after all.
The response itself is an example for what other companies should do. They acknowledge sincerely that they have a problem, with a promise that they are going to fix it. How many other companies you've seen that do that? Amazon and Google sure as hell don't.
"Dude, this is a service used by developers and devops. You aren't meant to trust what they say." that is ridiculous. I use their service and I have trusted what they have said. They are the experts on their own service, why shouldn't I?
Also, the reason I chose Heroku is because DevOps is not my area of expertise, if I wanted to measure and analysis the inner workings I would have hosted elsewhere. Heroku is meant to alleviate that pain for me, I pay them excess over what I would pay elsewhere for that luxury.
As for the website not lying, yes it does. Go to "how it works" and click on routing. It's plain not true. Is it too much to ask that they update this in the last 3 years since the change?
I think the response is purely PR. Actually give something that will help their existing customers with this problem.
I agree, some people tend to think that Heroku is some kind of silver bullet that magically scales anything into the sky. But the underlying platform is nothing we haven not used before, and scaling linearly as the userbase grows is no easy task indeed. Give them some slack..
I think this is a good response, they apologized, took responsibility for what has happened and said they were committed to fixing it and what they would do next to go about fixing it. Also the message came directly from the top with the GM carrying the can regardless of if he was directly at blame or not.
I was expecting more of a 'sorry, your holding it wrong' approach.
One might charitably speculate that these are organizational challenges related to growing and being part of Salesforce.com. Things that were simple for a small, dynamic company can become shockingly complicated as the number of interests and priorities increases.
We might also consider the potential for a clash of cultures: Heroku has been relatively open about implementation details. Salesforce, on the other hand, has shown an extreme reluctance to share this kind of information.
I confess I can't help but wonder if the new willingness to make this kind of surreptitious change might in any way be connected to Byron Sebastian's sudden resignation last September. Is that nutty of me?
That's actually a pretty impressive response as far as it goes. Obviously there's no details at this point, but he absolutely takes responsibility, doesn't try to deflect or sugar coat it, and manages to find a tone that is both professional/serious, yet also down-to-earth and earnest. I guess the real impact will be how they go about "making it right" but in terms of a first response to the situation the tone is near perfect.
No this is not impressive. This is them fucking up and misleading customers for 3 years, enjoying a great reputation and now FINALLY getting called out for their BS. They're about to lose that great reputation that they've spent the past years building up, so of course they're in major crisis mode and doing everything they can to fix this.
Your response doesn't really seem to be directed at my comment. In your first sentence you're using "this" as if you're talking about the blog post which is what I praise in my comment(the tone of it), but then in your second sentence "this" refers to the routing issue raised by rapgenius, I wasn't commenting on that at all - I'm not a Heroku customer I was merely commenting on a GM's response to negative press.
Yeah, it's still not impressive. The only thing that I'd say is impressive in response to the situation would be:
"Hi, CEO of Heroku here.
Sorry. We've been misleading customers and only telling the truth when pressed-hard for years. We've created this financial model for all of our customers who have been overpaying on dynos because of our shitty routing and will be reimbursing them based on that.
We've also rolled out a second dyno-tier, called "dyno with non-shitty routing". It's 10x as expensive, but at least we're being honest about it. All current customers will enjoy our "dyno with non-shitty routing" for the price they're currently paying for the next 2 years. Enough time for them to migrate away, like any reasonable person would expect them to after this."
Of course they're going to post something, and of course they'll make it sound as good as possible. But it's baffling how so many people applaud such meaningless damage control drivel time after time.
Considering how many people/companies fail so spectacularly at it, why would it be baffling? I also think you underestimate the difficulty in making things "sound as good as possible" that one quality is the basis of the entire marketing and political industries - and a large component of many others. You're basically saying "It's obvious - just be perfect!" - it is not that easy.
All that being said - I'm really not "applauding" Heroku or their actions (which are what matter) I'm waiting to hear what they'll say. In the mean time I thought their messaging (which matters much less) was good.
No worries antoko. We're not really banging up on you, just pissed off at heroku :) Their wording was good, better than usual when companies fuck up. But they're deeply embedded in the startup community so good PR with us is expected, betraying our trust like this, however is not.
I would reserve judgement on this response until we learn the truth. Whether or not a response is adequate depends on what they could have said and should have said, which obviously depends on the facts. So let's just wait for more information until we assign praise or blame.
My comment is 3 sentence long and has 3 caveats. I am definitely reserving judgement, my praise was mostly about the tone, which I maintain is near perfect. I'm really curious if it was a case of him just writing it because a response hadn't been forthcoming and there needed to be one or if there was high-level meetings dissecting every word and phrase to make it just so - or where on that continuum it fell.
It's a good response in that they are taking responsibility, but it is pretty obvious that they are reluctant to say anything about a fix. In my mind, "it's hard" isn't a valid excuse in this case, especially when there are relatively straightforward solutions that will solve this at a practical level. For example, you could imagine a naive form of intelligent routing that would work simply by keeping a counter per dyno:
- request comes in and gets routed to the dyno with the lowest count. Inc the count.
- response goes out. Dec the counter.
Since they control the flow both in and out, this requires at most a sorted collection of counters and would solve the problem at a "practical" level. Is it possible to still end up with one request that backs up another one or two? Sure. Is it likely? No. While this isn't as ideal as true intelligent routing, I think it's likely the best solution in a scenario where they have incomplete information about what a random process on a dyno can reliably handle (which is the case on the cedar stack).
Alternatively, they could just add some configuration that allows you to set the request density and then you could bring intelligent routing back. The couple of milliseconds that lookup/comparison would take is far better than the scenario they're in now.
EDIT: I realized my comment could be read as though I'm suggesting this naive solution is "easy". At scale it certainly isn't, but I do believe it's possible and as this is their business, that's not a valid reason to do what they are.
What if their inbound routing is hundreds of machines, each of which may get a request for any of their thousands of apps, spread across tens of thousands of web dynos?
Do you have a distributed sufficiently-consistent counter strategy that won't itself become a source of latency or bottlenecks or miscounts under traffic surges?
I doubt they want every inbound request to require:
• query remote redis for lowest-connection-count dyno(s) (from among potentially hundreds): 1 network roundtrip
• increment count at remote redis for chosen dyno: 1 network roundtrip (maybe can be coalesced with above?)
• when connection ends, decrement count at remote redis for chosen dyno: 1 network roundtrip
That's 2-3 extra roundtrips each inbound request, and new potential failure modes and bottlenecks around the redis instance(s). And the redis instance(s) might need retuning as operations scale and more state is needed.
Random routing lets a single loosely-consistent (perhaps distributed) table of 'up' dynos, with no other counter state, drive an arbitrarily large plant of simple, low-state routers.
This has all been solved previously. In Google Appengine the scheduler is aware of, for each instance:
* the type of instance it is
* the amount of memory currently being used
* the amount of CPU currently being used
* the last request time handled by that instance
It also tracks the profile of your application, and applies a scheduling algorithm based on what it has learned. For eg. the url /import may take 170MB and 800ms to run, on average, so it would schedule it with an instance that has more resources available.
> Each instance has its own queue for incoming requests. App Engine monitors the number of requests waiting in each instance's queue. If App Engine detects that queues for an application are getting too long due to increased load, it automatically creates a new instance of the application to handle that load
This is what it looks like from a user point of view:
Heroku essentially need to build all of that. The way it is solved is that the network roundtrips to poll the instances run in parallel to the scheduler. You don't do:
* accept request
* poll scheduler
* poll instance/dyno
* serve request
* update scheduler
* update instance/dyno
This all happens asynchronously. At most your data is 10ms out of date. It would also use a very lightweight UDP based protocol and would broadcast (and not round-trip, since you send the data frequently enough with a checksum that a single failure doesn't really matter, at worst it delays a request or two).
A big problem is that the newer stack is not homogenous - the applications deployed on Dyno have much, much bigger variability than the old "Rails/Rack only" stack of Heroku. Meanwhile GAE stack is fully controlled by Google and reuses, afaik, their impressive "google scale" toolchest that goes from replacement naming systems, through monitoring, IPC, custom load balancing etc.
While F5 and similar offer nice hw for that, I'm not sure if their hw (or HAProxy's software) supports the architecture type used by Heroku (many heterogenous workers running wildly different applications with dynamic association of worker to machine etc.)
> It also tracks the profile of your application, and applies a scheduling algorithm based on what it has learned. For eg. the url /import may take 170MB and 800ms to run, on average, so it would schedule it with an instance that has more resources available.
That is very awesome technology, but it something like that available for non-google people?
Sounds nice, but I'm not sure it's the only way -- that Heroku 'essentially needs to build all of that'. It'd be interesting to see whose routing-to-instance is faster in the non-contended case, between Heroku and GAE. Do you know of any benchmarks?
Don't know of any benchmarks, but I have/had a number of projects on AppEngine and it is very good (but expensive). I would be looking to include Elastic Beanstalk in a comparison as well, as it is gaining popularity since it launched (it doesn't have the lockin and supports any environment).
My argument was built on the premise that random routing isn't acceptable given the potential slow downs it can cause (as pointed out in the Rap Genius post). If you believe otherwise, then there's no real argument for me to make :)
With that said, in your example, you could do one and two together and the response doesn't need to wait on the completion of #3. So it's one network roundtrip, which I would imagine is a tiny fraction of what they're having to do already. It is certainly another moving piece, but again my argument is that they have to have a solution and this doesn't seem infeasible.
As I've written elsewhere, I think just having a way for dynos to refuse load (by not accepting a connection, or returning an error or redirect), such that the load tries another dyno, will probably achieve most of the benefits of 'intelligent' routing. And, preserve the stateless scalability of the 'routing mesh'.
Really? Is that so hard? All you need is a table on the router that tells it the best information it can currently have about the number of requests processed on each dyno - without doing a roundtrip. This requires exactly one additional (one-way) package: A message from the dyno to the router, telling it that it has finished the current request.
Now, to avoid dead dynos (because the finished message might have been lost somewhere) the dyno can repeat the finished message ever 30 seconds or so (and the router ignores messages with counts <= 0).
A problem with this proposal is the assumption that there is one 'the router' with this info, updated for tens of thousands of dynos and millions of requests per second.
Well, if this is the case that would be a pretty deep architectural problem, I'd say, for a PaaS like Heroku.
I think it's pretty obvious that you need at least two layers of hierarchy for the routing here: One (or more) router forwarding requests to virtualized routers (per Heroku customer 'instance' or whatever that's called), which in turn provide the functionality I described in software. I'd probably use VMs running a specialized minimal linux distro for the per-instance-routers.
There are dozens of possible ways to implement this in a distributed, atomic or near-atomic, low-impact way.
* One way is to have a list in Redis, just pop a dyno off it (atomic so each dyno is popped off exactly once), send the request to that dyno, and as soon as it's done, push the dyno back on the queue. 1RTT incoming, and let the dyno push itself back on after it's finished.
* Another way is to use sorted lists in Redis, increment/decrement the score based on the connections you're sending it/returning from it. Get the first dyno in line which will have the lowest score. This is harder but maybe more flexible.
* Presumably they already have a system in place in the router, that caches the dyno's a request to a particular app can be sent too, which includes detecting when a dyno has gone dead. Just use that same system but instead of detecting when it has gone dead, detect if it has more than 1 request waiting for it.
etc...
But in the end, 2-3 extra roundtrips for each inbound request is peanuts, that's the least of the problems with these ideas. That would add maybe 10ms? to each request. It's not like the servers are on the other side of the world. They're in the same datacenter connected by high-throughput cabling.
It would seem at first glance that the extra round trip(s) would be less costly than the potencial bottleneck by a large margin. As mentioned several times in the other thread, increasing average latency to narrow your latency histogram is almost always the correct choice.
This is NoSQL at startups in a nutshell. A master-slave vertical scaling database won't work when we're the size of twitter, so we're going to settle for a shoddy user experience while we customize the hell out of it. Heroku gets away from this with Postgres and hopefully they can get away from this with their load balancing too.
You don't need a distributed sufficiently-consistent counter strategy. You can do just fine with a two layer routing mechanism where the first layer "sort" the incoming requests (e.g. by host header) so that the second layer is grouped by customer and can apply any number of simple alternatives like least-connections.
The naive approach would fail badly if they didn't have some way of supporting a healthcheck. A customizable url path (/healthcheck is often used) where the app would return 200 if things look good would work. Otherwise you may wind up with dyno that's quickly sending back 500's where not appropriate, and since it's handling lots of requests the router would keep giving it more.
I'm not sure that should be a concern at the routing layer or even necessarily a concern of heroku. It's not their job to ensure that your code isn't blowing up.
That being said, health checks are nice for other reasons and could be used outside of the routing layer (which you need to sail along as quickly as possible).
The problem with that is when your code is failing to run properly due to their hardware problem - now whose fault is it?
I don't know how big they are. 50k machines? Could be off by an order of magnitude either way but I'll go with that. Suppose that your servers have, let's be generous, a 5 year mean time between failure. That's 10k machines dying every year. About 27 per day. A bit over 1 per hour.
Machines don't necessarily die cleanly. They get flaky. Bits flip. Memory gets corrupted. Network interfaces claim to have sent data they didn't. Every kind of thing that can go wrong, will go wrong, regularly. And every one of them opens you up to following "impossible" code paths where the machine still looks pretty good, but your software did something that should not be possible, and is now in a state that makes no sense. Eventually you figure it out and pull the machine.
Yeah, it doesn't happen to an individual customer too often. But it is always happening to someone, somewhere. And if you use least connections routing, many of those failures will be much, much bigger deals than they would be otherwise. And every time it happens, it was Heroku's fault.
I'm having trouble finding information about this. It's disturbing how little attention seems to be given to load balancing relative to how important it is.
Yeah, it's interesting what sort of emergent properties come out of massively-scalable, massively-distributed systems. For example, when you write software in school or for single-machine deployment, you're taught to assume that when there's a bug it's your fault, a defect in your software. That's no longer the case when you get into massive (10K+ machine) clusters, where when your program fails, it might be your software, or it might be the hardware, or it might be a random event like a cosmic ray (seriously...in early Google history, there were several failed crawls that happened because cosmic rays caused random single-bit errors in the software).
And so all the defect-prevention approaches you learn for writing single-machine software - testing, assertions, invariants, static-typing, code reviews, linters, coding standards - need to be supplemented with architectural approaches. Retries, canaries, phased rollouts, supervisors, restarts, checksums, timeouts, distributed transactions, replicas, Paxos, quorums, recovery logic, etc. A typical C++ or Java programmer thinks of reliability in terms of "How many bugs are in my program?" The Erlang guys figured out a while ago that this is insufficient for reliability, because the hardware might (and will, in a sufficiently large system) fail, and so to build reliable systems you need at least two computers, and it's better to let errors kill the process and trigger a fallback than to try to never have errors.
Seems obvious that a naive solution wouldn't be as easy at large scale. You have to imagine that Heroku would have considered a whole lot of options before deciding on random distribution. Give them some credit at least.
What's worse is that they are not dealing with the behaviour of just one app. Random routing probably works best for a certain subset of their customers, maybe even the majority. If they switched to it it's unlikely to have happened without measuring a few different approaches and deciding this gave the best results overall. Unfortunately they have to deal with all of their customers apps, some of whom might have a huge variation in response time, which seems to trigger these issues - it's a complicated topic and one solution might not work for everyone.
To be clear, I'm not saying the naive solution I proposed would be "easy". Just suggesting that better solutions do exist and given that solving this very problem is one of their biggest value propositions, taking the easier way out isn't acceptable.
We used to do long polling/comet in our app on Heroku (we axed that feature for non-technical reasons), which meant that many requests were taking several minutes while the framework could still process more requests. In your system, how would you account for asynchronous web frameworks?
There is a perverse conflict with platform service providers - the worse your scheduler performs the more profitable your service will be.
You replace intelligent request scheduling with more hardware and instances, which you charge the user for.
How much investment is there in platform service providers towards developing better schedulers that would reduce the number of instances required to serve an application? That answer, in this case, is "not a lot"
The incentives between provider and user are not aligned, which is why I am more inclined to buy and manage at a layer lower with virtual machines.
Edit: AppEngine went through a similar issue. Here is an interesting response from an engineer on their team:
> There is a perverse conflict with platform service providers - the worse your scheduler performs the more profitable your service will be.
I think the practical significance of this kind of incentives is overrated. The company I work for does outsourcing work, paid by hour. Do they have incentives to make me produce less so that their customers pay for more hours? Theoretically. Do they act on it? Hell, no - there is competition and customer satisfaction matters.
In theory, the service provider could just switch to a better scheduler and raise their rates to compensate, since the TCO for a customer would go down correspondingly. Their costs go down, their profits go up, and customers still benefit.
Prices are usually determined more by competition than by technical factors. Unfortunately, there's a fair bit of lock-in to PaaS vendors, which is the real reason I'd be skeptical about building a business on them. The nice thing about the VM layer is there's a well-documented, public API between your code and the platform, so when your service provider raises their rates, you can switch to another one or operate your own hardware.
What you could do is price based on the value you provide.
You could price per request that you serve for your customers. Of course that just puts the perverse incentive on your customers, since now the service provider is bearing the cost of a nonoptimized application. The client doesn't care much about the weight of a single request, since the cost to him is the same (well except for latency).
So what you could do is define a 'typical request' by running a suite of open source web application on the service provider. This way you see how much hardware is required for a given throughput of 'typical requests'. Put a price tag on that. Now pricing also becomes much clearer for the customers: they know that if their application's requests are roughly of the same weight as open source web application X, Y and Z, and if they serve N requests per month, then their cost will be roughly N*(price of 1 typical request) per month.
Now the service provider has the incentive to optimize its hardware and services, because then it can run more typical requests at the same cost. The client has the incentive to optimize his application, because then he will use fewer typical request units, and hence pay less.
You could also determine the cost of a typical request by averaging over all of your clients' applications, instead of a suite of open source applications.
Wow, I feel like Heroku is really dropping the ball here. Like, they are acting punch drunk or something. Basically all this says is "we hear you and we are sorry". They could have posted that a day ago. This still says nothing about what is wrong and what they are doing to fix it.
Also, I'm not sure at what point this is, but at some point around say $3-5k a month, (100+ dynos) you really should rethink using Heroku. At that point and higher, you really ought to know about your infrastructure enough to optimize for scale. The "just add more dynos" approach is stupid because adding more web fronts is often the lazy/expensive approach. Add a few queues or some smarter caching and you'll need fewer web servers. Throw in something like Varnish where you can and you need even fewer servers. Point being, at some point scaling is no longer "free", it takes work and Heroku isn't magic.
At $3-5k a month Heroku may as well start offering a consultancy service rather than hosting. Wanting unlimited scaling without needing local talent is a reasonable thing to want, but its unrealistic to expect if from one single platform.
This is a horribly inadequate response. Prices for hardware have dropped 30% over the last 3 years and heroku is admitting their performance has degraded by many orders of magnitude. It's completely unacceptable to simply say, "yeah there's a problem, we'll give you some metrics to understand it better."
Sure, it's great they responded. The response should be "you're right, we are fixing it and issue credits" for revenue gained from fraudulent claims about the performance of their product and a credibility straining bait-and-switch.
Most people are going to come here and mention how they are not planning on fixing the problem.
Put it into context. Heroku made this change 3 years ago, and also has had no issues admitting the change to users. Their documentation has lagged far behind and I believe they will be more transparent in the future. This is an engineering decision they made a long time ago that happened to get a lot of PR in the past 24 hours. Until there is a business reason (losing customers), I don't see them "fixing" the problem.
The only thing worse than being talked about is not being talked about - OW
You are almost investing in heroku by using their stack and tool chain, it isn't easy for well established customers to just up and move. This is probably a PR win for them, rather than a loss. Truth be told, it will be how they handle this in the coming months that will make them win/lose customers.
If you are locked in the trunk with any cloud solution , then you are a bad programmer/syst admin/whatever taking bad decisions, period.
You should be able to move your project infrastructure quickly from a service to another ,if you cant to that, well too bad when your infrastructure fails...
How many customers are running on a stack that old that are at the scale being complained about? It is probably cheaper to tell them to upgrade if they want better performance, or if they dont want to/ can't then they unfortunately can't be officially supported.
What the hell? It's good he owned up...I guess. But the response basically sounds like "yeah, we've been charging the same prices over the last few years for increasingly degraded performance and we would have continued to do so, but someone finally caught on so I guess we have to now do something about this, right?"
I think this is really a fine response considering the pretty terrible way the original post was written and the community responded. The simulation was a bit of a stretch because the supposed number of servers you need to achieve "equivalent" performance is highly dependent on how slow your worst case performance is, and if your worst case isn't that bad the numbers look a lot better. Don't remember the precise math, but back when I studied random processes we studied this problem and the conclusion was that randomly routing requests is generally not that much worse than doing the intelligent thing, and doing the intelligent thing is nowhere near as trivial as Rapgenius and random HN posters would have you believe. Given generally well behaved requests he random solution should be maybe 2-3x worse but nothing near 50x worse.
And besides, I really don't see why someone who needs that many dynos is still on Heroku.
> The simulation was a bit of a stretch because the supposed number of servers you need to achieve "equivalent" performance is highly dependent on how slow your worst case performance is, and if your worst case isn't that bad the numbers look a lot better
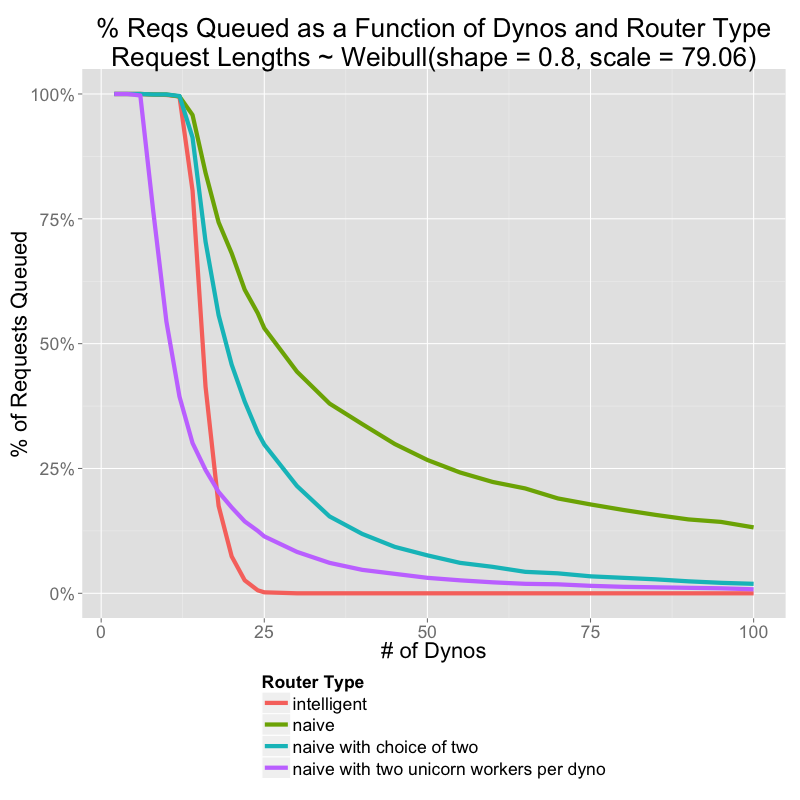
It's still pretty bad. Here's a graph of the relative performances of the different routing strategies when your response times are much better (50%: 50ms, 99%: 537ms, 99.9%: 898ms)
if I understand the chart correctly, using unicorn with two workers gets you pretty close to intelligent routing with no intelligence. I imagine adding up to three or four would make things even better... I don't know about puma/thin etc where you can perhaps crank it even further without too much memory tax(?)
To me this seems like the easiest approach for everybody concerned. Heroku can keep using random routing without adding complexity, and most users will not get affected if they are able to split the workload on the dyno-level.
On a slight tangent: On the rails app I'm working on I'm trying to religiously offload anything that might block or take too long to a resque task. It's not always feasible, but I think it's a good common-sense approach to try to avoid bottlenecks.
Generally, this is a fall out from queueing theory. I don't have access to my library right now, but any decent process simulation text will give you insight into the math of modeling this sort of thing.
What I find incredibly irritating about this blog response by Heroku is that it took a very visible post on Hackernews for them to act and reconsider their way of doing business.
They saw the potential loss in customers, and then acted. What this means is that they never had in mind to provide the best support and product they could for their customers before this news broke out.
Credit for owning the scope of the problem (allowing serious discrepancies for 3 years), which is sure to cost them trust from the community. But the skeptic in me reminds me that it's likely there was no way out of admitting it.
What disheartens me is that the documentation discrepancy caused real, extremely substantial aggregate monetary impact on customers, yet there is no mention of refunds. Perhaps that will come, but in my opinion, anything short of that is just damage control.
This is a time excessively demonstrate integrity, for them to go above and beyond. It's in their interest not to just paper over the whole thing.
It's so refreshing to see this kind of communication. I don't use Heroku, and don't know much about this specific issue, but they're responses to downtime and complaints have been so direct and BS-free that I'll definitely consider them when I need a PaaS.
I feel like there is an answer for this, but why are two companies in the "YC family" at odds so publicly? If RapGenius is "starting beef" like is done in the music industry, I find it odd that it would happen with someone on their own "label".
Perhaps this is ignorance on my behalf of how companies who have already been sold (Heroku) fit into the picture, but some explanation would be appreciated.
Well, let's put it like this. Those of us who know our programming shit and aren't afraid of a little math know exactly what has being going on here and that this answer is pretty much BS (what else is he supposed to say? basically he makes minimal concessions given the facts).
Working closely with our customers to develop long-term solutions
Of the five action items they listed, it seems that only the last of them is about actually solving the problem. I hope they are committed to it - better visibility of the problem can help, but I'd rather not have the problem in the first place.
The other ones are things that are obvious and immediate responses to the problem on description that don't take any deep analysis of alternatives.
Long-term fixes actually do require deep analysis of alternatives (and even what the appropriate parameters are for a solution that will deal with customers problems while maintaining Heroku's scalability), and aren't something you can do much more than make vague references to off the cuff.
The key question on that point will be follow-through.
That's not fair. What do you think "tools to understand and improve the performance of your apps" and "develop long-term solutions" from his bullets mean?
But, I'm surprised they didn't wait until the "in-depth technical review" was available to apologize. And the idea that they were informed of a problem "yesterday" doesn't quite match the impression RapGenius gave, that they'd been discussing this with Heroku support for a while.
"tools to understand and improve the performance of your apps" only commits them to updating their docs and tools to reflect how their system really works. It doesn't indicate any intention to fix the actual problem (the fact that requests can be routed to busy dynos), nor that they will make any kind of reimbursement to people who made business decisions based on incorrect docs.
"develop long-term solutions" doesn't really mean anything.
The first couple bullet points are about increasing transparency into how it works and what it is doing in an app. The last point is about fixing it.
| Working closely with our customers to develop long-term solutions
I cannot imagine this will be simple to fix. I don't know what Heroku's deployment is like^, but I figure it is very massive and complex and solving performance issues at that scale are not done overnight.
^That is the deployment and configuration of the Heroku platform, not how we as devs deploy to Heroku.
I don't think you can really conclude that from this statement, this section could be read to mean they plan on making changes:
"Working closely with our customers to develop long-term solutions"
At this point I imagine they're in damage control mode; I'm not surprised they'd be reluctant to make new promises before everyone's on the same page about the technical issues.
Actually he is, quite explicitly, saying that they will do a short-term description of the current behavior and its impact, provide tools to assist customers in understanding and managing the effect on their specific apps, and work on long-term fixes.
It requires statefulness and decisionmaking at the routing layer, and that's another thing that adds overhead and can go wrong at scale. (For example, there may be no one place with knowledge of all in-process requests. Traffic surges may lead to an arbitrary growth of state in the routing layer, rather than at the dynos.)
There are probably some simple techniques whereby dynos can themselves approximate the throughput of routing-to-idle, while Heroku's load-balancers continue to route randomly. For example, if a 'busy' dyno could shed a request, simply throwing it back to get another random assignment, most jam-ups could be alleviated until most dynos are busy. (And even then, the load could be spread more evenly, even in the case of some long requests and unlucky randomization.) Heroku may just need to coach their customers in that direction.
You are right. In the previous thread I pointed out one way of doing this with haproxy (there are many other tools that could do the job): "balance hdr(host)" on the first layer, and least connections balancing on the second layer. Or to know exactly which hosts are handled at the second layer (to minimize configuration size for each second layer server), create acl's for either specific hosts, or suitably short substrings, and your second layer servers can keep only the configuration for that subset.
You can also easily enough use "just" iptables at the second layer (supports weighted least connections and many others and you can plug in your own modules), which makes it very easy to do dynamic reconfiguration (to e.g. add/remove dynos), as well as traffic accounting (setting iptables to count bytes routed per rule is easy) and other fun stuff.
They could partition the routing, and maybe they do. But then (a) there's one extra hop mapping to the specialist routing group; and (b) it's still nice to have super-thin minimal-state routers, for example with just a list of up dynos updated once every few seconds, as opposed to live dyno load state updated thousands of times per second.
I too hope their full response givss more insight into their architecture... I have a couople of small projects at Herooku already and may use them. for several larger ones in the future.
I thought about mentioning this. Because 1 small hop is still less than random blowouts in response time.
You can even cheat by pushing the router IP into DNS. Hop eliminated.
> it's still nice to have super-thin minimal-state routers
I imagine Heroku's customers are not interested in what is nice for Heroku, they want Heroku to do the icky difficult stuff for them. That was the whole pitch.
Anyway, we're arguing about Star Wars vs Star Trek here because we have no earthly idea what they've tried.
Maybe, but they don't currently give each app its own IP, and might not want the complications of volatile IP reassignments, DNS TTLs, and so on. (Though, their current "CNAME-to-yourapp.herokuapp.com" recommendation would allow for this.)
...want Heroku to do the icky difficult stuff...
Yes, but to a point. Customers also want Heroku to provide a simple model that allows scaling as easy as twisting a knob to deploy more dynos, or move to a higher-resourced plan. Customers accept some limitations to fit that model.
Maybe Heroku has a good reason for thin, fast, stateless routing -- and that works well for most customers, perhaps with some app adjustments. Then, coaxing customers to fit that model, rather than rely on any sort of 'smart' routing that would be overkill for most, is the right path.
We'll know a lot more when they post their "in-depth technical review" Friday.
Because to be intelligent, you have to have the router talk to all the dynos to calculate load. Doing that in a performant way can get tricky, especially since people can hit a button and get 100 workers. The bigger the n, the more resources are required to track everything and the more things can go wrong.
It's not an intractable problem, but it's not trivial, affects only a small percentage of customers, and introduces complexity for everyone.
I feel pretty confident that there is a reasonable solution, and as someone that just spent the last 3 weeks building a custom buildpack and a new heroku app for an auto-scaling worker farm, I am happy to see such a quick, hopeful response.
I don't think this only affects a small percentage of customers. Maybe only a small percentage will notice.
This will affect any user with a high standard deviation in their application's response time.
Lets take an extreme case as an example: An application that has an average response time of 100ms, however 1% of the responses have a 3s response time.
They have relatively small load and they only have 2 web dynos running.
The admin thinks: We have this occasional slow response, but it should be fine. When one dyno is chewing on the 3s task, the other dyno will pick up the slack. Wrong.
With random routing, when one dyno is chewing on the slow task, 50% of the incoming requests are stacking up in that dyno's queue. The other dyno may be able to easily handle it's load, but half of your responses are still getting hit with 3s+ delays.
This is an extreme example, but this is not a rare issue. As the admin, unless you know about this issue, you will be perplexed by the seemingly random slow response times your users will be reporting. You won't see the problem in your logs, or your New Relic performance reports, but your customers will notice.
As others have pointed out, a major selling point of Heroku is it is supposed to "just work." These sorts of issues are supposed to be intelligently handled by their super-slick infrastructure. In my opinion, this is a serious issue. The fact that this has been biting users for 3 years now and Heroku is only willing to address the problem after they get major bad press is disheartening.
I have always been impressed by Heroku, especially how they constantly step up, admit their mistakes, and appear to be as transparent as possible about how they will fix their issues. This situation is seriously disappointing.
I am sure this is a very difficult problem to solve at their scale, but this is really what we as customers are paying them to solve.
Assuming you keep your prices roughly the same, the computation needed for assigning an available dyno becomes exponentially harder(costlier) as more dynos are added to the ecosystem. Thats why they changed the intelligent routing to random routing; to save cpu cycles.
The decision made by heroku was not an engineering decision, it was a business decision. While it is quite a bit frustrating, it is understandable and I don't think it will change. Since reverting a whole infrastructure to its original no-longer-profitable position is generally not a smart move.
A simple intelligent router may have 2^n performance, but I cannot imagine there are not other solutions that would bring performance closer to linear. I am not a queue theory expert, but I know they are out there. This is a well studied area of CS.
This is not only a problem for non-concurrent applications. It will become a problem as dyno usage increases for any application. The major factors will be the standard deviation of your response times and the number of responses you can handle per dyno. The issue just manifests first in applications that can only handle one request per dyno.
The purple line is a multi-threaded application.
No matter how concurrent your framework, it is still possible to overload the resources of a single dyno. When that happens, the router will continue to stack requests up in the queue.
What I see in that graph's purple line is that with the most basic concurrency you can have that is not nil, you get better times than some statistically optimal load-distributing solution (choice of two). I'd like to see similar graphs with 4, 8, or more workers to compare them.
It does seem to be what they are saying but, unfortunately, no :(
Random request routing is also present on Cedar [1]. The difference is that, on Cedar, you can easily run multi-threaded or even multi-process apps (the latter being harder due to a 512mb memory limit) which can mitigate the problem, but does not solve it. Modifying your app so all of your requests are handled extremely quickly also mitigates the problem, but does not solve it.
Seems to me the obvious solution is to do these things (multi-threaded app server, serve only/mostly short requests) and use at least a somewhat intelligent routing algorithm (perhaps 'least connections' would make sense).
I think I saw your comment and that they must have deleted it. Apparently their idea of keeping it civil means keeping out links to the blog post that it was a response to.
It seems strange for me to read in Heroku's response how forthcoming they are to accept blame and responsibility for the "a degradation in performance over the past 3 years".
Yet they state their action plan to "fix" this issue is to update their DOCUMENTATION and no mention of fixing the DEGRADATION issues itself.
> Yet they state their action plan to "fix" this issue is to update their DOCUMENTATION and no mention of fixing the DEGRADATION issues itself.
This is flat out untrue. The third bullet point in their action plan is to update their documentation, and the fifth is "Working closely with our customers to develop long-term solutions".
Updating the documentation to accurately reflect what the platform does is obviously critical to allow people to make decisions and manage applications on the platform as it is, so is an important and immediate part of the action plan.
Long-term fixes to the problem are also important, and are explicitly part of the action plan. Its clear that they haven't identified what those solutions are, but its not at all true that they haven't mentioned them as part of the action plan.
I'm very curious to see what the technical review turns up tomorrow.
This feels like something that would have been connected to the Salesforce acquisition 3 years ago, and then making the service less efficient in order to increase profits or revenue targets on paid accounts. Not to mention saving money on the free ones.
It would be a little bit like Tesla not only selling you the Model S, but also selling you the electricity you charge the vehicle with. At some point, they make the car less efficient, forcing you to charge more often, and then claiming they didn't document this very well. Frankly, there are only so many people who will be a capable enough electrical engineer (or in Heroku's case, a sysadmin) to catch the difference and measure it.
The apology should be, "we misled you, and betrayed your trust. Here's how we're planning on resolving that, and working to rebuild our relationship with our customers over the next year. [Insert specific, sweeping measures...]
Seems to me like a classy response to a real problem from Heroku.
We all need to remember that there are no magic bullets. The fact that Heroku can get a startup to, say, 5M uniques per day by dragging some sliders on a web panel and running up a bill on a corporate AMEX is pretty impressive.
At some point scaling a web business becomes a core competency and one needs to deal with it. I'm guessing by the time scaling an app on Heroku becomes an issue, if better understanding your scaling needs and handling them directly isn't going to save you a TON of money, your business model is probably broken.
So do the issues in the RapGenius post only affect those on the Bamboo stack? I'm procrastinating migrating to Cedar now but this could be a very good reason.
Also, I really love seeing a company take responsibility like this. I know the situations (and the stakes) are not comparable but this is a lot better than what Musk did when Tesla got a bad review. As a company just take the blame and say you can and will fix it, that's good enough for most people.
Honest question, why would Rapgenuis still be on Heroku if the y needed 100 dynos? Why not go directly to AWS at that scale? The cost savings would be pretty significant. Am I missing something?
Ops guys cost a lot more than just using Heroku, not to mention the cost of simply having the responsibility of servers (even if they are virtual). Never underestimate the value of just not having to think about something, especially when you're small group of people.
Before you undertake the more significant time and cost of migrating platforms, you see what you can wring out of what you've got. It is possible that after improving their performance enough on Heroku (or hell, even without improving it), they can not justify the up-front money and resources to migrate platforms.
Or, for all we know, they could already be in the process of migrating away from Heroku, but that doesn't happen overnight and doesn't help their performance in the meantime.
Wait, so those guys were on Bamboo, and complaining?
Fuck, that is so not cool.
We've been on cedar ever since it launched, and been running puma threads or unicorn workers.
The idea of one dyno per request is bullshit, and I wasn't sure if they were on cedar or not. A dyno is an allocated resource (512mb, not counting db, k/v store etc)
How ballsy of them to complain when they are doing it wrong.
Random routing is still wayyyyy worse than intelligent routing even if you're processing multiple requests simultaneously on a single dyno (see http://rapgenius.com/1504222)
Requests will still queue, but since time spent queuing at the dyno level doesn't appear in your logs or on New Relic, you'll never know it.
I think that's one of the real tragedies under all this, and compounding the tragedy is that it's going under-discussed: the performance monitoring is incomplete. If the dyno level queue time was apparent, this issue would have become obvious much sooner.
"Wait, so those guys were on Bamboo, and complaining? Fuck, that is so not cool."
That's a non-sequitur given that Heroku still supports it and didn't advocate migrating in their response.
It's fair to complain about a bug in Lion or in Windows 7 or in other products that are stil being supported. It's unfair to rail about a windows 95 bug, for example, but not something which is still being supported. And I'm surprised heroku didnt suggest Cedar in the response itself.
> We've been on cedar ever since it launched, and been running puma threads or unicorn workers. The idea of one dyno per request is bullshit, and I wasn't sure if they were on cedar or not. A dyno is an allocated resource (512mb, not counting db, k/v store etc)
It doesn't matter if you think one dyno per request is "bullshit" or not, Rails isn't multithreaded, so what do you propose they do? Using unicorn_rails on Cedar lets you fork off a few subprocesses to handle more requests on the dyno queue which gets you a constant factor bite at the dyno queue lengths, a few weeks or months of scale at best - it's not a real solution.
Heroku knows that Rails on Cedar is just as affected by their inability to route requests and they're only not copping to it in this blog post because they don't have a customer running Cedar complaining so loudly. Which is cowardly.
> How ballsy of them to complain when they are doing it wrong.
If you mean that deploying a rails app to Heroku is doing it wrong - a sentiment many are agreeing with right now - then yes, you're correct!
If you pay attention to queueing theory, you'd know that even a modest amount of parallelism per worker will let you run much closer to capacity while still having very few bad request pileups.
Another way to put that is that using Cedar lets you get acceptable end user performance with far fewer dynos.
> It doesn't matter if you think one dyno per request is "bullshit" or not, Rails isn't multithreaded
Sure it is. You just have to set `config.threadsafe!`, which right now is slated to be on by default in rails4.
But then you need a server stack that supports multi-threaded requests, such as puma which the parent comment mentioned using.
And then if you're using MRI, your multiple threads in a process still can't use more than one cpu at a time -- but this _probably_ doesn't matter in the scenario we're talking about, because a single heroku dyno isn't going to have access to more than one cpu at a time anyway, right?
How this all shakes out is indeed confusing. I am _not_ saying "If you just use puma and config.threadsafe!" all is well with their scheduler. I do not know one way or the other, it is hella confusing.
But it is incorrect to say "Rails isn't multithreaded, so what do you propose they do"
I think you're mistaken. New Bamboo apps can't be created, but apps that were created as Bamboo or migrated from Aspen to Bamboo before Bamboo was turned off are still running.
{kind=link}
{kind=link}
As for the comment "Improving our documentation and website to accurately reflect our product". That is a very round about way of saying "our website indicates our service does things that it does not" which is a VERY bad thing. People are paying for this service based on what Heroku claims it does.
If the website has been inaccurate for years, that is false advertising and really a bigger problem than they are giving credit to.
If anything, I am more disappointed now that I have read this response, it has not appeased anything.