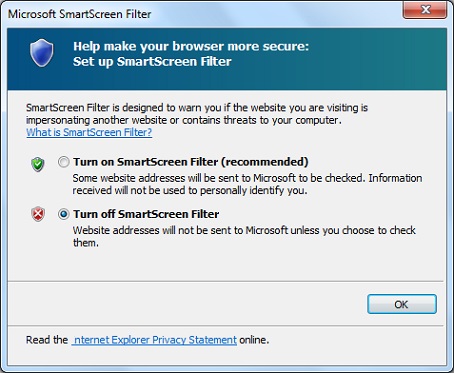
Eric Lawrence (PM on Edge, previously on Chrome, previously author of fiddler) showing screenshots of documentation that explains all that, and saying it's been documented this way for 14 years:
I am all for bashing bad privacy options, but from the linked tweet at least, this IS off by default. I can certainly see enterprise scenarios where this feature is very useful for security reasons. Did I miss some context?
Edit: oh, this is in addition to the Mirror stuff. Yea this should never be a thing.
I think you're making a big assumption that ordinary users care if Microsoft knows what URLs they visit--how many of them use blockers or another technology to opt out of e.g. Facebook tracking?
Ordinary users don't know what a URL even is. But they do assume every site they visit isn't being logged by Microsoft, much like they assume their car's manufacturer isn't recording the places they drive to using GPS.
"Users don't care" is such an intellectually dishonest argument when users aren't technical enough to understand the subject.
Maybe we should differentiate "users understand and don't care" against "users don't understand and don't care".
On one hand, a TOS usually describes privacy implications. On the other hand, there's no accountability that a user has understood or even read the TOS. Is it unreasonable to assume people will read the fine print?
> Is it unreasonable to assume people will read the fine print?
Unequivocally, yes. Even if someone hypothetically had enough time to read every TOS they've agreed to I would venture to guess the average user wouldn't be able to comprehend most of the terms[1] anyway. Disclosure documents are written by lawyers (corporate CYA) for lawyers (regulators, plaintiff's counsel, judges).
The law, however, disagrees with me entirely.
[1] Edit to clarify I mean "terms" as in the terms of the agreement
Delegating privacy rights feels like delegating monetary rights. As in, negotiating contracts for payments. This is coming from the perspective of a simple person trying to understand this complexity. Anytime I sign complex and impactful contracts, it's usually done in person with physical paper and a general understanding between both parties. An online agreement feels like scam artist's work, only after we've realized the value of our personal data. Maybe we're giving too much away at the notice of typed words? We're essentially giving away resource because we didn't realize the importance of it.
Most users probably don't assume anything, it doesn't even enter the lists of concerns or cares they have or ever would. It's not that they don't understand the subject, they simply do not give a crap one way or the other.
Random family in the US or elsewhere simply does not give a crap about things like this, no matter how much you want them to.
It's not ignorance, and the most intellectually dishonest arguments are really the argument here - "If people knew more about the subject or could know more, they'd care!".
If they knew as much as you did, they still wouldn't care.
I disagree in many ways. If someone knew exactly what type of information can be infered based on the information collected and all the many ways it can be used against them they would care.
Let's say they knew Microsoft can share this information with third parties which might affect their credit worthiness,employability and other very real and immediate aspects of their lives? Let us say the quality and availability of goods and services might change if MS or a third party used this information against them? What if MS can use ML to infer very personal and private aspects of their lives?
By your logic 4th amendment search and seizure restrictions don't matter either because most people assume the government can search them anyways.
There is a reason you have the right to legal representation when accused before the law, you don't understand the law well enough to answer questions and argue on your own. Tech isn't that different, people don't understand it well enough without relying on factual opinions of professionals in the field.
You are completely wrong, in my experience. I just recently had a chat with my 80 year old mum, and SHE was shocked and unhappy to find that google tracks her search history, let alone everything else.
I found myself in the unexpected position of trying to explain why (IMO) it was ok and not a big deal that they did that. I dont know whether I convinced her.
People assume they have privacy when they are alone. Its that simple.
IMO its not ok for any company to change that basic private-when-alone without a very simple, very clear explanation.
Sorry, but repeated studies on the issue basically find people simply don't care:
"Only 33.3% were concerned about their personal contact information like email address and phone number being shared with third parties, while 10.2% were worried about their friends and contacts being shared."
Can you find me one that says most did?
Because I can't.
Truthfully, if people cared half as much as hacker news thinks they do/should, it would already be a solved issue.
I dunno, maybe thats asking the wrong question? Im not sure why you are focused on contact information?
I can easily imagine people not caring about third parties knowing their phone number and email, thats already a lost battle. Everyone is used to giving those out.
Their search history though? their private chats with their friends? the websites they visit when they are alone? Their medical history?
The things they have bought themselves in the last 12 months? their favorite magazines?
Take some time and talk to people, I agree with the studies you found that said people dont care about their contact information, but ask people about other information.....search history is expected to be private, IME, by people who are not tech savvy. The same with their other private actions.
""93% of adults say that being in control of who can get information about them is important; 74% feel this is “very important,” while 19% say it is “somewhat important.”
90% say that controlling what information is collected about them is important—65% think it is “very important” and 25% say it is “somewhat important.”
Let’s take a step back here, and ask a few questions.
1) Is it possible to care about something that you don’t understand?
2) Is it possible to care about something whose existence you aren’t aware of?
I personally don’t think anyone can have a meaningful discussion about this issue without answering and agreeing on the answers to at least those two questions I ask above.
Agreed, the average user simply does not care about privacy to that degree. FaceApp is yet another example. On the bright side, most of the tools we need to "cover up" are available to us. You can't ask for more than freedom of choice, I suppose.
Telemetry is also documented to collect your browsing history at the Full level (which is the default, I think), but everyone here focuses on SmartScreen instead:
I'm guessing a single hash could be problematic for detections based on the domain for example. But this could be circumvented by sending hashed parts of the URL.
For example they could hash the domain, path and query separately.
Sending a hash of the URL or individual parts of the URL is problematic because the server can easily execute a dictionary attack to identify those parts in most cases.
The "Google Safe Browsing Update API" (used by Firefox, Chrome, Safari and others) solved this a long time ago. In that protocol, the browser hashes the URL, sends a short prefix of the hash to the server, and receives a list of hashes for the URLs that should be blocked. A huge number of valid URLs all hash to each prefix and the server does not know which one the user has visited. Also, the client caches the list of hash prefixes for which the block list is non-empty, to avoid unnecessary fetches of empty lists, which further improves privacy and reduces response time.
Also, the client doesn't send any kind of user ID token to the server.
Is there even a "pure" browser anymore? By that, I mean one which by default will do this: if I enter a URL in the address bar, it will fetch that page and its associated resources. If I click a link on a page, it will fetch its destination (this is obviously a simplified view, ignoring things like JS on the page etc.) No other network activity, no "recommendations", no other attempts to be "smart" or "helping" by doing anything beyond "pure" browsing.
I see a lot of this extra functionality being justified in the name of "security", but I don't think the gradual erosion of personal responsibility and agency that results is something which should continue.
I believe that Gnome's Epiphany (now confusingly called "Web") and KDE's Falkon are still "pure" browsers. Epiphany can integrate with a Firefox account, I think? But it's not on by default.
Epiphany only works on Linux but Falkon is available for Windows as well. Neither works on Macs but Macs have Safari which probably counts as "pure" if you aren't signed into iCloud. iCloud is pretty inoffensive even if you are.
Dillo has all the modern-web functionality of lynx, all the keyboard-driven capacity of Safari, and all the UI/UX appeal of an abandoned brutalist shopping mall.
1. Firefox downloads a list of partial hashes every 30 minutes from Google. It's only the first 32 bits of each hash. This can easily be turned off in about:preferences.
2. When you visit a website, Firefox checks the beginning of the URL against the partial hashes stored locally.
3. If the partial hash matches the beginning of the URL, Firefox downloads a list of all of the hashes beginning with the partial hash it matched.
4. Firefox checks the full hash of the URL against the new list of full hashes. If it matches, the site is blocked. If not, you continue on browsing.
When I first found out how it worked a while ago, I was pretty amazed. It goes to great lengths to not know what sites you're visiting.
[Disclaimer: I'm the TL of Safe Browsing in Chrome, and I worked directly with the author of the linked article for Firefox v4 support.]
FWIW, Google Chrome does the same because both Google Chrome and Firefox use the same Safe Browsing protocol v4.
The linked post was written a while ago when Firefox still used the protocol v2 but the post is still largely accurate.
Somewhat related, I recently realized that Microsoft Outlook on Android fetches _all mail_ on Microsoft servers, then sends it over to the app. If this is mentioned anywhere when setting up the account, I totally missed it.
This led me to look for a "pure" email client that would _only_ contact my server. Popular apps like Blue Mail and myMail did not work at all behind a firewall that blocked random internet access.
I am happy to report that K-9 mail (open source) was what I was looking for: it never tried to access anything other than my mail server.
I wholeheartedly recommend using NoRoot firewall (or similar) to see just how many random servers your (flashlight) apps talk to (and watch them fail miserably when you block that).
I think Waterfox meets your requirements. The only telemetry it sends is the version number so it can self-update (I haven't personally verified this).
No one should be surprised by this. Microsoft is Google, just with a price tag attached. (Google services are usually free of charge because they mine your data and target you with ads; Microsoft has discovered the concept of double-dipping and has now joined the party, while still charging for Windows.)
Getting you to sign into your computer with a Microsoft account is all about tracking and monitoring everything you do all of the time and selling a record of it to the highest bidder.
Doesn't Chrome send your entire browsing history to Google as well?
Edit: I thought this was a well know fact and if it isn't I might have been to harsh about Google and Chrome.
Edit 2: Thinking about it and searching a bit I conclude that IIRC Google at least used to have access to your browsing history as part of syncing it unencrypted.
Only through sync, which you can encrypt with a separate password to your Google account.
My sync is encrypted so I can't test this for you but I believe if it's not, you can check (and clear) your history here: https://myactivity.google.com/myactivity
Ah I was wrong about this!!!
SafeBrowse uses hashes.
Edit: never be afraid to admit your were wrong folks :) So it only gets a “potential list” of sites you visited. Wonder if the operators could aggregate the data enough to deanonymize things
> Doesn't Chrome send your entire browsing history to Google as well?
Most browsers/users do, essentially. When a person searches Google for example, results are links to Google that redirect to the target sites. Try it, mouse over a result, and look at the URL. Then a user clicks on one and finds a page that likely has doubleclick.net/adsense/analytics/fonts, which all feed back to Google. Or buttons/pixels/whatever for Facebook. Or both. Or both and 10 more organizations. Then since all mainstream browsers by default send referrer info, and since tracker code is so pervasive, and since browsers are easily fingerprintable, trackers follow you along as you click links going from page to page. Trackers are getting redundant high quality data. They're right there with you as you browse; they see what you see. Although some browsers are easier to configure for privacy, IMO the browser you use is less important than how you use it.
Multiple organizations have the potential to possess a near-complete view of your browsing history.
Everything you type into the address bar gets considered for possible completion, right? And part of that quite possibly entails sending it off to Google servers which take a stab at finding completions for it. Your claim seems plausible at least.
Also note there is a “roulette” feature in most address bars, where the browser starts loading and rendering the site before you ever hit submit. Very handy for sites wanting to pursue persistence
My activity[0] is Google's official way of telling you what it has collected about you from sources like Chrome. Things there will be used to personalize your experience.
If you are logged into Chrome your history is synchronized across platforms, tied to your Google account. Same as with Firefox Sync. Not sure about behavior when not logged in, or when incognito.
It is not so easy to do this MITM trick with Chrome, it has Google certs pinned down.
"For the transparent proxy to work, it needs .google.com to be added to the URL whitelist to allow all traffic to .google.com. This configuration is not supported because of Chrome security features that are in place, and we recommend that you avoid the use of transparent proxies." https://support.google.com/chrome/a/answer/3504942?hl=en
If you sign in it syncs history across devices, so I assume it does. Although it would technically be possible that they encrypt it using a key Google doesn't have, I wouldn't assume they implemented that.
So stop using a browser from a company that has a source of income besides selling your info to install a browser from a company to which you are the product. Ironic, no?
Not saying MS is not doing anything wrong, but the lesser evil I think.
You shouldn't need Edge, Chrome, or Firefox to install each other. If you know the URL of the file you want to download, you could use curl or wget. (Of course, that won't work if you do not know the URL. But hopefully someone will tell you if you are unable to find it on your own computer.)
As of some recent Windows 10 build (edit: 1803 or insider 17063+), curl.exe (need to specify full executable name not just "curl", which is aliased to Invoke-WebRequest by default) is shipped by default as well. I believe it came around the same time as OpenSSH. You'll also find a tar.exe binary.
No; to get it without going through a browser you'd have to install Windows Subsystem for Linux as an optional feature, then download a Linux distro from the Microsoft Store - arguable whether that doesn't involve a browser, really.
Well, by default, Chrome sends whatever you're typing in the URL bar to Google for auto-completion. No need to catch Google in such situation, it's a feature of Chrome.
The browser sends a prefix (first few bytes) of the hash [1], and gets back a list of full hashes to compare locally. This is called k-anonymity, and it's good enough for even services like Have I Been Pwned to use it for password lookups [2]
Other browsers use a _truncated_ hash. Easy enough to match to a known list of bad sites, but exceptionally difficult to reverse engineer a list of sites the user has visited.
Those hashes have to be essentially unique to prevent blocking good sites erroneous;y, and as such are easily associated to actual sites when you’re the scale of MS or Google.
Here's what all the browsers do (Firefox, Google and Safari all use Google's Safe Browsing service).
1. The truncated hash is checked against local database.
2. If there's a hit, send the truncated hash to Google, and receive a list of full hashes for the truncated hashes.
3. Check if the full hash is in that list. If so, warn.
I'm not certain that the hash is truncated enough, but the general idea is a pretty straightforward trade-off between the amount of information Google needs and the amount of information your computer needs.
Not if there's an other layer of verification locally. Then you can allow a few false positives with the hash on the remote and they'll get discarded when the full hash is compared locally. That being said 32bits of information seems like quite a lot and can probably used to match the original URL fairly accurately.
You also need to consider the greater context. Suppose my history shows I sent a hash that could be one of 100 different known URLs. One of them is about model airplanes, but there is no way to know I picked that one. Chance I like model airplanes? All else being equal.. call it 1%
But what if over the next hour I continue to send hashes with random subject matter sets that include model airplanes each time. Suppose the intersection of the possible subject matters shrinks with each additional hash, quite possibly contains only model airplanes.
I visited 100 URLs in one hour. For each URL there are 100 others with the same hash but independent topics. Lets say there are 10,000 known topics, but every hash I sent has model airplanes associated with it. Now what are the chances I like model planes?
It seems clear to me that this scheme, with logging, reveals a lot in theory. But maybe solving this problem in practice would cost more that the data is worth. For now.
You skipped a factor, in Safe Browsing Update API (the mode actual web browsers like Firefox use) that step where you send a 4 byte prefix only happens when the prefix already matched a local hotlist.
So if you visit 100 URLs in an hour, and using the local hotlist allows your browser to discard all but 1 of those URLs as definitely not bad, that's only one URL prefix checked against Google, not 100 so there's no triangulation.
And the actual number isn't 1-in-100, that's why they picked 4 byte prefixes. I haven't actually checked, but by eyeball from playing with this data for work I would guess 1-in-a-million.
So, you visit 100 URLs about model planes, one of them happens to be a 1-in-a-million match to a possible badware site, your browser sends the 4-byte hash prefix to Google, it gives back the 4-byte prefix of the badware site it was worried about which is different, your browser goes "Phew, good" and nothing happens.
There's just not really an opportunity for tracking here.
Ugh, editing goof - that last bit of my explanation is wrong, Google sends the whole SHA256 hash of the bad site's URL and your browser compares -that- to the full hash it calculates for the model plane site. The four byte prefix will be the same of course, if it wasn't we wouldn't get this far.
There’s a super-fast, no bullshit, mobile-friendly, absolutely wonderful version of twitter you can get if you disable javascript...
(i’ve only used it through tor tho)
I'm not sure about "super-fast" since, every time I visit twitter w/o JavaScript, I'm forced to click thru the message:
We've detected that JavaScript is disabled in your browser. Would you like to proceed to legacy Twitter?
And this annoyance persists. Click on a twitter link within the twitter website and you get the message again. And again. It's definitely a dark pattern meant to annoy you into enabling JavaScript.
no, it's likely you're either on a mobile device or your cookies are set so that it's redirecting you to it. the non-mobile version works fine and is clearly different.
There is a first step which uses bloom filters, and if the filter gives a result, it is hashed and the hash is sent to the google service to double-check.
That being said, a four byte / 32 bit hash is enough to almost uniquely identify a website. There number of 32 bit numbers and websites is roughly the same order of magnitude. It's a problem without a good solution because if you create many collisions then you also generate plenty of sites falsely reported as phishing and which admin would want that to happen on their site.
If you avoid creation of collisions, you have this identifyability problem.
There is this CRLite proposal [1] using layered bloom filters to stop reliance on web services. Maybe it can be adopted for phishing sites, as well.
The safe browsing protocol computes (up to) 30 hashes of each URL, most of which include path components of the URL. So the space of URLs subject to hashing is far greater than 2^32, and the hash prefix alone tells you practically nothing.
Furthermore the protocol does not declare as URL as blocked just because the 32-bit hash prefix matches. If the prefix matches, the browser downloads the list of full hashes and checks the full hash against that list locally.
It's frustrating to see people jumping to erroneous conclusions about how Safe Browsing works when the spec is publicly available and quite clear. https://developers.google.com/safe-browsing/v4/
Out of the box bloom filters let you set only false not-in-set probability to zero. The probability for false in-set probability varies, though it can be low if you choose parameters wisely.
What CRLite does achieves zero for both false positives BUT at quite a price. You need to know absolutely all the things that might ever be in the set before you start.
For CRLite they can almost wave that away by declaring that the set of things that might ever be in the CRL set is the set of logged certificates, so we can get that set from the log servers within 24 hours (the "Maximum Merge Delay" in public certificate transparency logs).
But you can't do that for URLs. The set of possible future phishing URLs has infinite size.
>That being said, a four byte / 32 bit hash is enough to almost uniquely identify a website. There number of 32 bit numbers and websites is roughly the same order of magnitude.
The utility of the hash for a user and some potential attacker is the same. Yes, passing 8 fewer bits means that they have 256 times more possible sites you might have visited. But it also means that you get 256 times as many false positives of websites being labeled as phising. This is what GP meant by it being problem without a good solution.
One possible option is to do what haveibeenpwned does, where you give fewer bits and then locally check. That would be a good improvement to the system's privacy, but you probably want to avoid downloading the hashes of every malicious website that starts with the given 3 bytes (I'd assume the list is quite large) for every page load.
My browser computes [among other things] SHA256('fakebank.example') and then it snips off the first four bytes and compares that to a large dataset it got from Google. It fetches updates to this dataset every few hours. Sure enough the four byte prefix is present in the dataset.
So, we've got an alarm - it calls Google, but it doesn't tell them it's thinking about https://fakebank.example/security/login at all, it just tells them the 4 byte prefix. Google responds with a list of full SHA256 hashes beginning with that prefix that it considers _right now_ to be phishing. The list might be empty (maybe fakebank.example was actually a Greek yoghurt company subject to a PHP 4.x attack, and they upgraded PHP and removed the phishing site so now it's fine) but if it has the entire SHA256 hash we calculated then I get an alert telling me that my browser thinks this is a phishing site and I might want to not visit.
Why can’t the browser request the mapping of the hash to the malicious website that is known and then check if that mapping is indeed what it is seeing?
Can you save text files that you're looking at in Edge yet? Like if you navigate to a URL that goes https://foo.com/blah.txt can you hit Ctrl+S or right-click on the text page and save the document? The last time I looked at Edge the answer was no.
I guess that most people who know that you can save web pages to your disk (and make use of that feature) also know that you can disable telemetry (and make use of that feature).
Not to defend Microsoft, but SIDs are non unique. I think theyre only guaranteed to be unique per AD forest with the addition of the RID subauthority. Lots of domains are domain.local or other such commonalities and so may have duplicates. Microsoft would know this, so the intent does not appear surveillance or data collection.
The 3 long numbers in the middle are called "Domain or local computer identifier". Further down it says that each of those numbers are encoded as a 32 bit integer. Assuming they're randomly generated, that's 96 bits of entropy, which is more than enough to uniquely identify every computer on the planet[1].
[1] There might be a few duplicates due to the birthday paradox.
This is one of the reasons I don't use chrome. Google tracks which search links I click on any browser but I assume they simply track everything else done with Chrome.
Every time I see people on HN campaigning for Microsoft as some kind of reformed tech company that has seen the errors of its past and turned into a force for good, something like this comes up.
Same old Microsoft. Second verse same as the first.
Yes. I have absolutely no problem with the way that works. It’s clearly spelled out how it works and how it’s configured. Seems few who actually use these tools have problems with this...
Code and .NET Core both send the same hash of the MAC (which at 6 bytes is hardly worth hashing) in their telemetry in order to correlate across applications.
Not sure if it's bought or organic, but no other company gets the response Microsoft gets. The smallest triviality get praised, the biggest flaws get rationalized away. Like, people here were going wild when they added UNIX line-ending support to notepad.
They employ a lot of people directly, and a lot of people are employed in their ecosystem. I'd deny that this is exclusively for MS, though. Every large company has an army of employees that come in to explain how things actually are. On HN, this happens just as often for every medium-sized company; the only companies who absolutely get bulldozed when they do something worth getting bulldozed for are tiny, because their defenses just get shouted down by the employees of competitors.
This is "the same verse" as what? Bundling IE with Windows? The same as making proprietary technologies on open ones? The same as strongarming Gary Kildall? No, no it isn't "the same". Anti M$ comment is just whiny.
SmartScreen for Windows Defender will send filenames, hashes and download locations to Microsoft as well.
This is less bad than "like" buttons tracking you around the web in an undocumented and not-optional way with no user benefit.
Is this so different to Google quietly signing you into Chrome when you sign into a Google website, and Chrome sync'ing your browser history to Google by default and sending URLs of pages you visit from the Omnibox?[1] Or "Sends URLs of some pages that you visit to Google, when your security is at risk" from the Chrome options? To Facebook scraping call records and SMS texts from Android devices for years? [2] Ubuntu with opt-out system data gathering in 18.04, and wants to gather data to track "relative popularity of apps"[3], or Steam gathering data about what games you play[4]. Would you believe, Wonderful helpful Google has every email you send or receive through a GMail account or to one, but Evil Microsoft has every email you send through/to an Office 365 account. Wonderful Google and Amazon could access any VM on their clouds, so could evil Microsoft on Azure - except Microsoft built Shielded VMs into Hyper-V to protect the VM from compromised hosts, and to keep secrets in the VM which host administrators cannot access. [5]
Tech companies spy on people for money, isn't as anti Microsoft an idea though, is it?
It's so weird to come in with a defense of "this is no worse than this long list of horrible things other companies have done, and other horrible things this company has done before!"
I completely agree with you, this is no worse than many of those things.
That's not what I'm defending. I'm attacking "same old Microsoft" as a content-free, /inaccurate/, /ill targetted/ and /boring/ comment.
"Downvoters should explain" well that "defense" is my explanation. It's not the "same old" behaviour, it's different, what it is the same as .. is other current day, much loved technology companies.
Except for specific ways it's better in Microsoft's favour - this is more explicit and easier to opt-out of than Google Analytics, Doubleclick (owned by Google) or Google+ social media tracking beacons, for one, or "talking to someone who uses gmail" which is super frustrating, for another.
I would never assume Google doesn't know every site I visit with Chrome. Let's scrutinize all of them rather than hold them to different standards based on our personal narrative.
{kind=link}
{kind=link}
https://twitter.com/ericlaw/status/1152933704198758401