> It's a spot where the VAE is trying to smuggle global information about the image through latent space. This is exactly the problem that KL-divergence loss is supposed to prevent.
Is that what KL divergence does?
I thought it was supposed to (when combined with reconstruction loss) “smooth” the latent space out so that you could interpolate over it.
Doesn’t increasing the weight of the KL term just result in random output in the latent; eg. What you get if you opt purely for KL divergence?
I honestly have no idea at all what the OP has found or what it means, but it doesnt seem that surprising that modifying the latent results in global changes in the output.
Is manually editing latents a thing?
Surely you would interpolate from another latent…? And if the result is chaos, you dont have well clustered latents? (Which is what happens from too much KL, not too little right?)
I'd feel a lot more 'across' this if the OP had demonstrated it on a trivial MNIST vae with both the issue, the result and quantitatively what fixing it does.
I can't comment on what changing the weights of the KL divergence does in this context, but generally
> Is that what KL divergence does?
KL divergence is basically a distance "metric" in the space of probability distributions. If you have two probability distributions A and B, you can ask how similar they are. "Metric" is in scare quotes because you can't actually get a distance function in the usual sense. For example, dist(A,B) != dist(B,A).
If you think about the distribution as giving information about things, then the distance function should say two things are close if they provide similar information and are distant if one provides more information about something than the other.
The comment claims (and I assume they know what they're talking about) that after training we want the KL divergence to be close to a standard Gaussian. So that would mean that our statistical distribution gives roughly the same information as a standard Gaussian. It sounds like this distribution has a whole lot of information in one heavily localized area though (or maybe too little information in that area, I'm not sure which way it goes).
Almost. The KL tells you how much additional information/entropy you get from a random sample of your distribution versus the target distribution.
Here, the target distribution is defined as the unit gaussian and this is defined as the point of zero information (the prior). The KL between the output of the encoder and the prior is telling us how much information can flow from the encoder to the decoder. You don't want the KL to be zero, but usually fairly close to zero.
You can think of the KL as the number of bits you would like to compress your image into.
MMmm... Is there any specific reason this would result in a 1-1 mapping between the latent and the decoded image? Wouldn't just be a random distribution and everything out of the VAE would just be pure chaos?
Unfortunately I don't know this field yet. User 317070 may have more context here. They commented here [0] about how to think about the KL divergence as measuring information from from the encoder to the decoder and what we want out of that.
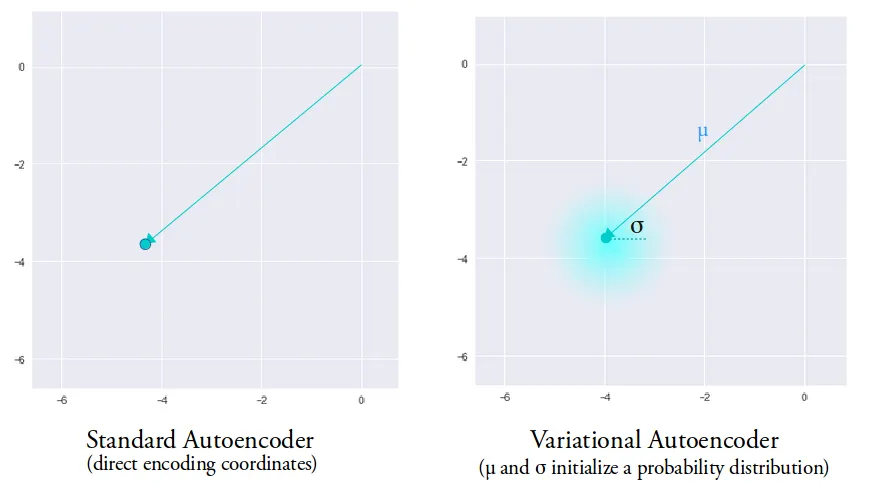
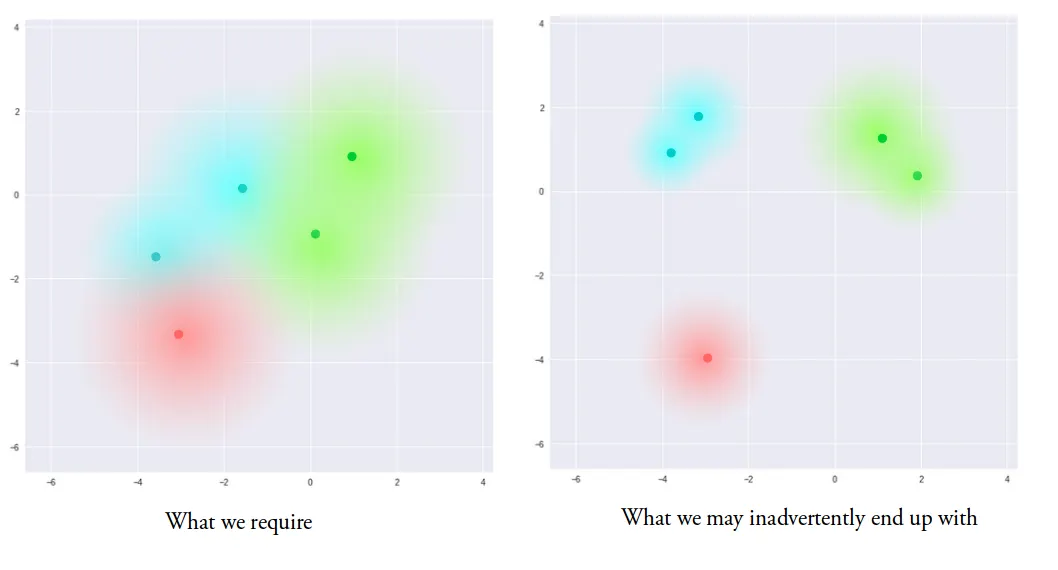
But based on the link you sent, it looks like what we're doing is creating multiple distributions each of which we want patterned on the standard normal. The key diagrams are
https://miro.medium.com/v2/resize:fit:1400/format:webp/1*96h... and https://miro.medium.com/v2/resize:fit:1400/format:webp/1*xCj.... You want the little clouds around each dot to be roughly the same shape. Intuitively, it seems like we want to add noise in various places, and we want that noise to be Gaussian noise. So to achieve that we measure the "distance" of each of these distributions from the standard Gaussian using KL divergence.
To me, it seems like one way to look at this is that the KL divergence is essentially a penalty term and it's the reconstruction loss we really want to optimize. The KL penalty term is there to serve essentially as a model of smoothness so that we don't veer too far away from continuity.
This might be similar to how you might try to optimize a model for, say, minimizing the cost of a car, but you want to make sure the car has 4 wheels and a steering wheel. So you might minimize the production cost while adding penalty terms for designs that have 3 or 5 wheels, etc.
But again I really want to emphasize that I don't know this field and I don't know what I'm talking about here. I'm just taking a stab.
>I honestly have no idea at all what the OP has found or what it means, but it doesnt seem that surprising that modifying the latent results in global changes in the output.
It only happens in one specific spot: https://i.imgur.com/8DSJYPP.png and https://i.imgur.com/WJsWG78.png. The fact that a single spot in the latent has such a huge impact on the whole image is not a good thing, because the diffusion model will treat that area as equal to the rest of the latent, without giving it more importance. The loss of the diffusion model is applied at the latent level, not the pixel level, so that you don't have to propagate the gradient of the VAE decoder during the training of the diffusion model, so it's unaware of the importance of that spot in the resulting image.
Not arguing that; I'm just saying I don't know that KL divergence does or is responsible for this, and I haven't seen any compelling argument that increasing the KL term would fix it.
There's no question the OP found a legit issue. The questions are more like:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Is that what KL divergence does?
I thought it was supposed to (when combined with reconstruction loss) “smooth” the latent space out so that you could interpolate over it.
Doesn’t increasing the weight of the KL term just result in random output in the latent; eg. What you get if you opt purely for KL divergence?
I honestly have no idea at all what the OP has found or what it means, but it doesnt seem that surprising that modifying the latent results in global changes in the output.
Is manually editing latents a thing?
Surely you would interpolate from another latent…? And if the result is chaos, you dont have well clustered latents? (Which is what happens from too much KL, not too little right?)
I'd feel a lot more 'across' this if the OP had demonstrated it on a trivial MNIST vae with both the issue, the result and quantitatively what fixing it does.
> What are the implications?
> Somewhat subtle, but significant.
Mm. I have to say I don't really get it.