The cross socket NUMA bandwidth is like a tiny straw. If the OS or application is failing to pin the memory, cpu and IO together on the correct numa node your going to have a major scalability problem.
So, two things can really throw this off, having a Physical->VM topology mismatch, or using a language that is garbage collected and won't allow the programmer to control memory/node placement.
I've literally gotten 10x perf improvements by fixing these kinds of problems in the past.
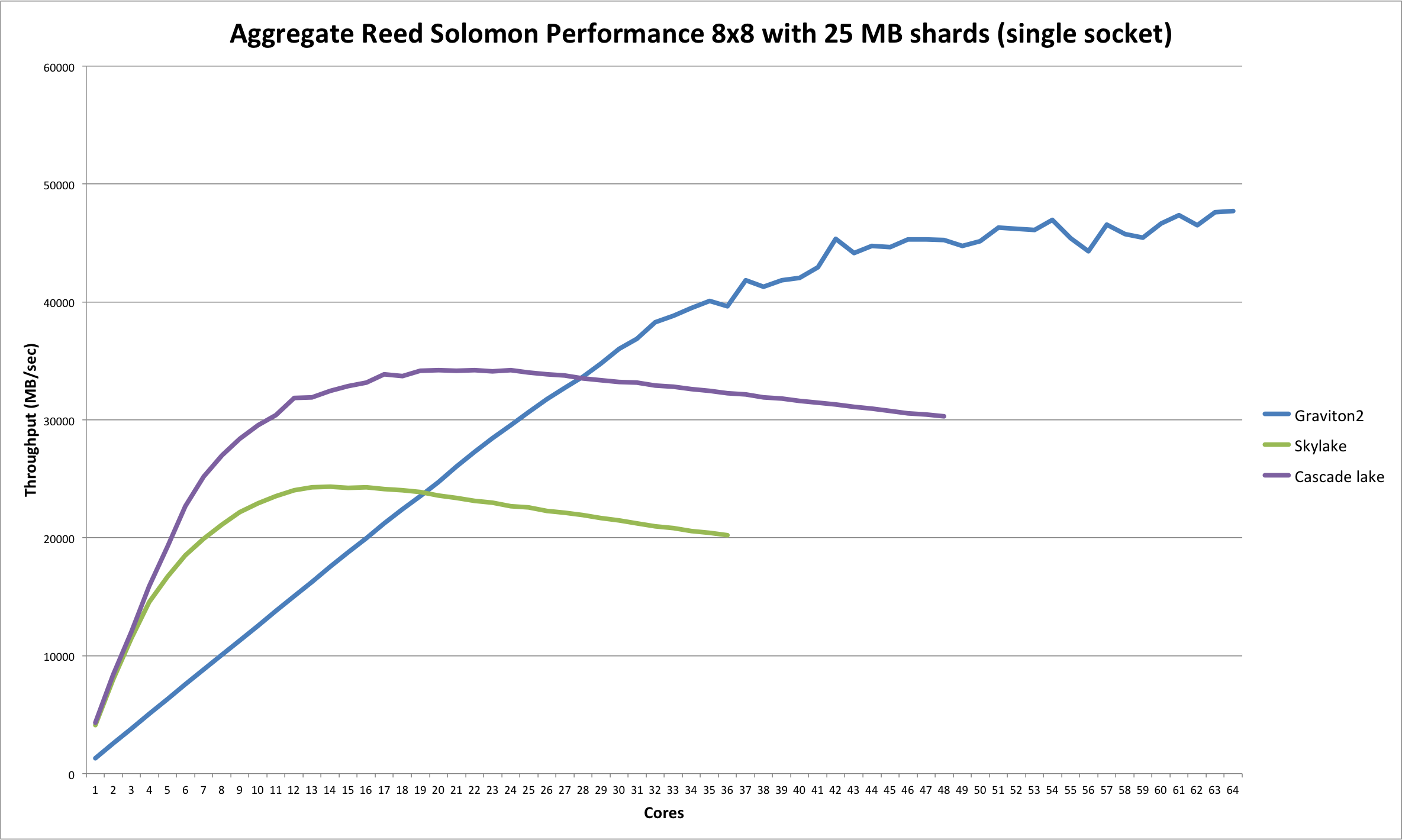
Combined with comparing cores to threads and the results are somewhat predictable. In this way, the simpler gravaton topology is really going to shine for applications that don't scale well. That is until intel builds an actual high core count single socket machine.
That really looks like it's just sorting by memory bandwidth. Particularly with Cascade Lake's results vs. Skylake at the ~10 core number, since there's not really any other major difference between those two.
Being that memory bandwidth constrained, and then not being NUMA aware, is also quite likely why the dual-socket results are a disaster.
The unidirectional bandwidth across a two socket system is roughly equal to a single DDR channel. Which is why you see postings on the intel forums about people complaining about their perf falling off a cliff if the hardware decides to flag the directory as requiring cross socket snoop (or whatever its actually doing). So even if you have done a reasonable job keeping your thread+data locally, doing a remote reference, or accidentally running the thread for a short while on the wrong socket can permanently lower the performance. See https://software.intel.com/en-us/forums/software-tuning-perf... for an example about a contented cache line.
Thankfully the latest products are mostly 10.4GT (gold and above) as it appears intel isn't doing as much product segmentation based on UPI link speeds anymore (silver/bronze are still slower though).
> The unidirectional bandwidth across a two socket system is roughly equal to a single DDR channel
Depends on the implementation. Epyc Rome's 2P socket design is 64 PCI-E 4.0 lanes between the two CPUs. That's 128 GB/s bandwidth, which is roughly equivalent to 6-channel DDR4 2666.
{kind=link}
The cross socket NUMA bandwidth is like a tiny straw. If the OS or application is failing to pin the memory, cpu and IO together on the correct numa node your going to have a major scalability problem.
So, two things can really throw this off, having a Physical->VM topology mismatch, or using a language that is garbage collected and won't allow the programmer to control memory/node placement.
I've literally gotten 10x perf improvements by fixing these kinds of problems in the past.
Combined with comparing cores to threads and the results are somewhat predictable. In this way, the simpler gravaton topology is really going to shine for applications that don't scale well. That is until intel builds an actual high core count single socket machine.