The more pedestrian 5950X or the now bargain 3950X are great for anyone doing a lot of compiling. With the right motherboard they even have ECC RAM support. Game changer for workstations in the $1000–$2000 range.
The more expensive Threadripper parts really shine when memory bandwidth becomes a bottleneck. In my experience, compiling code hasn’t been very memory bandwidth limited. However, some of my simulation tools don’t benefit much going from 8 to 16 cores with regular Ryzen CPUs because they’re memory constrained. Threadripper has much higher memory bandwidth.
I suspect the biggest (build time) benefit to most c++ workflows and toolchains was the move to ubiquitous SSD. Prior to that in my experience excepting expensive RAID array dedicated build machines, it was really easy to build a system that would always be IO bound on builds. There of course were tricks to improve things but you still tended to hit that wall unless your CPUs were really under spec.
edit: to be clearer, I'm not thinking of dedicated build machines here (hence RAID comment) but over all impact on dev time by getting local builds a lot faster.
SSDs help, but nothing beats core count X clock speed when compiling.
Source code files are relatively small and modern OSes are very good at caching. I ran out of SSD on my build server a while ago and had to use a mechanical HDD. To my surprise, it didn’t impact build times as much as I thought it would.
I did a test a while back where I had a workstation compiling linux with SSD and one with a HDD -- it turns out all the files were cached in the memory (measely 8gb). But for general usage and user experience I would reccomend SSD without any question.
Hmm. Maybe the tradeoff has changed since I last tested this (to be fair, a few years ago). But I'm also not focused on build servers especially, it's always been possible to make those reasonably fast. Unless you have a very specific sort of workflow anyway, your devs are doing way more local builds than on the server and that sped up a ton moving to SSD, in my experience anyway. YMMV of course.
Last time I benchmarked C++ compilation on SSDs vs HDDS (compiling the PCL project on Linux which took around 45 minutes), SSD didn't help in a noticeable fashion.
I believe that this makes sense:
In a typical C++ project like that which use template libraries like CGAL, compilation of a single file takes up to 30 seconds of CPU-only time. Even though each file (thanks to lack of sensible module system) churns through 500 MB of raw text includes, that's not a lot over 30 seconds, and the includes are usually from the same files, which means they are in the OS buffer cache anyway so they are read from RAM.
However, if the project uses C++ like C, compilation is a lot faster; e.g. for Linux kernel C builds, files can scroll by faster than a spinning disk seek time would allow.
Back in 2012 at a previous job we tested compilation performance on spinning disks versus solid state. On Linux it made almost no difference what so ever, on Windows however it was a game changer. The builds were an order of magnitude faster so it was well worth it making the switch.
Just mount a ramdisk over your portage TMPDIR (default /var/tmp/portage). You will need a decent amount of ram though for larger packages like LLVM. Disabling debug symbols will reduce the required space a bit.
You know I wonder how much of an impact this has had on the recent move back to statically typed and compiled languages vs. interpreted languages. I had assumed most of the compilation speedups were due to enhancements to the compiler toolchain - but my local laptop moving from 100 IOPS to > 100k IOPS and 3GB/s throughput may have more to do with it.
CPUs got faster too. My MacBook pro is a lot faster than the 6yo top of the line Mac Mini.
In fact, if compile times are being limited by storage there should be some quick wins in configuration terms - building intermediates to RAM, cache warming, etc - that can enable better performance than faster storage.
i (and some teamates) actually put HDDs on some workstations as SSD just die after 2-3 years of active build on them and with modern HDDs you have practically unlimited storage while you can have only limited number of 400G builds on SSD (the org has psychological barriers to having more than 1-2Tb SSD in a machine) and the SSD start to have perf issues when at 70-80% capacity . With HDD the build time didn't change much - the machines have enough memory for the system to cache a lot (256-512G RAM).
If your SSD would be at 100% utilization it’s going to take a lot of HDD to reach that kind of bandwidth. To the point where for high bandwidth loads SSD’s actually cost less even if you have to replace them regularly.
100% utilization and 30x the bandwidth = 30x as many HDD. Alternatively, if HDD’s are an option you’re a long way from 100% utilization.
SSD have hard time sustaining 200-400Mb/s write where is 4 HDD do is easily. Our case isn't that much about IOPS.
Anyway, reasonably available SSDs have up to [1000 x SSD size] total write limit, so doing couple of 400G builds/day would use up the 1TB drive in 3 years. At worst times we had to develop&maintain 5 releases in parallel instead of regular 2-3.
4 HDDs can do 200-400MB/s _sequential_ IO, 1 modern SSD can do 150-200MB/s _random_ IO and 400MB/s sequential IO while 4 HDDs would have a hard time doing IIRC more than 8MB/s random IO
i don't argue that. It is just random IO isn't that important for our use case, especially compare to capacity and sequential IO which are important for us and which HDD is ok for.
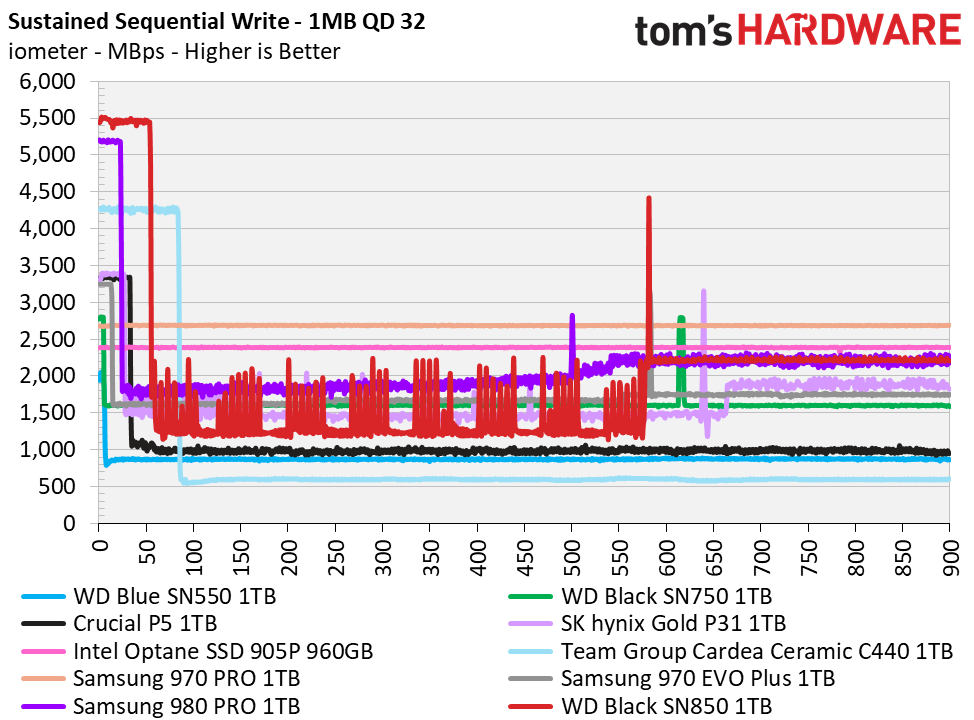
Few SSDs can sustain such a speed for a long time. After they exhaust their temporary SLC cache they drop to much lower speeds.
SSDs that have accumulated a large amount of writes might also make large pauses at random times during writing, for garbage collection.
Good SSDs remain faster than HDDs even in these circumstances, but they are nevertheless much slower than when benchmarked for short times while they are new.
Note how, in the graph, even the worst-performing SSD stays above 500 MB/sec sequentially for an indefinite amount of time, while the parent post claimed SSDs couldn't even do 200–400.
You can get SSDs without such issues. At least for the kind of long sequential writes followed by deletes where HDD are are even vaguely comparable, good SSD’s can maintain very close to their theoretical maximum speeds indefinitely.
They only really slow down in usage patterns that trash traditional HDD’s, which have much worse disk fragmentation issues.
Depends on the kind of SSD. If it's using SLC, the write endurance is much much higher. If you're going with cheap SSDs (TLC or QLC), your write endurance will suck.
SLC seems to be going away pretty quickly, if it hasn't already been phased out. It just can't produce the price / GB of the better tech. Also, that article you linked is almost 10 years old.
You're best bet for long-term reliability is to buy much more capacity than you need and try not to exceed >50% capacity for high write frequency situations. I keep an empty drive around to use as a temp directory for compiling, logging, temp files, etc.
Also, my understanding is that consumer-grade drive need a "cool down" period to allow them to perform wear leveling. So you don't want to be writing to these drives constantly.
I recently bought an external 32GB SLC SSD (in the form factor of an USB pendrive). Its random read/write speeds are quite insane (130+ MB/s both) while consumer SSDs like the Samsung 850 Evo barely manage 30 MB/s read/write. It's also advertised as very durable.
I plan on using a couple of those as ZFS metadata and small block caches for my home NAS, we'll see how it goes but people generally and universally praise the SLC SSDs for their durability.
> You're best bet for long-term reliability is to buy much more capacity than you need and try not to exceed >50% capacity for high write frequency situations. I keep an empty drive around to use as a temp directory for compiling, logging, temp files, etc.
That's likely true. I am pondering buying one external NVMe SSD for that purpose exactly.
It's actually not better tech, instead it's more complicated, more error prone and less durable ways to use the same technology that produces more space for a lower price. MLC is pretty much okay but TLC is a little too fragile and low performance in my opinion. I prefer spinning HDD's over QLC since the spinning drives have predictable performance.
Some QLC drives perform quite well. And of course for any workload that is primarily reads, they're totally fine. I use one to hold my Steam collection.
And logging all of those unit tests associated with all of those builds (and rolling over those logs with TRACE level debugging).
Every build gets fully tested at maximum TRACE logging, so that anyone who looks at the build / test later can search the logs for the bug.
8TBs of storage is a $200 hard drive. Fill it up, save everything. Buy 5 hard drives, copy data across them redundantly with ZFS and stuff.
1TBs of SSD storage is $100 (for 4GBps) to $200 (for 7GBps). Copy data from the hard drive array on the build server to the local workstation as you try to debug what went wrong in some unit test.
My mind was blown when I had to send a fully logged 5 minutes of system operation to a friend for diagnostics (MacOS 11 on an M1 Mini). He wasn't joking when he said don't go over a few minutes because the main 256GB system drive almost ran out of space in that time. After getting it compressed down from 80GB and sent over I got my mind blown again when he explained he had to move to his workstation with 512+gb of ram just to open the damn file.
A way to have your cake and eat it too - check out Primocache. It's pretty inexpensive disk caching software (especially for Windows Server which is where I really leverage it!).
Pair it with an Optane for L2 cache and it will speed up normal SSD use too ;)
The default one that caches disk data in memory? It solves a very different problem by caching data from slower disks onto faster disks. It can accelerate reads and it can also act as a writeback cache.
It's most comparable to lvmcache or bcache. As in, Primocache does three actually useful things:
- It can pre-populate an in-memory disk cache. Not massively useful, but depending on your workload and uptime it might save some time. Nothing I know of does this on Linux.
- It can act as a level 2 block cache, i.e. caching frequently accessed blocks from slow (HDD) storage on fast (SSD) storage. This is massively useful, especially for e.g. a Steam library.
- It can force extensive write buffering, using either main memory or SSD.
And yes, it can also act as a block buffer in main memory, but I don't find that helpful. Windows' default file cache does a good enough job, and Linux' VFS cache works even better. (Though ZFS' ARC works better yet...)
Its write bufferin increases write speeds massively, inasmuch as it delays actually writing out data. Obviously, doing so with main memory means a crash will lose data; what's not so obvious (but amply explained in the UI) is that, because it's a block-based write buffer, it can also corrupt your filesystem. Primocache does not obey write barriers in this mode.
What's even less obvious, and where it differs from lvmcache / bcache, is that this still happens if you use only an L2 write buffer, not a memory-based one. The data will still be there, on the SSD, but Primocache apparently doesn't restore the write-buffer state on bootup. Possibly it's not even journalled correctly; I don't know, I just got the impression from forums that fixing this would be difficult.
So, overall, bcache / lvmcache / ZFS* are all massively superior. Primocache is your only option on Windows, however, unless you'd like to setup iSCSI or something. I've considered that, but I'd need at least a 10G link to get worthwhile performance.
*: ZFS supports cache-on-SSD, and unlike a year ago that's persisted across reboots, but it doesn't support write-buffer-on-ssd. Except in the form of the SIL, which is of dubious usefulness; that buffer is only used for synchronous writes.
However, ZFS is a transaction-oriented filesystem. It never reorders writes between transaction groups, which means that if you run it with sync=disabled -- which disables fsync & related calls -- it's still impossible to get locally visible corruption. The state of your filesystem at bootup will be some* valid POSIX state, as if the machine was suddenly but cleanly shut down. You still need to tweak the filesystem parameters; by default transaction groups end after 5 seconds, which is unlikely to be optimal.
Alternately, you can run it on top of lvmcache or bcache.
Those are pretty beefy workstations, does every developer have one or are these really build servers? As I noted you could always throw money at this and end up somewhere reasonable, but it introduces workflow considerations for your devs.
anecdotally i'd see filesystem errors and write speed dropping, sometimes writes practically hanging, especially if the drive is close to 90% capacity.
I've had a Crucial 256GB SSD (MX100) since early 2015 and I use it with Windows 10. WSL 2's file system is on there along with Docker, which I've been using full time since then. That means all of my source code, installing dependencies, building Docker images, etc. is done on the SSD.
The SMART stats of the drive says it's at 88% health out of 100%, AKA it'll be dead when it reaches 0%. This is the wear and tear on the drive after ~6 years of full time usage on my primary all around dev / video creating / gaming workstation. It's been powered on 112 times for a grand total of 53,152 running hours and I've written 31TB total to it. 53,152 hours is 2,214 days or a little over 6 years. I keep my workstation on all the time short of power outages that drain my UPS or if I leave my place for days.
I go out of my way to save large files (videos) and other media (games, etc.) on a HDD but generally most apps are installed on the SSD and I don't really think about the writes.
As a counterpoint, I burn-tested several random M.2 NVME drives over a period of a month of 24/7 writes and reads and all but one model failed before the month was up
Part of the purpose of a burn test is to see how it handles temperature under load. We didn't have the option of adding cooling, many of the product installations took place in a hot climate, and nobody wanted to pay for a hardened part...
Anyway, my point is that SSD drive reliability varies wildly
Hmmm. Looks like I need to move my temp dir for GeForce instant replay off of my SSD. It records about 1.6GB/5min which is 460GB per day. RAM disk would probably be the best option.
I'm pretty sure it doesn't record the desktop with instant unless you have specifically set that up, so you'd only be writing to the drive while you're in game.
At my current job I do at least 150-200GB of writes per day.
50GB for code temporary files, 70+ GB for data files, x2 that for packing them, and then also deleting some of those to make some room to do it again.
Also the disk that it's on is over 50% full so that also degrades it faster as there's fewer blocks to wear level with.
The larger your SSD the more flash cells you have, so the more data you can write to it before it fails.
You can see this from the warranty for example, which for the Samsung 970 EVO[1] goes linearly from 150TBW for the 250GB model up to 1200TBW for the 2000GB model.
So if you take the 1000GB model with its 600TBW warranty, you can write 50BG of data per day for over 32 years before you're exhausted the drive write warranty.
They do but it's really large. The Tech Report did an endurance test on SSDs 5-6 years ago [0]. The tests took 18 months before all 6 SSDs were dead.
Generally you're looking at hundreds of terabytes, if not more than a petabyte in total write capacity before the drive is unusable.
This is for older drives (~6 years old as I said), and I don't know enough about storage technology and where it's come since then to say, but I imagine things probably have not gotten worse.
I am afraid they did, consumer SSDs moved from MLC (2 bits per cell) to TLC (3) or QLC (4). Durability changed from multiple petabytes to low hundreds of terabytes. Still a lot, but I suspect the test would be a lot shorter now.
The TLC drive in that test did fine. 3D flash cells are generally big enough for TLC to not be a problem. I would only worry about write limits on QLC right now, and even then .05 drive writes per day is well under warranty limits so I'd expect it to be fine. Short-lived files are all going to the SLC cache anyway.
SSDs avoid catastrophic write failures by retiring damaged blocks. Check the reported capacity; it may have shrunk :) Before you ever see bad blocks, the drive will expend spare blocks; this means that a new drive you buy has 10% more capacity than advertised, and this capacity will be spent to replace blocks worn by writes.
SSDs never shrink the reported capacity in response to defective/worn-out blocks. Instead, they have spare area that is not accessible to the user. The SMART data reported by the drive includes an indicator of how much spare area has been used and how much remains. When the available spare area starts dropping rapidly, you're approaching the drive's end of life.
I so happened to know this already, but I must say I've always found the approach somewhat weird. Wouldn't it make more sense to give the user all the available space, and then remove capacity slowly as blocks go bad? I guess they think people would be annoyed?
Imagine if we treated batteries like SSDs, not allowing the use of a set amount of capacity so that it can be added back later, when the battery's "real" capacity begins to fall. And then making the battery fail catastrophically when it ran out of "reserve" capacity, instead of letting the customer use what diminished capacity was still available.
Shrinking the usable space on a block device is wildly impractical. The SSD has no awareness of how any specific LBA is being used, no way to communicate with the host system to find out what LBAs are safe to permanently remove. You can't just incrementally delete LBAs from the end of the drive, because important data gets stored there, like the backup GPT and OS recovery partitions. Filesystems also don't really like when they get truncated. Deleting LBAs from the middle of a filesystem would be even more catastrophic. The vast majority of software and operating systems are simply not equipped to treat all block devices as thinly-provisioned. [1]
And SSDs already have all the infrastructure for fully virtualizing the mapping between LBAs and physical addresses, because that's fundamental to their ordinary operation. They also don't all start out with the same capacity; a brand-new SSD already starts out with a non-empty list of bad blocks, usually a few per die.
Even if it were practical to dynamically shrink block devices, it wouldn't be worth the trouble. SSD wear leveling is generally effective. When the drive starts retiring worn out blocks en masse, you can expect most of the "good" blocks to end up in the "bad" column pretty soon. So trying to continue using the drive would mean you'd see the usable capacity rapidly diminish until it reached the inevitable catastrophe of deleting critical data. It makes a lot more sense to stop before that point and make the drive read-only while all the data is still intact and recoverable.
[1] Technically, ATA TRIM/NVMe Deallocate commands mean the host can inform the drive about what LBAs are not currently in use, but that always comes with the expectation that they are still available to be used in the future. NVMe 1.4 added commands like Verify and Get LBA Status that allow the host to query about damaged LBAs, but when the drive indicates data has been unrecoverably corrupted, the host expects to be able to write fresh data to those LBAs and have it stored on media that's still usable. The closest we can get to the kind of mechanism you want is with NVMe Zoned Namespaces, where the drive can mark individual zones as permanently read-only or offline. But that's pretty coarse-grained, and handling it gracefully on the software side is still a challenge.
I can imagine, OSes in general are not prepared to such reported numbers shrinking. There would be a hole.
What if a moment ago my OS has still 64G and then all of the sudden it only has 63G. Where would the data go? I think something has to make up for the loss.
For me it makes sense to report logically 64G and internally you do the remapping magic.
I wonder, how some OSes deal with a hot-swap of RAM. You have a big virtual address space and all of the sudden there is no physical memory behind it.
Not quite how it works. The SSD will never have a capacity lower than its rated capacity.
For the failures I've seen, once the SSD goes to do a write operation and there's no free blocks left, it will lock into read-only mode. And at that point it is dead. Time to get a new one.
Now I'm really curious. I took the drive I swapped hundreds of terabytes to, and put it in a server (unfortunately not running a checksumming filesystem) and it ran happily for a year.
> The more expensive Threadripper parts really shine when memory bandwidth becomes a bottleneck.
Threadripper can be useful for IO, especially for C++ (which is famously quite IO intensive) owing to its 128 PCIe lanes, you can RAID0 a bunch of drives and have absolutely ridiculous IO.
Where can you get decent ECC ram for a reasonable price? I was on the hunt recently for ECC RAM for my new desktop and I gave up and pulled the trigger on low latency non-ECC RAM. Availability seems to be pretty terrible at the moment.
You can get ECC UDIMMs from Supermicro. They are rebranded Micron DIMMs. ECC memory is not going to go as high of frequencies as you might be looking for. They will only go up to the officially validated speed of the CPUs. https://store.supermicro.com/16gb-ddr4-mem-dr416l-cv02-eu26....
The rated speeds are not as high, but ECC memory can be overclocked just as non-ECC; memory overclock support is mostly up to the motherboard. I have some DDR4-2666 ECC overclocked to 3200 MHz with slightly tighter timings on TRX40.
I picked one up at the Minneapolis Microcenter about a week ago at near (or less) than MSRP. I'd been looking for any stock since launch, and that was the first one I'd seen show up in stock and queued up for it. (Same day as a bunch of video cards showed up, so a bit less competition.)
They have an online checkin app that they use to order the queue. You see it show up in stock, add yourself to the queue, and get an early enough spot - show up. No need to wait in the cold. (ymmv on weather, but up here... can be cold)
IIRC AMD has EEC support in all x70/x50 motherboards and cpu combinations. If I may, what kind of simulations are you running?
I am trying to build a system for Reinforcement Learning research and seeing many things depend on python, I am not certain how to best optimise the system.
Yep, with permanent WFH due to the pandemic I started working on a desktop with 5950X + 64 GB memory and it's been a huge upgrade over my work laptop (and probably any laptop available at the moment).
>C++Builder with TwineCompile is a powerful productivity solution for multi-core machines compiling 1 million lines of code very quickly and can work better than the MAKE/GCC parallel compilation Jobs feature due to it’s deep IDE integration
You're claiming this plugin has deeper IDE integration than `make`? I find that really, really difficult to believe. And if it's true, it seems like the solution is to either use a better IDE, or improve IDE support for the de facto standard tools that already exist, as opposed to writing a plugin for the -j flag.
Yes, it could be as simple as having Dev-C++ run a build every time a file is saved. Currently it does not do this. Remember, Dev-C++ didn't have -j support at all until I added it. TwineCompile does do this (background compile). Therefore the IDE is providing this functionality and has nothing really do to with make or the compiler.
TwineCompile is not a plugin wrapping the -j flag. It is a separate thing entirely unique to C++Builder. It does offer integration with MSBuild though.
The second part of that was the fall off. With the 1 million size files it only ever used half of the cores and each successive round of core compiles it would use even less cores. TwineCompile didn't seem to have that problem but this post was not about TwineCompile vs. MAKE -j so I did not investigate this farther.
I was expecting MAKE/GCC to blow me away and use all 64 cores full bore until complete and it did not do this.
I didn’t go into great detail of the reasons, but the jobserver doesn’t address the problem except for the most trivial cases—the core problem is that you can’t cross to a recursive make invocation via multiple edges.
This is fairly common in larger projects, so you end up having to do some hackery to manually sequence make invocations if you want to use recursive make (which is pretty awful).
Honestly, for large projects, Make is an insane choice, notwithstanding the fact that people who are sufficiently savvy at Make can sometimes make it work. (If your tools are bad, you can make up for it with extra staff time and expertise.)
> the core problem is that you can’t cross to a recursive make invocation via multiple edges.
I’ve never had that issue, and used to heavily use recursive make. I carefully benchmarked those make files, and am sure this wasn’t an issue.
I suggest reading the paper “Recursive Make Considered Harmful” before attempting to use make for a large project. It describes a lot of anti-patterns, and better alternatives.
I’ve found every alternative to make that I’ve used to be inferior, and they almost always advertise a “killer feature” that’s a bad idea, or already handled better by make. It’s surprising how many people reimplemented make because they didn’t want to RTFM.
Anyway, the next build system on my list to check out is bazel. Some people that I’ve seen make good use of make say it’s actually an improvement.
> I’ve never had that issue, and used to heavily use recursive make. I carefully benchmarked those make files, and am sure this wasn’t an issue.
So, you’ve never had two different targets that depend on something in a subdirectory? If you’ve just solved this by building subdirectories in a specific order, or building entire subdirectories rather than the specific targets you need, what you’re really doing is making an incorrect dependency graph in order to work around make’s limitations. These kind of decisions make sense for full builds, but interfere with incremental builds.
Bazel & family (Buck, Pants, Please, etc.) are among the few build systems that solve this problem well. It’s not an accident that they all use package:target syntax for specifying targets, rather than just using a path, because this allows the build system to determine exactly which file contains the relevant build rule without having to probe the filesystem.
I would love to simply recommend Bazel but the fact is there is a bit of a barrier to entry depending on how standard / nonstandard your build rules are and depending on how you think that third-party dependencies should be pulled in. Depending on your project, you could convert to Bazel in an hour just by looking at a couple examples, or you could have to dive deep into Bazel to figure out how to do something (custom toolchains, custom rules, etc.)
As you observed, the alternatives to make are often inferior, and it’s often because they’re solving the wrong problems. For example, sticking a more complex & sophisticated scripting system in front of make.
If there’s a requirement to use an intermediate target from a subdirectory, and that’s not expressible in the parents or siblings, you could run into issues. I thought you meant it failed to parallelize multiple unrelated targets because they are in multiple subdirectories.
Anyway, the solution to that specific problem is written up in “Recursive make considered harmful”. Make handles it elegantly.
The title is kind of a spoiler, but if you’re using recursive make and care about fine grained dependencies across makefiles, you’re doing something wrong.
As an aside, I wonder if recursive make misuse is why people claim ninja is faster than make. I’ve benchmarked projects before and after, and before, make was generally using < 1% CPU vs 1000%+ for clang.
Afterwards, ninja was exploiting the same underlying parallelism in the dependency graph as make was. Thanks to Amdahl’s Law, there was no measurable speedup. The only thing I can figure is there’s some perceived lack of expressivity in make’s dependency language, or there are an absurd number of dependencies with trivial “build” steps.
My experience is that "larger projects" to the investment in their build infrastructure to maximize parallelism in order to reduce build times because it pays dividends in terms of turn around time and thus productivity.
One of the joys of working with someone who has been building large projects for a while, is that they just design the build system from the start to be as parallel as practical.
Make isn't great, but if you look at the opensource world the vast majority of the large projects are make based. The backbone of your average distro is a thin layer on top of what is mostly automake/autoconf in the individual projects. That is because while I can create a toy project that builds with make in a half dozen lines, big projects can extend it to cover those odd edge cases that break a lot of other "better" build systems. Particularity, when a project starts including a half dozen different languages.
So, while i'm not a make fan, I'm really tired of people pissing on solutions (c also comes to mind) that have been working for decades because of edge cases or problems of their own creation because they don't understand the tool.
A well understood tool is one where people know where the problems lie and work around them. Most "perfect" tools are just project crashing dragons hiding under pretty marketing of immature tooling.
> …I'm really tired of people pissing on solutions (c also comes to mind) that have been working for decades because of edge cases or problems of their own creation because they don't understand the tool.
You would have to be extraordinarily cynical to think that there’s been no progress in making better build software in the past forty years or so.
Yes, there are definitely plenty of build systems out there that were built from scratch to “fix” make without a sufficient understanding of the underlying problem. I’m not going to name any; use your imagination. But make was never that good at handling large projects to begin with, and it was never especially good at ensuring builds are correct. This is not “pissing on make”, for Chris’s sake, make is from 1976 and it’s damn amazing that it’s still useful. This is just recognizing make’s limitations, and one of those limitations is the ability for make to handle large projects well in general, specific cases notwithstanding. Part of that is performance issues, and these are tied to correctness. As projects which use make grow larger, it becomes more likely that they run into problems which either interfere with the ability to run make recursively or the ability to run make incrementally.
The “poor craftsman who blames his tools” aphorism is a nice way to summarize your thoughts about these kind of problems sometimes, and it does apply to using tools like make and C, but it’s also a poor craftsman who chooses tools poorly suited to the task.
It may be a Windows thing. I too started reading the post and was thinking, why not -j128 or -j64 depending on if HT was on and then realized that the author's system wasn't one that had been tuned for decades to build software as quickly as possible :-).
It would be an interesting academic exercise to create a setup on Linux that did the same thing but using the extant build tools, and then to do a deep dive into how much of the computer was actually compiling code and how much of it was running the machinery of the OS/IDE/Linkages. A LONG time ago we used to do that at Sun to profile the "efficiency" of a machine in order to maximize the work it did for the user per unit time, vs other things. That sort of activity however became less of a priority as the CPUs literally became 1000x faster.
We're running our builds and tests on both Windows 10 and Linux. At least for Windows 7, the compiler start up time had a huge impact on total run time. I think back then we had 2500 tests, each compiled, then linked, and then dwarfdumped and then some more tools (we build a compiler). We moved some stuff to Linux (eg dwarfdump) and saved a few program executions by compiling & linking single c file tests in one step (yeah, the driver still calls everything, but the driver is called once less). I was under the impression Windows 10 improved on that (we didn't benchmark in detail since then, since it's still far enough), but on Linux I don't have to bat an eye on eg make -j32.
BTW, the author messed up anyway. Make -j does schedule everything at once. How do I know? Only way I got my private 128GB build host to oom...
Because you included a third-party project into your build which is not compatible with your build system and you don't want to rewrite all their ninjafiles into makefiles to match.
Someone should really formalize a standard for declaring dependencies which build systems can share between each other.
A “standard for declaring dependencies” is, itself, a build system without the execution engine. The execution engine is not actually the hard part about making a build system. So, what you’re asking for is really just a standardized build system.
Because it can be hard to maintain non-recursive make systems for large projects. Just because recursive make is discouraged does not mean that the alternative is without its own drawbacks.
Yeah, I would say this title is a little misleading. The example doesn't use any of the C++ features that cause long compile times, like templates and the STL.
Seems like he tried more complex examples too, but ran into roadblocks like a 2GB limit on executables and running into a commandline length limit restriction that dates back to early DOS days which made it impossible to link.
Both of those problems seemed solvable if he was willing to chunk up his application into libraries, maybe 1024 files per library then linked to the main application.
I believe this is one of the reasons for object libraries (or archives, the foo.a files on linux/unix), you can then link in all of the object files from one of those at link time without having to list them all at once. That won't get past the 2GB limit on executables but it will get past the command line length.
I was going to suggest that, but he's running on Windows and I don't know if they are supported there. I guess they probably are since they're a compiler feature.
That article mentioned Delphi and Object Pascal, and it brought back many fond memories. I absolutely LOVED Delphi and Object Pascal back in the day. So clean and so fun to program in. If Borland hadn't f-ed it up and had stayed around until now, I'd be the biggest Delphi fanboy.
Alas, that was not to be. Modern languages are fun and all, but not Delphi-back-in-the-day level fun :-).
2 actively maintained version of Delphi still exist, the original one maintained by Embarcadero, and an open-source one available at https://www.lazarus-ide.org/ .
After liking this article, I wanted to check out others on the site, and am shocked at the terrible usability of their front page. I can't finish reading the titles of their articles before the page just keeps moving things around on me. It is so frustrating, which is unfortunate because I would otherwise have been interested to see more of their content. Experience completely ruined by awful design judgment.
>"Concretely speaking, I wanted to use the linker to link a Chromium executable with full debug info (~2 GiB in size) just in 1 second. LLVM's lld, the fastest open-source linker which I originally created a few years ago, takes about 12 seconds to link Chromium on my machine. So the goal is 12x performance bump over lld. Compared to GNU gold, it's more than 50x."
Lucky sons of gun. We are stuck with Xeons. Have to wait 3 hours for our 20M C/C++ on the 2x14cores Xeon machine after a pull/rebase. Ryzen/TR would probably be faster 2-3x times for the same money, yet it is a BigCo, so no such luck (and our product is certified only for Xeons, so our customers can't run AMD too - thus we're de-facto part of the Great Enterprise Wall blocking AMD from on-premise datacenter).
Industrial software will always grow in size to use all available compilation time ... I have seen large Xeon distcc farms and the total build walltime was still measured in hours...
This shows that if you are making a not-very-fast compiler (most compilers these days), then the much maligned C compilation model has some serious advantages on modern and future hardware, due to its embarrassingly parallell nature.
Great read. I wonder if the make -j modification wasn’t scaling things across all cores because it was using the physical core count (number of cores) versus the logical core count (number of core threads).
Or perhaps the code wasn’t modified to spread the work across all processor core groups (a Windows thing to support more than 64 logical cores).
Does anyone have reviews of this on their JS test suite. The quicker the tests run the better my life, I have around 2000 quite slow tests... 76s MacBook 15” 2016, 30s M1 Apple Silicon Mac Mini, what should I expect with loads more cores like this?
Great article but for the love of god don't use Passmark. They are extremely bad on AMD scores. Now this is luckily two CPU's from AMD so it isn't bad but it is a bad comparison site as they heavily favour Intel.
Hahaha, fuck me, CPUs are fast. That's wicked. 15 mins. A billion lines of C. Insane. Wonder if there's some IO speed to be gained from ramdisking the inputs.
It is pointed out that the threadripper does worse per core when under full load than even high core count consumer CPUs like the 3950x/5950x. That's the tradeoff you make for huge core count CPUs. 4x 3950x might do better, but then you need to build 3 other PCs, and for actual processing tasks, co-ordinate stuff to run across multiple systems.
Lots of single-pass compilers can achieve 1MLOC/s. But the main problem is that C++ has an O(n^2) compilation model due to header explosion. Also, expanding C++ templates is very computationally intensive.
TCC is fast enough that you can recompile the kernel every time you boot up.
I remember playing with TCC-boot back in 2015, and on a relatively beefy machine at the time I could compile the kernel in 5 seconds (or about 37mb/s iirc).
I can build the D compiler (500k lines?) Warts and all in a second in my machine - and that's code that's not particularly complicated, but not at all optimized for compile times realistically.
To be fair, due to the fact that DMD can't depend on phobos it doesn't use a lot of the features that end up making D compiles slow, like lambdas and deep metaprogramming. DMD is in a way one of the least representative examples of a large D project.
V8 is a JIT compiler, which has a baseline interpreter and progressive optimization. It's not surprising that interpreters have fast startup time. (Hotspot is the primary exception in this case, but a big part of its slowdown comes from the fact that it verifies bytecode before loading it.)
Bytecode verification is not a large part of compilation time for Java. For HotSpot server, verification is dwarfed by building the IR, repeatedly walking and transforming it, generating code, and register allocation. Keep in mind that HotSpot will very likely inline a ton of methods, making the compilation unit large. Many passes are at least slightly superlinear, so that makes compilation time explode.
That said, I ported C1 (the client compiler) to Java back in my Maxine VM days, about 2009. At that time on typical x86 processors it was easily hitting 1.8MB/s (of bytecode) compilation time. You can work backward to how many lines of code a second that is (and sure, you aren't paying the cost of the frontend), but yeah, that is in the ballpark for 1MLOC/s I think. And that's with an optimizing compiler with IR and regalloc!
I wonder if it’d be possible / useful to implement a rust or C compiler that worked that way. Basically instant startup time after a code change is a delightful feature.
I've been bandying around ideas lately for an extremely fast c compiler that, among other things, caches machine code for individual function declarations. You wouldn't realistically be able to get to the level of speed as js, though, because js is a dynamic language. With a statically typed language like c or rust, any time you change a declaration, you have to re-typecheck everything that depends on that declaration. (Though you can frequently avoid generating new code, if you implement structs using hashtable semantics.) Both languages also have a concept of compile-time evaluation, and rust in particular has to deal with template expansion (which is not trivial, I hear they use an SMT solver for it now).
Strictly speaking, Rust doesn't have templates, or "template expansion", but there is a thing called "trait resolution" which does take effort to solve, that is related but not the same thing as what C++ calls "template expansion."
That sounds like a fun idea! I've been toying with the idea for years of having a fully incremental compiler - basically caching the dependency DAG of code compilation. "This function, depends on the definition of this struct, which in turn depend on these typedefs and this other struct..."
Then I can imagine a compiler which takes the DAG from the previous compilation and information about which lines of code have changed, and can figure out which intermediate compilation results need to be recomputed. And the result would be a set of blocks which change - globals and symbol table entries and function definitions. And then you could implement a linker in a sort of similar way - consuming the delta + information about the previous compilation run to figure out where and how to patch the executable from the previous compilation run.
The end result would be a compiler which should only need to do work proportional to how much machine code is effected by a change. So if you're working on chromium and you change one function in a cpp file, the incremental compilation should be instant. (Since it would only need to recompile that function, patch the binary with the change and update some jmp addresses. It would still be slow if you changed a struct thats used all over the place - but it wouldn't need to recompile every line of code that transitively includes that header, like we do right now.
You just need more ram. I 'ever compile at less than -j$(ncpu). Hard with less than 32 GB tho - a single clang instance can easily eat upwards of 1gb of ram
Aha, I only compile on ARM so I got no room to increase RAM...
Is it the same with g++? I have 4GB so I should be able to compile with 4 cores, but the processes only fill 2-3 cores even when I try make -j8 on a 8 core machine and then locks the entire OS until it craps out?!
Why are you compiling on ARM with only 4GB RAM? Wouldn't it make more sense to cross compile from a machine with more resources, if you cared about build speed? (maybe there's a good reason not to do that, idk)
If it's crapping out when you give it -j8, that seems to strongly suggest you're running into limited resources somewhere.
I'm no expert in the intricacies of parallel builds, but as far as I know you can still have dependencies between targets that will limit parallelism.
This is just a low end/uncommon hardware problem. I typically do make -j16 on a 4 core x86 system and it just works. You are probably running out of ram and the swapping resulting in that instability.
if you are in 32-bits you could still have trouble in the future though.
source: two days ago I had the exact same problem, so I mounted a 32gb swap file over an NFS drive because my SD card was 2gb (don't ask) and it still failed because ld tried to use more than 4gigs of ram
It is a good thing that Embarcadero is keeping alive this technology to create desktop apps from the early 2000s that was abandoned by MS and other large companies in favor of complex Web-based apps.
If you mean wrapping native widgets, this wouldn't solve much - you would still need some language to take care of the logic, like a JavaScript engine. At this point just using Electron is simply easier for devs, and as much as we hate it, realistically speaking it's still better than nothing.
How many times are they going to repeat the search phrases like "one billion lines"? It's reached the point where SEO obstructs human readability. It was cool that Object Pascal (maybe a descendant of Turbo Pascal) compiled 1e9 lines of Pascal in 5 minutes on the 64 core box. Scrolling way through the article, it looks like they had enough trouble setting up their parallel Windows C++ build environment on 64 cores that they ended up running 4 instances on 16 cores each, and splitting the source files among the instances. The build then took about 15 minutes on 64 cores, which is faster than I'd have expected.
This all seems kind of pointless since distributed C++ compilation has been a thing for decades, so they could have used a cluster of Ryzens instead of "zowie look at our huge expensive single box".
{kind=link}
The more pedestrian 5950X or the now bargain 3950X are great for anyone doing a lot of compiling. With the right motherboard they even have ECC RAM support. Game changer for workstations in the $1000–$2000 range.
The more expensive Threadripper parts really shine when memory bandwidth becomes a bottleneck. In my experience, compiling code hasn’t been very memory bandwidth limited. However, some of my simulation tools don’t benefit much going from 8 to 16 cores with regular Ryzen CPUs because they’re memory constrained. Threadripper has much higher memory bandwidth.