This problem is known as "attribution" - you have a "no" or "without" in the sentence, but you don't know where it belongs. One could (and one does) argue that the problem cannot be solved with statistical methods (ML), especially not in any domain where accuracy is required, such as medical recored analysis: "no evidence of cancer" and "evidence of no cancer" are very different things.
Zooming out, the language field breaks into several subfields:
- A large group of Chomsky followers in academia are all about logical rules but very little in the way of algorithmic applicability, or even interest in such.
- A large and well-funded group of ML practitioners, with a lot of algorithmic applicability, but arguably very shallow model of the language fails in cases like attribution. Neural networks might yet show improvement, but apparently didn't in this case.
- A small and poorly funded group of "comp ling", attempting to create formalisms (e.g. HPSG) that are still machine-verifiable, and even generative. My girlfriends is doing PhD in this area, in particular dealing with modeling WH questions, so I get some glimpse into it; it's a pity the field is not seeing more interest (and funding).
I guess, even in the original results, the problem is not really that Google search was not understanding the meaning of the search term (which is possible with today's models). Rather, it was a bit confused about what you are really searching for here. Maybe a comparison of shirts with and without stripes? The search query was just unusual, and it is not too unreasonable to guess that the query was not meant literally. At least this is a valid possibility, that the query was not meant literally. So it is reasonable to just return some results which might be related to the query, which will also be shirts with stripes.
If you argue this is bad behavior: Maybe we need a web query which really only takes the query literally. Putting the query in quotes will not quite have this effect for Google. Maybe some other syntax?
> the problem is not really that Google search was not understanding the meaning of the search term (...) Rather, it was a bit confused about what you are really searching for here. Maybe a comparison of shirts with and without stripes?
In this very specific case I don't buy it. Sure, it probably applies for other queries, but if you approach a salesperson and ask him for "shirts without stripes" it's pretty clear what you want, and he wont bring you any piece with stripes on it.
To be fair, the first and last query would also confuse me if someone asked me for that item. "Shirt without paisley" feels a bit like "cereal without elephants." You don't usually explicitly exclude an element that is relatively uncommon.
It's not just the way this is phrased, it's that there is no English-language formulation that works at all. Swap "shirt" for "tie", because paisley is quite common on ties. Now, try:
* tie without paisley
* tie not paisley
* non-paisley ties
* ties that aren't paisley
* ties other than paisley
You guessed it, in each case, at least half of the results are paisley ties. The only way to actually get what you want -- the set described by X, minus the set described by Y -- is to use the exclusion operator in the search, "ties -paisley".
This is great, and makes intuitive sense to somebody with multiple computer science degrees. But not only is it hard to explain to an outsider, it's actually quite hard to get them to think in a way that accommodates this capability, that is, in terms of set theory.
I don't agree. Paisley is a well-known pattern type and some people really dislike it. "Shirt without paisley" is not a common request but its meaning is clear (if you do an image search for paisley you get lots of fabric images, so it's not like search engines don't know it.) I'd say the same for "shirt without red buttons." In general the pattern <article of clothing> without <feature> shouldn't be that difficult for search engines---especially since many are tuned for consumers.
observations; firstly one can assume that google search can do no wrong. second observation is google search is made for noobs. thirdly you broke it because you are not a noob. 4th this will not be fixed because of said non-noob status.
And that's exactly what I mean to connote, text matches make for appalling search.
I have the same reservations about Google as anyone, but rewriting history is never the right move. Moving beyond text matching was what made search truly useful.
> Moving beyond text matching was
> what made search truly useful.
PageRank is what made Google more useful than its competition. They had it since the beginning, and I like it.
What I don't like is to search for the band "Chrisma" and get results for "fruitcake sale!" because Google corrected my spelling to "Christmas", decided to look for related concepts, and then boost whichever result is the most mercantile.
Yes, they have. Read what I said again, I don't dispute this. What Google does now is an improvement over text matchers. I never claimed that what they do now is better than Google circa 2000 (though I don't care to register an opinion either way on that).
Whatever they've done since, their product remains better than text matchers. Mercantile search is better than terrible search.
Google is in the business of producing quick results to sell ads while keeping the cost low. If anyone does better, they will likely do it using a costlier algorithm, and if there is more margin in reselling tangible products than ads then Amazon is incentivized to use costlier algorithms that are more accurate. But I think the margin in both cases does not justify the use of algorithms that may be more accurate in some small percentage of cases but a lot more costly.
animalCrax0rx is in the business of producing quick pithy posts to earn more karma while keeping understanding low and making claims that are not evidence based...
See how that works? That's not really what's going on. Sure, G. is incentivized to include pages quickly, but they are also incentivized to produce them accurately, and as the above poster indicates, this is quite a hard problem to solve generally.
A is also incentivized to sell items.
In many cases different algorithms will lead to quantifiably different results. The algorithm changes that work better for the measurement set will be kept and those changes which dont will be discarded. And both A and G do that within different constraints.
My cursor was hovering over the downvote arrow while reading your first sentence, before I realized what was going on in your post. Thank you for pleasantly surprising me!
Google is aware of this problem in their search approach. It's a business problem, not a technical one. You're saying the same thing in suggesting they base their decisions on some measurement set. If solving the problem adds complexity, which it certainly will, and there is not enough improvement in accuracy for the majority of cases in their measurement set, why bother? You sound like the kind of person that attacks people for their opinion. So weird, dude.
Your ad hominem on the other poster is unnecessary, violates the HN guidelines and not an apt comparison.
Pointing out the obvious: Google is an advertising company. If the cost of producing an accurate result outweighs the advertising income on a given term, there is no incentive for Google to produce better results.
This would predict that a query that has no advertising income will return no results, which is clearly not the case.
Having a search engine that people go to whenever they want to search for things is incredibly valuable, because they will come to you when they want to buy things and you can sell ads. But unless you consistently give the best results for all queries, people will go whenever does. It's worth investing strongly in all queries, not just highly monetizable ones.
(Disclosure: I work for Google, speaking only for myself)
> This would predict that a query that has no advertising income will return no results, which is clearly not the case.
I was about to say there are no such queries but then I remembered having to type a captcha for seemingly automated queries. The captcha page has no results on it obviously. This is because automated queries do not produce advertising revenue. You have to buy them.
I've typed an insane number of queries since the beginning. A decade ago I use to be able to find truly exotic articles, I could find every obscure blog posting on every blog with 3 readers and I was pretty sure google delivered all of it. The tiny communities that came with the supper niche topics rarely produced a link I didn't already find. If they did it was new and I didn't google for a while.
Today google feels like it is a pre-ordered list from which it removes the least matching articles. Only if the match is truly shit will it be moved slightly down the page. The most convincing in this is typing first name + last name queries in imagines and getting celeberties who only have the first or the last name.
People wont go, it has to get much worse before they do.
edit:
With humans an pets a good slap over the head or a firm NO! will usually do the trick.
There are very clearly many queries with no advertising revenue, because there are many queries that show no ads. Trying some searches off the top of my head that I expected wouldn't have ads, I don't get any ads on [cabbage], [who is the president], [3+5], or [why is the sky blue]. On the other hand, if I search for a highly commercial query like [mesothelioma] the first four results are ads.
> A decade ago I use to be able to find truly exotic articles, I could find every obscure blog posting on every blog with 3 readers
My model of what happened is that SEO got a lot better. When Google first came out it was amazing because Page Rank was able to identify implicit ranking information in pages. Once it's valuable to have lots of backlinks, though, this gets heavily gamed. Staying ahead of efforts to game the algorithm is really hard, and I think a lot of times people's experience of a better search engine comes from a time when SEO was much less sophisticated.
> The most convincing in this is typing first name + last name queries in imagines and getting celebrities who only have the first or the last name.
This hasn't been my experience, so I tried an image search for [tom cruise], curious if I would get other Toms. The first 45 responses were all of the celebrity, and image 46 was of Glen Powell in https://helenair.com/people/tom-cruise-helps-glen-powell-lea... which is a different kind of mistake. Do you remember what query you were seeing this on?
> This hasn't been my experience, so I tried an image search for [tom cruise]
I believe what he means is that searching for first name + last name of someone who isn’t a celebrity gets you celebrities who match either the first name or last name.
Searching for Tim Cruise blankets you with pictures of Tom Cruise, but it at least says “Showing results for tom cruise“ so you know it did an autocorrect. When I tried other first names + Cruise, the effect is less pronounced than with the Neeson example. Maybe it’s because cruise is a more common name as well as an English word.
Thanks for clearly articulating what many people on HN seem to fail to grasp. It’s not that Google got worse over the years at surfacing the obscure content they used to so easily find. That obscure content has gotten completely buried under the mountain of content being published every day, and the cat and mouse game of SEO has evolved so rapidly that the problem space of generalized search is so much harder these days than it was 10-15 years ago. Not to mention the broader user base that they have to serve as well.
It is the same thing! The mistake is obvious. For-profit content is prioritized. Google is the driving force behind the for-profit internet but sadly for google: you cant do organic ranking on commerce. ahhhh The index is now a [very limited] snapshot of the glory days.
You don't have to bother creating anything new unless you have something to sell and are willing to invest (big).
Facebook is actually a pretty pathetic implementation where we can still find content created by normal people. If people made traditional websites in stead of facebook groups and facebook pages NO ONE would be able to find it.
We've witnessed the great obliteration of what was once a nice place and now we have to hear google was not to blame?? The death by a thousand cuts is actually well documented.
We tell you what your site must look like or we'll gut it:
https://en.wikipedia.org/wiki/Google_PenguinGoogle Penguin is a codename[1] for a Google algorithm
update that was first announced on April 24, 2012. The update was aimed at decreasing search engine rankings of websites that violate Google's Webmaster Guidelines[2]
There, this is what the entire internet must look like. We went from indexing to engineering here.
We recommend marking user-generated content (UGC) links, such as comments and forum posts, as ugc.
If you want to recognize and reward trustworthy contributors, you might remove this attribute from links posted by members or users who have consistently made high-quality contributions over time. Read more about avoiding comment spam.
Before this those elaborately contributing got actual credit for it. Do you think you got a choice in it? Google clearly demands you ban credit for comments. OR ELSE!
rel="nofollow"
Use the nofollow value when other values don't apply, and you'd rather Google not associate your site with, or crawl the linked page from, your site. (For links within your own site, use robots.txt, as described below.)
Woah association! How did we go from linking-to to association? It was important enough for readers but be careful to hide it from google. Such little unimportant websites simply shouldn't exist in our index. We command you to help keep our index clean of such filth!
Then the magical: We wont actually tell you what is wrong with your website! Ferengi Rule of Acquisition 39 "Don't tell customers more than they need to know." Get a budget and hire someone to do SEO. Deal with it, we don't care. No, you don't have any feedback.
> There are very clearly many queries with no advertising revenue, because there are many queries that show no ads.
Queries without ads do produce revenue. They are an essential part of the formula.
Think of people standing around in bars. We cant argue that just standing there doesn't produce revenue.
The flowers on the table in a restaurant produce revenue.
Free parking produces revenue.
If queries without adds didn't produce revenue they wouldn't exist. More often enough it doesn't even take an extra query, the adds will sit behind the links.
I don't think we disagree? Above I wrote: "Having a search engine that people go to whenever they want to search for things is incredibly valuable, because they will come to you when they want to buy things and you can sell ads."
This is pointless overcomplicating. I might agree if the example would be slightly more interesting, but "without stripes" isn't even "absence of <stripes>", it is essentially a colour/pattern and can be easily attributed to a range of things exactly the same way "green" can be. Google translate correctly associates much more dubious and abstract concepts than that, and does it with statistical methods, i.e. associating word combinations with a location in a vector space. The fact all major search engines fail to do it here is just shameful. Especially Amazon, where it is pretty much a primary search function.
Something like: build an representation of the text that's language independent and integrated in other knowledge domains, and predict the receiver's reaction to a verbalization of a representation.
But it isn't necessary to formalize any of it. At the current level of sophistication, our informal common ground of words like "understanding" suffice for a discussion. It's obvious Google Translate doesn't resemble human language processing.
A shirt is an item of clothing. Items of clothing are made from material. Some materials have patterns. One type of pattern is stripes.
Seems like a matter for logical inference. At which point it becomes fairly easy to find shirts made from material where that materials pattern is not stripes.
But yes, no AI I have seen works reliably on even basic queries like this.
What you've described is not simple logical inference, it is logical inference from common sense knowledge. This is an extremely hard problem, much harder than solving attribution in such simple cases.
Most likely, common sense reasoning will be required to get full natural language processing, since human communication relies extremely often on such reasoning. But building a knowledge base of common sense facts will be one of the hardest challenges ever attempted in machine learning/artificial intelligence.
Exactly. But it was already not showing you the weather before you said anything. The query stymies shallow parses NLP assistants do, but isn't one you would actually give in real life.
> This problem is known as "attribution" - you have a "no" or "without" in the sentence, but you don't know where it belongs. One could (and one does) argue that the problem cannot be solved with statistical methods (ML), especially not in any domain where accuracy is required, such as medical recored analysis: "no evidence of cancer" and "evidence of no cancer" are very different things.
Couldn't you just parse the sentence into a dependency tree and look at the relationships to figure that out? CoreNLP got both of your examples right (try it at http://nlp.stanford.edu:8080/corenlp/process, can't link the result directly).
You've solved the problem of accuracy, but you've now introduced a huge recall problem. Your query will never find a page advertising 'the best shirts without stripes', as it contains the word 'stripes'.
To be useful, Google must solve natural language problems. You can't solve natural language problems by using formal language in sine bits of the problem, at least not until we have a full Chomsky-style understanding of the whole of human language.
English is fine, googling for "stripeless shirt" works well enough. The question "shirt without stripes" is begging us to ask is whether we might want to reevaluate projections of imminent AI takeover.
It does, if you're running a search engine for a general audience. the `-` operator is useful, but it's almost an admission of defeat: what most users want is to be able to describe what they're looking for in reasonable english and get relevant results back. Having `-` for advanced users is useful, but it's not friendly to the majority of users.
> you have a "no" or "without" in the sentence, but you don't know where it belongs
Well, one could argue, that it belongs exactly where anyone entering the query put it. Before "stripes".
The problem is often, that search engines try to be too clever, while not offering any kind of switch "exactly those words in this order" and that is just a bad user interface.
I am little surprised with this result. When I worked on similar products we constantly look at our query stream, sorted the high volume queries and manually intervened to present better results to our users.
I will not be surprised millions of dollars are being lost because of this substandard query result per year.
If the problem is that it didn't know where to apply the without, then why does it show me results from only a single entity? I would prefer so see an interleaved set of results containing all ambiguous entities.
I think that given the complexity of the problem they don't even try to parse the sentence and do attribution - they just shotgun with ML and hope for the best.
There is this, too, from 4 years ago, which seems reasonable in my not-very-well-informed opinion (speaking of which, I'm not sure the work referenced here can deal with hyphenated negation, but it should be simple to include)
As someone else said you don't know that's wrong for what Amazon are optimising. If they find people [with your background profile] who buy shirts are susceptible to buying sweatpants, they might also find that if the seed you with "sweatpants" as an idea up front that the repeated presentation of sweatpants in "people who bought X also bought Y" sections is more effective.
That's the sort of thing I'd expect Amazon to be doing?
I think if you were visiting a personal tailor, or perhaps talking to a shop assistant, you might get something akin to that.
T: I think pink would look good on you, and it's very fashionable right now.
You: Just bring me some yellow shirts to try.
T: Oh, I got these, and brought this pink one anyway; try it!
But, of course Google isn't making fashion suggestions. But then, ... the tailor might also be just trying to shift excess stock or be on a bonus for selling that particular high-cost shirt.
To be blunt: My personal tailor’s first response should be to do what I asked.
They can certainly also bring some stock to shift, or offer suggestions while I’m trying something on, but if they aren’t listening when I make a direct request or when I clearly say no, then they aren’t really there for me, their customer.
Tbh, I feel like the underpinning “problem” is that more and more these marketplaces are optimizing for what they want to sell, and seeming to ignore blatant requests.
I’m an odd one that I already know specifically what I want to buy before I search for it, but I’m certainly not the only one (and I think everyone has done that at least once).
This doesn't seem like you need fancy linguistics ML to fix. You take 90s-era search engine tech and add a database of attributes about every kind of product there is, and take a guess at whether "without" is a search term, a search result modifier, or a filter for an attribute of a product. When you display the results, simply ask the user if that was right; if it wasn't, ask them if they preferred the other filter method. Use those responses as a corpus to train the algorithm.
I mean, context is key, right? You're on Amazon and your first search term is "shirts". Unless their is a band called "shirts without stripes", the user wants shirts. The rest of the query is probably some filter of that product. You know shirts sometimes have stripes. It's not a one-size-fits-all algorithm, but it's simple enough that the user should end up with the results they wanted.
I think you’re mystifying a lot of people in this thread! Can you add to your explanation why it’s hard for ML to associate the negation with “stripes”? It seems easy: language => English, in English “without” modifies following phrase, not preceding.
You need to actually build up noun comprehension though, because "evidence of no remaining cancer" or other qualifier words can greatly confuse the situation.
You'd also have quite a bit of fun trying to parse the phrase "no means no" or other usages where "no" is being used as a noun... And for bonus points, folks talk to search engines in broken english all the time so "shirts no single striped" is a totally reasonable query to submit to a server and expect to be parse-able.
I don't know the usage stats on AskJeeves but that search engine specifically purported itself to do well when asked a question in english. Now, the tech at the time wasn't even near close to being able to support it, but their advertising targeted it. That all said I never typed in "Who is Derek Jeter?" and I don't know anyone who did.
I think the basic issue is that people just don't respect machines and want to minimize the amount of effort spend on communicating with them - I don't say "Alexa please bring up songs by Death Grips if you don't mind" I shout "Alexa! Play! Death Grips!" and then yell at it when it misunderstands.
That's an excellent example to show why statistical NLP outperforms discrete parsing using logical rules. That A1 and A2 means the same is something that is clear to us from the context. This is something a continuous vector space model can capture and a discrete rules based model cannot.
While this is indeed an example of the attribution problem, I'd argue that this particular query will never be solved. I don't search for a "shirt without stripes", I search for a "solid <insert color here> shirt, or a "<insert color here> hawai'ian shirt".
I'd be curious to see how many sentences with attribution problems actually have other structural issues. If I want to write clearly and without ambiguity, I rewrite sentences that have these problems. Why wouldn't I do the same for search queries?
I don't think this particular problem is related to the language model. "[item] without [attribute]" is trivial to understand even without a sophisticated language model.
The bad results are because they're not positively indexing the absense of the feature by deeply analyzing the images or products beyond the descriptions. "Shirt with stripes" yields almost exclusively striped shirts. Exclude those results from all "shirts" and there are still a lot of striped shirts that the search algorithm doesn't know enough to exclude.
Because there aren't two kinds of shirt, striped or solid coloured. You even acknowledge that by mentioning Hawai'ian shirts. You might want a small check shirt, a mostly plain shirt but not mind logos so not completely monocolour, a plaid shirt, a large check lumberjack style, spotted or dotted or diamond pattern, flowery pattern, you might not even know what the other available options are to search for them one by one - you just know that you don't want stripes.
There is no ambiguity in "not stripes", you can't invert it and write it in the positive form of what you want; the neatest way to describe the category of what you want to browse is "things which are not stripey".
Particular personal bugbear is car websites where you can filter in "petrol engine" or "diesel engine", but there is no support for negative filtering, so you can't choose "not LPG". In so many search-and-filter options you can't exclude your dealbreakers, and it's much more likely that I have a single dealbreaker which rejects a choice overriding all other considerations, than that I have a single dealmaker which makes a choice overriding all else.
To be clear (for the benefit of anyone else who reads this), the windows in the Seattle Tower are made of glass, but the exterior of the building is not that modern all-glass-and-steel look[1]. This is a third interpretation of non-glass I hadn't thought of and it took me a minute to figure it out.
"non-glass skyscraper":
1. No glass used in the exterior construction at all -> implying no windows
2. No glass used in the exterior construction at all -> implying the windows are made out of something other than glass
3. A skyscraper in which glass is not a prominent architectural feature, but the building does contain features like windows and doors that contain glass. (This comment)
Yo seem to think that queries of this form are ambiguous, but they are not. Given the set of shirts, and that the subset of 'shirts with stripes' is well-defined (which you apparently accept, given that you seem to think that 'shirts with stripes' is an unambiguous query (which it is)), then its complement is well-defined; there is no 'Russell's Barber' paradox here, as there is no self-reference.
>If I want to write clearly and without ambiguity, I rewrite sentences that have these problems. Why wouldn't I do the same for search queries?
Ok, so imagine one online retailer follows your advice and expect the users to write clear and unambiguous queries, while another retailer puts extra effort into attribution.
Great question, but with potentially nonintuitive results.
A sales gimmick furniture store would use in the past was to offer customers a free gallon on ice cream for visiting the store. The value was to the store offering the promotion, as shoppers would be drawn to the "free" gift, but on receiving the ice cream -- too much to eat directly. -- would then have to go home to put the dessert in the freezer. And have less time to comparison shop at competing merchant's stores. Given limited shopping time (usually a weekend activity), this is an effective resource exhaustion attack.
Similar tricks to tie up time, patience, or cognitive reserve are common in sales. For a dominant vendor, tweaking the hassle factor of a site so long as defection rates are low could well be a net positive, if it makes the likelihood of a visitor going to other sites lower.
Still I insist that business serving up more relevant search results for loosely phrased queries will make more money than the one relying on the user to formulate perfect queries.
The original "confusopoly" link talked almost exclusively about pricing, and for good reason: pricing is based on numbers, which humans are bad at but computers are very good at, and every product in the catalog has a price, so it's easy to take the same tactic and apply it to all of the products.
I'm not sure trying to confuse people about whether a shirt has stripes on it would make as much sense. The purchaser seems likely to give up on picking an ideal shirt and just go with the cheapest result.
I thought I'd written on a more comparable gripe similar to the "shirt without stripes" problem in online commerce, the confusopoly item was the closest I could find readily. (Other is likely among my G+ take-out.)
Both though have the same essence: a manifestly confusing and annoying interface may be serving the merchant's interests.
See also Ling's Cars, possibly explaining awful Web design:
Just because they've implemented something that helps in a certain area doesn't mean they'll always get it right.
I think you'd struggle to find anywhere Google claims to "understand everything", making your assertion a strawman.
Literally in the article you're quoting from Google:
> But you’ll still stump Google from time to time. Even with BERT, we don’t always get it right. If you search for “what state is south of Nebraska,” BERT’s best guess is a community called “South Nebraska.” (If you've got a feeling it's not in Kansas, you're right.)
"So that’s a lot of technical details, but what does it all mean for you? Well, by applying BERT models to both ranking and featured snippets in Search, we’re able to do a much better job helping you find useful information. In fact, when it comes to ranking results, BERT will help Search better understand one in 10 searches in the U.S. in English, and we’ll bring this to more languages and locales over time.
"Particularly for longer, more conversational queries, or searches where prepositions like “for” and “to” matter a lot to the meaning, Search will be able to understand the context of the words in your query. You can search in a way that feels natural for you.
...
"No matter what you’re looking for, or what language you speak, we hope you’re able to let go of some of your keyword-ese and search in a way that feels natural for you. But you’ll still stump Google from time to time. Even with BERT, we don’t always get it right. If you search for “what state is south of Nebraska,” BERT’s best guess is a community called “South Nebraska.” (If you've got a feeling it's not in Kansas, you're right.)
"Language understanding remains an ongoing challenge, and it keeps us motivated to continue to improve Search. We’re always getting better and working to find the meaning in-- and most helpful information for-- every query you send our way."
OK, but what if an Amazon algorithm has actually learned that people who search for "shirt without stripes" are more likely to buy more things if the first image they see is a picture of a striped shirt?
The original version of which talks of an "Invisible hand" and if that's not an metaphor for divine intervention hidden by an chaotic system i don't know what is.
It's rather surprising how often almost all complex systems theories be it AI, cosmology or economics have an aspects where even the theorists are resorting "to because it is".
Sometimes those statements are based on measured data but it's not always easy or possible to do so accurately for highly interconnected system or worse system where you have actors reacting to theoretical model in a way that changes how the system behaves.
in that case the applied AI stops being a Search tool (as was the purpose of the search bar) and becomes a new Ad tool. And this masquerading is not a great thing at all, for the same reason why people don't like bots pretending being humans during phone calls.
But it’s not a search tool. It’s a make Amazon money tool, as all their tools are. I think you misunderstand why amazon build these tools if you think they are to make your life easier in trying to locate things to buy on their site. That’s a happy coincidence. They build them to make money.
I don't think it violates the efficient markets hypothesis. I think that entails "if it was possible for someone to create an AI that would make more money by showing something else, the AI would be showing something else." Roughly, efficiency means that the most profitable solution will be the one that wins out, but "profitability" includes the costs of building such an advanced system, assuming that it's possible at all.
I think it's more likely that they've A/B tested faulty algorithms and picked the one that's the least faulty.
I don't have proof, but I strongly believe that a search algorithm that returns what a customer is actually searching for will drive more sales. I suppose it's possible that with time, consistently bad results will beat a customer into submission and drive more sales of stuff the customer doesn't want. But I don't believe that's true, and this would only be the case if the customer accepts that the thing they want doesn't exist. If the customer is pretty sure that solid color shirts exist, they'll just shop elsewhere until they find it.
It's a tricky balance between sales and relevance. If you don't watch for relevance you will end up showing only booze and porn in the commerce search results, border-line-porn in video search (true story), and so on.
Then the algorithm would not be acting in the customer's interests.
Presumably this would be after the algo devalued people who clicked on "Next Page" until they came to a page that had stripeless shirts on it, or who, after the search, only ever clicked on stripeless shirts. "Deeds not words," dontchaknow.
The fact they put some disclaimer after bragging doesn't discredit the point of the author who says those companies brag with AI but still fail to fulfil basic queries.
The point that the author is making, in a very understated way, is that all three companies have PR websites that breathlessly describe their advanced AI capabilities, yet they cannot understand a very simple query that young children can.
One can play this game a lot and most results will return expected cultural biased results. A "kind person" is apparently a white girl. A "good person", a white woman. A "bad person", white men. A "evil person", white men. A "honest person", equal mix of white women and white men. "Dishonest person", white men in suits. "Generous person", hands of white women. "Happy person", women of color. "Unhappy person", old white men. "Criminal person", Hispanic men. "Insane person", white men. "Sane person", white women.
Is it surprising that very few of the result surprises me?
Yes. If I had the energy and time to do a proper researched data set I would have a bot search through the top 100 common words associated with either warmth (sociability and morality) or competence, and then use a facial recognition system go through the first 100 images of each to determine the distribution of gender, age and skin color.
Following the stereotype content model theory I would likely get a pretty decent prediction of what kind of culture and group perspective produced the data. You could also rerun the experiment in different locations to see if it differ.
FWIW, this is most likely not a bias of the search engine, but just a reflection of its sources (mostly stock image platforms I suppose). So if most stock images of blue trolls would be labelled with "politician", you'd eventually find blue trolls when searching for "politician".
Yes. I thought about words people use in priming studies, usually in order to trigger a behavior, and just typed the word with space and "person" appended.
I did use images.google.se in order to tell google which country I wanted my bias from since that is the culture and demographics I am most familiar with. I also only looked at photos of a person and ignored emojis.
I have also seen here on HN links to websites that have captured screen shots of word association from google images and published them so you could click a word see the screen shot. They tend to follow the same line as above, but with some subtle differences, and I suspect that is the country culture being just a bit different to mine.
You really should link to screenshots of your results so people can judge for themselves.
I just submitted all your searches to google.com from Australia, and the results were nothing like what you described; all the results were very diverse.
This is to be expected, as Google has been criticised for years for reinforcing stereotypes in image search results, and has gone to great effort to adjust the algorithms to reduce this effect.
I usually don't spend time producing evidence since no one else does it, nor did the parent comment, or you for that matter. It also tend to derail discussions onto details and arguments over word definitions.
First is happy person. Out of 20 we have 14 women, 4 guys, 2 children.
Second is criminal person. The contrast to the first image should be obvious enough that I don't need to type it.
If I type in "person" only I get the following persons in the first row in following order:
Pierre Person (male)
Greta Thunberg (female)
Greta Thunberg (female)
Unnamed man (male)
Unnamed woman (female)
Mark zuckerberg (male)
Keanu Reeves (male)
Greta Thunberg (female)
Trump (male)
Read Terry (male)
Unnamed man (male)
Greta Thunberg (female)
Greta Thunberg (female)
Unnamed woman (female)
Unnamed woman (female)
Resulting in 8 pictures of females, 8 males, which I must say is very balanced (I don't care to take a screenshot, format and upload, so if you don't trust the result then don't).
Typing in doctor as someone suggested in a other thread I get in order (f=female, m=male): fffmffmmmmfmmfffmfmfmmmff
and Nurse: fffmffmfmmffmffmfffmffmffff
Interestingly the first 5 images have the same order of gender and are both primarily female, through doctor tend to equalize a bit more later while nurse tend to remain a bit more female dominated.
Thanks for the screenshot. It helps (and by the way, yes the onus is on you to provide evidence as you're the one making the original claim).
Your initial comment said "Happy person", women of color.
But your screenshot showed several white people, several men, and a diversity of ages. Yes, more women, which is probably reflective of the frequency of photos with that search term/description in stock photo libraries and articles/blog posts featuring them. No big deal.
You also said "Criminal person", Hispanic men
But the screenshot contains more photos of India's prime minister than it does of Hispanic men. In fact I can't see any obviously-Hispanic men, and the biggest category in that set seems to be white men (though some are ambiguous).
The doctor and nurse searches suggest Google is making some effort to de-bias the results against the stereotype.
To me the biggest takeaway is that image search results still aren't very good at all, for generic searches like this.
Indeed it's likely that they can't be, as it's so hard to discern the user's true intent (for something as broad as "happy person"), compared to something more specific like "roger federer" or "eiffel tower".
I couldn't quite believe your comment when I read it so I did a Google image search for "person" and the results weren't a lot better than you'd suggested. Mostly white men, a few white women, a very few black women, a handful of Asians, and multiple instances of Terry Crews.
The net result of that Google search, combined with the "Shirt Without Stripes" repo, leaves me even more unimpressed with the capabilities of our AI overlords.
I think the skewing of results lessening your impressed-ness is the wrong takeaway. If anything, the AI is a more perfect mirror of the society it learned from than you expected. Perhaps the right way to look at it is that we are capable of producing things that we don't understand, that are more sophisticated than we realize.
You may be right. It's been bugging me since I posted earlier on so I fired up a VPN with an endpoint in Japan, along with a private browsing session in Firefox, to see if I got different results. As it happens the results were interesting:
- If I entered "person" I'd see a mix of images substantially similar to what I saw using google.co.uk up to and including Terry Crews, which was frankly a little weird, and otherwise mostly white
- If I entered "人", which Google Translate reliably informs me is Japanese for "person", I'd see a few white faces, but a substantial majority of Japanese people
So it seems possible that Google's trying to be smart in showing me images that reflect the ethnic makeup I might expect based on my language and location. I mean, it's doing a pretty imperfect job of it (men are overrepresented, for one) but viewed charitably it's possible that's what's going on.
Is the case for woke outrage against Google Image Search overstated? Possibly; possibly not. After these experiments I honestly don't feel like I have enough data to come to a conclusion either way, although it does seem like they may at least be trying to do a half decent job.
This seems like you're attributing motive to google here, but I don't believe that's right. For example, Terry Crews appears in the query "person" because his "TIME Person of the Year 2017 Interview" article was very popular online. I get a lot of Greta Thunberg because she was TIME Person of the Year 2019 and received similar online attention because of Donald Trump.
The TL;DR of it is that google crawls the internet for photos, associates those photos with text content pulled from the caption or from the surrounding page, and gives them a popularity score based on the popularity of the page/image. There are some cleverer bits trying to label objects in the images, but it's primarily a reflection of how frequently that image is accessed and how well the text content on the page matches your query. There's some additional localization, anti-spam, and freshness rating that influences the results too.
The majority of pages with "人" and a photo on it that has a machine labeled person image would be a photo of a japanese/chinese person, and if you're being localized to japan with a vpn, that would be even more true.
Google doesn't "know" what you're trying to search. It's a giant pattern matching game that slices and dices and rearranges text to find the closest match.
> Google doesn't "know" what you're trying to search. It's a giant pattern matching game that slices and dices and rearranges text to find the closest match.
I'm not disputing that, and it certainly explains why it's "good enough" for somes search queries whilst being totally gimpy for others.
My understanding was that Google does prioritise what it's classified as local search results though, on the basis that they're likely to be more relevant.
This is the problem though, all those companies are advertising fantastical results. They aren't saying "Hey! We spent billions of dollars so our algorithm could be as racist as your uncle Steve!". Oh and by the way, Steve is now right - because all the crimes he ever finds out about are by black people, because that's what Google has decided he wants to see. So it's no longer him seeking out ways of justifying his latent racist tendencies, no, he's outsourced that to Google.
Interestingly, duckduckgo shows me, as second result, an albino tiger with, you guessed it, no stripes. The page title has "[...] with NO stripes [...]" in it, so I assume that helped the algo a bit.
EDIT: I also got the painted horse (it looks spray-painted, if you ask me) and I must admit it's quite funny to look at
Those look almost entirely like stock photos or part of advertisements. It's probably just reflecting the biases of what photos other businesses like, which get the label of "doctor" or "nurse".
Any sort of image search is going to tend to be biased toward stock photos, because those images are well labeled, and often created to match things people search for.
> The AI has no morality. It simply reflects and amplifies the morality of the data it was given.
Key point right there. Unless Google is deliberately injecting racial and/or gender bias into their code, which seems extremely far fetched (to put it kindly), the real fault lies with us humans and what we choose to publish on the web.
What does the color of people's skin in search results have to do with morality? I was raised not to see color, now we have this "progressive" movement hell bent on manipulating search results to disproportionately represent minorities. If you want to filter your search results based on the color of skin you can do that easily.
What bias? Who is biased? Quick duckduckgoing indicates there are far more male than female doctors in the US. So statistically, it would be correct to return mostly male doctors in an image search. If you want a photo of a specifically gendered doctor, it's not hard to specify. Not really seeing a problem here.
I would contend that society is biased. There is no evidence that says men are better doctors than women, and in fact what little this has been studied says that women make better doctors than men (and is reflected in the more recent med school graduation classes which are majority women).
So it's a question of what you are asking for when you search for [doctor]. Are you asking for a statistical sampling or are you asking for a set of exemplars?
> So statistically, it would be correct to return mostly male doctors in an image search.
And that's exactly it. The AI has no morality. It's doing exactly what it should, and is amplifying our existing biases.
> So really you can't blame anyone but society for having such deeply engrained biases.
You can blame statistics for that. Beyond that, you can blame genetics for slightly skewing the gender ratios of certain fields and human social behavior to amplify this gap to an extreme degree.
Honestly, I don't think morality is the issue here; it is objectively inaccurate to show only white men for the search string "doctor" when not all doctors in the U.S. are white men, and most doctors in the world are not white men. This would be like showing only canoes if someone searched "boat"--we would rightly consider that an error to be corrected.
IMO, wrapping it in a concept like "morality" because the pictures have people in them just serves to excuse the problem and obscure its (otherwise obvious) solution.
I tried this as well in an incognito window on Firefox and got the results you mentioned. I notice, however, that virtually all of the results have associated text containing the word person. It seems likely that Google image search featurizes photographs to include surrounding document context.
(That's how I would do it if I wanted more accurate rather than more general results.)
I don’t understand why AI or a search engine had to meet your or anyone’s expectations for diversity. If I searched for “shirt” and didn’t get shirt pictures in the color I wanted I would just tune my query instead.
I just did a google image search for "person". The first 5 images were of Greta Thunberg. She must be the most representative person ever.
The next few images contained Donald Trump, Terry Crews, Bill Gates and a French politician named Pierre Person.
After that it was actually quite a varied mix of men/women and color/white people.
I am still not very impressed with Google's search engine in this aspect, but it is not biased in the way you suggest.
At least it is not biased that way for me. As far as I am aware, and I might be completely wrong here, Google, in part, bases its search results on your prior search history and other stored profile information. It is entirely possible that your search results say more about your online profile than about Google engine :)
> The first 5 images were of Greta Thunberg. She must be the most representative person ever.
Well, she was the 2019 Time Person of the Year.
Likewise, Trump was the 2016 choice, and Crews and Gates have been featured as part of a group Person of the Year (“The Silence Breakers” and “The Good Samaritans” respectively).
4 of my top 7 images (the top line) are Greta Thunberg in a search for "person". First viewport is 11 men, 11 women, 1 stick person, of which there are 4 Thunbergs, 4 Trumps, 2 Crews. People seem to be if they got major "person" awards like "most powerful person" or "person of the year".
There's not much diversity, assuming Terry Crews is from USA, then all the first viewport full of images are Western people; except Ms Thunberg they're all from USA AFAICT [I'm in UK].
The first non-Western person would be a Polish dude called Andrzej Person (the second Person called Person in my list after a USA dancer/actress), then Xi Jinping a few lines down. The population in my UK city is such that about 5/30 of my kids primary and secondary school, respectively, classmates have recent Asian (Indian/Pakistani) heritage. So, relative to our population, there are more black people, far fewer Indian-subcontinent no obviously local people.
Interesting for me is there are no boys. I see girls, men and women of various ages but no boys. 7 viewports down there's an anonymous boy in an image for "national short person day". The only other boys in the top 10 pages are [sexual and violent] crime victims.
The adjectives with thumbnails across the top are interesting too - beautiful, fake, anime, attractive, kawaii are women; short, skinny, obese, big [a hugely obese person on a scooter], cute, business are men.
Most of the person results appear to be 'Time Person of the Year' related. Another result is a guy with the last name Person. The results don't seem to be related to the definition of the word 'person'.
For me it shows all newsworthy people and articles. It shows the titles of the pages and they are all stuff like "11 signs you are a good person" So it seems clear that there is no kind of AI bias here but simply that high ranking articles with the word person more often than not choose white men as their stock image.
Most of the very top results seem to be of trump and greta thunberg.
You've raised an entirely unrelated problem. Showing shirts with stripes when you search for "shirts without stripes" is just plain wrong. Showing only a single demographic of person when you search for "person" is correct, it just doesn't have the level of diversity you seem to want. Nothing about diversity is implied in the query, and so your observation is completely unrelated to a plainly incorrect query.
On the other hand, the bias in the results means they're somewhat incorrect: there is more than one demographic of person, showing only one in response to a query that doesn't ask for a particular one is incorrect.
If you were unfamiliar with them and searched "widgets" to find out more and got widgets of a single colour and form, it would not be an unreasonable assumption that widgets are mostly (if not entirely) that shape and colour, especially if there was nothing to indicate that this was a subset of potential widgets.
It's not so much "demand for diversity" as it is "more accurate and correct representation".
Yeah, that's one plausible explanation. (I don't remember the nature of the letter.)
Relatedly, one time I picked up a prescription for a cat. The cat's name was listed as CatFirstName MyLastName. They had another (human) client with that same first and name. It turned out that on my previous visit they had "corrected" that client's record to indicate that he was a cat.
I think search algorithms still have a long way to go to really understand the intention. Try your image search results for
"white person" "black person" "asian person"
"white inventors" "black inventors" "asian inventors"
Doesn't quite deliver what would be expected.
More than racism on the part of google[1] I would attribute that to it being an hard problem with too many dimensions. About three years ago if you searched "white actors" google would give two full pages of only black people (I have no idea whether the actor part was correct).
Many interpreted this along tribal lines, but likely it is that there is constant tuning and lots of complex constraints.
[1] not to say that you implied the reason was racism, but often it is attributed to something along those lines
The inverse: a favorite trope of the American far right is that GIS for "american family" will show you photos of... mixed race families. (Something the far right has strong opinions on, and is a tiny minority of all marriages in the US)
Something of a corollary to Brooksian egg-manning: with an infinite number of possible searches, you can find at least one whose results do not exactly match the current demographics of the state from which you place the search.
Jokes on you. Not having diversity is now considered incorrect, even if it wasn't stated. AI needs to learn to keep up with the craving for relevance the rest of Silicon Valley has by ensuring all results comply with whatever equal opportunity mantra is now in vogue. The next time I search for "CSS color chart" I expect the preselected color to be black.
Google has for years put out puff pieces talking about high accuracy on image tagging. It’s only within the last few months that searching my Photos library for “cat” returned something other than pictures of my dog.
There’s a nuanced argument that practitioners know how ML is so dependent on training data and accuracy tails off sharply, but that nuance tends to removed from anything selling to potential customers — which has not been a great way to keep them in my experience.
I'd assume pets are hard as there are so many varieties (potentially even harder than humans). For the last few years Google Photos has correctly returned photos for a search of "Lamborghini" in my albums. I'd expect "shirt stripes" to fall into that category.
Sure, I’m not saying it’s an easy problem — just that the marketing is once again setting the field up for failure by giving the impression of human-level performance but delivering results only in very narrow scenarios.
I think a huge Chinese room type parser with a bunch of heuristics bolted on probably provides much better bang for the buck than trying to implement actual NLP (in every possible language, or even just in English). So that's probably what nearly everybody is doing.
He probably meant "more spicier". Second image for "now one with stripped this time please" yielded image that is linked to article about deep-fake nudes.
That point is akin to stating: These three companies have not solved the hard problem of common sense [1], so are not allowed to advertise their AI without looking silly.
Nobody has solved the common sense knowledge problem yet. A solution for that would qualify as Artificial General Intelligence and pass the Turing Test.
But search engines have come a long way. I even suspect that when search engines place too much logical - or embedding relevance to stop words such as "without", that, on average, the relevant metrics would go down. It is not completely ignored as "shirt with stripes" surfaces more striped shirts than "shirt without stripes". "shirt -stripes" does what you want it to do.
Searching for "white family USA" shows a lot of interracial families. Here "white" is likely not ignored as much, and thus it surfaces pages with images where that word is explicitly mentioned, which is likely happening when describing race.
You can use Google to find Tori Amos when searching for "redhead female singer sings about rape". Bing surfaces porn sites. DDG surfaces lists (top 100 female singers) type results. The Wikipedia page that Google surfaces does not even contain the word "redhead", yet it falls back to list style results when removing "redhead" from your query, suggesting "redhead" and "Tori Amos" are close in their semantic space. That's impressive progress over 10-20 years back.
Does Amazon pretends to do AI? They are just offering a platform to do your own Machine Learning. I don't think they ever said their search engine was doing anything smart.
EDIT: scrap that, I didn't mean Alexa, which is doing AI obviously, but the search engine of Amazon's retail website.
Anyway, NLP is hard and everyone sucks at it. Think about it: just building something that could work with any <N1> <preposition> <N2> or any other way to express the same requests would mean understanding the relationships of every possible combinations of N1 and N2. It means building a generalized world model that is quite different from simply applying ML to a narrow use case. Cracking that would more or less mean solving general AI which probably won't happen soon.
Not actually true. ML is one area of study within the field of AI. Thanks to marketing departments and slightly shoddy journalism these two things are now casually treated as equivalents, but they're really not: ML is still very much a subset of AI.
I disagree, "shirt without stripes" is an unusual word choice, not one that our ML models would be optimized for. Try "solid color shirt" and you'll see how much better the results are - at least on Google.
"Shirt without stripes" may (or may not) be an unusual word choice to enter into a search engine, but it's definitely one that a child would understand.
Additionally, "shirt without stripes" is not the same as "solid color shirt"; as an example, take a look at:
Quite so. "Shirt without stripes" can include shirts in plenty of patterns other than solid colours (paisley, polka dot, checked, battenberg, floral print, etc.).
Yes, that exact sequence of words isn't particularly common. And yet a child, even if they have hey have never been exposed to it, has no problem understanding what it means.
Whereas all these services seem to be processing the input in such a superficial way that they give the searcher results that aren't just inaccurate but are the opposite of what was asked for.
You have to realize that search is not AI. It's pattern matching. And the string "shirt without stripes" matches really good with "shirt with stripes". Levenshtein distance is 3.
If vendors would use the term "shirt without stripes" than it would match great, but they call it "plain shirt".
“Chicken without head”, “men without pants”, “sky without clouds” only work because the users uploading the images tended to tag them as such... (in that case the users do the hard coding of meaning)
Just searched same on google and first non-plain shirt was in the second hundred. Duckduckgo was similar. Considering that they classify images according to surrounding text, it seems like pretty good result.
I would go in a store and search there. Not everything has to be solved by tech and AI. This is a prime example of a problem that requires insane amount of work and yet provide absolutely no value to the world.
People still think we will have self driving cars "in two years" yet here we are talking about dumb shirts. AI winter is coming
I have noticed in the past few years google results have become noticeable worse for similar reasons. Google used to _surprise_ me with how good it was able to understand what I was really looking for even when I put in vague terms. I remember being shocked on several occasions when putting in half remembered sentences, lyrics, expressions from something I had heard years ago and it being the first! result. I almost never have this experience anymore. Instead it seems to almost always return the "dumb" result, i.e. the things I was not looking for, even trying to avoid using clever search terms. It's almost like it is only doing basic word matching or something now. Also, usually the first page is all blogspam SEO garbage now.
Google was good at launch because it was harvesting data from webrings and directories to provide it "high quality" link ranking data. However, they didn't thank or credit or share any of their revenue with the sites whose human curation helped their results become so impressive. Seeing that Google search was effective, most human curators stopped curating directories and webrings. The SEO industry picked up the slack and began curating "blogs" that are junk links to junk products. This pair of outcomes led to the gradual and ongoing decay of Google's result quality.
Google has not yet discovered how to automate "is this a quality link?" evaluation or not, since they can't tell the difference between "an amateur who's put in 20 years and just writes haphazardly" and "an SEO professional who uses Markov-generated text to juice links". They have started to select "human-curated" sources of knowledge to promote above search results, which has resulted in various instances of e.g. a political party's search results showing a parody image. They simply cannot evaluate trust without the data they initially harvested to make their billions, and without curation their algorithm will continue to fail.
> Google has not yet discovered how to automate "is this a quality link?"
Google has so much more data than just the keywords and searches people make, it seems like this should be a problem they could solve.
Through tracking cookies (e.g. Google Analytics) they should be able to follow a single user's session from start to finish, and they also should be able to 'rank' users in some vague way where they'd learn which users very rarely fall for ads or spend time on the sites that they know are BS. Those sites that are showing up on page 5 or 6 of the search results, but still get far more attention than others on the first few pages, could get ranked higher.
But I don't think many of Google's problems these days are technical in nature. They're caused by the MBAs now having more power at Google than the techies, and thus increasing revenue is more important than accuracy.
Theoretically, they could do a lot of things, but plenty of those would get them in hot water from a regulatory standpoint.
Also, don't underestimate the adversaries. Ranking well on Google means earning a lot of money. So much so, that I'd argue the SEO-people are making significantly more money than Google loses by having spammy SERPs. They will happily throw money at the problem and work around the filters. I don't think you can really select for quality by statistical measures. Google tried and massively threw "trust" at traditional media companies and "brands". The SEO-people responded by simply paying the media companies to host their content, and now they rank top 3, pay less than they did by buying links previously, and never get penalties.
Nope, all they could do there would be to group people together based on their "search behavior graph". The problem of finding BS sites is in itself a "shirt without stripes"-level hard problem. That's why being able to rely on user curation is (was?) so important for Google. People didn't curate the internet at first for money, they did it because they were interested in the subject for which they were curating their web ring.
I disagree with your first point but agree with your second. Google obsoleted most webrings/directories because page rank was a better way of calculating a websites popularity. Then, websites figured out how to game page rank, and its been a gradual decline ever since.
HN keeps mentioning dark SEO and companies gaming the ranking.
That might explain a lot but I don't think so.
Just look to how they are messing up simple searches because of basic lack of quality controls:
- Why doesn't doublequotes work anymore? Not because dark SEO vut because nobody cares.
- Same goes for the verbatim option.
- The last Android phone I liked was the Samsung SII, and last year I finally gave up and got the cheapest new iPhone I could get, an XR. My iPhone XR reliably does something my S3, S4, S7 Edge and at least one Samsung Note couldn't do: it just work as expected without unreasonable delays.
- Ads. They seem to be optimized to fleece advertisers for pay-per-views because a good number of the ads I've seen are ridiculous, especially given that I had reported those ads a number of times. I guess what certain customers that probably paid a lot for those impressions would say if they knew that I had specifically tried to opt out from those ads and weren't in the target group anyway.
The point is that the web rings and directories were an important source of good PageRank input. By killing them off, Google basically clearcut all their resources and did nothing to replant, and now the web is becoming a desert where nothing can grow.
Google was good because they used to optimise to giving the best search results, that was their aim. Now their aim is best profit, it seems, and their results appear to correspond (keep you on site longer).
Google's aim was to replace other sources of information with Google:
> People make decisions based on information they find on the Web. So companies that are in-between people and their information are in a very powerful position
Profit was on their minds from the very beginning:
> There are a lot of benefits for us, aside from potential financial success.
Revenue, however, was not urgent back then, to them or to their VCs:
> Right now, we’re thinking about generating some revenue. We have a number of ways to doing that. One thing is we can put up some advertising.
So over the past two decades, they executed a two-pronged approach: Become indispensable and Become profitable. But now they're trying to pivot from "at web search" to "at assisting human beings", and that's a much more difficult problem when their approach to "Become profitable" was to use algorithms rather than human beings.
Here's a useful litmus test for whether Google has succeeded at that pivot:
If you were in a foreign city and you suddenly wanted to propose marriage to your partner, would you trust Google Assistant to help you find a ring, make a dinner reservation, and ensure that the staff support the mood you want (Quiet or Loud, Private or Public)?
Your search for "skiing Norway" mostly returns results for skiing in the French Alps, because those pages have much higher visit rates.
Google is a dumbass nowadays, and regularly ignores half your search terms to present you with absolutely irrelevant results, that have gotten lots of visits in the past.
There are, like DuckDuckGo. But the first complaint is usually "their results aren't as good as Google" and that's because Google in reality still gives better results because of their (lack of) privacy.
People want better results but don't want to be tracked, and those things are in opposition to each other.
I think the only time Google still reliably gives better results than Duckduckgo is for non-English languges (which Qwant is good for), or when Google has something indexed and Bing/DDG does not.
But taking it as a given the Google's results are better, is that really because of lack of privacy, or just because of how Google has been pouring more money and talent into the problem longer than anyone else? Because I'm not convinced that personal data is particularly useful for generating search results. The example they always give is determining whether a search for "jaguar" means the cat or the car. But that always seemed silly to me, because most searches are going to give extra context to disambiguate ("jaguar habitat"), and even they don't, the user is smart enough to type "jaguar car" if they're not getting the right results. Further, Google doesn't actually know whether I'm more interested in cars or cats—it justs know that I'm a woman in college, so it guesses that I'm less interested in cars. Is that really so useful?
Does searching Google through Tor give noticeably worse results than searching google while logged in? I would be genuinely surprised if it did.
It took me something like 6 years, but I've gone over to DDG. Their results were poorer than Google's for me, so when I tried to switch I used to end up repeating and adding !g to every search. I don't think DDG got better, but Google results are bad enough that I think they're equal in quality now (for me). I don't login to Google, have tracking disabled, use uBlock and pihole; FF/Brave.
Yeah I guess it comes down to monetization strategy and how loyal/sympathetic the early adopters are.
It's funny because it's frequently mentioned how Google's tracking is what enables it to give such personalized search results, but often I question how effective that really is.
For instance I question if Google has some profile on me and shows results they _think_ I will want to see (e.g. news related), and thus leave out other results. If it works that way then I'm frequently seeing the same websites in my results and effectively being siloed and shielded from other results that I may find interesting.
Their new strategy of adding snippets for everything has truly gone insane. I search a query for "covid us deaths" today and had to scroll about 3 viewport lengths down to even see the first result.
What happened to just a plain list of blue links?
From a marketing perspective, I feel like DDG needs to change it's name or use a shortened alias. "Google" is an incredible word as it's easy to spell, remember, and it's short. Interestingly they own "duck.com"...
> There are, like DuckDuckGo. But the first complaint is usually "their results aren't as good as Google" and that's because Google in reality still gives better results because of their (lack of) privacy.
Alternative hypothesis: people only have had Google as reference for years, which means that Google represents "reality" to them. Anything that looks even slightly different is therefore worse.
I don't know about you, but 4 out of 5 times, when I research my ddg query, which did not produce a single relevant result on the first page, on Google, I get a good result as #1... Maybe I search google optimized.
Still though: This is not evidence for Google's search quality. I, too, feel, like the results got worse over the last years.
Also: Afaik, DDG uses bing under the hood, not what I would call "search startup" in the sense of revolutionizing search quality.
The results are correct for me. You just wanted to write a snarky comment. Did that make you feel better and gloat on Twitter about how you called Google a dumbass ?
I have also found that search results are getting frustratingly worse. Often even when I put in explicit search terms and quotes, and filter out words that I don't want, Google will return results that don't adhere to what I am looking for or just return no results at all. I remember when I would search for something and find much more relevant information. Now the first 5 or 6 search results are ad-sponsored and aren't relevant, but I have to go to the 3rd or 4th page to find something that matches. I also often have to search for things that were posted in the last year or less because the older postings are increasingly irrelevant.
I suspect their job has gotten way harder. It's easy to forget that they aren't just passively indexing. The web is basically google's adversary, with every page trying to be top ranked regardless of whether it "should" be.
If it wasn't AdWords, it'd be something else. People build websites because they want their content to be seen. That means competing for search result ranking.
That was when people built websites to deliver content. Now people build websites to get highly ranked in Google. No matter how good google's algos are, they can't win when the underlying content is just SEO'd garbage.
SEO'd garbage often contains ads, including Google ads. There's no incentive for Google to fix this problem.
Google's job is not to give you great search results, it's to keep you clicking on ads. Ideally it would be the ads on the search results page directly, but if that doesn't work then a blogspam website with Google ads is the next best thing.
If Google was a paid service this problem would be solved the next day. Oh, and Pinterest would completely disappear from Google too. :)
Cable television could get away with it because for a long time there was no alternative, so they could renege on the promise of no ads and still keep making money (though now people have alternatives in the form of streaming services and cable television is circling the drain).
Search engines are a relatively competitive market. A paid Google with no extra perks will not fly when the majority of people will just flee to Bing. For a paid Google to be successful it has to provide additional value such as filtering out ads, blogspam, Pinterest and other wastes of time.
Spotify & YouTube Premium run without ads just fine, so why wouldn't it work for search engines? Text is way more compressible then music and video. So at least on serving data it is way more cheaper than the aforementioned services
Because an MBA will realize that they're "leaving money on the table" and not "maximizing shareholder value" by selling ad free subscription services.
Subscription based services also require you to be authenticated and that enables fine grained invasive tracking. Something traditional media couldn't do.
If delivery costs were a factor then I shouldn't be charged $15 for an ebook with near zero distribution costs when a paperback was $5 before ebooks came onto the scene and introduced a new incentive for price gouging.
I would gladly pay 7.50 euros a month for a search engine which would serve me good results without the SEO blogspam. Sadly, I think that no new pages are written without SEO bullcrap. The next best thing I think is to use the search functionality of sites themselves (like Stackoverflow, Reddit, HackerNews etc.)
Google has gotten worse for me BECAUSE of the stuff you're talking about: It used to search everything and find the words that I cared about.
Today, it will silently guess at what I want, and rewrite the query. If they have indexed pages that contain the words I put in, but don't meet their freshness/recency/goodness criteria, they will return OTHER pages with content that contains vaguely related words. "Oh, he couldn't have meant that, it's from 6 months ago, and it's niche!"
They'll even show this off by bolding the words I didn't want to search for.
So, if I'm looking for something that isn't popular -- duckduckgo it is. It doesn't do this kind of rewriting, so my queries still work.
I'm not sure what has changed but I've experienced of late DDG participating in a similar style of result padding/query ignoring which has been publicly brought up in Reddit feedback (and I've certainly complained about using their own feedback form). Seemingly arbitrarily even double quoted strings I've observed being ignored which is not how it was even six months ago.
I still continue to use it though since as some here have already mentioned Google's results because worse a few years ago and DDG was lean and good enough to switch. I do hope they'd consider more such feedback.
I agree with search getting worse, now I always have to add quotes around my keywords: yes, I really wanted to search for this exact thing. I also end up adding "reddit" in my query just so I can reach some genuine useful questions/responses instead of top 10 blog posts written just for the Amazon affiliate links.
Searching "men without pants" versus "men with pants" gives much better results.
This is a case where, while it makes sense to say the sentence, it's not a common use of language, and at the end of the day, the search engine will find what's written down, it's not a natural language processor yet (despite any marketing).
Shirt stores don't advertise "Shirts without stripes - 20% off", they describe them as "Solid shirts" or "Plain shirts". Men's fashion blogs talk about picking "solid shirts" or "plain shirts" for a particular look. If I walked into a clothing store and asked for "shirts without stripes", the sales person would most likely laugh and say "er, you mean you want plain shirts?".
Plain shirts/solid shorts are the most common way to refer to these, and people seem to be searching this way:
Regarding moving towards natural language processing - the "without" part is not as important as knowing the context.
My kids will ask me to get from the bakery things like "the round bread with a hole and seeds", which I know means "sesame bagel", or "the sticky bread", which means "cinnamon twists" - which I understand because I know the context. Sometimes they say "I want the red thingy", and I need to ask a bunch of questions to eventually get at what they want (sometimes it's a red sweater, sometimes it's cranberry juice).
Unless Google starts asking questions back, I don't think there is any way it can give you what you want right away.
Vaguely similar to a joke from Ninotchka that Zizek often uses about the difference between 'coffee without cream' and 'coffee without milk'. He usually uses it to reference the concept of negation in the Hegelian dialectic, but he's also mentioned the difficulty of computers understanding negation in the context of the coffee/cream example.
Why should it not be possible to solve this with statistical methods? The model just needs to be able to understand the important meaning of "no" in here, in the context of the whole sentence. I would guess that most modern NNs from the NLP area (Transformer or LSTM) would be able to correctly differentiate the meaning. The problem is, I think there is no fancy NN (yet) behind Google search, and the other web searches.
To extend on that, you can think of the human brain as just another (powerful) statistical model.
"there is no evidence of cancer" and "there is evidence of no cancer" are two different statements with different meaning, so it's more complex a task than just understanding the importance of "no" in a sentence. It's involves semantic analysis of the sentence. The paper I linked to below describes a technique they call "deep parsing." Check it out for more context.
Lexical analysis is surely clever enough to make "no evidence" and "no cancer" the atoms used and should even differentiate "no cancer" from "no, cancer" pretty easily? Are we really still at 80s chatbot level functionality when it comes to string parsing?
Related aside: It frustrates me no end that spellcheck still doesn't appear to use any probablistic considerations, like Markov chains, to determine the intended word. And that when I click the next to last letter to make an adjustment it doesn't then change the suggestions to alternate endings, etc.. Perhaps newer devices than I have do this.
The general problem is much harder than that. You need to understand double negatives, when do they invert the meaning and when do they underline it? "Ain't nobody got time for that" can be interpreted in different ways. And then you need to understand sarcasm. Then a later sentence can invert the meaning of an earlier one. E.g. "This is the best movie ever. Said no one". Using word-pairs as features is easy, but there are just so many exceptions and ambiguity it's a very difficult problem to solve well.
"The city councilmen refused the demonstrators a permit because they advocated violence."
Which party is "they"? There is no lexical information that can possibly answer this question. It depends entirely on an actual understanding of what "city councilmen" and "demonstrators" (in the context of city councilmen and permits!) are, and which one would be more likely to be advocating violence (and in which case that would lead to a permit denial).
Background: Until recently I worked at a symbolic AI company who was tackling this problem. I myself didn't work on this problem directly, but I became 100% convinced that their approach, while a long shot, was the only conceivable way of solving it in a fully generalized way.
Another fun sentence is "I never said she stole my money". It has 7 different meanings depending on which word is stressed/emphasized. Was about to type it all but DDG'd this:
It gets even worse: "The city councilmen refused the demonstrators a permit because they advocated peace." the meaning of this sentence in 1968 is different than in 2020!
While it was an interesting point, it doesn't seem completely applicable here. Presumably the classifications include context. "A shirt with no stripes" should be distinguishable from "a stripes with no shirt" in the this context.
This is true, but isn't really that relevant to the parent's point about statistical methods. Statistical methods (and "deep learning" is such a method) could certainly take the order of words in a sentence into account, for example.
None. I was merely pointing out that your comment wasn't a response to albertzeyer's point about statistical methods. That is to say, maybe you didn't parse their comment properly ;)
Nope, I was simply countering that it's not as simple as they suggested. I added the link to the paper to show one approach to given them some context as to what might it look like.
I tried to search for "cheese without holes" on Google and it yielded good results. I think the problem here is that the query is something people would rarely search.
I just searched google images for "cheese" and "cheese without holes" and I got roughly the same results (about 1/3 of the images had holes in both cases).
If that's the case that's a big problem, because human children are trivially capable of both formulating and understanding uncommon sentences which still make sense.
It might be hard to come up with examples on the spot, but in everyday life you will routinely come across things you need to refer to by negation which are relatively uncommon.
Human children are also capable of walking, but it’s one of the hardest problems in robotics. Things brains can do intuitively, they can do because they have millions of years of evolution behind them.
Of the things the human brain does, I wouldn't say walking is very interesting.
The most amazing property in my opinion is the fact that it trains itself. (Whereas neural networks are trained by external systems).
I suspect it's related to imprinting. To take the example of filial imprinting, the brain must have some hardcoded notion of what a parent looks like. Then this is used to to build a parent detector, and the hardcoded notion is thereafter discarded. Then the newly learnt parent detector is used in reinforcement learning (near parent = good). Keep in mind that this all happens just after birth or hatching, before the visual centres of the brain have had any chance to train.
Yes, sure, exactly. It's a complex task. I'm just saying that there is no reason why a statistical model should not be able to solve the task. And you seem to agree on that. You even linked such a method.
> I think there is no fancy NN (yet) behind Google search,
During the deep learning boom, Google made a huge push towards NN-based NLP. SEO's and their PR calls their efforts collectively RankBrain: https://en.wikipedia.org/wiki/RankBrain
I think we are on the cusp of combining symbolical/logical operations over the vectors produced by Neural Networks (or at least, major effort there). Could be by neatly tying up all these different NN-based NLP modules (parsing, semantic distance, knowledge bases, ...) with another set of decision layers stacked on top.
This very question was the subject of a lengthy debate between Norvig and Chomsky. I won't rehash it here, but here's a glimpse:
Chomsky: Statistical analysis of snowflakes falling outside the window may predict the next snowflake, but it will do very little for weather prediction, and nothing for climate analysis.
Norvig: Give us enough data and we will get close enough for all practical purposes.
This kind of reminds me of the plot of the current season on Westworld (no spoilers). The amount of data needed to really have "enough data" is often not practical, therefore (ironically) never letting you apply it "for practical purposes."
Are you sure of that? After all, we don't have all the same interpretation for every word in the dictionary. Ask a hundred person in the street - well perhaps not these days - the meaning of the word "meaning", how many different explanations will you get? And will you be able to reduce them all to the same "fundamental" meaning?
Boolean queries aren't statistically analyzed; they're parsed and algebraically evaluate. So your point seems to support the opposite thing you're supporting.
Yeah I don't really know how github works. When I click the OP link I see a tiny bit of text and then three screenshots. Is there a whole article on this topic I'm missing?
The OP most likely isn't up to date on latest NN architectures which can learn from the ordering of words. Statistical methods <> ML, not anymore in NLP.
I guess it depends on what you mean with statistical methods but as you said "not anymore in NLP" then yes, statistical methods are in NLP. Both language models and transformers use statistics to predict.
- Shirt Without Stripes: shirts where the description contains both "without" and "stripes". Example: a shirt without collar, with stripes.
- "Shirt Without Stripes": a mess, with and without stripes, suggesting an unusual search query. In fact, the linked article site is the first result in web search.
- Stripeless shirt: sexy women in strapless shirts
- "stripeless shirt": pictures of Invader Zim...
- "stripeless" shirt: mostly shirts without stripes, but there are some shirts with stripes that are described as stripeless...
The last one may give us a hint at the problem. If you have to mention a shirt is without stipes, you are probably comparing is to a shirt with stripes. For example imagine a forum, some guy is posting a picture of a shirt with stripes, I can expect some people to ask questions like "do they sell this shirt without stripes"? Or maybe the seller himself may have a something like "shirt without stripes available here (link)" in the description. So the search engines tie "shirt without stripes" to pictures of shirts with stripes.
I remember an incident where searching for "jew" on Google led to antisemitic websites. The reason was simply that that exact word was rarely used in other contexts. Mainstream and Jewish source tend to use the words "jews" and "jewish" but not "jew". And because Google doesn't look at the dictionary meanings of words but rather what people use them for, you get issues like that.
> The reason was simply that that exact word was rarely used in other contexts
I had a similar problem when I was trying to convince a friend that homeopathy was a complete and utter fraud with absolutely no basis in reality. She was convinced that the internet's overwhelming consensus was that homeopathy was valuable and regular doctors were control-freaks who make things up when they don't know the answers.
To prove her point, she did an internet search for allopathic medicine and showed me how the majority of the results were negative.
To me, the most interesting implication here is that this must not adversely affect Google's ad revenue. If it did, they would surely fix it. This, in turn, means that apparently we have been trained to interface with search engines such that this is not a problem.
Sometimes I wonder how much my brain has changed to use search engines / how much of it is dedicated to effective googling. Makes me feel like a cyborg.
That sounds like an ad business version of the efficient market theory. E.g, that can't possibly be a hundred dollar bill on the ground, because if it was someone else would surely already have picked it up by now.
I think you're overestimating Google's sophistication.
The other day I found that googling something like “mesothelioma -lawyer” will exclude results with “lawyer” but all the ads will still be for lawyers and contain the word “lawyer”.
I guess because they leave it up to the advertiser to determine the negative match words and that seems to always have priority.
Similar thing happens on Twitter. If you mute a phrase it will block organic content including the phrase from appearing in your timeline, except ads including the muted terms still appear in your timeline.
That statement was true of every past search engine, too. AltaVista must have been great and its severe limitations must not have affected revenue, or else they surely would have improved it.
Everything is for the best, in this best of all possible search engines -- the Candide fallacy.
What exactly would happen if it was a material negative impact on their revenue and they didn't fix it?
If Google isn't under survival pressure to get better (and they aren't) the incentives aren't aligned for them to improve or even to not get worse every year.
If Google is failing first gradually then suddenly it might not even be within the institutional power to notice how bad it's become before it's too late.
Along these lines, I once heard somewhere that people do not process the word 'dont'. As a coach, I've had to shift my vocabulary to focus on the 'do's rather than the 'dont's
Eg: If you're doing a sport where leaning forward is bad, avoid telling yourself 'dont lean forward' as your mind only hears 'lean forward', therefore reinforcing the thing you're trying to avoid. Alternatively, tell yourself 'lean back' or 'stay straight' or whatever you're focusing on for that maneuver or drill.
Interestingly I've found this same approach from good coaches across completely different niche sports. I imagine this phenomenon has been discovered a number of times by various smart people. It certainly wasn't intuitive to me, but since learning to use affirmative advice in real-time sport situations, my advice got noticeably more effective.
If the first thing that comes to your mind when you hear "imagine a non-pink elephant" isn't either a pink elephant or "WTF, how is a pink elephant?", then you are in a very small minority.
The funny thing is that this search is pretty easy to put into first order logic (shirt(x) & ~striped(x)). I guess we now have computers that are bad at logic.
This is something that has annoyed me since the Altavista times. I want to search for "madonna but not the singer", and find pictures of the holy icon. I can do "madonna -singer", but that fails if the page mentions the word "singer" a single time. Even if it is "This is a page about madonna statues, but not about the famous singer."
It would be great if I could add negative keywords to a website, or mark text as "don't index" or "index with a negative weight". But probably, people would game this in ways I can't imagine.
There is probably a clever ML solution for this, like having meaning-vectors for distinct ideas, and pushing pages that are close to one meaning away from the other meaning. Classification is easy if you have a keywords like "painting" and "catholic", but if it is "virgin" or "prayer" then it could be either meaning, so there is never a bullet-proof solution.
I have a PhD in NLP (which is what we often call it on the CS side, but is almost synonymous with CL="computational linguistics" on the cognitive/linguistics side of the field). I remember a talk at our annual conference, well-attended, perhaps around 2003 or so. The speaker was from one of the labs that was really leaning into "big data", which was only just becoming possible at that point, and argued persuasively that we should all just throw out our parsers and formalisms—ditch the computational linguistics side, basically—because we were on the edge of functionally infinite (unsupervised) data, and supervised and partially supervised systems would never ever be able to keep up. He presented performance numbers and how the unsupervised systems needed a lot more data to compete with the supervised systems, but that data was available, and he threw more and more and more data at the system and it got better and better. (I no longer remember the specific task he was using to illustrate his point.)
There were gasps in the room and a kind of depressed acquiescence: geez, he might be right. And the pendulum indeed swung in that direction, hard, and the field has been overwhelmingly dominated by the statistical machine learning folks on the CS side of the field, while the linguists kind of quietly keep the flame alive in their corner.
But I thought then, and I still think now, that it really just was another swing of the pendulum (which has gone back and forth a few times since the birth of the field in the 1960s). Perhaps it's now time again for someone to ring up the linguists and let them apply their expertise again?
If you select "I don't like this recommendation" for a video on youtube, you will get to provide feedback on why you did so: either "I don't like this video" or "I've already watched this video." I've pressed the latter on literally thousands of videos at this point, and after well over a year of this, YouTube still hasn't figured out that I don't want to be recommended videos that I've already watched.
Likewise, Google says I should log into their website for personalized search results, but after years of always clicking on Python 3 results over Python 2.7 results, it never learned to show me the correct result.
Eventually I realized that personalized recommendations are more or less just a thin cover for collecting vast amounts of data with no benefit to the consumer. I believe we have the technology to do better, but we don't use it. In fact, we seem to be using it less and less.
My experience has been that most ads that "follow me around" peddle the exact same thing I purchased most recently. No, I will not buy a second electric kettle again, let alone the exact make and model that I now own. I'd rather have generic ads, so I might discover some new product that I could (at least in theory) actually buy.
I love this. It is such an easy to grasp example of what is "wrong" with search. Historically, searching was keyword based so documents with "shirt" and "stripes" would rank highly, even though none of those pages had the keyword "without".
As humans we know immediately that the search is for documents about shirts where stripes are not present. But the term 'without' doesn't make it through to the term compositor step which is feeding terms in a binary relationship. We might make such a relationship as
Q = "shirt" AND NOT "stripes"
You could onebox it (the Google term for a search short circuit path that recognizes the query pattern and some some specific action, for example calculations are a onebox) and then you get a box of shirts with no stripes and an bunch of query results with.
You can n-gram it, by ranking the without-stripes n-gram higher than the individual terms, but that doesn't help all that much because the English language documents don't call them "shirts without stripes", generally they are referred to as "plain shirts" or "solid shirts" (plain-shirt(s) and solid-shirt(s) respectively). But you might do okay punning without-stripes => plain or to solid.
From a query perspective you get better accuracy with the query "shirts -stripes". This algorithmic query uses unary minus to indicate a term that should not be on the document but it isn't very friendly to non-engineer searchers.
Finally you can build a punning database, which is often done with misspellings like "britney spears" (ok so I'm dating my tenure with that :-)) which takes construction terms like "without", "with", "except", "exactly" and creates an algorithmic query that is most like the original by simple substitution. This would map "<term> without <term>" => "<term> -<term>". The risk there is that "doctors without borders" might not return the organization on the first page (compare results from "doctors without borders" and "doctors -borders", ouch!)
When people get sucked into search it is this kind of problem that they spend a lot of time and debate on :-)
Perhaps, but would you really say "Hi, I'm wearing a shirt without stripes"?
It's a completely artificial construct. Simply the fact that this hacker-news entry is the #1 search result shows that real human people do not perform this search in significant quantity. But we can quantify that with data to backup the assumption [1][2]. When people want to buy a shirt without stripes, they do not describe the shirt by what it doesn't have.
In fact, it's trivial to cherry pick a random selection of words that on the face of it sounds like something a human might search for, but it turns out never occurs in practice. Add to that the fact that the term is being searched without quotes [3], which results in the negation not actually being attached to anything.
Do you go to a store to buy it along with your Pants Without Suspenders, Socks Without Animal Print, and other items defined purely by what they don't have?
Is it just me or does it feel like in the last couple years all of these companies have had the quality of their search go down? I've noticed large portions of my search will go ignored and it will just grab the most popular terms in my search rather than searching all terms.
This is also confusing what you search for vs. what the vendor thinks you will buy. Product catalog searches often intentionally return items outside your search parameters.
I would never search for something this way. If I wanted to find a 4WD car, I wouldn't search for "cars without 2WD."
Likewise, here, I would search for solid-colored shirts.
And these services are limited to the content/terminology utilized by the cataloged sites/products.
If I am selling a "black shirt" or a "solid black shirt," it is not google's job to catalog it as a "shirt without stripes," unless I advertise it as a "black shirt without stripes."
I would use natural language to test a services' NLP ability.
But it what if you just hate shirts with stripes but do like polka dots or other patterns? You can do a fancy advanced search query with OR and EXCLUDE tricks but that is not what this post is trying to emphasize.
Let's assume the point of the OP is that Google sucks at understanding this search that most people would logically understand.
But let's also logically assume that most content on the web is telling the visitor what their page or product is, not what it is not.
I would expect a shirt to be advertised and described as what it is: “black shirt” not “shirt without stripes.”
So if a content creator does not include the exact term “without stripes” in the description of shirt, then you are relying on google to infer meaning on your behalf and the content creator.
Now, this is relatively inconsequential for a shirt and perhaps not well representative, as a fashion-related searches a different than many searches. If I search for “news without coronavirus,” should I expect only articles that do not refer to coronavirus? I wouldn’t.
If I was allergic to peanuts and I searched for “food without peanuts,” I would expect results from content creators and sellers of products who took care to include the term “without peanuts,” because they are advertising their product as safe for those with peanut allergies. I would not rely on google or amazon to make that determination for me.
Both for google and individual sites, there are better options to further narrow results. If you don’t want to narrowly define your result to a specific pattern or color, the first search more broadly and then used advanced settings or filters to omit terms and/or include others.
Your car example makes sense because there are pretty much only 2 options.
Unfortunately people don't search for "solid shirts". At best they search for "plain shirts", but there's a lot of taste to clothing that means people often do want a shirt without stripes, but are open to patterned/plain.
I think searching "shirts without stripes" is very legitimate in fashion.
I say this having built a clothing search function for the company I work for, and one that does not support this sort of query.
So the one you built will exclude shirts with stripes if "shirts without stripes" is typed directly into a search box? Or there are secondary filters to omit and/or only show certain patterns?
I suppose my ideal UI understands your search, and then moves what it can to (interactively modifiable, as in Amazon's sidebar) filters, keyword searching on the rest.
Currently when I search Amazon and then see that some of my search terms are filter options / categories, I try to remove that from the search (which isn't always easy) in case there's more results I'm missing because they happen not to have the keywords.
We're a company coming out of the YC W20 batch working on the product attribution problem http://glisten.ai/.
There's too many products nowadays to be manually attributed (e.g. pattern=stripes), making it hard return good results even with entity resolution for queries. We train classifiers to categorize products, including what something is not, using their images and descriptions.
Google Photo's search is a similar source of amusement for me. While it's quite good, it also fails fairly regularly and sometimes amusingly. For me "turtle" includes understandable mistakes like fish, a snail, and a rock that does look a bit like a turtle. However "turtle" also includes this, a picture of sequined slippers reflecting light?! https://i.imgur.com/4aSlA4B.jpg
I'm guessing one of those reflections looks like a turtle? Or maybe a pattern on the floor, wall, or rug?
Although there are examples where I'm unsure if the AI is dumber than my 4yo or smarter than me. This is a result for "truck": https://i.imgur.com/JcgXZAG.jpg
Even (especially?) my 4yo knows those are Brio trains, not trucks. However, trains have components called trucks! https://en.wikipedia.org/wiki/Steam_locomotive_components I'm unsure whether or not any of the wheel assemblies on these toy trains are considered trucks, so either the AI is extremely smart or slightly dumber than a 4yo.
Although search within apps can be even worse.
I was looking through Google Movies the other day for the film 2001 and instead it swamps the results with those from the year 2001 - one could argue that there are lots of people who are massively keen to buy films based on the year of production, but I suspect it's better to satisfy those looking for years in the title first and then after that brief interruption list the year based results, rather than the other way around.
Similarly looking for "The Book of Why" on Audible is dismal: even when it's in quotes it isn't until the 42 result that the exact match shows up, with a load of useless not-obviously connected results turning up first.
Both these failures interest me as they have a tangible financial implication (I clearly had money to spend) and yet they remain unfixed.
I realize the obvious fix for the Audible problem is to interpret double quotes as "only search for this phrase," but I wonder if an alternative solution would be do TFIDF for combinations of wordsm, not just individual words. For example, the search crawler could watch for the phrase "the book", "the book of", "the book of why", "book of", "book of why", and "of why", and weight the search results accordingly.
Yes, that would be a better user experience as:
1. not everyone will think to use quotes
2. it would probably be more resilient to minor user errors too (eg if it had been misused misheard as The Book of Way you'd still have a fair chance of it returning the desired result fairly high in the list)
the icab link from yesterday showed a screenshot of amazon when their categories listings were still meaningful and helpful. nowadays, it's just a pain.
i recently looked for dough scrapers. i wanted to see what's selling best and what's most rated. they are everywhere. in dessert & decoration, in utensils, in bakeware, and many other categories. i mean i get it...
it's not just search that's hard. categorization is also an issue here.
Yes. I expect to get results that contain the keywords "shirt", "stripes", and "without", but perhaps with the last term ignored. Why, what would you expect? Would you search for "shirts that don't have stripes"? Or "shirts lacking stripes"?
Google started doing that with its regular search queries several years ago. There are thousands of complains on HN about how it's almost impossible now to find anything without "quoting" "every" "word" "of" "your" "query".
It sounds like you expect the search engines to understand natural language, because your expectations are influenced by what is "touted". Do you think that's a realistic expectation?
This is the only interface you really get into the amazon catalog. What if you really are looking for shirts that don't have stripes? How would you formulate the query?
Of the first ten hits:
Amazon: 7/10 aren't shirts (but all are stripeless)
Google: All shirts, one is checked
Bing: All shirts, all contain stripes in description.
Not exactly glowing for Amazon, clearly unsupported by Bing.
Like Google, Amazon is supposed to support the - operator, but, also like Google, it's not clear whether it does anything at the moment. As others here have suggested, maybe "solid shirts"?
I would prefer results containing words "shirt", "stripes" and "without". I don't want search engines to freely interpret my query and guess what I probably wanted to see while burying exact results in hundreds of pages of useless garbage.
I think it depends on the application. If I’m searching for products in a store I do want “shirts without stripes” to give me shirts without stripes. I have a hard time thinking of a case when including results with the word “without” would be useful when it comes to online shopping.
When I’m looking up information, like an article, especially technical information, then yes I want the search engine to do as little interpreting as possible. That’s because any interpretation rules it uses won’t always be relevant so I’d rather have more control.
But for Amazon? I don’t see how someone can see the average user typing “shirts without stripes” and getting almost nothing but shirts with stripes, and going “yup, works as expected”.
How is interpreting "shirts without stripes" as "I wish to see shirts that don't have any stripes" guessing?
I would venture to say that most people (meaning your use case is in the minority) who type "shirts without stripes" want to see results showing shirts without stripes not results "containing words "shirt", "stripes" and "without".
I think what is happening here is that you know how search engines work and so you are conditioned to expect them to do what they're doing.
«How is interpreting "shirts without stripes" as "I wish to see shirts that don't have any stripes" guessing?"»
Because I was looking for pages about the band called "Shirts without Stripes". Because I wanted pages with shirts that have stripes but where the page featured the word "without", because their shirts are without something else. Because I want to see striped shirts from the company called "Without". I don't want the machine to guess what I mean. It can never know.
Exactly. Those who want the search engine to "understand" what they are asking for when they use words like "without" may not have thought through the unintended consequences. For there is no combination of search terms that might not be interpreted in a variety of ways that the searcher never imagined, because of the ambiguity of natural language. Better to learn and use search operators, and the strategies of careful choice of keywords.
Precisely, as there is a better way to do it. Search for "solid-colored shirt" or "black shirt" and/or further define your search to exclude the term "stripes."
Proof that SELECT with GROUP BY doesn't work if your tags aren't correct.
Joking aside, it doesn't surprise me that this isn't being picked up — aren't most of these AI teams more R&D than actual public-facing? Maybe I'm just cynical though.
This contrasts with my query of "guys in jean jumpers singing too ra loo ra loo" a few years back, which Google correctly identified as "Come on Eileen" by Dexys Midnight Runners. To this day my favourite search experience.
If it were butter, you'd want an unstriped shirt. If it were provolone, you'd want a non-striped shirt. But because it's neither of those, I think you just want a "shirt" or maybe, a "plain shirt". Indeed, I get much better results with either of the latter two search terms. There's no need to mention stripes at all, since no pattern is the default state, isn't it?
because google does understand that no and without are interchangeable. But, understandably, it does not correlate "shirt without stripes" as being the same thing as "solid-colored shirts." Why, because no one advertises or describes a solid-colored shirt as a shirt without stripes and no one searches that way. It's an irrelevant point, in my opinion.
my point was that this very web page on HN got to top of Google search in 42 minutes or less on this search term
'''
Shirt Without Stripes | Hacker Newsnews.ycombinator.com › item
42 mins ago - The point that the author is making, in a very understated way, is that all three companies have PR websites that breathlessly describe their ...
So the better search would be "DisplayPort adapter for a Mac."
As with including the word "stripes" in a search where you want to omit results with stripes, including the word "mini" is only causing unnecessary confusion. The adapter that works for a Mac Mini will also work for a Macbook, as an example.
Point being that the more narrowly-defined search does not require Google or Amazon to infer any meaning beyond what the object of the search is actually defined as.
A shirt lacking stripes would never be described or labeled as a "shirt without stripes."
In the absence of that actual description, you are asking google to assume what you mean.
It seems quite doable to handle "shirt without stripes" in the following way:
1) Gather all items labeled as "shirts" (among other labels)
2) Filter out any labels that includes "stripes"
A shirt doesn't have to be labeled "shirt without stripes" for this to work. A shirt labeled "shirt with stripes" or "striped shirt" would not match, and lots of other shirts (solid shirts, shirts with prints, whatever) would match just fine.
Only slightly related but a couple of years back I got an alexa as a gift. When you open the alexa app, they had the option to add list of todos as a reminder. The first thing I did is to say something like - Alexa, add a reminder to get milk and eggs and paper. The app literally added a single item like this - milkANDeggsANDpaper.
Every once in a while I try the voice recognition by trying to speak normally to it. Normally, as is saying things like: "please set a reminder for five... umm... no I mean 6 o'clock".
Normal humans do this all the time, and if I can't do it speaking to it becomes incredibly frustrating to the point that I never want to do it again. I don't want to plan ahead what to say before I say it.
Granted, it's been a couple of years since I last tried so maybe they're better now.
Larry: "I saw a red Lamborghini in the parking lot!"
Most people will assume Lisa is driving a red Lamborghini and back from Vacation, meanwhile, all the bots are searching for Lamborghini vacations and trying to figure out what's going on in the conversation.
So basically the AI doesn't convert "without x" to "-x" even though the basic capability needed is there. This is why AI is a hard problem, especially when it meets the real world.
It's 2020 and we're still quibbling about the terminology used in SQL, what did we expect?
It's not enough to say "Oh, we should add a rule that 'without' means negate the next word" because that only applies to this one situation, in this one language. Let's generalize the problem: We aren't correctly translating from English (or other spoken languages) to Computer/Logic.
The state of the art in machine translation (from what I've read at least) is translating from language-A to a language-less "concept space" and then from there to language-B. Could that be done where the output language is something a search engine can use to find what you want correctly?
Given that pattern, I suspect we could see much better results in cases like this.
I think that this is actually really encouraging in showing that we still have a ways to go in improving search engines. A lot of people treat search engines as a solved problem, at least for non-question answering aspects.
Google has gotten significantly _less_ useful for finding technical information over the last decade or so. It used to be the case that when searching for some tech-related item (say, how to use functions in bash), the results would take you to someone's personal website or a wiki. Ostensibly, the more people linked to it and the more people clicked on it in the results, the better it ranked for that query and similar queries.
Today, entering in any tech-related query at all takes you to StackOverflow, end of story. Not only are SO answers quite often outdated (or even terrible advice in general), most of the time I'm not looking for a "here's how you do X", I'm looking for background information on a topic.
Most non-tech queries I put into google are even _more_ useless as the results tend to fall into these categories:
* Wikipedia (okay for _very_ general things, useless for domain-specific knowledge)
* SEO-enhanced blogspam, (a.k.a. "8 Weird Ways to Earn Millions Through Gaming The System!")
* Tweets on twitter (!)
The dev/tech industry desperately needs a search engine that somehow prioritizes _quality_ content, not one-off answers, blogspam, and tweets.
I am amazed at the amount of things people are willing to treat as "solved problem".
At a point there was a TED talk explaining social networks were a solved problem now that facebook was dominant. Recycling was seen as solved problem until it wasn't etc.
I wonder how many actual "sovled problems" we have.
They want to always return results even when they don't have any. So they will remove some of your query. This last week Google even returned months old results when I asked for the last 24 hours. It's so frustrating. I wish the Google team that decided this nonsense have to migrate Python 2 to Python 3 projects until they retire.
Yeah that works, but it's not the point. The author isn't saying there's no way to search for shirts that don't have stripes. They're saying search engines still don't understand how to find shirts without stripes in the same way humans do.
Problem here is not about negation, but there is no product that's described as "shirt without stripes". Stripes and shirt will come together in a different sense, since Google cannot find whole phrase it has to find parts. For example check for "shirt without shoulders"
I somewhat agree, but for me personally, "car without wheels" and "shirt without stripes" are about equal in terms of usage regularity.
I'd also say nobody uses the phrase "birds without flight", but instead "flightless birds".
I'd imagine people say "hairless dogs" a lot more often than "dogs without hair".
And the shirt examples show that there are many uses of the lead phrase "shirts without" that work just fine, but for some reason "stripes" really stands out far beyond the others. "Shirts without shoulders" is kind of a bizarre term to match, when almost all search results show "off the shoulder" or "cold shoulder" as the thing being matched.
There's a larger, nuanced point here: statistical ML based "AI" is simply an API over aggregated samples of human intelligence. The sampling suffers from bias (the "white men" example in this thread), gaps (the OP's example, which relies on "shirts without stripes" being an uncommon, though perfectly acceptable phrase), and many more such shortcomings of what is essentially "rote learning".
Humans can kind of make some assumptions based on context, but it's really just a poorly defined, vague query.
What if you walked into a store and asked an associate for a shirt without stripes? What would you get?
Probably some further questions for clarification. What about checked shirts? Floral prints? Plaid? Do you want no pattern at all? T-shirt? Polo shirt? Dress shirt?
Granted, the AI results are particularly bad because they give you the one thing that you specifically didn't ask for, but that's also the only information you provided. Defining a query in terms of what you don't instead of what you do isn't going to go well.
What if you went to google and said "Show me all the webpages that aren't about elephants"? Sure, you'd get something, but would it be anything useful?
This is a good example of the bar HNers must have these days when they bafflingly assert that Google is somehow getting worse from what they remember.
Google has gotten better, it's just HNer expectations that have changed as they expect more and more magic.
For example, the subtitle on the repo is "Stupid AI" when this query has never worked in these search engines, and it won't anytime soon.
You'd think the technical HN crowd would be more advanced than to make the same mistakes that (they complain that) stakeholders/users/gamers make when they mistakenly think everything is much easier than it actually is. Things aren't "stupid" just because they can't yet read your mind.
I would expect there to be an e-commerce site or blog post somewhere containing a page with the exact title "shirts without stripes" and I'd expect it to be the first match.
That darn conceptual search sure is hard :) The technical approach to achieving this involves a sentence embedding that then uses vector search to match documents based on a distance metric like cosine similarity. If you encode a description of a shirt in an embedding trained on all shopping item descriptions, it should match up with the search query. The trick is in getting a sentence embedding from a short query to match a longer description in a document description - long summaries of text in embeddings tends to average too much and cloud meaning. The other problem is including the vector search feature without screwing up other searches.
On a meta note, I am a bit tired of HN submissions being used more as "Writing Prompts" rather than as links to substantive material.
This thread is an excellent example. The author of the linked page didn't have the decency to actually make a substantive point, instead sharing three screenshots and posting the link here, chumming the HN waters with the kind of stuff that brings in the sharks from far and wide.
Bashing on big cos: Check
Vague pronouncements about AI: Check
Generic side-swipes about 'ad revenue': Check
This is why a coherent thesis is required to even initiate a proper discussion, because in the absence of that it invariably devolves to lowest-common-denominator shit-flinging.
Here's another fun fact about how commerce search engines work (I spent a couple of years on this):
Negations sidestep almost all of the algorithms that try to provide an improved result set, and fall through to pure text relevancy. So try searching on amazon for shirt, then search for: shirt -xkxkxkxk. Since xkxkxkxk doesn't match any documents, the negation should have no effect, but it does, the effect it has is to sidestep all the fancy relevancy work and hardcoded query rewrite rules, domcat rules, demand and sales/impression statistics etcetc, and give you basically awful search results. You don't even get shirts.
I'm actually not sure I expect this much from a search engine. Typically there is going to be a useful word to describe what you want without having to hope it can understand "no" or "without" (for example, without stripes -> "solid" or even "NOT striped" in many cases).
Anyone with a programming background knows there is an art to forming useful search queries--it is an acquired skill. I'd personally much rather the engine bring back predictable results given mundane rules and keywords than attempt to understand sentences using an opaque method of understanding.
I think Google should design primarily for people who DON'T know a ton about crafting queries, even if it's at the expense of a much smaller number of folks who are experts.
That said, this seems like an obvious place for improvement where both groups can be made happy.
Since there is no context is provided, I do not expect it to understand prepositions itself.
Given exact query to human, they create environment thus context themselves.
It may also depend on whom you are asking to. For example, myself, entering this site to find out news about software & tech.
Also since 'Stripe' is a company name, I assumed link will get the list of shirt shops who do not accept Stripe as a payment method/provider. (Thus some kind of protest related thing)
I literally thought about that yesterday and did not see the page thinking "That's too much for tonight".
To be fair, the only thing that Google needs to do internally is to match this query to “shirt -stripe” and then you’ll get the necessary answer. The bigger question is why they are not doing that.
"Plain shirt" works a charm though. What is a 'shirt without stripes' anyway? That could be a shirt with diamonds? Or a plain one? Or a Hawaiian shirt?
A good demonstration of the linguistic fact that far from being meaningless, prepositions (adpositions, more generally) are actually highly consequential for meaning and are highly ambiguous between different meanings. Here's a paper that'll give you a good appreciation of this from an NLP perspective if you're curious: https://www.aclweb.org/anthology/W16-1712.pdf
I believe the future of AI, as showcased by this simple usecase, is not one central AI such as Google search engine recognizing the context, but rather each of us having a "smart assistant" with a personalized, trained understanding of the contexts that we mean.
And it's only that smart assistant that automates coping with the deficiencies of a one-size-fits-all central solution, finding me shirts with no stripes by using a rather dumb search engine. (Or "a pizza I would like", etc.)
I'm kinda late to this conversation but there are companies and Engineers trying to solve this problem basically adding more "semantics" to visual content. Good place to start is with this blog from Pinterest.
Because a repo is meant for source control. People are using the issue tracker to leave general comments. There's no reason to branch or fork a blog post. It pollutes the contributions metrics. That said, I don't really care how people use Github, but there are better blog solutions out there already that would make more sense to use. However, this aches of the old adage "when all you have is a hammer, everything looks like a nail"
As others have pointed out, most search engines don't support natural language search in general, let alone natural language negation in particular.
There are several reasons for this, including the following:
1) Natural language understanding for search has gotten a lot better, but it is still not as robust as keyword matching. The upside of delighting some users with natural language understanding doesn't yet justify the downside of making the experience worse for everyone else.
2) Most users today don't use natural language search queries. That is surely a chicken-and-egg problem: perhaps users would love to use natural language search if it worked as well or better than keyword search. But that's where we are today. So, until there's a breakthrough, most search engine developers see more incremental gain from optimizing some form of keyword search than from trying to support natural language search.
3) Even if the search engine understands the search query perfectly, it still has to match that interpretation against the documentation representation. In general, it's a lot easier to understand a query like "shirt with stripes" than to reliably know which of the shirts in the catalog do or don't have stripes. No one has perfectly clean, complete, or consistent data. We need not just query understanding, but item understanding too.
4) Negation is especially hard. A search index tends to focus on including accurate content rather than exhaustive content. That makes it impossible to distinguish negation from not knowing. It's the classic problem of absence of evidence is not being evidence of absence. This is also a problem for keyword and boolean search -- negating a word generally won't negate synonyms or other variations of that word.
5) The people maintaining search indexes and searchers co-evolve to address -- or at least work around -- many of these issues. For example, most shoppers don't search for a "dress without sleeves"; they search for a "sleeveless dress". Everyone is motivated to drive towards a shared vocabulary, and that at least addresses the common cases.
None of this is to say that we shouldn't be striving to improve the way people and search engines communicate. But I'm not convinced that an example like this one sheds much light on the problem.
I think, looking at shirt without stripes and shirt with out stripes in Google images, that without is decompounded, which then ends up giving you shirt with stripes, however the slight difference between the two searches "shirt without stripes" and "shirt with out stripes" is that the there are some exact hits mixed in also, so there are some results for "shirt without stripes" mixed in with the decompounded query.
Strangely, in the context of the "Coffee without cream" example given in the video, I can see it possibly interpreted as "Coffee, with cream on the side, but not in it - I'll pour it myself". It's a stretch of assumption, but depending on culture, it could make sense.
"Shirt without stripes" is harder to imagine it meaning "strips on the side. I'll add them myself".
The author doesn't want a plain shirt. He wants one without stripes. This includes harlequin shirts, shirts with logos, shirts with pictures, tie die shirts. All good, as long as they don't have stripes.
So the - is working, contrary to the claims of several people here. The bottom line is that it is super easy to get results with shirts that don't have stripes, if you don't expect your search engine to understand English (which it would be wildly unrealistic to expect, and, besides, is not what you want).
While it is easy to get results based on certain keyword matching, Google has been publicly touting their ability to use NLP in search to better understand english. So this just shows a small limitation in their BERT models (https://www.blog.google/products/search/search-language-unde...). Doesn't make it any less impressive.
Yeah... As expected, negating the stripes on that last google search makes no apparent difference for me, and "plain shirt" has an entirely different meaning from "shirt without stripes".
if it really makes no apparent difference to you then I guess Google has decided I'm somebody who cares about using the - operator and you're not and for this reason serves me greatly different results because shirt -stripes is quite different from shirt with stripes or shirt without stripes.
not that there aren't a couple of striped shirts in there, but nothing like otherwise. So I mean, there is an extremely apparent difference from me, even though there is not the perfect result you might wish for.
Apparently, this kinda works in Thai language too(and I think other language also) The search keyword is "เสื้อไม่มีแถบ" which is literally translated as 'Shirt without stripes'. It's common words to speak, unlike 'without' in English.
The result, of course, show shirt with some kind of stripe, albeit not prominent like the English one.
The latest embeddings/networks like BERT can handle encoding this logic. They take the surrounding words in context when they're encoded.
Google can do this now, for example in a prototype. The tough thing is to get it to consumer-grade quality without messing up other searches. The QA process is utterly brutal because one weird search can be a scandal.
On a positive note Google used to have trouble with a query like "words with q without u", now the top 5 pages at least all show the correct results, eg:
https://word.tips/words-with/q/without/u/
Since I was a teenager, if someone energetically asserts a statement is “true” or “false,” I drop the true or false and evaluate the statement. In essence, their only communication to me is, ‘I think this is important!’ Often, why they think it’s important is more pressing than whether the statement is true.
I wonder if this is a need for humans need to learn search queries. "-stripes" instead of "without stripes".
Or does input need to have basic filters applied before handing to ML? "without X" or "no X" = "-X"? Can be foiled with "shirt without having stripes".
I think that query analysis in terms of volume of actual people using this query will show that very little people if any actually type "shirt without stripes". Once enough people do it, feedback is accumulated that results are bad (by CTR analysis), and results will auto-correct.
In search we know it’s easy to cherry pick queries and criticize any search engine. A search engine is optimizing for billions of queries. Most of which are on the long tail.
The real question is “shirts without stripes” really a query people enter? Or representative of a real pattern in the data?
> A search engine is optimizing for billions of queries. Most of which are on the long tail.
Citation needed.
As far as my personal observations go, Google is NOT optimized for long tail at all. It is always trying to return most popular results from cache of most popular results. Once the cache is exhausted, Google starts to return completely irrelevant trash (anything after first two pages of search is pure spam and meaningless keyword soup).
If you try to look up some obscure keyword and find nothing, try again after couple of months. There is a very high likehood, that you will see dozens of "new" results — most of them being from several years old pages. Perhaps, the actual long-tail searches still happen somewhere in background, but you are not going to see their output right away — instead you need to wait until they get committed to the nearby cache.
Another alarming change, that happened relatively recently (4-5 years ago), is tendency to increase number of results at expense of match precision. A long time ago Google actually returned exact results when you quoted search phrase. Then they started to ignore quotes. Then they started to ignore some of search terms, if doing so results in greater number of results. Finally, Google gained horrifying ability to ignore MOST of search terms. OP's example probably has the same cause — Google's NLP knows the meaning of word "without". But Alphabet Inc. can't afford to hose all those websites, that use AdWords to sell you STRIPED SHIRTS. This would mean a loss of money! THE LOSS OF MONEY!!!
It's representative of a real pattern in queries, albeit maybe not the most common one. You'd most likely see this sort of query as a followup. The user types in [shirts], gets a bunch of results, some with stripes and some without, and wants to only see the results without. So they modify their query from [shirts] to [shirts without stripes].
And since most search applications are basically just finding you the results with the most keyword matches, with a little bit of extra magic thrown in, the above is basically what you see.
These queries are basically the equivalent of optical illusions in cognitive psychology when studying the visual system -- seeing how the systems break tells you a lot about how they work.
Have you ever seen shirt dresses in your dress shirt queries, or vice versa? The search application isn't caring enough about bigrams and compound words.
Have you ever seen bowls in your bowling queries or fish in your fishing queries? The search application is over-stemming.
Natural language search is a real pain on any general purpose search application, particularly ones that have to deal with titles. The obvious simple fix to this query is to rewrite [x without y] to [x -y], but then when someone goes to search for [a day without rain] or [a year without summer], you are going to totally break those queries.
I mean, if I google the phrase "shirts -stripes" and click the Images tab I see mainly shirts without stripes.
So it's essentially the same input, and essentially the same expected output, but there must be quite a knot between understanding the word "without" and literally just using the - operator.
Right, but the - operator requires prior knowledge that the search engine understands boolean operators and that a -b is an alias of "listings with a on their text that don't have b in their text too" whereas "a without b" is inmediately recognizable by whoever is writing the search as "I want something of kind A without property B"
I wonder why this problem hasn't been resolved yet, considering we had NLP systems capable of this for a decade now.
Maybe it's too hard to scale to production. Or Pagerank is still better most of the time. Or plain old monopoly and risk aversion.
So I’d have to ask, is the problem the AI doesn’t intuit “without stripes”, find shirts that satisfy that condition (what kind of shirts? Dress shirts? T shirts?) and then do an image search identifing shirts and their quality of stripeyness
It seems to me that the problem isn't so much that this search performs incorrectly. Rather it is that many search engines have removed the tools that allowed a user to specify exactly what they are looking for (e.g. shirt -stripes).
You have to know to search for "solid colored shirt", but when you can't think of this variation of search, or maybe there isn't one, exclusion is your only option, and it's broken.
On Amazon's side of things I would also include the obnoxious "Hey you just bought a pair of sneakers so now I will change all your recommendations to sneakers".
I get the author's point, but if you think about it, a search engine is a database that serves you results you want to see. Why should a search engine be fine tuned towards things you don't want see?
If it's meaningful for some reason, then it works:
"shirt -stripes" seems to work on google.com at least, even though they and others like DDG have been getting really bad at ignoring "-foo" terms recently.
Noticed something interesting, if you search for 'shirt without sleeves' in google images, you DO get sleeveless shirts. So why doesn't this work with stripes?
On a related note, Google seems to favor forum replies which instruct users to perform a search in order to find the answer to the question that they had asked.
This is expected, not wanted though, I would expect some semantic analysis translated into "shirt -stripes", but what you really mean is "solid color shirt". This is a tough one but surely something that can be tackled with research
shirt -stripes does not mean "solid color shirt", as the - operator looks for that text on the page, instead of performing a semantic "I don't want stripes".
You're joking, but perhaps you're right. It's unnatural to search in the negative -- "solid shirt" or something like that would be more likely from a human with that actual intent.
This just suggests to me that real humans haven't issued that type of search query enough for the AI to know what to do with it. Which wouldn't be so big of a problem.
Most important is what the advertisements at the top show. The organic results are so yesterday. The Google Ads AI should already be teaching you that All you base belong to us.
None of them make an attempt at filtering this. While I found it amusing because they advertise with AI magic in other areas, those search engines all advertise to be keyword searches and one of them being "the worst" means it's either random (since none of them are trying) or they are the best (since it matches the stripes keyword).
To be honest I wish they actually were keyword searches and that the machine doesn't try to be smarter than you. Many times when I carefully specify which keywords must appear on the page, it'll ignore parts of the query or add unrelated synonyms. Usually one can work around it with operators but it's tedious and doesn't work reliably.
That is, learn to structure your query in a way that Google understands what you're trying to say. This used to be what yuo had to do, but now that Google tries to understand the intent of what you're trying to say and advertises as such, it's clearly a hack.
This sounds great, right? But consider the recommendation engines that are part of Amazon, Stack Overflow, whatever. You've just filtered out pages that have a shirt without stripes on it ... but have a striped shirt somewhere in a recommendation bar on the page.
I've run into so many variations of this. You can search for something only to have the recommendation/related results embedded on whatever page to throw off your results one way or another.
I genuinely think that whatever standard HTML/XTHML is at ought to have, either as an attribute or a semantic tag, some kind of "related" or "recommended" ability to set that content apart. My cynical thought is that even if it were adopted, it would probably get abused in some fashion.
What happens when someone asks you about one of those items? You consult your memory reserves, and you find that those are proper names of specific entities. So your brain returns those entities. Now there very well be a high school band called "Shirts without Stripes", you most likely would call up plain shirts or shirts with non-striped patterns. No reason that a search engine wouldn't follow the same rules (i.e., Google must have millions of entries for Doctors without Borders and Men without Hats).
IIRC if you use quotation marks in your search query, it would search for the exact match of that phrase without any search operators processed inside of it. So those scenarios you listed would still work fine.
Though I somewhat agree, I don't think that an average user even knows about existence of search operators in the first place, let alone being aware of this specific one and when to use it.
Search engines are indexing content based on [edit]STATIC [/edit] keywords, though.
The author's intent exceeds both the capabilities and intended use case of search engines.
The query "shirts without stripes" if interpreted by human would require any search system to not only analyse the keywords and tags (of the products/images), but also the content, which is an infeasible task given its dynamic nature.
So the author wants: select all shirts where content analysis of returned images yields no stripes.
This is a context-sensitive image/product search based on arbitrary, dynamically created criteria and shows that user isn't aware of what the search functionality does as opposed to exposing weak "AI". [edit]To clarify: you cannot add all possible keywords/criteria in advance[/edit]
The point of this isn't asking how to apply boolean search operators, it's showing that the largest AI-focused companies in the world absolutely suck at NLP.
Why would you really apply NLP to a search engine though? Generally speaking a weighted keyword search is good enough 95% of the time and requires significantly less resources to perform.
I work specifically in this field with clients, and deliver training on applying NLP to search.
You’d be surprised how effective NLP is for use when identifying query intent, and pulling out modifiers that should apply as metadata filters.
Weighted keyword search works a lot, but it fails hard for many long tail queries (especially in e-commerce and other attribute heavy domains).
IMO there really isn’t a good excuse for these firms to fail at queries like this. The query itself isn’t particularly difficult when using a decent NLP stack and following well known practices.
If it's technically possible then presumably it's a deliberate product choice to not have better search results for "shirt without stripes". And that seems entirely plausible.
Google is already by far the most widely used search engine, so they don't really need to innovate or improve the search product very much in order to attract and retain users. Presumably capturing more advertising spending from the companies paying for ads is a bigger priority.
Microsoft under Satya Nadella has been all about enterprise and cloud, and I doubt Bing is a strategic priority any more, so it's not surprising that they wouldn't put a lot of resources into making it better.
Amazon is a little surprising. You'd think they'd have a lot to gain from making it easier for people to find what they're looking for. But maybe less than perfect search results are deliberate? Maybe it's like how supermarkets put basic items in the back of the store and high-margin impulse buys in the front - so you have to walk past chocolates and chips if you want to buy a carton of milk.
If Amazon is deliberately nerfing search results then maybe Google would stand to benefit from having better shopping-related results - people would get frustrated trying to find a shirt without stripes on Amazon and just use Google instead, letting Google profit from advertising in the process. But maybe people selling shirts aren't willing to pay much for ads, so there isn't much money for Google to make by getting better at finding specific types of shirts.
I dunno if any of these conjectures are anywhere near accurate, but it's interesting to think about.
I feel like that's stretching the definition of NLP though. Technically you are processing natural language but it seems like you've found that doing essentially a keyword match but using certain keywords as more advanced filters rather than just search terms.
I think that is probably not a common enough use case to optimize for. Additionally it would be easy for a user in that position to just search "shirt" and ignore the occasional striped one, or to search "polka dot" and "paisley" seperately
I understand the point, but there are plenty of bigger fish that I would want Amazon and Google to fry before spending their engineers' time on a triviality like this. I just don't think that having to make three queries instead of one in this occasional situation is such a big deal.
You're arguing the search is "good enough". Because we can adapt to the machines. But the company who will not force us to do so will get our business. The company who creates the best digital butler will win. They know this. They try hard. And they still fail at simple stuff when judged by humans.
Another possibility is that maybe it really is "good enough", and they get a bigger advantage by competing with each other on more important aspects of usability than these kind of trivial issues
Assumptions like this is what makes search so terrible for many many companies.
You can't assume that customers would type one thing or another - you need to gather lots of query log data and see what you find. You'd be surprised how much variation there is, but once you do have this data you can then find patterns to cover lots of (but not all) cases.
Of course, they should look at the data before making such an assumption. I am not suggesting otherwise, I'm just making a guess as to why it's been done this way. I suspect they have looked at the data and identified that it is not a common use case.
Apple probably expected most users genuinely wanting to make a phone call would hold their iphone 4s a certain way. Turns out expectations don't always match reality.
From a product perspective, I would say there is a reasonable expectation that a customer will provide that query and expect the results to come back with plain shirts. Anything different is a degraded customer experience. Sure, a technical user will understand which queries to provide better, but 90% of customers won't have that skillset. Its our job as engineers to serve those people, and the queries they provide.
So NLP is totally a thing you want to have in search. Arguably, its the whole point of search as it exists now.
Why would you really apply NLP to a search engine though?
If you go to Google's homepage and click the microphone at the end of the search input box you can search by speaking. All it does is convert to speech to text, but it implies you might be able to search in a more "natural language" way.
Depends on your audience, but I imagine many find the answer boxes on Google search pretty useful. Getting the population of a city without having to click any links is probably good for your perceived value. For this you need some NLP tech to extract intent from the query and match it to the right entity in their knowledge graph (in addition to something to help you build the graph in the first place).
I agree, I think it's a better idea to improve the knowledge management (in terms of a relational hypergraph) before trying to create the bridge between the natural/digital knowledge representations. I have a hunch a good knowledge management system would be more amenable to being queried using natural language since relations are probably constructed similarly to the patterns we see in natural language syntax.
Certain query styles which the NLP operators help clarify. Recent personal examples: "is butyl rubber an organic or inorganic compound?" and "which gloves are best for both acetone and nitric acid?"
all three of these search engines offer "voice assistant" platforms that encourage you to speak to them in natural language, and send your query to the search engine verbatim under a broad set of circumstances.
Generally, yes. But you can go very far and cover a lot of cases when you stick to a narrow domain and common patterns that customers of your product will typically use.
Yeah the examples would probably do better if they had a front layer model determining the general topic "clothing" then shipping the query off to the clothing and fashion specific model for details.
Lots of focus on a general purpose mono-model, but
I think a collection of specialized subsystems is a better representation and would produce better results, faster.
Siri has lots of known problems. My biggest gripes are the lack of context and lack of a "discussion" state.
But Siri is a general domain problem, which is really really hard. Siri set the expectation you can ask it anything, and it works terribly and for most questions just gives up and runs a web search.
If you are an e-commerce company though, that's a narrow enough domain, because you know that for most people, they're looking for products to buy or compare. It's not an unbounded Q&A service.
Not that but maybe someone can explain if the technology is "AI" why it still takes tens of thousands of hours to implement a project? Shouldn't we call it AI when the frameworks can be implemented with relative ease? My point is that the level of customization required to achieve AI, in my opinion, doesn't make it very intelligent.
One of the primary methods to join multiple learned models is a decision tree (or combination of decision trees making a decision forest), which can be simplified as a series of if statements/conditionals. So if you join a 'is it a shirt' model with a 'is it striped' model you get two sets of things, and with how big data approaches this it is something you can do quickly. As other people have pointed out the issue here is that the NLP of the actual search is not creating a negation of two sets, it is returning the intersect of sets 'is it a shirt', 'is it striped' and shrugging its shoulders and either intersecting it with 'things with the text without', or throwing up its hands entirely based on the context because it wasn't programmed to do something smarter.
The term has been bastardized. AI is now any app that uses if statements, so long as it's obscured to the user. So now "AGI" exists, because apparently the word "general" now means "intelligent", unlike "intelligence".
At some point in the future marketers will learn about AGI, and we'll have to make yet another term, maybe artificial general practical intelligence?
Right, because when I think of "intelligence" I assume it's specialized and otherwise is dumb as rocks. Naturally. Which is why marketers are really just advertising specialized tools, not agi. Obviously.
I know what agi is; I just find the terms backward.
When you think of intelligence, you think of the human kind. As we create different things that have some of the properties we usually identify as "intelligence", but lack others that were completely correlated until that time, we need to create better words that can express the new situation.
It's perfectly ok to prefer the qualifier to go the other way around, keep intelligence general and change the name of the specialized form. But that's just not how our language evolved.
Or maybe there's just not a lot of AI in their main search product (for whatever reason). They seem to be pretty good in other areas (Translate, Cloud speech-to-text, Alexa etc.)
For the matter of translation they actually aren't pretty good. DeepL outsmarted all of them (at least for the supported languages). Given the resources thrown at this problem by the different companies I would even say the results of Google, MS and such are actually quite disappointing. (And I don't think one could say "but this companies did the upfront work" as the basic ideas are something 60 years old).
It's not as simple as NLP. The shirts them selves have to labelled as having stripes or not. If striped is not a attribute of the shirt, it doesn't matter of the NLP can parse the meaning of striped.
Saying this is unreadable is untrue. Also, I agree clear communication is important, but in this case it is highly trivial; if you don't know something that someone is referencing, a quick Google search immediately clarifies it. This is much like the fight couples have over keeping a toilet seat up or down: it doesn't really matter what you do or who does it. Because of that, you come across as querulous.
As an aside, I think that there are much more important factors to consider in regard to clarity and readability. I believe some of those are accurate articulation and logical tractability of ideas communicated.
How is the comment more or less readable if you know that Ninotchka is a movie and Zizek is a Slovenian philosopher?
The difference between coffee without cream and coffee without milk is the same whether Ninotchka and Zizek are the things described above, or if they are a city and a taxi driver.
People on an website like this should at least have a general idea of who Zizek is. I've never yet read any of his books but as a guy living in the Balkans this short clip [1] of Zizek explaining the geography that separates Central Europe from the Balkans is one of the best things on YT.
The GP didn't come across as ill-intended to me; it outlined an issue, gave a solution, and hopefully everyone who viewed it thought about context for half a second. I do agree with it that adding context to the comment is better than assuming random readers are going to actually look up capitalized names.
Your comment, on the other hand, comes off as the one that's disparaging and includes a personal attack.
You got it backwards. This is the opposite of the problem I and many other people tend to have with search engines lately. I do not want the damn thing to combine words, exclude unpopular ones, and search for synonyms without me telling it to explicitly. As little as you can semantics please.
If Google wants to group words by semantics, they should have a semantical grouping operator. For example "shirts (without stripes)". What if I am looking for a song text with these exact words in random positions?
If what author wants was implemented, it would make my experience with Google even worse, unless it could think for me also. But then why would it need me in the first place?
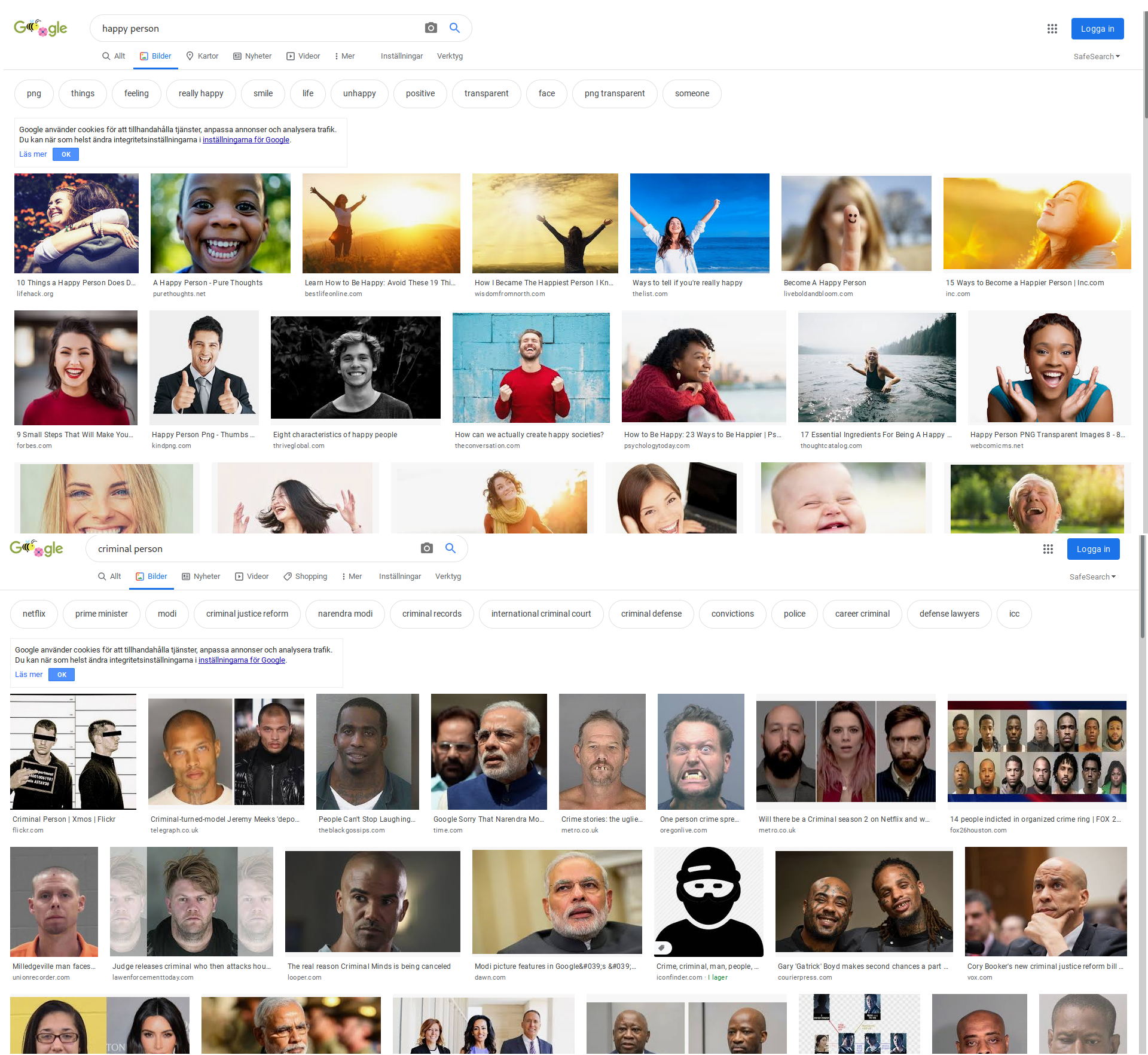{kind=link}
{kind=link}
{kind=link}
Zooming out, the language field breaks into several subfields:
- A large group of Chomsky followers in academia are all about logical rules but very little in the way of algorithmic applicability, or even interest in such.
- A large and well-funded group of ML practitioners, with a lot of algorithmic applicability, but arguably very shallow model of the language fails in cases like attribution. Neural networks might yet show improvement, but apparently didn't in this case.
- A small and poorly funded group of "comp ling", attempting to create formalisms (e.g. HPSG) that are still machine-verifiable, and even generative. My girlfriends is doing PhD in this area, in particular dealing with modeling WH questions, so I get some glimpse into it; it's a pity the field is not seeing more interest (and funding).