> This stack was created out of frustration due to the fact that to this day there's no easy way to have a full email server without the overhead of installing and configuring all servers needed to handle incoming and outgoing messages.
Interesting approach, though I solved this frustration by the use of a Docker and kept "my data is mine" + "no vendor lock-in" + "I control all the gears" approach. (Though, it's not perfect since VPS is ran by "someone" else.. but that place where you run this stack can be easily changed at your convenience).
Simple docker-compose.yml with 3 images and voila.
This AWS S3 SES setup looks far more complex than what I did using only 3 docker images: the postfix (for smtp), dovecot (for imap), opendkim (for email sigining & verification).
It's really easy to fire-up a VPS with a single click nowadays.
If someone is interested in the images I am using:
Then you just feed the images with the right configs (main.cf, master.cf, .., dovecot.conf, opendkim.conf).
It's also possible to template the configs and make the variable-based configs. Make things scale friendly.
I am also using Terraform to automate the server deployment/DNS record updates so it is easy to get from 0 to 100.
The only drawback is that you are the one to maintain the OS/SW upgrades, security, etc.. but that's something I really want to do by myself instead of relying on someone else :-)
Another “serverless” route for Docker containers is to deploy the containers with Fargate which isn’t too hard and gives you autoscaling without having to re-architect your application for serverless. (And has correspondingly less vendor lock-in)
> Interesting approach, though I solved this frustration by the use of a Docker and kept "my data is mine" + "no vendor lock-in" + "I control all the gears" approach.
Yeah, I totally understand the desire. And even hosting this on a cloud, you benefit from SMTP TLS sometimes, presuming no active MITM and the cloud service not actively abusing its privileges on your VM or storage. Which is probably not happening widely. At least as opposed to the protocol level logging that SES or similar services do for sure.
I recently opened some new accounts at AWS and other large one for a new company... first thing to do is setup mail of course. Both denied my request to allow SMTP. AWS ominously rejected me with some vague "maybe one or more of these reasons" including prior ToS violations or payment issues with "linked" accounts.
Frankly it's scary, and so far they are stonewalling me on any details as to what I "may" have done. AWS is one place I sure don't want to have a bad reputation with.
Fraud detection is such a frustrating double edged sword. They can’t share what was detected or why because the bad guys will start taking it into account. That leaves us with manual human review as the only means to address false positives. But that doesn’t scale so it’s either backlogged, low quality or nonexistent.
It’s impossible to guarantee that the reason can’t get back to bad actors if you give that information out to anybody, so that information isn’t given out. If you can figure out a way, you’d have a bigger license to print money than Google and Amazon, combined. The problem is, rfc-3514 aside, there’s no evil “bit” and no way to tell if the person making a request is good or bad, or if they’re even the person who’s account they’re using. Don’t forget the possibility of an “inside job” either.
Sorry for the bad developer experience, but fighting all the various kinds of fraud is harder than it looks. Thankfully ML's made strides in this area.
I think the issue is that not very many customers want to maintain their own mail server anyway, so it's just easier to turn down these requests unless the customer asking spends enough money that you don't want to offend them.
If you are a noob with a domain and need to host your own mail server, you need mail-in-a-box. Look it up. It runs on a VPS and configures email and even a static site for your domain. It also comes with a dashboard where you can create additional email accounts.
Don't you have problems with deliverability? I've found sending emails directly from an AWS IP (i.e. not via SES) has major issues with reputation management. It's really easy to have outgoing emails mysteriously spam filtered.
complex but not to mention expensive. i wonder what the costs per month would be sending/receiving a relatively small workload per day (1000 messages) doing it with SES and S3 versus a cheap vps provider.
Another drawback is that while yes, you can scale up fairly easily with terraform, your server can also fall over if you get a heavy burst of traffic, and you'll return errors until you're able to provision more machines. Depending on what you're doing, how fast you're growing, and how much tolerance your users have for downtime, that might be a pretty big deal.
You can set up autoscaling groups via terraform just fine, with a little bit of care taken to ensure that you trigger on the right metrics.
If anything mail is pretty much the easiest thing you can possibly pick to scale, because the inbound mail will be automatically retried. And haproxy in front of SMTP servers works just fine (really, any load balancer that can load balance raw TCP connections, but I've used haproxy to load balance thousands of messages a second).
For your user-facing side you need a bit more resiliency, but nothing stops you from using a service like SES to back a traditional setup for sending either. Reliably scaling outbound mail is the easy bit - the hard part is the reputation management that managed mail services provides, and no specific deployment mechanism will solve that.
Sure, but for heavy/bursty traffic, you can still have downtime while new VMs spin up. Retries might save you or they might make the problem worse, depending on the size and pattern of the burst and how your auto-scaling config interacts with the retry config of various hosts.
It may seem like a nitpick or something not worth worrying about, and for most that's probably the case. But for some businesses it could be a crucial difference. My point is simply that this is a legitimate benefit of serverless that wasn't mentioned above--I didn't think that would be a controversial point.
That is no different for serverless. You don't magically escape startup times - you need to carefully ensure that cold startup times are low enough, or that you maintain excess capacity to compensate.
The precise extent is different between different platforms depending on overheads, but that just means the point at which you need to trigger scaling is different.
You can find lots of descriptions of approaches people have taken to keep serverless instances running to avoid the cold start delays to work around this... For autoscaling groups you'd instead configure the alarm points used to trigger the scaling accordingly.
Serverless platforms tends to assume the startup will be fast enough to keep the connection open rather than return an error, but that is a load balancer config issue - you can set up retries and wait for other platforms too if it makes sense.
(Though for email this really does not matter - retries for all commonly used mail servers follow some form of exponential backoff up to many hours at least; retries works just fine in practice)
> That is no different for serverless. You don't magically escape startup times - you need to carefully ensure that cold startup times are low enough, or that you maintain excess capacity to compensate.
Serverless deployments are just another ladder step up the abstraction level, continuing the tradition that hardware doesn't matter. Similar to code compiled into assembly or a garbage collector managing memory. In the common cases, these cases are harmless (otherwise they wouldn't be popular), but they generally hide what's actually happening. Doing a garbage collection on a 200MB app is generally pretty snappy. But doing one on a 32GB server app can take seconds or minutes.
Abstractions like these are fine, as long as the limits of the abstraction are well understood. Sadly, that is rarely the case.
> Reliably scaling outbound mail is the easy bit - the hard part is the reputation management that managed mail services provides, and no specific deployment mechanism will solve that.
^this. if you want to send email its not hard....but if you want that mail to pass spam filters its a different problem altogether. hosted services like SES and mailgun will expose problems in how you are using emails (not handling bounces, not handling unsubscribes, etc) and in our case was very helpful.
Yeah, this is normal.
One bus can't fit more people than it physically can.
The high load can be alleviated by the use of more MX server DNS records (and the MX servers of course, across the different locations), LBs, smarter thresholds.
Of course nothing is a panacea.
Either way you will hit the AWS's limits or will get a huge bill. And then, even if you set up the budget limits, it still won't make the service more available once you reach the limits.
If you're running a saas and the increased traffic comes from paying customers, you likely prefer a huge bill to downtime.
But apart from that, there's a huge benefit in saying "I'm happy to spend any amount up to X" and not needing to do any capacity planning beyond that vs. continually trying to guess what's the right % to over-provision your VMs and having downtime when you get it wrong.
Yep, but how can you be sure the serverless provider will never go down? I've witnessed multiple times when AWS's services went down.
> If you're running a saas and the increased traffic comes from paying customers, you likely prefer a huge bill to downtime.
Well, in such situation, I would probably run more advanced container orchestrators such as Kubernetes which you will then configure to automatically spawn the additional server instances.
Of course there are certain advantages in running a serverless code as you have just mentioned, but since my primary concerns are "my data is mine" + "no vendor lock-in" + "I control all the gears", it is not the best option for me. Unless I want to run & provide the serverless services by & for myself.
It's always a game between the security (more freedom) and the convenience (less freedom). Though, for some, there is more freedom in the convenience (until they start to see their hands are in the digital cuffs :P)
The serverless provider can go down just like the VM provider can go down, but the key difference is that it won't go down due to traffic bursts.
Auto-scaling helps, but it still takes awhile to spin up new VMs, and you'll have downtime in the meantime for sufficiently large bursts.
On lock-in, in my experience with any non-trivial infrastructure you end up tied to your provider anyway. You're still going to need IAM users and VPCs and subnets and provider-specific auto-scaling and all that jazz. Serverless lock-in is deeper, but either way switching is a big project.
This is why the important projects must be thoroughly planned and tested in order avoid non-trivial infra or a blind cat situation.
And then it is a really good idea to leverage IaaC (Infrastructure as a code) which would bring the whole thing up really quick.
If it's a well behaving e-mail server it will keep trying to send the e-mail... A trick to stop spammers is to block all new connections for an hour. While spammers wont try again. Sadly some legitimate e-mail servers will not try again either :/
Also some e-mail servers wont try your backup e-mail server... Some servers will even give up if they haven't been able to establish a connection within a second. Some developers/admins give zero shit about edge cases and conditions outside their developer machine. Especially if it's a company that buys invoices they will take any reason to drop the e-mail so they can add a reminder fee.
Right, I'm looking at this more as a potential backend for an email-heavy saas, in which case I think handling bursts without downtime could be pretty important. If you just need a mail server for yourself or a small company, I agree it's not an issue.
We accidentally had ses credentials set up on our QA server and quickly got banned for sending too many sdf@sdf.com emails. Took quite some time to get it unbanned. Since then we switched to Mailgun for email delivery but ses is still useful for processing incoming email via Lambda
Very good point about sending test e-mails, which also reminds me of the next friendly reminder: SES has a Mailbox Simulator [0] where you can send e-mails to specific e-mail addresses and check the notifications you receive, e.g., bounces.
If you're using the SNS notifications [1], these notifications will be JSON objects [2]; you can then use a notification to extract the information needed, e.g. a bouncing e-mail address to be stored in a local registry in case of a bounce notification.
We are careful to use throwaway email addresses like randomusername@mailinator.com on our dev and staging servers so they still get delivered, but we can just forget about them.
Really interested to learn about the SES simulator address though (posted as a reply on this thread) - don't know how we missed that, and it would have really helped with early testing when we were developing the email queueing system on our app.
We configure all our test addresses to success@ses.amazon.com (or whatever the simulator address actually is) so we don’t spam or get banned by inadvertance
I don't know anything about serverless --- to this day I fail to understand what this word is even supposed to mean. And the deployment diagram[1] sure looks complicated to me. I think I prefer old-school servers.
The benefits to using this approach over a traditional server are:
1. Someone else maintains the software running these services, including OS upgrades, security upgrades and patches, uptime monitoring, etc.
2. Since every logical component is an independent service, each scaling independently, any one single component is unlikely to become a bottle-neck while scaling. In traditional monolithic servers, you'll have to have contingency plans if you beat storage/network/CPU/RAM limits
3. The closest thing to this is to break up a monolithic email server into microservices and deploy them as independently scalable containers, which is a considerable engineering effort.
Assuming this works as advertised, you can go from zero to a full blown email service for organizations with thousands of people (assuming the stated AWS limits are lifted), in record time
> 1. Someone else maintains the software running these services, including OS upgrades, security upgrades and patches, uptime monitoring, etc.
This is the standard marketing phrase echoed to promote serverless. By experience, I don't think is valid. Packages like unattended-upgrades automates all this stuff.
Also, not being able to verify what the software is doing is scary and looks like a 10 steps backwards to me.
> 2. Since every logical component is an independent service, each scaling independently, any one single component is unlikely to become a bottle-neck while scaling. In traditional monolithic servers, you'll have to have contingency plans if you beat storage/network/CPU/RAM limits
Except when it comes with a bottle-neck by default. Running mail servers requires rather little resource.
> 3. The closest thing to this is to break up a monolithic email server into microservices and deploy them as independently scalable containers, which is a considerable engineering effort.
Why in earth? Have you seen the postfix architecture?
> Assuming this works as advertised, you can go from zero to a full blown email service for organizations with thousands of people (assuming the stated AWS limits are lifted), in record time.
I'm pretty sure one can have a up and running mail server while the "cloudformation" thingy will still be running :)
The long and short of it is that “serverless” is all done on a pay-per-use basis. So is running a VM to host an email server — let’s say $5/month on the low end. With this setup you’d be paying pennies a month assuming normal personal usage. If you were running an email server for your Fortune 500 company, yeah this wouldn’t make sense. But for personal usage? Assuming SES isn’t on the shit list of Google et al this is fire-and-forget, and dirt cheap.
This use case and logic seems really weird to sell the serverless buzzword. My personal email has been somebody else's problem since the 90s and is done through the provider of my personal domain at no additional cost.
Setting up a serverless email server seems like something I'd have to bother with and maintain a few years down the line when the platform of choice inevitably changes something. Some use cases of serverless applications just shift maintenance efforts. Sure, I don't have to update OS packages. I still have to wonder if the service I'm using for my serverless stuff will be there (for startup vendors) in a few years or, more likely for vendors like AWS, change their terms, pricing or aspects of their API. I can pay a student intern to maintain a single VPS based $whatever, AWS consultants cost a multiple of that. If that's something you can and want to do yourself, sure, that's great - even for small use cases like this but then it becomes a philosophical toy problem more than a technical challenge.
> Assuming this works as advertised, you can go from zero to a full blown email service for organizations with thousands of people (assuming the stated AWS limits are lifted), in record time
All the hard parts of doing that are in dealing with reputation, not in setting up a mail server or or scaling it. I've run an e-mail service with ~2 million users on hardware with comparable CPU, memory and IO capacity to my current laptop in the past. Setting up the mail server was not the time consuming part.
And the reputation bit in this instance is handled by SES. If you put a regular mail server behind something like SES for outbound messages, that's simple too.
While I do see benefits to serverless, this seems to me to be a good demonstration of how it is still in a totally embryonic state when it comes to things like ease of use.
> Assuming this works as advertised, you can go from zero to a full blown email service for organizations with thousands of people (assuming the stated AWS limits are lifted), in record time
As someone who has been in this industry for over 30 years from being a grunt to wearing CTO hats if there's one thing that my experience unquestionably taught me is that there's absolutely nothing ever works like it is advertised. Ever.
I really think you can get a serverless experience with a radically different OS than we think of the set-it-and-forget-it Linux OSes. If you have an OS that is designed for self maintenance a lot of these problems go away, but your debugging experience isn't super different. I expand these thoughts here: https://robszumski.com/serverless-with-servers/
I still fail to understand why 4 years in, people seem to be confused about the idea that definitions of words involve over the years and that the computer industry has both been coining and adopting phrases.
But a quick Google search is all that it would take to “understand it”
Not a single post on Hacker News can use the term "serverless" without the exact same replies being posted every time. It's as if a certain portion of the HN crowd simply cannot fathom that a new term exists and is in use, and instead resort to the same, tired responses.
> Not a single post on Hacker News can use the term "serverless" wits nhout the exact same replies being posted every time.
As a serverless skeptic/critic, the buzzword bingo aspect of serverless computing is far from being the problem, and it's a gross missrepresentation of the problems posed by serverless computing.
The main problem with server applications such as AWS lambda, along with lack of control, is how utterly expensive it becomes by enforcing a SaaS business model to simple function calls, and how convoluted and needlessly complex it becomes by having to resort to yet another premium service to simply manage workflows (see AWS step functions).
Suggesting that any criticism of the serverless fad is just old grumpy incompetent developers that are too dumb to understand the future and are to scared of being out of a job is a disingenuous attack on anyone who has the audacity of not falling behind a fad.
There are absolutely valid criticisms of serverless (as you called out, vendor lock in and complexity for large applications being a big ones). But it's still an important and interesting technology that many individuals and companies are invested in, sharing side projects, open source tools (like the OP's), etc. In many cases, it can be cost efficient, or even (human) resource efficient to use a serverless setup.
So it gets quite repetitive to still be debating that, yes, we know there are servers running the code, it's just a name.
Also, a lot of the value in serverless lies in time saved managing said servers, which sometimes escapes engineers who are only looking at a project from the "well let's just spin up a quick VPS and install Ubuntu and these 15 packages, get DKIM working, throw a Let's Encrypt cert on the endpoint, launch a sidecar Prometheus and Grafan server for monitoring, and boom, you're done, why even use AWS?" perspective.
You are missing the point. (the "tired responses")
No, there only very few cases, such as shaving video encoding time (the one that started all this mess around "serverless")
For majority of other cases, using "(human) resource efficient" or "time saved managing servers" to justify the use of "serverless" is a plain bogus argument, since you end up shifting (best case scenario) OR spending more (worst case) time "managing the cloud's alphabet soup".
I will not even start talking about the code base mess.
Again you only spend more time if you don’t know what you’re doing.
I’m not a front end developer by any stretch of the imagination. Would it be a valid argument if I said that React isn’t a good solution because I have years of experienced with server side rendering?
Again, don’t blame the tools just because you didn’t take the time to learn how to use them efficiently.
If my name doesn’t give you a clue,I was around and developing way before AWS or hosted solutions was a thing. Being able to provision resources by writing yaml and not having to deal with the infrastructure gatekeepers is a godsend.
No, there only very few cases, such as shaving video encoding time (the one that started all this mess around "serverless")
There are millions of people using computers in countless different ways. Are you sure that you know all of the valid use cases?
> If my name doesn’t give you a clue,I was around and developing way before AWS or hosted solutions was a thing. Being able to provision resources by writing yaml and not having to deal with the infrastructure gatekeepers is a godsend.
Take some time to learn some soft skills, just enough to be able to convince people to do stuff for you, if you are the "throw over the wall ones" I recommend to get out of your sillo and interact well with the rest of your team :)
The problem with "serverless" is this kind of attitude around it.
My team and management (who is even older than I am so he’s not a young idealist by any means) are aggressively “killing as many pets” as possible and going all in on managed services and serviceless - including lambda, Fargate (Serverless Docker), CodeBuild (Serverless builds), AWS SFTP (getting rid of our sftp server).
Don’t get me started on the “cloud consultants” who were just a bunch of old school net ops folks who only knew how to click around on the web console and duplicate and on prem infrastructure.
Yes, working for small companies I’ve had to manage servers and networks back in the day in addition to development.
We would even go with “Aurora Serverless” for our non production environments if it had feature parity with regular Aurora.
I have a background in systems engineering building public/private cloud from hardware(cab and networking physical and logical provisioning) to VM provisioning automation and tooling. I've provided managed server, PHP hosting, Mail, and just about any other form of support you can imagine an ISP/Hosting provider needing to provide.
These days I deal more with full stack development and SRE type work. I ACTIVELY AVOID running servers, using tools like Chef and Ansible, and running kubernetes clusters unless there is a strong value proposition for them that can't be ignored. This despite the fact that I have no gatekeepers and ton of experience with all of them.
The poster above me does a better job of articulating the points I had, but at the end of the day, it seems to me like you are discounting an entire model of compute, part of an industry, the work that tons of developers are doing, not to mention new and interesting ways of developing new things, simply because you either don't want to learn something new or because you're attached to an existing way.
Note that I've never once said that running your own mail server is the wrong thing to do, because I don't claim to know everyone's complex environments. Instead, I'm pushing back against this habit of immediately discounting anything new simply because it replaces an older way of operating.
Fortunately the industry as a whole seems much more receptive to new things, otherwise we'd still be on mainframes everywhere, right?
> The poster above me does a better job of articulating the points I had, but at the end of the day, it seems to me like you are discounting an entire model of compute, part of an industry, the work that tons of developers are doing, not to mention new and interesting ways of developing new things, simply because you either don't want to learn something new or because you're attached to an existing way.
This mix of appeal to authority with the sunken cost fallacy makes no sense at all and does nothing to show any merit or present any technical case. Your argument boils down to launching personal attacks on anyone who has the gall to not jump onto the bandwagon you've jumped on. Yet, if you wish to make a case for a tool then you have to obligation to actually present a case and demonstrate the advantages.
Bullying those who don't blindly follow buzzword-driven development principles and resorting to name-calling just wastes everyone's time, and actually just creates noise that muffles the contributions of those who actually have something interesting to say regarding the tecnology.
> But it's still an important and interesting technology that many individuals and companies are invested in, sharing side projects, open source tools (like the OP's), etc.
That says nothing about the technical merits. In fact, it's just an appeal to popularity mixed with a touch of appeal to authority. Technologies should be judged by their technical merits.
> In many cases, it can be cost efficient, or even (human) resource efficient to use a serverless setup.
The argument in favor of the cost effectiveness of Function-as-a-Service (FaaS) offerings is exclusively in the side of the service provider. By convincing clients to give up reserving VM instances and instead switch to a glorified batch job service, service providers are able to increase their capacity with the exact same infrastructure. That's the main selling point. Afterwards, charging customers a premium to use the service is a secondary bonus.
> So it gets quite repetitive to still be debating that, yes, we know there are servers running the code, it's just a name.
Again, this line of argument is simply silly and entirely misses (or worse, avoids) the actual criticism being directed at the whole "serverless" fad. It'suite bluntly nothing more than a strawman.
> Also, a lot of the value in serverless lies in time saved managing said servers
This whole line of argument also makes no sense once we factor in the fact that containerization is a thing and nowadays launching web services is as hard as launching a batch job. In fact, some container orchestration services already support plain old batch jobs through Docker containers. Just build a container with your "serverless" code, launch the container, let the "serverless" code do its thing, and wait until completion. No "server" involved whatsoever.
Afterwards, charging customers a premium to use the service is a secondary bonus.
If I have a process that either only needs to run sporadically and/or is very spikey - web request, events, etc. why wouldn’t it be cheaper if you only need peak capacity 20% instead of paying for peak capacity all of the time when you don’t need it?
It doesn’t take an advanced degree in math to determine where the break even point between paying more per second for extreme elasticity is cheaper than paying for an always available resource.
If you’re using a cluster, traditional you’re still paying for peak capacity of your cluster all of the time.
But guess what? AWS also offers Serverless Docker - Fargate and the same math applies, you pay slightly more for the elasticity and not having to spend time managing a cluster of servers for the convenience and elasticity.
But either way, if your business is so undercapitalized that the difference between serverless and reserved capacity, you have bigger issues. Also, the more pets you can get rid of and the more automation and training of your developers you can do, if you can just reduce your infrastructure staff by one person, it will more than pay for itself.
Okay, it may very well be true that one particular serverless product is very expensive or overly complex. That’s a fine argument to make.
But that has nothing to do with whether the term “serverless” has a well-established meaning. It’s not just a buzzword, or at least it’s not always used as a buzzword and does in fact have a straightforward meaning.
If I don’t like serverless products, or I think people need to be aware of problems they might face, I should just make those arguments. I should not just say “I still don’t know what serverless means” or “serverless is just a buzzword.”
> But that has nothing to do with whether the term “serverless” has a well-established meaning. It’s not just a buzzword, or at least it’s not always used as a buzzword and does in fact have a straightforward meaning.
You're confounding two independent issues: "serverless" being a buzzword, and "serverless" not having a precise and well established meaning.
The fact that "serverless" is indeed a buzzword is indisputable. Thus the only issue that's up for debate is whether "serverless" has a precise and well established meaning.
The problem with the assertion that "serverless" is a meaningful term is that it turns a blind eye to the fact that "serverless" is expected to be an umbrella term that refers to multiple concepts, some of which are well established. For example, "serverless" is used by some people to refer to a more concrete and specific and well established concept of Function-as-a-Service (FaaS). Yet, albeit FaaS is portraied as a subset of "serverless" concept, FaaS does not represent the concept, which is assumed to be more broadly defined.
This ambiguity and vagueness opens the door to discussions on whether pain old "managed services" warrant the "serverless" buzzword, which would underline the buzzword factor by the way an old and well established concept is being rebranded. Then there are futile discussions on whether irrelevant and secondary implementation details of managed services, such as the degree of automation and auto-scaling, are in line with what is true "servelessness".
But in the end this collective grasping at straws just underlines the lack of substance behind the "serverless" keyword.
> The fact that "serverless" is indeed a buzzword is indisputable.
It can be used as a buzzword, but it isn’t always. The same goes for “the cloud.” It’s used in marketing because it sounds cool and people think they need it, but at the same time it can be perfectly clear to use the term in technical contexts.
> For example, "serverless" is used by some people to refer to a more concrete and specific and well established concept of Function-as-a-Service (FaaS). Yet, albeit FaaS is portraied as a subset of "serverless" concept, FaaS does not represent the concept, which is assumed to be more broadly defined.
What’s vague about this? FaaS is a serverless product, but not all serverless products are FaaS.
> What’s vague about this? FaaS is a serverless product, but not all serverless products are FaaS.
That was precisely the point I made. There's no need to repeat it.
Yet, you've missed the point I've made subsequently, where I've specifically pointed out how the fact that the "serverless" buzzword is being tacked onto old and established technologies such as plain old managed services.
As if the time to manage servers is free. But lambda is far from expensive. If you’re spending even $100 a month on lambda, you probably have a successful business.
And everything is “complex” if you don’t know how to do it optimally.
I work in projects which make heavy use of function-as-a-service, and I have first-hand accounts of how FaaS offerings have lead developers to waste a couple of weeks getting FaaS to do what could have been done in a couple of hours with a tried-and-true web service.
> But lambda is far from expensive.
Relatively to the cost of a VM instance? Yes, it's expensive. We're in a day and age where a vCPU with 2GB of RAM can be had for 3€/month, and the pricing examples posted on AWS Lambda's page show a scenario where slightly over a month of function run time requiring 512MB of RAM would cost around $18.
In addition, AWS lambda usage is rounded up in intervals of 0.1s and 128MB, thus inexpensive function calls are way overcharged.
> If you’re spending even $100 a month on lambda, you probably have a successful business.
This assertion is missing the fact that those $100 a month on lambdas might be handled by $10 worth of computational resources in the cloud and a software architecture that isn't convoluted or tied to a single vendor. Thus the fact is that a fad is being pushed without technical merit or sound operational reasoning.
We have a Jenkins server for builds. Most of the time, you push code and the build starts immediately. However, at times we have 10 builds in the queue and you’re sitting there waiting for your small build behind larger builds.
On the other hand, we’ve started moving to CodeBuild “Serverless builds”. When we aren’t running builds, we aren’t paying for it. However when crunch time comes, we can run up to 50 builds simultaneously (you can request a larger limit). How much would it cost to have build servers that could handle peak demand and how much of a waste would it be to have that server sitting idle?
And if you’re worried about the difference in cost between $100 and $10, you’re not running a business.
Will that $10 a month server scale up with demand?
As far as it taking “two or three weeks” - “its a poor craftsmen who blames his tools”. Don’t blame AWS for the missing skillset of your developers. There is no reason that it should take your developers any longer to build an API with lambda instead of a server.
In fact, you can host the same APIs with lambda by only adding two or three lines of code and using proxy integration.
You either completely missed the point or you are too invested in going off on a tangent to try to change the subject.
The $100 vs $10 was not intended to argument the merit of $10 savings: it refutes the absurd claim that $100 expenditures justifies adopting a convoluted architecture, because the fact is not adopting a convoluted architecture is actually much cheaper.
Additionally, somehow you've brushed aside the fact that the main cost is developer time, and a convoluted solution based on flavor-of-the-month tech fads requires more maintenance and developer man-hours than basic tried-and-true solutions like standard run-of-the-mill web services.
> How much would it cost to have build servers that could handle peak demand and how much of a waste would it be to have that server sitting idle?
I honestly fail to see what point you're trying to make because: a) you don't need "serverless" services such as AWS lambdas to get CICD pipelines to work, and b) cluster autoscaling is a basic offering provided by pretty much all major cloud providers. Thus, what's your point?
> As far as it taking “two or three weeks” - “its a poor craftsmen who blames his tools”.
So any proof that refutes your baseless assertions is brushed aside by your "you're holding it wrong" baseless assertion? Doesn't sound like a discussion on technical merits.
You're underlining the biggest problem with buzzword-driven development: the lack of technical merit is a constant and everything boils down to petty personal politics.
Your “proof” is an anecdote that was easily disproven by a link.
If it takes your developers two weeks to host an API in a Lambda when I showed you a link on how simple it is. It says more about your developers than AWS.
My time is far from cheap and any time that we can spend letting someone else do the grunt work is valuable.
> Your “proof” is an anecdote that was easily disproven by a link.
Real-world problems don't go away when you try to brush them aside. You either face the facts or remain in fantasy land.
> If it takes your developers two weeks to host an API in a Lambda
Please don't put words in other people's mouths. You have absolutely no idea about what the problems were and already made it quite clear that you don't care about facts or reality, and simply prefer to fabricate accusations to avoid discussing technical issues. That speaks volumes about your own competence and technical ability.
I’m going by the only facts that you offered. You said that it took your developers two weeks to do something that should only take an hour. I showed you an example of how to host a standard API or website within lambda with minimum effort.
If your developer haven’t come up with processes to efficiently manage their development and deployment processes - it’s a process issue that others have already solved.
You did not. You fabricated accusations to fill gaps in your comprehension based on your imagination alone, and proceeded to use your made-up accusations to attack others. That's not cool, and just speaks volumes regarding your lack of arguments and your ability to contribute to a discussion.
I have first-hand accounts of how FaaS offerings have lead developers to waste a couple of weeks getting FaaS to do what could have been done in a couple of hours with a tried-and-true web service.
There is no world where a competent developer who knows his tooling should take “a couple of weeks” to set up an API on lambda that would only take “a couple of hours on a web server”.
You can treat a lambda instance just like a web server by using API Gateway, proxy integration and simple to use function provided by AWS that translates the lambda/APIGW event to a form that your framework expects.
Hosting static content on S3 (css, JS, html) is a click of a few buttons. Copying your content is a simple “aws s3 cp” command to do an “xcopy deployment”.
I'd rather be on call for a serverless system than otherwise. Getting paged at 2am because some log file filled up a disk, or a million other details that your "couple of hours" solution didn't take into account? No thanks.
> I'd rather be on call for a serverless system than otherwise. Getting paged at 2am because some log file filled up a disk, or a million other details that your "couple of hours" solution didn't take into account? No thanks.
How about getting paged at 2am because somehow a lambda called by AWS step functions workflow is failing due to hitting a timeout while uploading a 20MB file to a S3 bucket? Because this is an actual real world case that happened in the real world.
Well, with step functions you can have auto retry with exponential back off in case of failure. But you had a lambda that couldn’t upload a 20Mb file to S3 in 15 minutes? Whatever the issue was, you would have more than likely had the same issue with a VM. A lambda runtime environment is nothing special for all intents and purposes but a Linux VM with well known constraints - a 512MB /tmp storage, and up to a 15 minute runtime.
> Not a single post on Hacker News can use the term "serverless" without the exact same replies being posted every time.
Indeed.
> It's as if a certain portion of the HN crowd simply cannot fathom that a new term exists and is in use, and instead resort to the same, tired responses.
If was only "a certain portion/crowd" it will have no responses at all.
I see more like:
"It's as if a certain portion of the HN crowd simply cannot fathom that servers exists and is easy to use, and instead resort to the same, tired responses."
> Serverless computing is a cloud-computing execution model in which the cloud provider runs the server, and dynamically manages the allocation of machine resources. Pricing is based on the actual amount of resources consumed by an application, rather than on pre-purchased units of capacity.
So I don't see too much of a difference from a VPS I pay for that will cost me more if I start using more network bandwidth.
But then I hear that you don't have ssh access and that your architecture is built around one specific vendor, so now you can't move to a different provider. Sounds like hell to me.
If I don’t have any messages in my queue/request to my API/messages in my stream, I am not paying for VMs or networking.
If I have thousands of messages in my queue, enough runtimes are started to handle the messages with the throughput I configure.
And as far as worrying about one vendor, the lock in boogeymen is vastly overrated. Once you have any type of scale, even if you are just using a bunch of VMs (and if you are you’re spending more money for a cloud provider than just using a colo without any of the benefits), once you have your data in the databases, network configurations, your security rules, your connection to the cloud provider with sitters Direct Connect, a site to site VPN, client to site VPNs for all of your developers, you’ve gone through security audits, etc. you’re for all intents and purposes locked in anyway where the pain of migration will be a multi month project with little to show for it.
It’s like all of those bushy tailed architects who are going to use the repository pattern and not use any database specific SQl just in case one day the CTO decides to move away from their six figure a year Oracle installation to Mysql.
I've found that "I don't even get what the word is supposed to mean" is someone's first experience with tech fear. In my experience (including my own personal anecdata) they tend to mean "I don't want to learn this new thing and because of that I'm worried I'll be left behind if everyone switches to this"
I also don’t get this. I’ve been programming either professionally or personally for 30+ years. But this isn’t a new phenomenon.
Back in the early 90s you had an “Apple II Forever” movement with people still holding on to their 8 bit Apple //e’s while Apple and the rest of the world moved on.
> I've found that "I don't even get what the word is supposed to mean" is someone's first experience with tech fear.
This is a gross misrepresentation of the actual problem affecting the "serverless" fad, which is the buzzword overload accompanied by a lack of objective definitions. Function-as-a-service (FaaS) is an objective, clear-cut concept, but "serverless computing" is supposed to be a more general term where FaaS is only a realization of the concept. Yet, by keeping the concept as a buzzword then the proponents actually avoid having to argue the merits and the advantages of this sort of architecture, thus contributing to the growing skepticism.
"Cloud" has gotten even less specific technically as new marketing uses for it become established. What do bare metal private cloud and Google Docs have in common, anyone?
As I wrote in another comment, there is a world of software outside of web development. And I'm not especially fearful of being left behind. I spend almost all my free time learning new things. But I wouldn't really jump at the opportunity of learning something that locks me into a single company's services. Learning the fundamentals of computers seems like a much better use of my time.
A lot of concepts that apply to serverless and other cloud computing services are applicable across providers as well. Even if the details are different.
I would liken it to learning programming languages. Learning new languages isn't considered "locking you into a language". It's even widely considered beneficial because it makes learning more languages even easier and brings new perspectives to the table.
Edit: An interesting example. Learning something enough to know when NOT to use it is gaining a valuable skill that's worth $$ to employers.
> I would liken it to learning programming languages. Learning new languages isn't considered "locking you into a language". It's even widely considered beneficial because it makes learning more languages even easier and brings new perspectives to the table.
Partly true, if you don't plan on using the language. But this seems only true, because the majority of programming languages today are open source and portable across different platforms. On the other hand, some time ago C# implied .Net Framework and that would lock you into the Microsoft+Windows ecosystem.
In the same way, using SQL that's understood only by PostgreSQL isn't going to be as much painful as using something specific to Oracle databases when the company behind it goes haywire as Oracle did with Java (if not for OpenJDK).
Because after you have “learned the fundamentals” it takes a lot longer to “learn” how to write a function that takes in two parameters, zip it up with all of your dependencies and upload it....
I suspect the "serverless" word was created due to the emotional appeal to a specific (majority) group that is strongly opinionated against having servers at all.
Reading from the README.md file:
There are two major limitations with SES:
For security reasons, AWS defaults to 200 emails sent per 24 hour period at a rate of 1 email/second. If you need to send more than that, you'll need to ask AWS to increase your limit.
By default, you can't send emails to unverified addresses. If you'd like to be able to send (as opposed to just receiving), you'll need to reach out to AWS to remove this limitation from your account.
I see zero benefit in having complete vendor lock-in, non-sense limitations, seriously, with a $5 VPS can send at least 300 emails per minute.
I find these absurdly limited mail services strange. The one time I had to craft some "extra" email, was sending out surveys to an opt-in group for an EU project. There were some 10 000 recipients, and we had to send each a different email, in order to link responders with surveys (ie: a template email with description and an unique url of the form https://example.com/survey/123xyz).
Generating the emails in a naive loop and sending them via python took an insignificant amount of time - but in the end we worked out doing batches of 2000 at a time was easy enough - and with some help from the college that ran the email service (via exim) it all worked out (if you're going to send 10k mails in a day, it's nice to give your postmaster a heads up).
Hosting the mail server ourselves (using eg exim or postfix) would've worked too. Not sure about any of the spam-as-a-http-api services - even with custom domains they tend to have poor reputation, and they have these silly limits that mean they're not only not "auto scaling" - they're very low performance.
The problem is spam. The big providers providing hosted emails do a lot of work to make sure the emails people send with them actually end up at the recipients inbox and not in spam quarantine - but that doesn't work if the provider is then used by spammers. So the limits are set to discourage spammers while making most use-cases for email still possible.
If one were to ask me what to do, I'd say emails should cost 0.1 cent each, to be paid to the recipient...
The emails sent by your $5 VPS wouldn't stand a chance of actually being delivered to people's Gmail or Outlook mailboxes. Whereas SES actually works.
Also, it is incredibly easy to ask AWS support to increase the limit. A startup I worked with had only thousands of users; we told AWS about it and they gave us 5 million emails per 24 hours.
By all reports of people who have set up their own mail server lately, just having SPF and DKIM set up still won’t cut it for delivery to the major mail providers these days.
I run my own email server, with no spam filter, and inspect where every spam comes from. I get a lot of spam from random shitty providers, but none from major VPS providers (Scaleway, Hetzner, Linode, Digital Ocean, ...) with the exception of OVH.
I do however get spam from Amazon SES a couple of times a month.
All those limits are removed within hours and are one time support ticket requests. AWS doesn't want every account to be instantly usable as a spam account if someone is compromised.
I think the more significant annoyance would be the lack of IMAP/POP, I don't see how that is addressed.
Serverless is beautiful. You just need to try some basic serverless concepts. Like run a website on S3.
But to your second point, I agree. the technical hurdle required to learn all the configuration and moving parts ... And then to know that this language is vendor specific... Makes it less palatable.
That's why I expect the cloud vendors to normalize their offerings over time. I should be able to take a CloudFormation template from aws and put it through Googles Deployment Manager
Managed hosting is used in at least two different ways:
* As a synonym for dedicated hosting. E.g. you rent a machine, and run what you want on it. And have to patch stuff etc.
* As a separate tier of service above dedicated hosting where the hosting provider is responsible for running the services on the machine. Some managed hosting providers will take responsibility for scaling too, though often it will be a semi-manual process.
Managed hosting in this second sense is to serverless what dedicated hosting is to "regular" cloud instances.
You might even toss in running managed services externally in the second definition, for example DNS for your own domain - pretty much every service small to large offers a DNS hosting service with your account, typically at no charge. Otherwise, you'd have to run your own server, etc.
> When you are just using a VM - it’s your responsibility to keep the VMs and the runtimes patched, design a scaling solution, etc.
Your comment did nothing to address the point, which is that your definiiton of "serverless" is actually just a buzzword used to refer to the old as the web commercial practice of managed hosting.
Serverless is not just “managed hosting” in the cgi-bin since - serverless implies there is no server to manage and it’s for all intents and purposes “infinitely scalable”.
For instance, Amazon’s hosted versions of Mysql, Postgres, Sql Server, etc are not what they consider “Serverless” you still have to size it appropriately and if your needs increase, have to move to a larger server. You have to worry about CPU utilization, memory utilization etc.
DynamoDB is considered “serverless” because you don’t have to manage any of that.
The same is the difference between S3 and provisioning storage that you attach to your VM.
Please don't digress. The questions regarding you assertions on "serverless" don't change or are addressed with your attempt to divert attentions to other buzzwords.
> Serverless is not just “managed hosting” in the cgi-bin since - serverless implies there is no server to manage and it’s for all intents and purposes “infinitely scalable”.
You're running in circles by trying to pin a buzzword on managed hosting.
> For instance, Amazon’s hosted versions of Mysql, Postgres, Sql Server, etc are not what they consider “Serverless”
I wouldn't use AWS as an example of coherent classification, as AWS's database offerings have multiple ovelapping concerns, including an overreaching gray area of "serverless-ness". See for example Amazon RDS and Amazon Aurora.
Yes Aurora Serverless is a distinct offering. Regular Aurora you have a certain server of a certain size. Aurora Serverless autoscales - just like lambda.
> Aurora Serverless autoscales - just like lambda.
If you're confused to the point of confounding autoscaling with serverless then I'm afraid there is no point to continue this discussion. You're just underlining the fact that "serverless" is a fad being mindlessly disseminated by clueless proponents.
Well, no I’m not “patently wrong”. Aurora Serverless has limitations and features that are not available with Aurora. This includes lacking the ability to load and unload from S3 and it has the “Data API” which lets you use APIs to interact with the database instead of your typical database connections. This feature is not available with regular Aurora. It was implemented specifically for Serverless workloads so your lambda doesn’t have to “run inside your VPC” since that increases the cold start times.
We specifically could not use Aurora Serverless for our ETL jobs because of the lack of integration with S3
Again there is a difference between reading documentation and actually using it.
I’m also not confounding “Autoscaling” and services. Being able to scale on demand and “scale down to zero” is one of the parts of how Serverless is defined.
>cgi-bin didn’t have any type of process isolation
"Lambdas" don't by nature either. I can run cgi-bin in a FirecrackerVM-like ecosystem with one script per VM.
>Also, it didn’t tie in to other none web based events.
Webhooks aren't new.
I'm not disputing the popularity and convenience of serverless. I'm just noting it's somewhat like Docker. Packaging existing tech in an easier-to-use bundle.
Lambdas by nature do exactly that. AWS’s runtime launches the “VMs” in response to an event.
And with webhooks I’m required to keep enough server capacity running all of the time to handle the events. Can a web hook automatically instantiate enough VMs on demand without reducing throughput?
That still begs the question, why am I as a developer wasting time fiddling with infrastructure that I could just throw a little money and a yaml file at AWS and let them do it? How am I adding a business value that will make my company money doing grunt work?
cgi-bin had pretty strong process isolation for the day (Unix user account and process boundaries/limits/quotas). Enough to have remarkably robust multitenant setups on single servers.
Could Godaddy’s side business launch isolated VMs when items appeared in a queue? A file appeared on a server? Events came from a stream? Could it respond to any events besides http?
To you. But the world has moved on from Apple 2e and now managed hosting is analogous to serverless.
See because only science has a concrete fixed point for measuring which is the speed of light.
Human culture is subjective buzzwords where the only relative fixed point is when they learned a term.
Serverless is “managed hosting 3.0”.
First there was bare metal, run your cage. Then ec2/traditional VMs. Now just an ephemeral thread.
Computer people need to stop thinking in terms used by product & marketing people. Reasoning around it from the perspective of how it’s implemented specifically helps with the understanding.
It’s a Linux OS wrapped in layers of UX to facilitate composition of services. Unix command line tools at scale.
Cloud provider is just an OS at scale. They handle CPU, memory, scheduling, etc., all the same things a desktop OS does from the end user perspective, using a different process model we don’t generally care about as end users
Hopefully OpenAPI will help normalize this interface. Who knows though. Rich people like to drag their feet when they think sticking with the status quo gives them an advantage. Bezos may feel like making it easy to copy paste away from his cloud is a shitty idea
I can’t tell what your point is. I’m agreeing that managed hosting is the next evolution.
But Lambda is more than just for APIs. But if you’re worried about the “lock in” boogeyman for APIs, there are small packages for every language that lambda supports that allows you to run your standard Node/Express, C#/WebAPI, Python/Django/Flask API, etc on lambda just by changing the entry point.
Right now I’m deploying a Node/Express app to both lambda and Fargate (Serverless Docker) withoit any code changes.
My biggest problem with the "serverless" term is that it's a solution to a few different problems conflated into one term.
* Not having to manage a server.
* Not having to have dedicated resources which can be wasteful.
* Having an architecture that scales.
When most people talk about serverless, they mean something that solves all three of those problems. When I think of serverless, I think it only needs to solve the first problem.
What if I don't want to manage a server, but I want dedicated resources? I just want to deploy a standard web app (written with node js for example) with a postgres backend and preallocated resources but without having to maintain a server? Is that serverless?
I don't get the faux-naivety over the term "serverless". Most modern cars have "keyless" unlocking and ignition, yet.. you still need a key present. You just don't have to think about or manipulate the key. Serverless is much the same.
Probably this means that there is no server you can SSH to nor need to maintain.
It could probably be called a serverhostage/server-lock-in computing, where someone else keeps the _shared_ server(s) away from you and runs other people's, potentially harmful, instructions as well :-)
Ok, so "serverless" is just a buzzword that doesn't really have a good meaning. That's doesn't really matter. To me it's just easier and actually meaningful and objective to refer to services like AWS lambda as "Function as a Service".
It is in the cloud. It's different in that you don't have access to the cloud server, just a service on it.
To me it's like having one hand tied behind your back while someone else uses their hand to do what you'd have done with the one tied behind your back. It's cheaper, sometimes it works the way you want it to, but you always feel a bit restricted.
> It's cheaper, sometimes it works the way you want it to, but you always feel a bit restricted.
The "cheapness" argument is open to debate. So far the main argument I've seen for Function-as-a-Service offerings is that it's cheaper than just paying for a VM instance to run a dedicated service. To start off, a dedicated VM can cost about 5€ a month, which represents the absolute total saving that is supposed to be driving this discussion. Even if we ignore this fact, if you already have VM instances running somewhere then you certainly have enough computing capacity to spare to run these compute tasks without having to incur in extra charges per function call.
a VM can cost far less then $5 a month to run, depending if your bussiness is large enough and can run (or have it run for you) its infra properly.
I once did some simple estimation of a cost of a VM inside our own infrastructure, and the costs was something around a euro or less.
A single, modern server can hosts a crapton of VM's, especially if you have a competent operations team inside your bussiness who builds tooling for it.
The less pessimistic interpretation is that it's like having someone else be your devops department. Unlike what people like to think, most people running traditional VMs and containers end up doing just as much devops as on a dedicated server (while doing consulting, I'd typically get more hours at higher rates out of people insisting on AWS, because getting an AWS setup right is a lot of work), so serveless is appealing as a way of making more of the devops stuff someone elses problem.
I get your feeling - I like to be able to ssh in as well, but then I see people I've worked for, and realise that to most of them having ssh access does no good, because they don't know how to troubleshoot over an ssh connection, and they don't want to have to know.
To them, losing that flexibility doesn't really matter, because they weren't doing it anyway.
It's more than SSH access that you give up though. You have to bend to the paradigm completely or you're really fighting against it.
For one example, I keep running up against wanting to delay an execution of one lambda from another. There are some truly horrible hacks out there to try and achieve that.
Absolutely. Frankly I think in a few years time we'll look at Lambda the way we look at people dumping php scripts on a shared server today. It needs a lot of thinking before serverless fulfills its long term potential in those respects.
The irony is that a whole lot of the solutions are well understood; just not in the same environments. E.g. "enterprise" computing went through a whole cycle of building application services for small self-contained components with discovery and messaging in the late 90's that people seem to have largely forgotten as somewhere to look to at least for a laundry list of what kind of services are needed.
When you are “running it in the cloud” with a traditional VM you still have a server that you can log into, that’s always running, requires patching and if you get a spike, you have to set up your own scaling policies and it will usually scale more slowly.
>...so, there is a server? What's with the name, then?
The name is just a marketing gimmick. Absent any other context, "serverless" seems like it must be a paradigm shifting technology so sufficiently advanced that it renders servers obsolete, as if by magic.
It's the same sort of trick that people sometimes pull when they show off an application to "do x in 10 lines" (or some absurd low number), when the app is just making API calls to a remote server running several million LOC.
It's an annoying marketing term, sure enough, but the ideas it names aren't terrible. It's not always a mistake to pay someone else to take care of maintenance, scaling and security.
It’s more than just a managed service. RDS is Amazon’s managed database cloud service, but you still provision and pay for a specific virtual server with a certain number of CPUs and amount of RAM. “Serverless” generally implies that you do not provision any server hardware (even virtual) and instead only provide application code.
I’m no expert, but I think you run RDS on an EC2 instance, so it’s basically just a normal virtual server running Amazon’s managed version of the RDBMS. I’m not sure what happens if an instance “fails” but I assume you can have downtime if Amazon needs to move your VM, just like EC2, but I assume Amazon handles moving the instance and restarting it.
> I think you run RDS on an EC2 instance, so it’s basically just a normal virtual server running Amazon’s managed version of the RDBMS
Yes I think that's right. That is to say, it doesn't give you replication.
> I’m not sure what happens if an instance “fails” but I assume you can have downtime if Amazon needs to move your VM, just like EC2, but I assume Amazon handles moving the instance and restarting it.
No need for the quotation marks, that's the correct terminology. Your suspicions seem to be right on - it looks like RDS handles instance-failure for you, with non-trivial downtime, but no data-loss. [0]
Serverless: abstracted services that don't require you to know or care about the underlying server.
It's still not perfect, sometimes you do need/want to know/care, but it's usually superficial -- e.g. what libraries are installed by default so I can optimize the build.
No, and this is why we have a bunch of old school Net ops guys who pass one certification, call themselves “cloud consultants”, do a bunch of lift and shifts and leave clients paying more than just using a colo.
IaaS = your data + code to run it + create servers to run the code.
PaaS = your data + code to run it. Servers automatically provided.
SaaS = your data. Code and servers are automatically provided.
Serverless is just another name for PaaS where your bring your code, which can be deployed as a single JS function in a text file or an entire container running anything.
Higher level of execution abstraction. With cloud execution granularity is an instance on a server somewhere that you have to deal with. With serverless execution granularity is your bit of code "function" and cloud now provides not only processor but also a software platform to execute your logic.
You have a service and give it a role that has some permissions. If you want to have the minimal permissions probably would at least end up with services*2 roles&policies if you write a custom policiy for every role, so the service can't do more than needed.
I mean, you could probably calculate one role and one policy for all the stuff that runs, to make it really simple, but I don't think this will make it secure.
But, yes, I don't like IAM either.
I read some people don't even use it anymore, but I didn't find out what they are doing instead.
One of the things that characterizes our culture in Cybernus is language.
As we aimed to be an ever evolving civilization, it was decided that our language should then be, also, ever evolving. Once a month, during The Update -our most significant celebration where new discoveries, thought trends, etc, were presented to the population at large- a time was reserved for the ritual of language renovation. A number of random words, somewhere in the range of 30 to 50, were marked as outdated while a similar number, again from 30 to 50, of new words was introduced into the language as the words to show you were current with your civic duties of evolution and progress.
Usage of so called outdated words wasn't re-classified as a crime until much later, and only as a way to better enforce the goal of Continuous Progress. For some time you were just seen as an outcast or simply as one of the billions of poor people. Poverty was not so much defined in economic terms mainly because it wouldn't have meant much, with what happened in 2043 and all that. Instead being poor now meant you were someone that did not have access to enough information to participate in the careless happiness of Continuous Progress. But as I said, not keeping up with language evolution is now considered an offence and repeater offenders are forced to undergo re-adjustment.
Of course, after a short period of going through this, it was noticed that it's not so easy to continuously come up with new words and not make the language a unintelligible garble. And so words are recycled rather than discarded, which was a wasteful and unsustainable thing to do anyway.
-- Excerpt from "A Visitor in Cybernus" - a "recollection of future history" from Sean M. Ferion. 2007. Sadly out of print and very difficult to find.
It means you string a bunch of shit together via aws lambda instances and docker microservices
If its any consolation, at this years Vegas AWS love-fest, most people started walking out once the Amazon presenter started talking 'serverless' recipes
It's pretty well understood by now that serverless is meant to connote that you (the firm owning the application) don't manage the server(s). Someone else does it while you just bring your application code.
It’s no more “misleading” than having a “bug” in your code. Does anyone with even an iota of computer experience think “Serverless” means that their software is being run by leprechrauns?
Nowhere else on HN is willfully not taking the time to learn about technology celebrated except when it comes to cloud concepts.
“the more you understand about farming, the more absurd it is to call them server farms.”
“the more you understand about biology, the more absurd it is to call them bugs”
“The more you understand about meteorology the more absurd it is to call it ‘the cloud’”
Yes, if it weren’t for people on Hn educating the poor unwashed masses we would all think that our software running “Serverless” was being run by elves at the North Pole.
Do you also complain when people say they have a “bug” in their code or that they have a “server farm”? Are they literally watering the server floor and waiting for computers to grow?
Not at all. It's in this case, using the term serverless is akin to calling cloud based software (Google Docs, TurboTax, etc) softwareless. It's closer to calling a stop sign a "go sign" than descriptors from your example. Calling managed servers "serverless" is distinctively misleading.
How is it any more misleading than “bugs”, “containers”, “the cloud”,”server farms”, etc.
Wouldn’t you be the first to criticize someone who didn’t take the time to understand other computer concepts that had been around for years and then attempted to speak intelligently about them?
It's misleading because "serverless" intuitively means peer to peer, where everything runs on clients and there are truly no servers. So unlike "bug" it has an intuitive meaning that is the opposite of what the buzzword now means.
The term serverless is not a metaphor like your examples, it's a contradiction. Big difference. I feel like understanding the "computer concepts" makes the term seem even more absurd.
You’ve never worked with C code that had to run on both big endian and little endian systems that had to share a common byte protocol. Where two bytes in the same order can mean something completely different.
There are a lot of things “confusing” about computer science when you don’t take the time to learn it.
On the contrary, I've worked with 8 and {32,64}bit x {LE,BE} chips many times and wrote quite a lot of network code in C. But you're mixing syntax with semantics.
Which byte is the high order byte is just as much semantics defined by the chip vendor that would be confusing to the uninitiated as “Serverless” would be to an old school net ops person who doesn’t know anything about cloud computing.
It isn't a great name, but: it doesn't bare a contradiction in itself (contrary to "serverless"), there was already a tradition of drawing unspecified networks or internet as a cloud in diagrams. So "running in the cloud" as running "somewhere in the network we used to draw as a cloud" has an explanation.
Also note, I didn't state that there are only two types of names. I commented on what "bug" and "serverless" is.
I think and hope this guy is trolling. If not he will be left behind if a back end dev. Even if you have"real" servers this is how your micro services should be built.
Thanks for putting this together and documenting it so well. I’ve had to build this solution twice now, and far less elegantly.
The S3 PUT charges caught me off guard the first time (receiving lots of marketing/spam email will cost $1/1000 emails). I ended up putting small emails up to 400 kB in dynamoDB and only using S3 for large emails and attachments, which could be a means of cost reduction in this solution as well.
I’ve been working on a small side project that involves processing incoming email. In particular, it’s an app that needs to do something for each email it receives from (hopefully paying!) users.
I am not interested in storing user mail, so SES is just too costly, at least according to a quick worst-case calculation.
That leaves me with two options:
1. Self-hosted Postfix
2. Mail service like Mailgun
With (1), there is no need to worry about overages, but scaling the mail server might be challenging.
The advantage of (2) over SES is that you are only charged a flat fee for each email, regardless of size. Emails are then automatically deleted after some period of time. Scaling up and down is easy.
For now, I am using Mailgun, but I am writing the mail processing daemon in a way that will make it easy to transition to Postfix, if needed.
Also, I decided to write the mail processing backend in Rust, so I’ve been learning the language as I go!
> I’ve been working on a small side project that involves processing incoming email. In particular, it’s an app that needs to do something for each email it receives from (hopefully paying!) users.
I wish you all the best! Mind if I ask for the link?
> With (1), there is no need to worry about overages, but scaling the mail server might be challenging.
Honestly, quite the opposite.
1. Duplicate your MX box.
2. Duplicate your MX record.
That is it :)
> I am writing the mail processing daemon ... in Rust...
You might like to take a look in https://github.com/mailman/mailman for ideas/inspiration. It's a great tool for processing emails too, but cannot deny I'm now curious to see how one in rust will look like.
Yes, I only learned about MX record priorities last night haha. With Postfix, the most straightforward way to run code on receiving an email seems to be through a pipe filter. Running multiple filter processes probably requires a beefy server.
Thanks for that link! I might just use a similar approach to allow users to configure how to receive emails (HTTP or stdin, etc.).
Then limit the number of filters... you can have postfix run a fixed number of smtpd processes, and each process handles only one message at a time.
When they're all full, your server will just stop handling messages, but SMTP will retry anyway, giving you plenty of time to scale up if the load is consistently too high
I’m actually doing something similar, I opted for SES, S3 and Lamda, I am a bit worried about costs, especially when i need to scale up, and handle larger emails.
Seems like a crazy amount of architecture. Does AWS keep all this stuff organized in some way, or will my personal experiments in Lamba accidentally break this because it's all merged together?
Say I've installed this.
I now want to write my own lamba service to handle contact form POSTs or something. Then I decide to delete it, but I accidentally delete one of these crazy email things. What happens?
>his day there's no easy way to have a full email server without the overhead of installing and configuring all servers needed to handle incoming and outgoing messages.
Most serverless offerings are somewhat compatible with a pitcher of greasing. It would be a doable exercise to duplicate this codebase for a few other platforms.
My take away is that you'd be able to receive your emails and customize the handling of every email.
i.e. emails are received and put into specific buckets/folders and then, per message, a process is triggered to do something unique (put into database, forward to another IMAP'ed box, etc.)
JMAP is a radically different beast. The similarities between this thing’s JSON format for sending and JMAP’s Email data type are superficial only: they’re both JSON and are representing the same thing, so it should be no surprise that they look similar. But that’s a quite tiny part of what JMAP is: JMAP is an object synchronisation protocol. (And this is why JMAP so much more complex than the typical REST API. And why I prefer it so much.)
I also think the JSON here is only for sending, not for receiving—I presume that you’ll receive the MIME message, because otherwise you’d be throwing away all kinds of essential information.
All of this gets you basically nowhere along the path to JMAP, and achieving a JMAP endpoint would be a lot of effort. This project doesn’t look to be at all suitable as a base for such an endeavour. Things like sorting (e.g. newest first), querying (e.g. emails from so-and-so) and JMAP’s state management (so the server can tell you “something changed” and you can ask the server to tell you what changed since x, rather than needing to throw everything away and start again) don’t work well within the design of this system—you need to store lots of extra details along the way, maintaining indexes and other such things.
For such an endeavour, I would instead recommend either wrapping an existing mail server in serverless voodoo (much of which I expect to be not too hard: you’re essentially just replacing ingress and egress and not running it as a daemon; but there will be architecturally difficult parts like getting push channels working probably), or starting new mail server software from scratch designed to be able to work serverless.
(I work for Fastmail on our webmail. I have general knowledge of how mail servers work internally, but little specific knowledge; for example, I have no idea how amenable Cyrus, which we use and develop, would be to serverless packaging.)
For the record it seems this seems to do some basic processing:
> The Inbox or Sent folder triggers another Lambda function that loads the raw email, converts it to a .html and .txt file, and stores it alongside the original message, while storing any attachments in the attachments.
This looks OK for me having clients do indexing and processing. From your description it seems JMAP choose a different tradeoffs and puts more services on the server side.
This project seems to be designed more for a process-and-delete workflow, whereas JMAP is designed as a general-purpose object synchronisation protocol on which you can build arbitrary email clients.
Authenticating the actual sender vs. authenticating the server or service controlling the domain for reputation purposes.
If you trust Amazon enough to use their cloud services, there's little reason not to trust them for the latter. Doesn't mean trusting them with respect to the former.
Things like DKIM makes no assertion that the content was sent by the right person; just that whomever controls the domain has trusted the service in question to send e-mail on their behalf.
Making the data someone else's problem. :P One cool thing with the cloud is that you can work with the data without it leaving the "cloud". If the consumer of the data, eg the e-mail client is also in the cloud, it really doesn't matter where the HDD is located.
{kind=link}
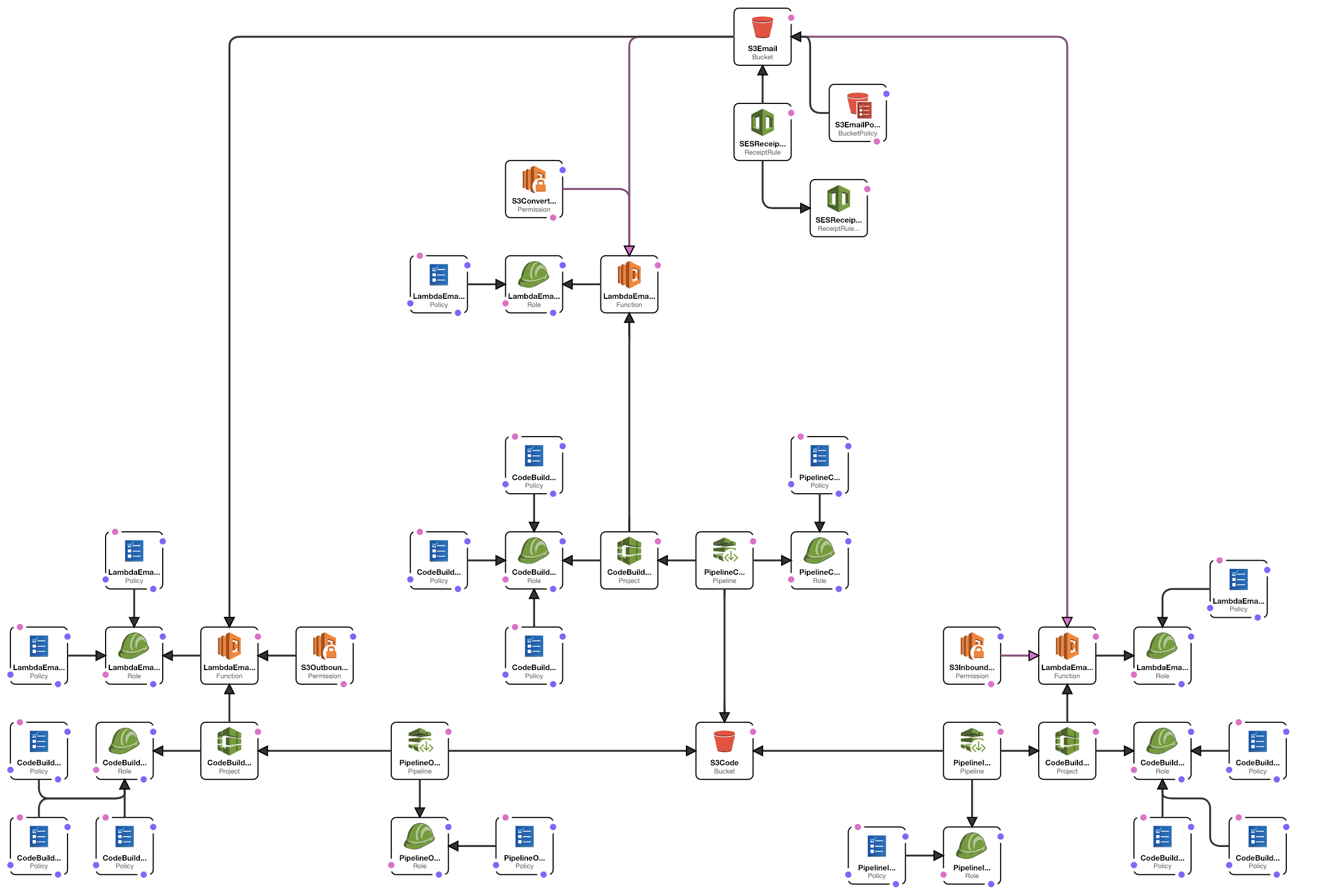{kind=link}
Interesting approach, though I solved this frustration by the use of a Docker and kept "my data is mine" + "no vendor lock-in" + "I control all the gears" approach. (Though, it's not perfect since VPS is ran by "someone" else.. but that place where you run this stack can be easily changed at your convenience). Simple docker-compose.yml with 3 images and voila.
This AWS S3 SES setup looks far more complex than what I did using only 3 docker images: the postfix (for smtp), dovecot (for imap), opendkim (for email sigining & verification). It's really easy to fire-up a VPS with a single click nowadays.
If someone is interested in the images I am using:
- https://git.nixaid.com/arno/postfix
- https://git.nixaid.com/arno/dovecot
- https://git.nixaid.com/arno/opendkim
Then you just feed the images with the right configs (main.cf, master.cf, .., dovecot.conf, opendkim.conf).
It's also possible to template the configs and make the variable-based configs. Make things scale friendly. I am also using Terraform to automate the server deployment/DNS record updates so it is easy to get from 0 to 100.
The only drawback is that you are the one to maintain the OS/SW upgrades, security, etc.. but that's something I really want to do by myself instead of relying on someone else :-)