If you aren't compute bound, most workloads are dictated by the speed of main memory. And most business workloads spend their time waiting. Intel has historically focused on single core performance, this is what they are _really_ good at while this graviton part has decided to go wide and focus on many core.
The memory controller on the ARM part must be excellent given that the Intel machine had 2x sockets.
I don't think a core to core comparison or core to hyperthreaded core makes much sense. There are so many other unknowns, they only appear to be similar metrics. $/work_unit is the benchmark I would focus on in case like object storage.
My money would be on greater memory bandwidth and probably better use of that bandwidth.
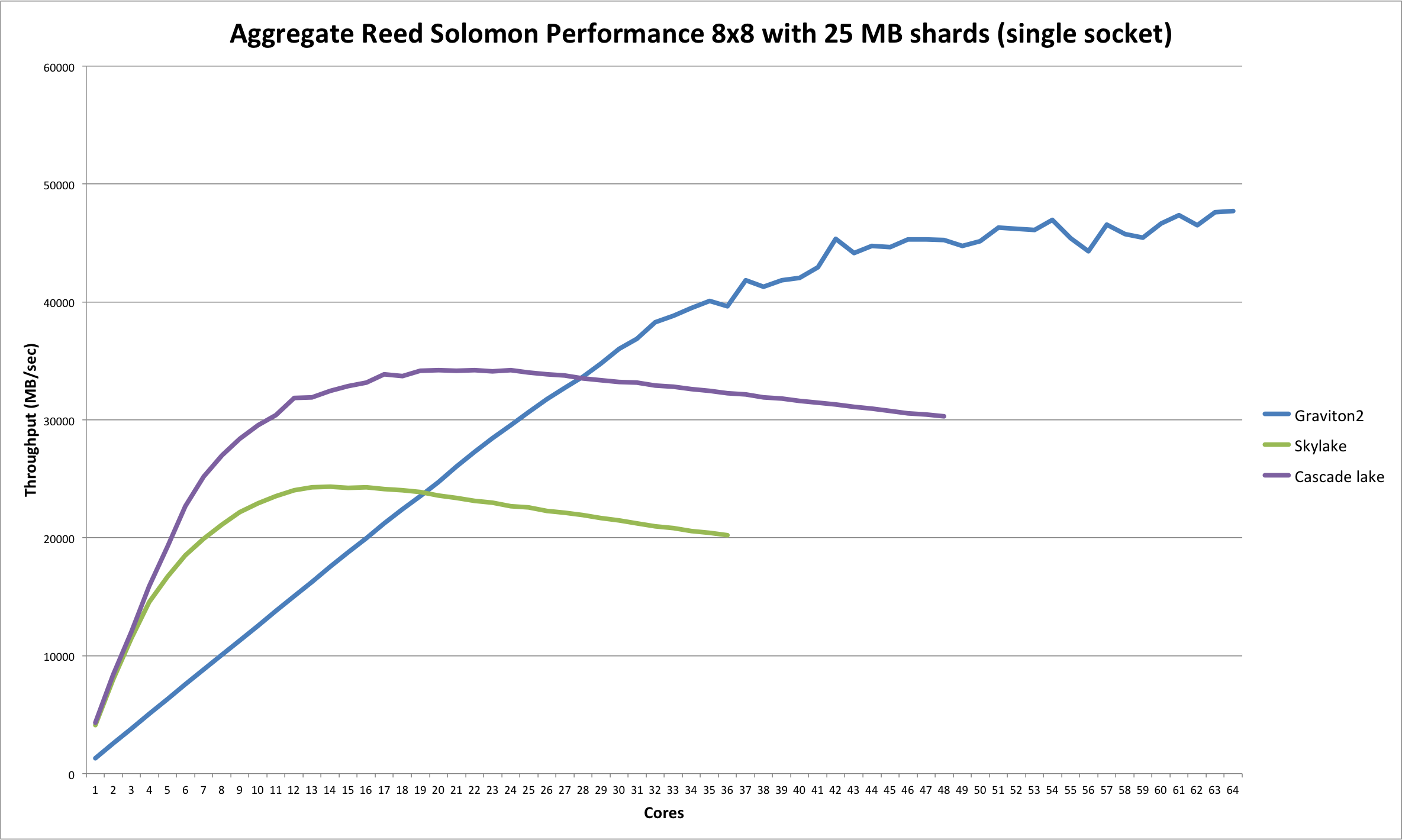
If you look at the big graph later on in the article, even for similar _physical_ core counts the Graviton does better than the Skylake - this implies there's another bottleneck.
It's worth pointing out as well that ARM's weaker memory model gives it many more opportunities for aggressive optimisations that can make better use of the available bandwidth.
> even for similar _physical_ core counts the Graviton does better than the Skylake - this implies there's another bottleneck.
It doesn't, though, not until Skylake has already hit a bottleneck & graviton2 can eventually "catch up".
Skylake caps out at around 12 cores, at which point performance goes flat & even regresses. At 12 cores, though, skylake has a huge lead over a 12 core Graviton2.
Similarly, Cascade Lake caps out at around 18 cores. But again at 18 cores the gap between Cascade Lake & Graviton2 is huge.
The bottleneck in play here is most likely memory bandwidth. The Graviton2 chip has 8-channel DDR4-3200 memory for a theoretical bandwidth of 204GB/s. That's going to be far more than any single CPU Xeon currently on the market. By comparison the Skylake would be 6 channel DDR4-2666 and Cascade Lake 6 channel DDR4-2933.
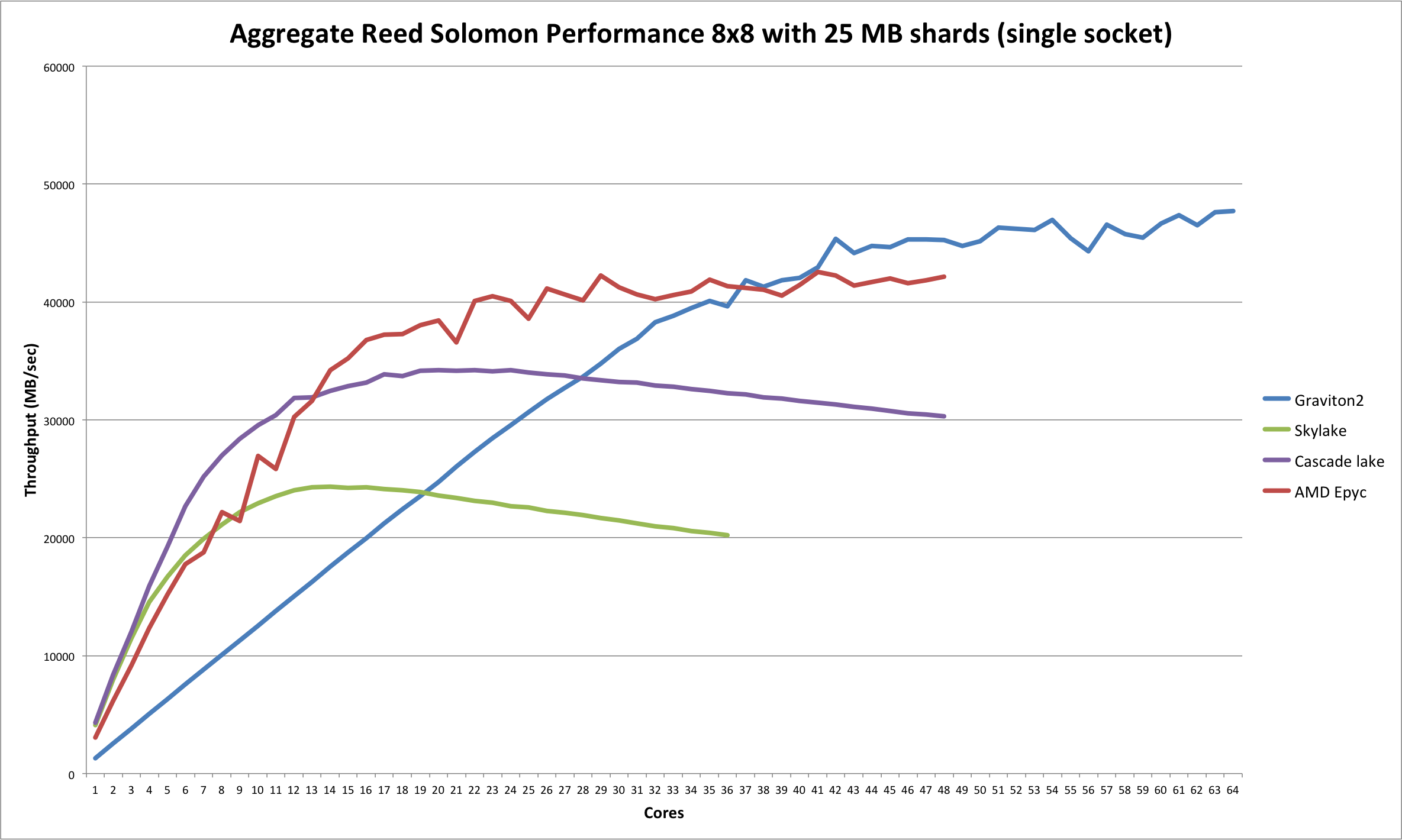
So for this particular test the interesting comparison would be against Epyc Rome, which is also 8 channel DDR4-3200 and is up to 64 physical cores.
The cross socket NUMA bandwidth is like a tiny straw. If the OS or application is failing to pin the memory, cpu and IO together on the correct numa node your going to have a major scalability problem.
So, two things can really throw this off, having a Physical->VM topology mismatch, or using a language that is garbage collected and won't allow the programmer to control memory/node placement.
I've literally gotten 10x perf improvements by fixing these kinds of problems in the past.
Combined with comparing cores to threads and the results are somewhat predictable. In this way, the simpler gravaton topology is really going to shine for applications that don't scale well. That is until intel builds an actual high core count single socket machine.
That really looks like it's just sorting by memory bandwidth. Particularly with Cascade Lake's results vs. Skylake at the ~10 core number, since there's not really any other major difference between those two.
Being that memory bandwidth constrained, and then not being NUMA aware, is also quite likely why the dual-socket results are a disaster.
The unidirectional bandwidth across a two socket system is roughly equal to a single DDR channel. Which is why you see postings on the intel forums about people complaining about their perf falling off a cliff if the hardware decides to flag the directory as requiring cross socket snoop (or whatever its actually doing). So even if you have done a reasonable job keeping your thread+data locally, doing a remote reference, or accidentally running the thread for a short while on the wrong socket can permanently lower the performance. See https://software.intel.com/en-us/forums/software-tuning-perf... for an example about a contented cache line.
Thankfully the latest products are mostly 10.4GT (gold and above) as it appears intel isn't doing as much product segmentation based on UPI link speeds anymore (silver/bronze are still slower though).
> The unidirectional bandwidth across a two socket system is roughly equal to a single DDR channel
Depends on the implementation. Epyc Rome's 2P socket design is 64 PCI-E 4.0 lanes between the two CPUs. That's 128 GB/s bandwidth, which is roughly equivalent to 6-channel DDR4 2666.
Graviton 2 uses off the shelf Neoverse N1 cores designed by ARM.
> Amazon is an Arm architecture licensee.
Do you have a source for this, or is this conjecture? As far as I can tell, neither Amazon nor ARM have announced that Amazon has an architecture license.
The best part of this new era of ARM based servers is competition.
In the early 90's Intel slowly and steady marched into the datacenter arena up to a point that become the dominant player.
Intel was brilliant and created a distribution strategy that allowed multiple vendors use the x86 chip each with different server solutions. IMO This multitude of server offers based in the same architecture (x86) is what killed all other CPUs.. Just to remember a few players: Equipment Corporation (DEC), Sun, HPe, and even IBM now well near defunct.
It's very exciting to see ARM rising to datacenter arena. IMO ARM is a superior CPU, and now they have, just like Intel, new distributors creating multiple offers based on a single well know platform.
These benchmarks seem primarily to demonstrate that for “straight line” computationally intensive algorithms, hyperthreading doesn’t buy you very much—in my experience something like 20% additional throughput. In those scenarios, all else being equal, 64 cores worth of compute will have a big advantage over 36.
That's true, but it's also true that "straight line" algorithms that don't involve branching pipeline stalls tend to be straightforwardly parallelizable, in which case a scalar CPU isn't the right hardware to be using in the first place and you want to be comparing vector FPU and/or GPU implementations.
Or to put it more strongly: The multi-core comparison makes no sense. If the goal is to compare performance per core, as a way to evaluate CPU efficiency in the abstract, then they should be comparing equal numbers of physical cores, not logical cores.
Such a comparison does miss some practical benefits of the ARM instances. The ARM instances seemingly have more physical cores available on a single AWS instance – but “performance on a single instance” would be a different comparison, one where the Intel instances shouldn’t be limited to 64 threads. And the ARM instances may have a cost advantage (I haven’t checked), but performance for equal cost would again be a different comparison.
I agree that the article should at least have mentioned the cost, to allow for comparison on a more meaningful basis than perf per core. Though in the end that makes things look worse for Intel. The c5.18xlarge (Xeon) is $3.06/hour, m6g.16xlarge (ARM) is $2.464/hour.
The dual vs single socket section really shows how much of a performance landmine NUMA is. You really need to properly pin your workloads, but that's a huge pain in the ass that often never happens during tuning.
Completely. A lot of people I have worked with have no idea what NUMA even is whole having NUMA machines. It’s just a magic box. Zero understanding of the hardware architecture at all.
Comparing the systems with Two sockets vs One socket, Hyperthreading vs None. I don't think we can trust the result that much.
But just for general opinion. Intel CPU has strong memory guarantee between cores compared to the ARM. If the implementation is really good at parallel execution so it doesn't require a lot of data sharing between threads, ARM architecture potentially be better than Intel, if its implementation were good.
Graviton 2 (single socket, no SMT) comes out ahead of Skylake (dual socket, SMT enabled) in the multicore scenario. Do you think that result would change if Graviton 2 was instead compared against single socket, SMT disabled Skylake?
I agree. When comparing graviton with an intel CPU, you're going to have an intel premium.
The jaggedness of the cascade-lake graph concerns me. The article provides no explanation for it. Is it another process interfering with some runs and how many test runs did they do to get these charts?
The goal of the S3 team at Amazon, or somebody like Backblaze is to make hard drives 100% of costs. That is, they want to reduce the cost of compute, datacenters, racks etc. to approximately zero.
If CPUs are dominating your costs or performance, then you're doing S3 Compatible Object Storage wrong IMO.
I don't think Minio is trying to compete directly against S3, especially when they run on EC2 (a service running on AWS will never be cheaper than AWS itself). It sounds like they're targeting a higher-performance S3-compatible niche.
They announced it is their intention to have all their services and SaaS running on top of Graviton instances. i.e They are eating their own dog food. They said this will be a long time, multi year method. ( And whenever Amazon is saying this that means they are doing as fast as possible to optimise for cost )
The S3 protocol needs MD5 hashes, which these benchmarks don't cover. A Xeon core can do that with a couple of hundred MB/s. As it's a continuous hash of the whole object, this limits S3 performance.
I guess AWS does not care that much about single stream S3 performance but will optimize for costs.
I don't think it uses md5 any more, the newer protocol versions support sha256 hashes and thats only if the user checks, may not be what is used internally.
For the object upload, AWSv4 request signature uses SHA256 on the payload/object, but I don't know if S3 also computes & compares the digest or just uses the x-amz-content-sha256 header value.
Do you happen to know if AWSv4 with S3 also computes & compares the SHA256 of the payload/object or does it just use the specified x-amz-content-sha256 header's value?
Now try this with hyperthreading disabled since it's disabled on the arm machine.
If you have a 24 core machine and you run the same task on 48 threads, you will sometimes see some performance drop compared to running it on 24 threads.
HT doesn't change this. Some loads are not ht friendly and you should account for this when deciding on how many threads to spawn.
They limited it to 64 cores to be fair to the arm processor but did not limit it to 18/24 cores to be fair to the intel processor. Why is that?
The last graph is the most enlightening if you keep in mind the number of real cpus each processor has.
CPU architects make lots of different choices and tradeoffs - in this case Intel have chosen hyperthreaded physically larger CPUs, while the ARM chip's designers have decided that hyperthreading brings no meaningful improvement but lets them build smaller (and maybe faster) CPUs, and as a result more CPUs per die.
These are tradoffs that we make all the time when building CPUs - none are 'best' it's more that a group of changes is better for a particular case.
So the people benchmarking here have NOT turned off hyperthreading on the ARM chips, there is none to turn off, instead there are more CPUs - the ARM guys have optimised their 64 core chip to be useful in their target market which happens to be closer to what these guy's application does
Running 64 threads on the intel cpus is slowing them down vs running the number of real cpus they have.
and as i said, since they limited the test to 64 threads even thou one of the cpus has more then 64 vcpus, ("to be fair to the arm processor") the moment they saw the final graph, they should have done the same thing in reverse, to be fair to the intel processor. Otherwise it just reeks of selective methodology application.
Of course, as you said, the real answer is they should not have limited the test to 64 threads. that doesn't match real workloads where the number of threads would be set to the number of cpus or vcpus.
Instead they should have done single threaded, tests with both processors maxed out at max(intel vcpu, arm vcpu) threads on both, as well as one where they set each to their respective max, as well as repeat with the real cpus number.
While power draw can't be measured in an AWS instance, there's no particular reason to suspect there's anything all that interesting here. Other ARM 64-80 core chips have the "normal" ~200W TDPs you'd expect to find in server CPUs of this type, and there's been very little difference in general power efficiency between ARM & x86 for many years now. ISA doesn't matter much here, it's more about the target design & performance the chip is trying to hit.
On the assumption performance equals this particular workload, then Graviton ( Or specifically Graviton 2 ) should, with an extremely high degree of certainty have an upper hand.
To answer your question in its general form, you have to take into account what types of "performance" you are interested in, and what Node these CPU are manufacturers in, Not to mention there are different form of Graviton and Intel ( x86 )
That could or could not be correct. We don't know their bill of materials. Probably some people can estimate it better for Intel. I understand the ARM stuff is AWS proprietary, so I would be surprised is any figures are public. Besides the costs are unkown the margins could be very different. AWS might be willing to pay a high investment to get more independent of Intel in the long term.
I worked at a big corporation in the mobile space before. They were willing to pay a high investment to get more independent of their single ARM SoC supplier. (It failed because Intel could not deliver in the end.)
I found that very interesting, thank you very much. I didn't follow the development closely and had no idea how close apparently ARM64 (well the Graviton2 implementation at least) in performance is to Intel's server CPUs.
I wished there would be some published results from a standardized test though. Is there any reason there is none for e.g. SPECpower?
Look at the single core results and you'll see the per-core performance isn't close at all. Depending on what you're doing, this may be a lot more relevant than the number of CPUs you can fit into a single socket.
It's unclear how NUMA-aware this benchmark is. The single-socket Intel results are not really that far off from the dual-socket results, which suggests it's not very NUMA friendly? Or there's some other factor in play there. But if it's not NUMA aware, and is suffering from that, then it's not really that surprising that 64 physical cores are faster than 18 physical cores, even if the later are ~2-3x faster cores.
A lot of the comments and the Article seems to be missing some context.
On Graviton -
People vastly under estimated the scale of Hyper scaler. ( They are called Hyper Scaler for a reason ) and over estimated the cost Amazon actually put / required / invested into G2 ( Graviton 2).
Over 50% of Intel Data Center Group revenue are from HyperScaler. Some estimate put Amazon at 50% of all HyperScaler. That is 25% of Intel Data Center Group revenue are from Amazon alone. Or ~$7B per year. To put this into perspective, AMD, a company that does R&D on CPU, GPU, in multiple different market segment make less revenue in 2019 ( $6.7B ) than Amazon spend with Intel.
It is important to note Data Centre Spends continue to grows with no end in sight. Amazon estimated there are less than 10% of Enterprise IT workloads are currently on Cloud. And IT in Enterprise is growing as well. Which means there is a double multiplier.
G2 is an ARM custom N1 Design. Basically with less core and L2 cache to reduce die size and cost. The N1 is TSMC blueprint design ready. So while you cant really buy "Graviton 2", in theory you can get a replica fabbed from TSMC if you have the money. ( On the assumption Amazon did not put any custom IP into it ) And That means G2 isn't a billion dollar project. Even if it cost Amazon $200M, if Amazon only make 1M G2 over its life time, that is still only $200 per unit. Or less than $300 including Wafer price. Compare to the cost of buying the highest core count from from Intel. The cost is nothing.
Also reminder Amazon dont sell chips. And the biggest recurring cost to AWS other than engineers is actually power. And in terms of workload per watts, G2 currently has huge lead in many areas. And as I have noted in another reply, Amazon intends to move all of its services and SaaS running on G2. The energy efficiency gain with G2 and future Graviton at AWS scale would be additional margin or advantage.
On the Article and SMT / HyperThread -
I guess the headline "Intel vs ARM" is a little clickbaity and may not be an accurate description. Which lead to comments thinking it is a technical comparison between the two. But I dont think the article intends it to be that way. It also assumes you are familiar with Cloud Vendors and pricing. Which means you knew what vCPU are, instances are priced per vCPU and ARM instances with the same vCPU prices are always cheaper.
And that means from a Cloud deployment and usage perspective, whether the Intel Core does SMT / Hyperthread, or can reached up to 6GHz is irrelevant. Since it is not designed to test those. You are paying by vCPU and you have a specific type of workload. You could buy a 64 vCPU Intel instances, run a maximum 32 Thread test on it and compared to a 32 vCPU G2 instances. But you will be paying more than double the price. IBM POWER9 also has SMT4 or 4 Threads per Core. No one disable SMT just to test its Single Core performance.
And as noted in the first reply, the test is clearly Memory Bound, in which G2 has an advantage of having 2 more Memory Channels along with higher Memory Speed support. It would be much better to see how it compares to the recently announced AMD Zen 2 instances also comes with 8 Channel memory.
It clearly performs and scales a lot better than the Intel CPUs (no doubt also benefiting from the increased memory bandwidth) and at high core counts is very close to the Graviton2.
Furthermore, I agree that the “investment costs” for Amazon are almost minute, they might have already earned it back.
I’ve seen rumours that AWS lost a lot of money developing their ARM chips. I haven’t seen a strong source confirming this, but it does pour cold water on the idea that ARM is ready to take on x86 for general server compute, though no doubt there are niches where it can do well.
If "lost a lot of money" means that they made a large investment that isn't paid off by just the first couple of months of the first generation there's no surprise there and their management would have been expecting it. It's pretty much impossible for their ARM chips to have paid off yet and it's a silly way to look at a long term strategy. It's a bit like a shipping company buying some new, gas-efficient trucks and being dinged because they haven't paid off their full cost in just a couple of months.
Plus this gives them more leverage over Intel on top of already being one of their biggest customers. I can't criticize an approach that puts the screws to them on price competitiveness.
The Graviton chips are just ARM reference designs with a few tiny modifications, very little R&D required. The majority of the NRE costs were probably the 7nm tapeout which is supposedly in the 10s of millions dollar range.
> 7nm tapeout which is supposedly in the 10s of millions dollar range.
Yes. Cookie cutter SoCs stopped making money at around 65nm node. You need to put more on the table these days than just bare ARM cores and generic peripherals to sell a SoC.
Many dotcoms that ventured into chipmaking are now quietly bailing out.
Making your own chips just to undercut Intel is a stupid idea. People tried it before more times than I can count. Just remember all of RISC epopeias from nineties. Where are SPARC, PARISC, PPC, MIPS now?
The fact that they use ARM instead of any other RISC core makes little difference.
Internet companies are too small to make money from undercutting chipmakers, but I believe they are not that far away from that point.
Maybe in 10 years or so, you will be working on a PC with Genuine Google(R) chip
You maybe aren't appreciating the scale of the cloud companies properly. In 2019, Amazon had 6x the Capex of AMD's entire revenue. Google 4x, Microsoft 3x. Obviously all of that Capex isn't for compute, but given the cost structure of servers, a significant chunk will be.
If AMD can profitably build and sell a state of the art CPU in the world with that scale, why couldn't the cloud companies be able to?
That's easy to say, now think of why other companies with n-times money "can't simply do that"?
It takes quite a lot of effort, and skill: execution capability. GAF companies are easy money companies, they, and their executives are not made for that.
But your initial argument wasn't about competence, it was an economic argument about scale. To quote, "the internet
companies are too small", "No amount I can imagine can pay off for the tapeout on the latest node for them".
Given you've pivoted away from the economics to claiming that they just can't do it, how do you explain the results from this article? Shouldn't Amazon have been too incompetent to build a state of the art server CPU? How about Google's TPUs, in-house switches, and in-house NIC ASICs? Just failed prestige projects?
That’s not really a valid comparison. The market for chips was a lot smaller as was the volume. Who knows how many chips that Amazon and Google use for their own servers. They have to use more internally than the number of PPC chips that IBM and Motorola sold at its height.
On the other hand, it wouldn’t have made sense for Apple to design their own chips for Macs, but they sell 200-250 million ARM based devices a year.
> Who knows how many chips that Amazon and Google use for their own servers.
No amount I can imagine can pay off for the tapeout on the latest node for them. All dotcoms taken together make for single digit percentage of wafer output for both Intel, or AMD.
Apple doesn't make money on chips, they make money off their devices. An A13 may well not make them money, but the whole Iphone does.
I doubt it. The A13 and successors are money printing machines.
Apple has always been about limiting SKUs to maximize their economies of scale. The original iMac was a great example of this... although they had no market share, they had like 3 SKUs vs HP and Dell who had dozens or hundreds of different PCs. It was the biggest selling model of computer at the time, and they make money on it because of that scale.
They do the same thing with the iPhone today. The SE has the same guts as the flagship SKU, which is in turn faster than any competing product. The control of the roadmap and capabilities of the CPUs is a huge competitive advantage that makes a lot of money. They save money on things they don’t control like batteries because the faster CPU uses less power, etc.
Everyone else is stuck with whatever garbage Qualcomm is dishing out.
Amazon is in a similar place. There remains a lot of on-premise server compute that AWS wants to conquer. You need to think about their actions today in terms of what they mean in 2030.
> They save money on things they don’t control like batteries because the faster CPU uses less power, etc. Everyone else is stuck with whatever garbage Qualcomm is dishing out.
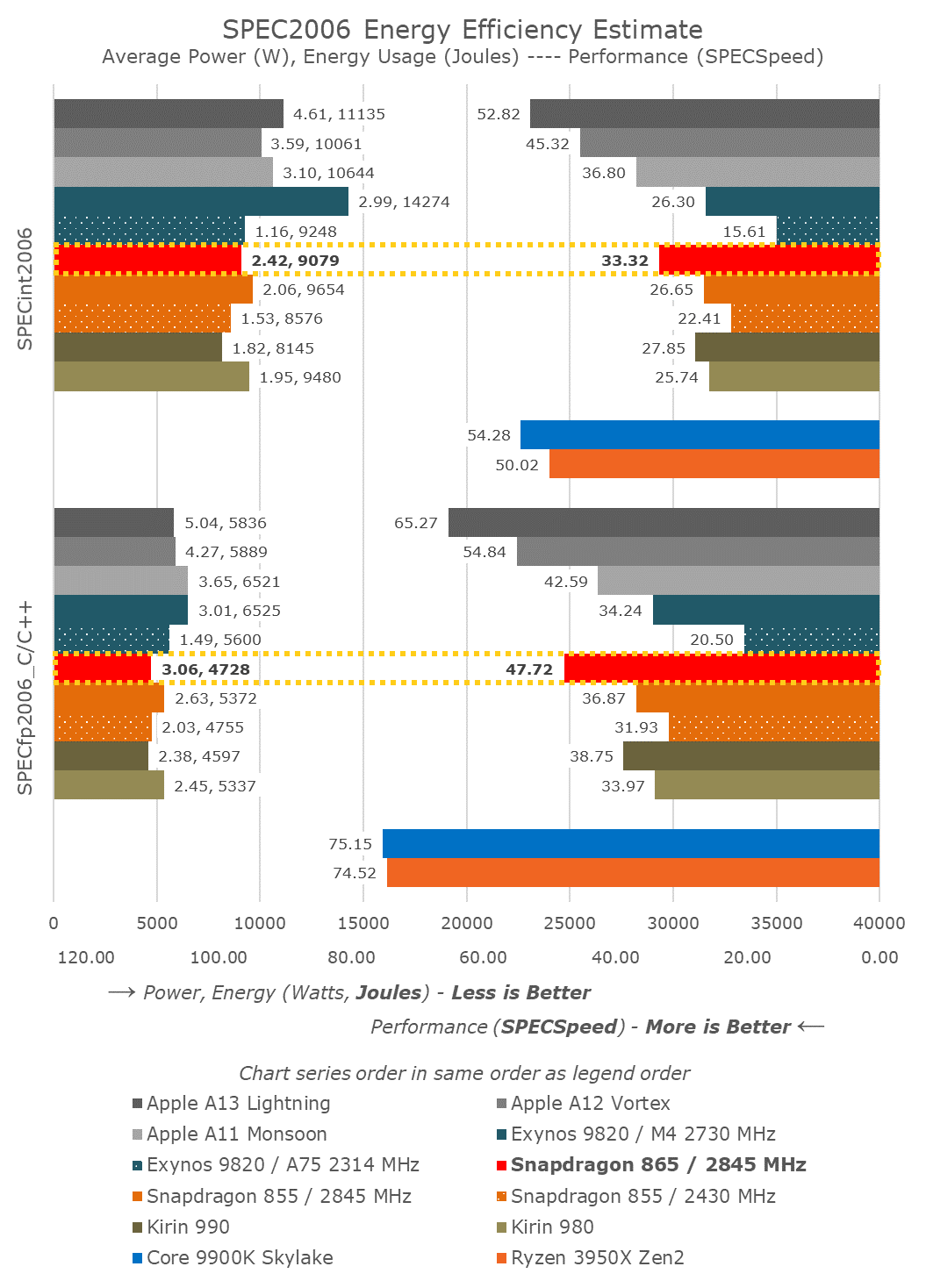
I don't think the battery/CPU relation you posit is true - the A13 is faster in single-core performance than the Snapdragon 865 (or 855), but consumes more total power to do the same work: https://images.anandtech.com/doci/15207/SPEC2006_S865.png
I think all this tells you is that ARM's big cores chose a power/performance curve point well below the A13. The upcoming Cortex-X1 in next year's 875 will be their first attempt at breaking into that market.
I’m not an expert in mobile CPU’s, but I know that those benchmarks are server benchmarks and aren’t designed for a mobile use case.
Mobile CPUs usually have low power and high performance modes, and aggressively shed power loads when idle. I’m not sure what benchmark is appropriate, but I wouldn’t draw much from that one.
Exactly. I work in the enterprise space, and we are the frog in the slowly boiling water. In 2009, cloud email was unthinkable, in 2012, on-prem email was unthinkable.
Most compute workloads are the same, and the sorry state of the legacy hardware companies is testament to that. HPE sold off its field services to Unisys, the Dell conglomerate exists (owing to the collapse in valuation of once mighty EMC), IBM is whatever IBM has become, etc. Oracle essentially doesn’t pay salespeople for selling traditional software.
At some point, more enterprise workloads just won’t be feasible anywhere but cloud. The stupid government or a bank will pay a few FTEs to swap parts for $1M/year, but everyone else will have moved to cloud.
A national government has a very different risk calculus. Imagine you are, say, Indian government, you have to trust AWS with your data and they won't shut you off if Donald trump goes nuts.
And Amazon doesn’t make money off chips. It makes money selling services that run on chips. They both sell integrated products.
But, we also aren’t talking about all chips. Just server class chips. Energy cost is also a very real cost at the scale of the cloud vendors. If they can decrease the overall cost and the cost/per watt. It’s a win.
> No amount I can imagine can pay off for the tapeout on the latest node for them. All dotcoms taken together make for single digit percentage of wafer output for both Intel, or AMD.
How did they “lose money”? They aren’t selling them to other vendors. The only fair way to compute a “loss” is whether they save money in the long term from using ARM vs x86.
Cost money sure... but for all anyone knows, just showing a working ES to the right people at intel and amd knocked enough off their chip pricing to get all their money back ;)
And I strongly suspect Apple's been doing the same with ARM MacBook prototypes since A8X, if not before...
Speculation aside, it's pretty cool to see an ARM core competitive at this scale at the socket level.
The original use was as CPUs in their network devices, which meant they could sell more x86 cores as they didnt have to use some to support networking and remote storage. Probably made a lot of money selling the additional cores.
This test is flawed in so many ways. I just do not understand how the authors do not feel ashamed about what they're trying to sell to readers.
In a healthy environment the author/s presenting study of such quality would've been laughed out the door.
What their results are actually showing is that up to about 18 cores - the actual number of physical cores on a single Intel's CPU they've tested Intel kicks the shit out of Graviton. So if you want proper test to compare that particular Graviton 64 core CPU with the Intel then take system with single socket Intel CPU with 64 real cores as well and then come back with the results.
You, not me, argued that performance is not what to consider but performance per core (not physical cpu). Don’t push arbitrary metrics and then complain when you’re called out for it.
I guess it depends on what they're trying to say (which isn't clear). When you get an AWS machine with 36 vCPUs, if you pick Intel, you get 36 threads, if you pick a Graviton2, you get 36 Cores.
No, they’re comparing one physical Intel CPU/socket to one physical ARM cpu/socket of roughly equal price. That seems far more equal than an arbitrary comparison of cores when the architectures are so different.
{kind=link}
{kind=link}
{kind=link}
The memory controller on the ARM part must be excellent given that the Intel machine had 2x sockets.
I don't think a core to core comparison or core to hyperthreaded core makes much sense. There are so many other unknowns, they only appear to be similar metrics. $/work_unit is the benchmark I would focus on in case like object storage.