First, Little's Law[1] can be mentioned as a formalized version of the "red arrow" in the blog post. It's true you cannot increase subsystem capacity (peak throughput) by adding queues.
However, queues can "fix" an overload in one sense by making an engineering tradeoff of increased latency and additional complexity (e.g. SPOF[2]). Peak capacity handling didn't increase but overall server utilization can be maximized because jobs waiting in a queue will eventually soak up resources running at less than 100% capacity.
If response time (or job completion time) remains a fixed engineering constraint, queues will not magically solve that.
NCQ works well when many writers are trying to get access to the hard drive. Of course this works well, unless you attempt to do more IOPS than your drive array supports for a continued amount of time. At that point applications that require fsync or write barriers will get terrible performance due to latency , and you should re-evaluate your storage. Which is the whole point of queues don't fix overload.
Yes, having a queue can help in optimizing the throughput, but only if it exists some economy of scale by combining some tasks (which is the case with NCQ). But the when the queued tasks are completely independent, then having a queue doesn't help in increasing throughput.
Queues can also allow you to break up load that can/should be distributed to multiple workers as well... it's a natural means of spreading out load.
For example, you may have a classifieds site, where users will upload/attach images to a listing. This doesn't occur at a consistent rate, and you may have 5,10,20 workers or more you can spin up if it gets under heavier load.
Queues let you separate the workload of processing images to different optimized sizes, while allowing the rest of the system to operate normally. This isn't a situation where it's to work around back-pressure but to normalize and distribute load.
Much like distributed databases help in a lot of ways. If you are mostly read, then read-only replicas are likely the simplest answer. If you're write heavy then sharding may be your best bet. Need to distribute processing load that can be async, queues/workers are a good approach.
It's a tool, like any other... It doesn't replace distribution, replication or sharding, it's meant to be used in combination with.
The article is talking about boring old queueing, like at the bank. The teller does not ask what kind of transaction you're looking for, even if they're optimized for check depositing. It's a straight up first come first serve scenario.
This type of queueing can smooth out demand spikes at the cost of latency. The author's point is naively adding a queue doesn't solve scaling problems. Although, as you point out, it may enable optimizations that are otherwise impossible.
NCQ actively interrogates the current list of work and optimizes delivery around what needs to be done. that's not the op's point.
Using ONLY a queue to "fix" a bottleneck can serve to buffer your input, but will still fail when your sustained input is greater than your sustained output.
--
I feel like this is pretty common-sense to most people, that the only way to fix a bottleneck is to widen the neck. If people are running into this situation in the real world, they either don't understand their core problem or are blocked from actually fixing or measuring it.
The problem stated by the author doesn't have really anything to do with queues. A queue is a tool that someone, quite sensibly, might use as part of a solution to widen a bottleneck, but obviously it can't be the entire solution.
The article is a great (literally visual) illustration of the issue, though, and is a great resource to explain it to other people; for example, managers who (fairly) ask 'we just bought new hardware what's the problem?' but don't understand systems architecture and the concept of multiple bottlenecks or the value of re-engineering existing systems.
It has a subtle physics flaw, which is that the sink, as it fills up, will cause flow through the bottleneck to be greater. Ignoring this, the metaphor is indeed pretty good.
It sounds like common sense, but a lot of people use the queue as a means to widen the neck, or rather the current perceived (and measured!) bottleneck they have. Usually there is another bottleneck hidden deeper in the system, and that one is the one that will cause all kinds of terrible issues.
Absolutely. That's what I meant in saying that if people are experiencing it, they don't understand or can't measure their real problem.
I think a more helpful slant for the original post would have been focusing on determining the root cause, as opposed to going into great detail on why queues were not a solution to the problem. (Especially when they might be part of a reasonable solution to the root cause.)
Yeah, the text that goes behind that post in chapter 3 of http://www.erlang-in-anger.com focuses a lot more on finding the underlying true bottleneck, but I didn't feel like re-writing the same thing in many places, differently.
So I headed for a queue rant, because at least that way I only have to link to the blog post when I end up discussing these issues in the context of queues.
As far as I know, queues are used for decoupling two systems so that you can scale individual components easier. In the example used in the article, adding more pipes out the wall.
A queue has a perk of smoothing out the peaks which may give the illusion of fixing overload, but really you haven't added any capacity, only latency. Also latency is sometimes a reasonable thing to add if it allows higher server utilisation rates.
I would say that it's not really an illusion of fixing overload. Real-world workloads are often spiky and setting things up so you can size your capacity for the average rather than a peak is a real fix, as long as the delays are acceptable.
Some monitoring is needed, if spinning up additional workers doesn't help (the bottleneck isn't CPU), then profile one of your workers, and find out what the bottleneck is, and fix it. Is one job spending lots of time waiting on a DB query? Add an index.
I suppose queues aren't really the problem so much as using a queue to decouple your systems so you don't have to think about the slow parts. If you decouple things, you still need monitoring.
Not sure if a queue actually helps with scaling components, at least it isn't the only way to scale components. If they are on separate servers you could just send a network call to it. It is the other components problem how to scale itself. It could be split into multiple servers with a load balancer in front of it. Still no queue but you can scale anyway. If it is on the same server the queue will probably not help at all.
If you use a service bus you might end up with a kind of queue that has to hold messages from all components to all other components, that is more or less all messages in the system. That might be a big bottleneck that will affect all parts of the system (but you will probably notice very early on).
Queues don't fix overload if demand is not related to completion of previous tasks. But sometimes it is!
Consider Internet congestion control. When a path is overloaded, a queue builds in the bottleneck router, eventually it fills, and packets are dropped. TCP congestion control reduces its congestion window, and the rate coming into the queue is reduced. So far so good - the queue didn't fix overload - dropping packets did. But TCP is reliable; it will just retransmit, so dropping packets didn't really shed load - it just moved the queue back to the sending host. No work was really shed from the overall system.
Now what really solves the overload is that the latency of job completion has increased significantly, and for much (though not all) Internet traffic, the job submission rate is clocked off the job completion rate. Think: you can't click on a link on a web page until you've downloaded that web page.
The only reason the Internet works when congestion happens is this: increased transfer latency decreases the connection setup rate. Thus, in a very real sense, the queue (partly in the router, partly in the sending host) did fix overload. But only because there's an external closed loop feedback system in operation.
"A function/method call to something ends up taking longer? It's slow. Not enough people think of it as back-pressure making its way through your system. In fact, slow distributed systems are often the canary in the overload coal mine"
Your case is simply back-pressure (albeit a somewhat interesting one where having a queue implicitly applies back pressure on a per user basis). And while it helps decrease load by tying up commands, it still indicates you have a bottleneck that is going to overflow at increased load; if users start refreshing the page because it's loading slowly, or if you have an influx of users, you can still overflow, and adding queues isn't going to fix that, just make it last a little longer before it falls over again. To fix it, you need to reduce the bottleneck, or find another mechanism to impose back pressure (one that is across the entire system).
We don't have fully async computers. Something somewhere will block, be it in the CPU, fetching blocks from a disk, kernel context switches, etc. You will hit fundamental limits. Heck, I've hit network card limits before and was none the wiser. There is actually a really good question you can ask yourself when designing a system: do you want it to go very fast at times, or do you want it to have very predictable speed? I learned to choose the latter: better fire up 16 processes and delegate work to them from a master process than to fire up one async loop that may get bogged down at some point.
At the same time, having a good mental model of what your code is waiting on or is blocked by is very important. Years ago I read advice on building multi-threaded systems. It went something like "when asked what's the hardest thing about coding up multi-threaded systems, beginners say things like deadlocks, but real pros say 'avoiding doing nothing'". So if your application does some large bit of work and in the middle of it it's blocked, why not go do something else.
Here's the hitch, and what the article alludes to: a system where you have 16 worker processes and they are either handling a client request or are waiting, your max users is 16. That's it, it's a hard limit. By design you can't process 17 requests at once. If you however go with an async system, let's say based on Node.js, you don't have this control. You have a crude "how many connections can we accept" thing, but you generally can't introduce limits you can actually reason about. If you simply set your max connections wide open, and then connect it all to MongoDB, you'll quickly find that MongoDB has a global write lock that will start rearing its ugly head. You can't overcome this limit, but you also don't know where this limit is. Systems with set internal limits that propagate back pressure to the edge, on the other hand, have very predictable behavior.
I think you are ignoring a few things about web development.
First, 16 workers don't equal 16 concurrent users if you have less then 16 cores in your server, if you don't then you still have a queue, it's just the queue the OS uses to handle context switches - which is even harder to reason about.
Second, the entire idea behind event-based processing (what node.js and Java based netty or vert.x) as opposed to thread-based is that the bottleneck is rarely the cpu.
Event-based processing is one of the ways to "avoid doing nothing".
Great article, a lot of these points really hit home with me, as we've been using queues to process a lot of our data in the last few years. I think if you consider your queue being fine while having items backed up under normal conditions, you're going to have serious problems to deal with as soon as you hit 1) more input 2) you get a nasty bug in your system 3) often a combination of both.
As an aside, I really enjoy working with AWS' SQS queues, as they allow you to define a maximum number of reads + a redrive policy. So you can throw, for example, items in a "dead messages" queue if they were processed unsuccessfully 2 times. We use this to replay data, stick it almost immediately in our unit tests, and improve software incrementally this way.
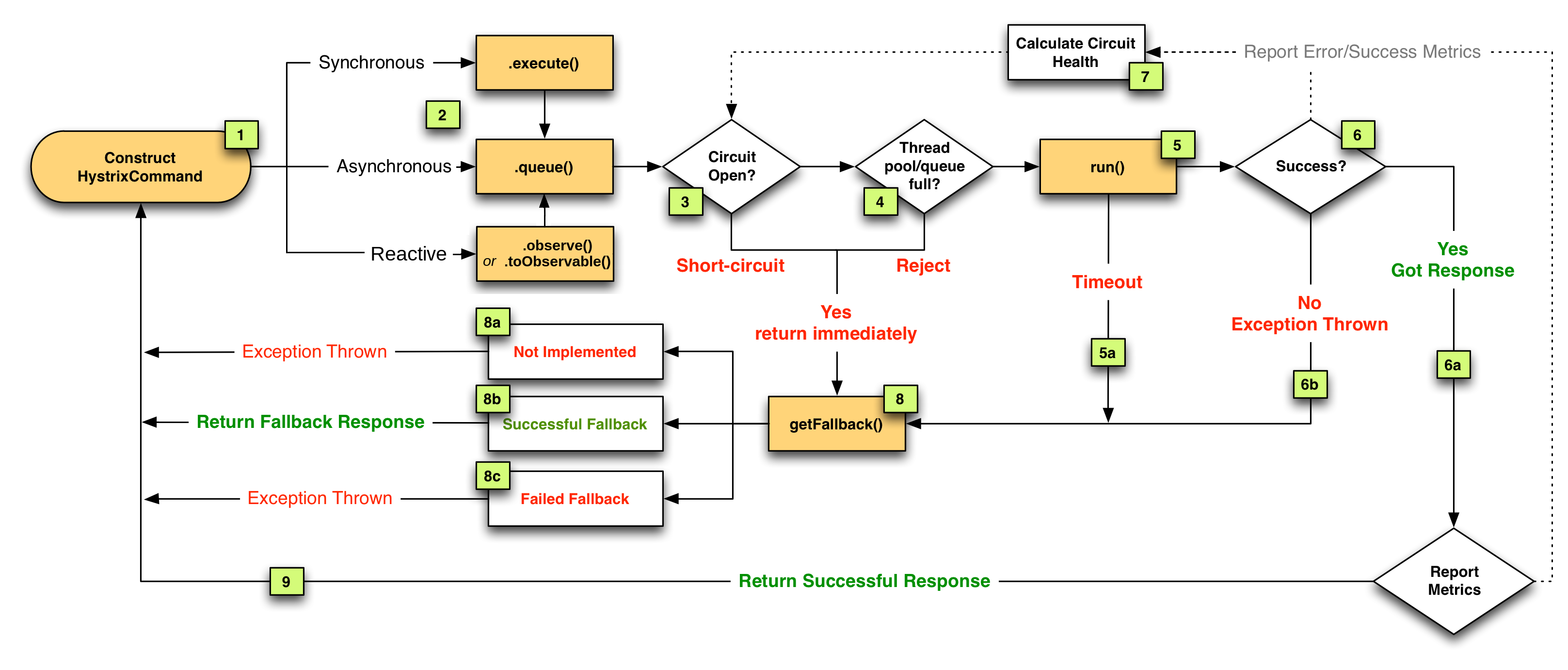
Anyone reading this may be interested in the related concept of the 'circuit breaker' technique employed by things such as Hystrix (Netflix), to avoid getting into this state.
Not a solution per se, but the simple philosophy is to set yourself up to fail fast: when back pressure reaches some threshold the 'circuit opens' and your servers immediately respond to new requests with an error, instead of ingesting huge numbers of requests which flood your internal queues or overload your infrastructure.
Queues help you scale horizontally. Basically, you can put a lot of kitchen sinks on the right side of the diagrams. Of course, this is done with careful design of the application and not just adding a queue alone.
OT: The hardest part I have found with queue design is task cancellation. How does one 'cancel' tasks that are already in the queue or being processed? I haven't come across a good framework that solves this cleanly. For example, if I queue up a task X in the queue. The task now need to be 'cancelled'. How can I ensure this? Looks like I need some sort of messaging bus?
> The hardest part I have found with queue design is task cancellation. How does one 'cancel' tasks that are already in the queue or being processed?
That really depends on the queue implementation. If your queue is a DB table and you have identifiers for the items added to the queue that are mapped to a column in the DB, cancelling a queued item is just updating the appropriate column to flag the item as cancelled or deleting it outright (cancelling an in process item is usually more problematic, because its no longer on the queue, its with a worker. More robust engines that include more than just queue functionality may handle this -- but in general it requires that workers hand something back to the engine which then applies any permanent state changes, so that if the engine gets a cancellation it can just not make those changes; it could work if all changes also had a corresponding compensation mechanism so that if a work item was cancelled after some work was committed related to it, the appropriate compensation could be done.)
Take a look at Gearman. You get distributed background or foreground tasks with identifiers and optional queue persistence. Workers can also optionally report back their progress when working on a job. You can add and remove workers trivially at any time.
This is such an awesome article that puts into words that I've been contemplating for a while now. I've been trying to explain this exact scenario to various management folks but they just don't get it and always scream why can't you "queue" them up!
Even I was under the impression that queues are meant to solve the problem of overload; but over time I slowly realized that that's not at all what queues are meant for!
Queues are meant to solve following (not exhaustive list) problems.
1. Tight coupling. An example is decoupling "payments" from "order processing". Here, two independently running processes need to message each other and Queue is one way of messaging.
2. Surge handling.
What typically happens is that #2 gets conflated with "increasing the overall throughput of the system". And it does work for a while since in the initial days the real bottleneck won't be reached. And when it does reach; due to marketing campaign and what not; then you have situation described in the article.
tl;dr In a system, if requests arrive at a rate that is greater than its throughput then no queue can save you.
The fascinating thing about scaling systems is that you will end up discovering a new bottleneck every time; e.g., A bottleneck moving from NIC to a switch and to a router and so on!
To fix overload swap queues for stacks, set a timeout, and clear the stack when you estimate based on throughput the the time will expire.
eg.
On a webserver where people get refresh happy, I'd set the timeout at about 5 seconds. If requests are taking on average 2 seconds and the request is already 3 seconds old, return a 500, drop the connection, etc. Then clear the rest of the stack.
Answer requests in a LIFO manner as at least that way in an overload condition some requests are answered and the 'queue' is cleared quickly.
It's like when you have 3 papers due and only time to do 2, you elect to not do one so you can do the other two. You should ideally kill the one that is due first.
Queue size is not important. The time a request resides in the queue is. If you have short burst, the queue will fill quickly and drain quickly, and a request will only stay a short time in it. If your system is overloaded, the requests' 'sojourn time' will increase and stay high. Google for papers about codel/controlled delay.
In any case, backpressure and discarding requests (just another form of backpressure) only move the queue upstream towards the sender. One strategy to deal with this is only to backpressure requests of a subset of users. Only they will experience high delay.
That's an overly complicated way of saying "use bounded queues". Your system can get into a really bad state if you don't use bounded queues, and take a long time to recover. Unfortunately, limiting your queue size is not a quick hack. The reason you use it mostly that it forces you to develop feedback mechanisms, flow control, retry logic, and fairness across your whole system.
Continuing the sentence from the title, "but they allow you to deal with it better".
The question is what is the business requirement and guarantee regarding the message delivery. In my experience with logging systems is that losing a very small percentage of your data in case there is an outage in the storage layer is tolerable.
That allows us writing code that sends or receives messages using a channel (Go, Clojure) and have sane timeouts to gracefully deal with overload, saving 200 (or so) messages in a local buffer and going back to reading the queue after a read timeout.
With this concurrency model queues are very powerful tool of separating concerns in your code. Having thread safe parts that can be executed as a thread or as a gorutine lets you use 1:1 mapping to OS threads or N:M.
Back to the original point, queues don't fix overload, but I still prefer deal with overload using queues over other solutions (locking or whatever).
RMQ deals with this fairly decently now via flow control (as of 2.8.0, I think). Basically, if it determines that the queue isn't keeping up with publishers, it'll throttle publishers (by blocking on publishes) to slow down publication to a manageable speed. It also uses this mechanism to block publishers if free memory/free disk space fall below preconfigured thresholds. When a publisher is blocked, RMQ notifies it that is has been flow controlled, so the publisher can optionally take some action to help mitigate whatever circumstances caused the flow control.
It's not perfect, but it's actually pretty good at mitigating the problem of RMQ causing an RMQ-oriented system to eat itself.
FTR: We use (Resque/Jesque) redis-backed queues extensively in our applications/APIs for interprocess communication, off-loading messages that don't have to be processed immediately, and for sharing load between servers.
This article could have been "X Don't Fix Overload". If you're not looking for, and fixing, the actual bottleneck, then any improperly implemented solution could be in that title.
With that being said, there is good information in there. I just didn't agree with the strong bias against queues.
Author here. I use queues all the time. I program in Erlang and there is one unbounded queue in every single process' mailbox in every node.
The problem is not queues themselves, it's when queues are used to 'optimize' an application (usually the front-end) by removing the synchronous aspect of things. In some cases it's reasonable, say long running tasks like video processing or whatever could be handled in many other ways than blocking up the front-end, for friendlier results.
I've seen queues applied in plenty of times where their use case will be to handle temporary overload (by raising latency and pushing some work to be done later, when the system slows down). The problem is that as time goes and that temporary overload becomes more and more permanent (or has such a magnitude as you can't catch up on it in your slow hours), it suddenly starts exploding very violently.
How much time the queue buys you is unknown, because the people running in these issues have likely not been able to characterize the load on their system, or the peak load they'd have (because the system dies before then). It's a challenging problem. Ideally you fix it by putting boundaries on your system (even on your queue! that's good!) and expect to lose data eventually or block it.
The really really dangerous thing is using a queue and never expecting you will lose data. That's when things get to be very wrong because these assumptions lead to bad system design (end-to-end principle and idempotence are often ignored).
And then people go on to blame queues as the problem, when the real issue was that they used a queue to solve overload without applying proper resource management to them.
Most of what I rant about in that blog post is stuff I've seen happen and even participated in. I don't want that anymore.
I understand where you are coming from and I'd even recommend your article to people considering using queuing. I apologize if made it sound like I didn't like or understand the article. It just felt a bit heavy on dissuading people from considering using queuing, however, reading through it again I can see that the intent is to describe why queues should not be used in a very particular context.
It would be nice to see a similar write-up on appropriate use of queuing, with more plumbing visuals.
> How much time the queue buys you is unknown, because the people running in these issues have likely not been able to characterize the load on their system, or the peak load they'd have (because the system dies before then). It's a challenging problem.
Is this a case for using queueing theory to model your system's behaviour?
Even if you don't go down that path (and there are tools for it[0]), using queues to connect components helps find bottlenecks in one very simple way: you can look for where the queues are growing. As a rule of thumb, the longest queue is going to be in front of the bottleneck.
The longest queue is going to be in front of the tightest bottleneck, but not the central bottleneck critical to your application.
If you find you have a bottleneck halfway through the pipe and you make that bottleneck go away, your true real bottleneck down in the wall still remains there, and all your optimizations done above that one will end up just opening the floodgates wider.
Once you've protected that kind of more at-risk core, then it's easier and safer to measure everything that sits above it in the stack, and it puts an upper bound on how much you need to optimize (you stop when you hit your rate limits on the core component).
It seems like you're really talking more about the danger of unbounded queues (and the virtue of bounded queues). A synchronous process is effectively just a bounded queue with a maximum capacity of 1.
I sometimes use this - that was built as a call-center simulation - to get quick-and-dirty figures to have an idea of the actual queueing strategy tradeoffs. Queueus are okay, depends on what you want to do with them.
http://queuewiz.queuemetrics.com/
Yes, if things further down your stack are not capable of handling the load in decent time your queue is going to overflow (assuming a fixed capacity). No, it does not make your entire stack faster -- it just defers processing in a way you can manage and tame it. What can become faster is things like front-end requests, which are no longer held up by blocking operations or a starved CPU. Either way, it buys you some time to actually re-engineer your stack to work faster and at greater scale.
2. The author isn't arguing anything opposed to what you're saying; yes, it can speed up front-end requests by deferring work, but if you build an image uploading system that can't handle 10,000 image post-processing tasks per minute, then deferring image post-processing into a queue won't solve your bottleneck.
The author isn't talking about individual components of a system, he's talking about the entire system as a whole. Even when you're using it to speed up your front-end, you still need the capacity to do the post-processing on the backend.
Nothing he says is wrong, but I'm not sure why people would be using queues on web requests. Do people really do this? I guess I can see it happening, but... it just doesn't feel right.
I use queues to, well, queue up work. Work that doesn't have to be done anywhere close to realtime. Things like background data processing, or in another case where I have up to 10 seconds to process a piece of data that comes in. Something like activemq lets me distribute the work easily, easily monitor the queues to see if any step needs more processing power, and is great for passing around the work.
In Appengine web requests often kick of tasks in queues todo the heavy lifting. This makes the response of web requests very fast. However you dont need queues when you need synchronous results, or whenever the task is small.
Can the problem be solved by using a fair queueing?
chunk off the overloaded queue into small groups and then have your workers chew a bit of each at a time. the LAST-IN folks won't have to wait ages for FIRST-IN folks to finish.
off topic but parisian french sounds way nicer than quebecois, the language of blue collar workers from 18th century, had to unlearn the horrible quebecois after high school.
Thank you for illustrating the reason for this blog post so perfectly.
The problem is not that the queue(s) aren't being accessed by workers fairly, but that requests are being dumped onto the queue(s) faster than the workers (or whatever your bottleneck is) can handle.
To stretch the metaphor, too often software devs respond with "Let's add more sinks (queues)!", rather than "let's add more drains, and make sure the ones we have are clean (identify the source of the bottlenecks and work to remove them/scale them)!". The first is comparatively easy, and seems to 'fix' the problem for a little bit; the latter requires measurement and careful architectural decisions, and possibly breaking changes.
It's not about queueing algorithm, it's about putting things into the queue faster than you're taking them out. Regardless of your algorithm's fairness, you're still going to have a queue that backs up until it overflows.
{kind=link}
However, queues can "fix" an overload in one sense by making an engineering tradeoff of increased latency and additional complexity (e.g. SPOF[2]). Peak capacity handling didn't increase but overall server utilization can be maximized because jobs waiting in a queue will eventually soak up resources running at less than 100% capacity.
If response time (or job completion time) remains a fixed engineering constraint, queues will not magically solve that.
[1]http://en.wikipedia.org/wiki/Little%27s_law
[2]http://en.wikipedia.org/wiki/Single_point_of_failure