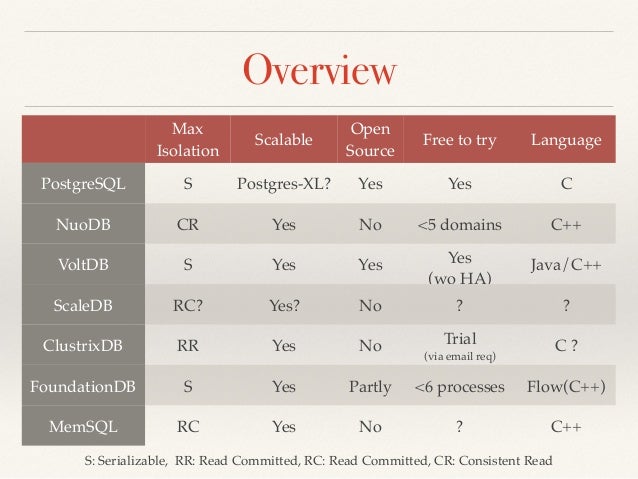
For anyone else too lazy to read the slides to find out what NewSQL is, this is slide 13:
NewSQL: definition
"A DBMS that delivers the scalability and flexibility
promised by NoSQL while retaining the support for SQL
queries and/or ACID, or to improve performance for
appropriate workloads."
451 Group
It's a shame that most of these aren't open source.
At one point I had great hopes for RethinkDB. It seemed like a great fit when I first heard about it: It's among the newer databases, it's open source, MVCC, distributed, sharded, multi-master, and has a neat query language with some advanced features.
Unfortunately, while RethinkDB does feel very pleasant and modern, performance is pretty terrible, and it's quite lacking in some other areas.
We're still optimizing the performance of certain operations. There are definitely still a few rough edges, especially with analytical queries as you'd pointed out.
As far as basic operations (inserts, updates, retrieving documents etc.) are concerned, RethinkDB already has competitive performance and we hope to publish official benchmark results soon. As you know, good, comparable benchmarks aren't easy, and we're currently spending most of our time on improving RethinkDB rather than working on those. But they're definitely coming.
This is just a guess, but a query involving COUNT(*) might execute faster with PostgreSQL since it can use an index for making the count basically a constant-time operation, while RethinkDB doesn' currently support this. That is definitely a missing feature on our end.
If you get a chance, I'd be very happy to hear from you about the specific queries and the data you'd been testing, so we can look into those specific performance problems. My email is daniel at rethinkdb.com .
Benchmarks are indeed hard, which is why I only posted a very specific couple of numbers.
Postgres isn't using an index for the count. When you're essentially tallying an entire table it's a lot less efficient to traverse a B-Tree than to just sequentially stream the table, which is something Postgres is pretty good at.
Here's a sample explain output [1]. Mind you, that server was under heavy load (load avg 12) when I ran the query, which is why the numbers are higher than usual; with no competing CPU or I/O, it normally takes about 500ms.
That box has only 4GB of RAM, out of which it's using about 512MB for caching, and the OS is using about 1.5GB for the file page cache. As you can see from the plan, it's hitting 38,108 buffers, or 297MB of data, meaning its plowing through approximately 148MB/sec to compute the aggregation.
For comparison, RethinkDB chugs about 6GB of RAM before it manages to eke out some results from that query. I'm honestly not sure what it's doing.
Are you able to go into more detail about the performance of RethinkDB? Considering to use it for a new project but haven't been able to find anything solid about performance except vague and hand-waving "not very fast" anecdotes.
It's been a few weeks since I did a benchmark comparison, and I don't have a setup anymore that I can re-run to get real numbers.
RethinkDB is decent but not great at simple queries, like "select * where foo = 1". Unfortunately, and it's a rather big minus, Rethink doesn't have a planner, and every index has to be specified explicitly. This puts a burden on the application, which needs to be completely index-aware.
Where it really does break down is on aggregations. On a 800k dataset of semi-complex documents, the query "select x, count(*) from y group by x" (x here is a string with a cardinality of 89) took 4 seconds with Postgres, 84 seconds with Rethink on a test box.
In this scenario, Postgres was actually running in a slow Virtualbox VM, whereas Rethink was running natively; on our production servers, the same query takes about 500ms. In this scenario, Rethink used about 6GB out of the 8GB of memory allocated to it, whereas Postgres just streams the data through the FS cache -- so I think Rethink is just using a really bad query strategy.
Rethink's benefit, of course, is horizontal scaling, and it's supposed to be able to parallelize reads. But it has to work for the types of queries you give it. I strongly advise looking at your application's query needs, importing some test data, and seing how they perform. If you don't need aggregations or complex joins, it might work for you.
Thank you for coming back to this thread to share your experience, much appreciated!
I did not realize RethinkDB lacks a query planner/optimizer. That is a huge downside. The docs didn't seem to make much effort to point out this limitation.
We consider ourselves NewSQL http://schemafreedb.com/. We are looking into using Nuodb as one of our backend storage options when scalability is a concern, default is MySQL with TokuDB.
Or use posgres-xc, or mariadb 10 with galera and maxscale. Postgres has JSON storage. MariaDBB has dynamic and virtual columns, and the CONNECT engine which can now directly create new or edit existing JSON files using the SQL interface, instead of dedicated functions for JSON manipulation.
With the recent SQL-like query language, I think Cassandra comes pretty close to satisfying the requirements as well, as long as you don't require multi-key transactions.
It's not bad, and Apache Spark adds SQL on top of some other nosql DBs, but they are still hard to use.
Cassandra for example: you can't just put a secondary index on a table to enable sorting on it. There are secondary indexes, but they aren't useful for that (they don't perform well on high cardinality data).
Want a different sort? Make a new table. And duplicate the data, since there are no JOINs.
This is because the top priority for Cassandra is being scalable and always-on in the first place. New features are added only if they meet these goals. Therefore you have guarantee it will always scale and it has no single point of failure, not even a temporary one, regardless of which feature you use.
Some other new database engines do it in different order - first adding as many RDBMS features as possible and then making some of them kinda scalable (in some circumstances, if the phase of the moon is right, etc.). Sure, that might feel less cumbersome at the beginning on a single laptop (feels like good old RDBMS), but once you scale it out, it is far from being all roses.
BTW, duplicating (denormalizing) data is the way to go if you really need scalability. In general case, joins or traditional indexes with references from the index leaves to the original data do not scale on distributed data sets.
{kind=link}