I think in a strange way, this tool is actually not a terrible idea. Git is not a configuration management tool, no matter how hard people try to shoe-horn it into that role. A simpler Git designed for configuration management is indeed a good idea.
Unfortunately, I think the implementation leaves a lot to be desired. For one, not including the committer is an important flaw. If you're only managing your own system's configuration, it makes sense, but surely ESR realizes that UNIX-based OSes are multiuser systems, often administrated by teams of people. Being able to track whodunnit is definitely an important part of the equation. (It'd be incredibly clever if it signed the log with the user's public key too, but that might be asking a lot.)
Needing something like SRC to track changes to a simple README or HOWTO? My local bin dir? Ehh not so much. Especially if it's a software project? No, that definitely should live in the VCS with the code, so that those who touch the code will also touch the documentation. It says a lot about src that it doesn't even live in a src repository.
It's actually a good idea. People often don't bother version-controlling simple stuff because it's a hassle.
Here's the thing that's funny to me: git is easy. Everyone (especially mercurial users) goes on about how horrible the UI is, but when I think of git, I think of how similar it is to RCS: easy, quick, and simple. With both, I can diff things and check in changes very quickly. I have a bunch of single files in RCS which I'm moving over to git because it's a no brainer: all the speed and ease of use with a ton of advantages (such as dead simple replication) if I ever need them.
I love git. I'm a git power user. I've used git as the datastore for a CRM I built.
But I respectfully disagree. Git is not "easy." You've been conditioned. You and I know that it's very very hard to lose work or lose commits with Git. I'd say it's nearly impossible to do on accident. But in my first month with Git I rewrote several things because I messed up somehow and couldn't figure it out. I would hose my checkout and resort to doing a new clone. I've since helped run a big transition from SVN to Git and saw the same struggles there.
Git is power tools for my code. I could never go back to SVN. But it's not easy.
I agree. Git is powerful, flexible, and (once you grok it) quite simple to understand ... but it baffles new users, and is a complete turn off for people who happen not to be software engineers, even those who are otherwise highly intelligent.
I work trying to bridge the gap between a team of mathematicians and algorithms engineers, and a team of embedded software engineers. Most of the embedded software engineers "grok" git (after some practice), and are (fairly) happy using it on a day to day basis.
The Mathematicians and Algorithms engineers, on the other hand, aren't really interested in getting to grips with Git (or any version control system for that matter). They'd rather spend their time thinking about mathematics and statistics. (Quite rightly).
The decision to use git, whilst justifiable for many valid technical reasons, has definitely thrown up some additional challenges for me and for our organization.
It's easy to mess up a somewhat complex repo in git, but for versioning really simple things like rsync scripts or dot-files, where you have one committer, one branch, and a linear commit log, git's pretty easy. git init, git commit -am, gitk to view history or diff, done.
Not that hard to use git as a replacement for RCS. A few extra commands (not going to quibble over the fact that RCS requires checkout before edit), but that's about it. The one thing I can see going for RCS is its granularity (in only tracking single files), but that can be as much a burden as managing whole git repos, ie it depends on the use case.
Version control is one of those annoying admin tasks that you have to do and what to think about as little as possible. Git makes you think about it a lot.
Version control is one of those annoying admin tasks that you have to do and what to think about as little as possible.
I disagree. Version control as a concept is inherently embedded in every software change you make as part of a team. Every time you coordinate a change with other people, you are participating in a version control task. Your VCS can either capture the inherent complexity involved or it can sit there and force you to hash out the complexities on your own before you invoke it. Either way, you will be occupied by the task of controlling versions of your code.
Git is typical of a tool built by engineers. It has good primitives but a clunky overall design and horrible UI. It does not naturally encourage the most effective modes of use. Hell, even the "best practices" of the git community are highly questionable (just rewrite history for aesthetic reasons, what could go wrong?).
Git is highly tuned to the use case of serving linux kernel development. Many other folks have figured out decent ways to use it effectively as well but don't mistake that for Git being an unquestionably good tool or for it being "easy". Sure, the core workflow is pretty straightforward, but the fact that the easy stuff is easy is not a ringing endorsement of a tool. Good tools make hard stuff easier and easy stuff trivial.
Make no mistake, I think there are lots of awesome parts of git, the most important being its distributed nature. It's trivial to setup a repository because everything is a repository. That's pretty potent, and git has some reasonably well engineered components inside of it which make it fast for many common use cases, which is fantastic. But a big part of why git has been so successful lately has been because it hasn't had a lot of competition. Much of the competition is either hugely expensive (perforce, TFS), doesn't match the use case (same), hugely outdated (SVN), or terrible (TFS). The main competition for git is Mercurial, and a big reason git won out over Hg is because of mindshare traction and network effect from linux kernel development and then github.
The biggest problem now is that so many git fans are afraid of criticizing git's shortcomings.
just rewrite history for aesthetic reasons, what could go wrong?
I have never understood the problem that some people have with the idea of rewriting history. It's as if the very idea of it offends them. Do file system writes also put you off? Is it important that I see the history of every single keystroke you made while twiddling with your config file? When you fixed a typo you made in a comment before publishing your change, how is this not a "rewrite of history for aesthetic reasons"? Do you really need to know about all the tens of little WIP commits I made because I just wanted to back up my changes before going to the bathroom? Am I not allowed to clean up a little bit before I publish all my own changes to the world?
Now if you're just talking about rewriting published history, then nobody is going to disagree with you.
What people are really saying when they say you shouldn't write history is that your SCM shouldn't support work in progress checkins. Not supporting that just makes your SCM inflexible.
I see the ability to change local history as a huge benefit. Not only can I track changes but before I publish them I can make decisions about how to make them more presentable/understandable to other developers.
Exactly this. I get all the benefits of a DVCS, pushing and pulling from my private fork, distributing development between my home and office machines, never losing changes; and then when I'm ready to publish, I can go back and rationalize my commits (many of which are "git commit -am 'oh sbt'" sorts of things) into a useful history and issue a PR for the rest of the team to code review.
It's taken me a while to come around, but you'd have to pry rebase out of my cold dead hands now.
Sadly, Git users frequently do rewrite published history, by merging branches via "git rebase" followed by a fast-forward merge (i.e. replaying the branch on top of the target), all to maintain that wonderful linear "history". And that's a bad thing because it destroys information about the context in which a change was made. (I've been baffled a few times by apparently bad commits, before realizing they were rebased and did make sense originally.)
If they're rewriting published history, it's even worse than that, because it could change history that you are currently developing on top of, requiring some more advanced git knowledge to get your local repository into a correct state.
I have not found it to happen often though, for two reasons. First, it is widely agreed upon among almost all mildly experienced to highly experienced Git users that rewriting published history is a bad thing. Second, if it becomes a problem with new Git users doing this, you can turn of non-ff updates in the public repository, thereby disallowing this to ever happen, unless you go through all the steps to delete and recreate a branch.
If you're working with your local unpublished history, then it is your responsibility to make sure they still make sense in the context of newer updates from the public repo regardless of whether you rebase or merge. I can see how it would be confusing if people failed at this. I tend to find that more confusion results from people inflating the history with loads of one-commit merge bubbles everywhere rather than just rebasing their small changes.
"git checkout -- <file>" does not actually revert a file from the branch. It reverts it from the index. It's only a revert-to-branch operation if you don't have anything in the index. So if you land into one of those "gituations" where use of the index is being foisted upon you, it might not do what you are used to.
There is also the flaw that the -- separator is not required for giving paths: "git checkout <file>" also works. So if you are trying to check out a branch or tag, and make a typo and accidentally type the name of a file which has unstaged changes, you lose them. It doesn't rename the original file to a backup like good old "cvs up -C file".
Git is so easy a good search for "git tutorial" returns 2.7 million results. I've lost track of how man HN Front Page posts there have been trying to explain just how easy git is. The sheer volume of posts desperately trying to show how easy git is should be enough evidence to prove that it is infact not easy, simple, or intuitive.
I use it all the time, but there are situations and environments where it's overkill. Same with Mercurial. For starters it requires installation and that they is effectively a deterrent for many people especially non-devs.
Nothing stopping shops from writing a simple wrapper to add commiter ID and signature in a machine-readable standard way to the commit messages. Sure that could be easily gotten around. So can git's.
It is a great idea. Git is just too much of an hassle when you only have one file of TODOs, a tiny hack or what not. Why bother with checksums when an incremental integer helps me memorize what revision I'm on?
However as others has pointed out, maybe the dependency on rcs was not the best choice.
He claims he did not use Mercurial because (a) it stores the history in binary blobs, (b) it does not have sequential revision numbers, and (c) its CLI syntax is ugly, see [1]. Unfortunately he is wrong about (b) and (c). Mercurial assigns automatic sequential revision numbers (perfect for a single non-distributed repo) and its CLI syntax is so neat that this is the reason I do use it a lot to track changes to single files...
Sounds like ESR should have spent a little more time studying Mercurial.
I cannot understand his need for (a). Does he want the possibility to quickly and easily see, or edit the history? If it's only seeing it all, in one command, then a simple "hg log -e" does it.
Edit: @leoc I based my comment on "Other projects to mold Mercurial and Git [...] will fail criteria #3 and #5, and often #4 as well" with #4 referring to a "modern CLI syntax". But yeah it could be implied that this criticism does not (always) apply to Mercurial.
I'm nit particularly fond of git, I much prefer mercurial - but they are of course pretty much equivalent. Either way I have a hard time seeing which usecases aren't covered by the duo of RCS and mercurial (actually I'm very hard pressed to see why one would ever use RCS over mercurial, but no question RCS is simpler). At least something like fossil have some actually unique features....
I am not entirely sure I understand why one wouldn't use git for this role. If you don't need a remote git repository, you don't need to use one, and git will be available everywhere. Certainly many production machines will tend to have it for deployment of applications across multiple machines.
What are some use cases that don't work with git (which is probably already available on the system)? And why wouldn't git be an effective tool for that particular role?
I'm certainly not as experienced as ESR (though, I'm coming up on 20 years of administering Linux and UNIX servers), and perhaps I'm missing some subtle nuance here. I'm not wanting to come off as "screw this, this is stupid". I'm just genuinely not understanding why I should learn a new tool (or re-learn an old tool that's be "reloaded") when git does all of this and more...and I already know it and have it installed broadly across my systems.
> Because, for one thing, "one" sometimes doesn't have the computer science degree and years of experience to even begin to understand Git, for one thing.
With respect, I call shenanigans on this my good friend.
I dropped out of highschool and attended no postsecondary and I don't have any problems with Git. I started with the basics and read more as I got myself into tighter and tighter jams.
I feel like this myth is perpetuated by a small group of people who are very vocal about "git is hard". If git commit and git checkout are too complicated, I don't know what else to say except that every VCS has those concepts, perhaps you're just used to those systems instead.
> I dropped out of highschool and attended no postsecondary and I don't have any problems with Git. I started with the basics and read more as I got myself into tighter and tighter jams.
I think you may be underestimating the wideness of audience that this may appeal to. I was thinking of introducing my rather older Dad who knows nothing about CS/programming to version control and plaintext. He is an accountant, and currently uses the "File_Copy_1.docx" method of version control, even for simple documents that could just be handled by plaintext.
I would prefer that he avoid the confusion of git, where `git checkout [X]` can refer to [X] being a branch, commit, or file.. This new basic RCS may be good in that regard. I guess another option might be Legit (http://git-legit.org).
> I dropped out of highschool and attended no postsecondary and I don't have any problems with Git.
Git problems arise when people want to do moderately sophisticated things, beyond just committing changes and viewing logs and diffs.
> If git commit and git checkout are too complicated,
If "If git commit and git checkout are too complicated" is your argument, then you aren't doing anything more sophisticated with git than what you learned from a svn to git migration tutorial in five minutes.
People do more with version control than "commit and forget".
If that's all you need, then what you really want is backup software that takes regular snapshots of your filesystem.
I think you may have misunderstood my comment, of course there is more to it then checkout and commit.
Those are the basics, that's where you start. Then you get stuck somehow, and you read more. That's what I did at least.
IMO It's about not giving yourself the impression that the learning curve is insurmountable, you can do it. Starting with the basics and growing up is, I thought, common knowledge for acquiring a new skill.
I find when I get confused and flustered with git, every single time it's because I don't understand [yet] how I got into the current state. I've found that if I take a breath, put the problem aside and focus on figuring out how I got into that broken state, then the solution reveals itself -- not once have I ever lost code as a result of git confusion.
I perfectly understand that there are hordes of programmers for whom messing around with git is far more interesting than the actual code they are working on.
"Man, I just interactively rebased my last six changes so the commits are in a different order, and two of them were squashed into one! Boy, does that feel productive."
> It's about not giving yourself the impression that the learning curve is insurmountable, you can do it
Perhaps I can, but with mercurial around I dont see why I need to. I think no one in their right mind claims git cannot be grokked. They question whether that effort is well spent given there are equally effective alternatives that people find simpler to use.
Other than github I fail to see a compelling reason going for git apart for the linux kernel development workflow of course. Its not a bad tool but not quite the "you possibly cannot and should not do without it" that it is made out to be.
That comment goes out of its way to make things seem complicated. The different synonyms for things are confusing, and are evidence of the fact that Git has evolved over time rather than springing forth fully formed.
That said, the staging area is one of the most useful features of Git, and if you don't want to use it, you can largely ignore it. The staging area allows me to make a few simple changes in the order that they occur to me, but add and commit them (using git add -p) in the order that makes the most sense for code review.
Also: I highly recommend setting up shell aliases for the most commonly used commands, whether you use Git or anything else. "gco" is much faster to type than "git checkout", etc.
> The staging area allows me to make a few simple changes in the order that they occur to me, but add and commit them (using git add -p) in the order that makes the most sense for code review.
Ah, but note that "git commit" also takes a "--patch" argument. So the add-and-commit case you are describing can in fact be done in one step. That step uses the index, but only for its implementation; you're not aware of it. "git commit --patch ..." appears to move selected changes from the working copy straight to a new commit on HEAD. The command could be implemented in a version of git that doesn't have an index.
Those little commits you make in preparation for review are your true staging area.
git commit and git checkout are fine. git pull and git push are where the problems start.
as I got myself into tighter and tighter jams
I suppose this is the thing; if you're happy to learn that way, fine. It's just that git is particularly prone to "I've trashed local state and lost work" / "I've just pushed a huge mess and will have to lose time cleaning it up, if that's even possible".
I love git, but even git checkout is asinine. It's fine for checking out a tag/branch/rev/treeish, but why on earth does it also revert files to their checked in state if given a path argument?
I don't think git should be prone to trashing local state due to how it usually yells at you when it's about to do that, but then I've been working with a student this quarter who seems to do that every time I push something to github and she needs to pull. I think if the git community got together, did a usability study on how people actually use git, and renamed/split out commands into names that made sense, it would be a huge boon for general usability.
> why on earth does it also revert files to their checked in state if given a path argument
Simplification! :) "git checkout file" reverts a file from the index. If it doesn't exist in the index, then from HEAD.
The problem is that you can make a typo, because branches, tags and files are all in the same namespace. Suppose you wanted to type "git checkout foob" which is a tag or branch, but instead you make a mistake and type "git checkout foom" which is the name of a file that happens to have unstaged changes. Oops!
If "file" has unstaged changes, then "git checkout file" should rename it out of the way first to "file.#1#" or whatever. (Hello, look at CVS!)
Learning by mistake is one of the quickest ways to learn something though. Personally, to mitigate the possibility of losing my hard work to this problem, I started using git for personal projects and didn't use it for my important work until I was comfortable with it (eg had run into several problems, but resolved all of them).
This also helped me understand Git well enough to teach it to my colleagues (and in teaching others, you learn even more yourself), and now that everyone on my team is comfortable with it we've switched to it almost exclusively.
I think git hard a small but steep learning curve. Lots of developers aren't used to using the command line anymore so git can seem 'scary'. Personally I gave up on git a couple of times before finally learning it but as a developer working by myself I also couldn't understand the need for version control (at the time) so giving up wasn't a big deal. I think once you give it a couple of hours of your time you can understand enough to use it in most situations. Plus the GUI tools (SourceTree for example) are quite good.
Nah, it's not _that_ bad. Only way one may realize Git is hard is to compare it with other DVCSes, so avoiding that makes him confident enough to spread wishful speculations of it's something is wrong with people, not Git.
I would say, git isn't harder than any other distributed vcs. However, its tooling leaves a lot to be desired: its terminology is non-obvious and requires sifting through dense man pages (or dense reference books), it's hugely inconsistent (e.g. git remote rename vs git branch -m), and rebasing and merging can create confusing messes for users to sift through.
DVCS is hard. Git is hard. They're hard for very different reasons.
With a centralised VCS, you have two 'version's of the file system: your local working copy, and the current branch in central repository. That leaves limited room for inconsistencies between the versions that might confuse the user / need conflict resolution.
Logical versions = Number of working copies + Number of branches
With a distributed VCS, you necessarily add a third 'version' (current branch in local repository). That's unavoidable.
Logical versions = Number of working copies + Number of local branches (over all working copies) + Number of branches in central repository.
But git is considerable worse: with git checkout working with a central repository, there's at least 5 versions involved, all of which may differ: working copy, index, local branch in local repo, remote branch in local repo, branch in remote repo.
Different commands affect different 'versions', so it's easy for new users to get them into an inconsistent state, and pretty much impossible for them to recover: usually they can't identify the reason for their trouble because they do not distinguish between these 5 'versions' mentally.
It's impossible to build good tooling on top of this mess, unless your tooling completely hides these extra 'versions' from the user by always keeping them consistent with some other 'version'.
For example, a commit tool might use the stash only during the commit itself, so stash and local working copy are always kept consistent. Unless the user also uses the git command-line client...
Of course, git is also hard due to the inconsistencies in the command line interface, but that's in addition to this fundamental unnecessarily complexity.
git init # make a local repo
git add foo.txt # add the file
[edit]
git add -u # add changes to commit
git commit -m"made a change" # check in changes
git log # see commits
git status # what has changed
What you need to know is that "git add" has little to do with "foo add" where "foo" is just about any other version control system. Look, you ran "git add" on files that were already added, what?
There is this hidden thing called the index that confuses the heck out of everyone. Oh, but it's not always called the index, either: that would be unnecessarily easy. Sometimes it is called "the cache". How to show the difference between the index and HEAD? Why, of course not "git diff --index" but "git diff --cached".
(In what way the index acts as a cache is beyond me; a cache is a fast place where you look for something that is also available in some slower place, but things in the index are sometimes only in the index and nowhere else!)
Furthermore, things in the index are not "indexed" or "cached". Why, they are "staged". So why don't they call it the stage? (And only that: no synonyms?)
(The index behaves like a cache in the following sense: it has transparent "read through". If you do a "git diff", you see the difference between the index and your working copy for any changed file. But if the index doesn't have that file, then it gets out of the way and you see the diff between HEAD and the working copy. This confuses people because the transparent behavior teaches them, most of the tiem, that "git diff" is like "svn diff" when it isn't.)
The overloaded meanings of "git reset" are astonishing also. Sometimes it means "make the working tree like what is in HEAD". Sometimes it means "no, don't touch the working tree, but change HEAD to a particular revision". Sometimes it means "don't touch HEAD or the working tree: make the index look like a particular revision".
Want interactivity? Sometimes it's --interactive, and sometimes it's --patch. Please, just let me do "git stash --interactive"; don't make me correct that to "--patch".
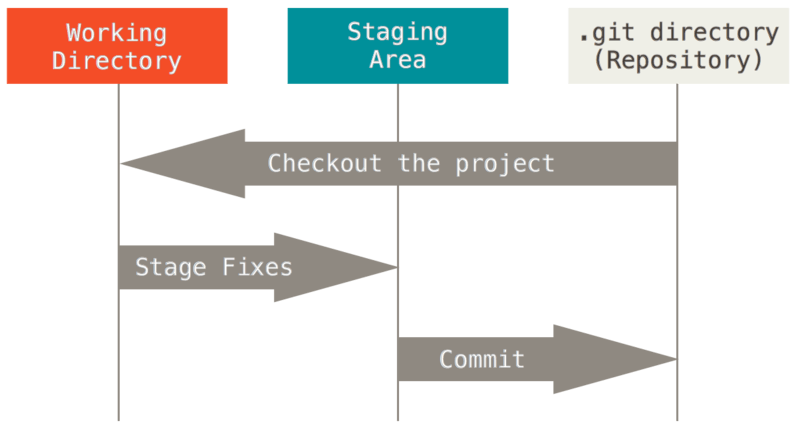
You do have some very valid points, and git can be confusing. I wonder if those points are more confusing for someone coming to git from some other VCS than someone using git as their first VCS. My 13 year old son got the idea of Git after seeing a diagram like this:
You beat me to it. RCS can't scale up like Git, but Git scales down very nicely. Instead of learning two VCSes, you can reuse the same one you probably already use for everything else.
Sure, Git isn't the last word in VCS. There's lots of room for innovation in the space. Still, I don't see anything in the docs (at http://www.catb.org/~esr/src/src.html) that Git can't do just as well. It seems to be a solution in need of a problem.
That's what I do on my "bin" directories (for scripts and such).
On the other hand, maybe being able to grab something analogous to a ",v" file and moving the archive for a single file around by itself has some value. Just not enough value for me to bother installing RCS when git is already present :-)
Sure, I sometimes try things that don't work, and I can just revert my changes. I'm just used to having everything in source control, so I even like it for one-off stuff that doesn't fit in an existing repo.
This is a wasteful step; you can commit all your changes with "git commit -a" which adds the modified files to the index, and commits, in one step.
The index is a completely pointless idea in git that has no purpose; the next major version of git should factor it out. Git would really improve if it lost the index thing.
You're already using distributed version control where you can have a whole swath of commits which are not published to your upstream. That is all the staging area you need; you don't need a staging area before your staging area. There are just too many levels: working copy to index. Index to commit. Commit to upstream repo.
Git tries to hide the index from users, but that backfires when awareness of its semantics crops up in corner cases. For instance, quite stupidly, if you try to revert a file from a prior commit with "git reset <sha> <file>", it does it in the index rather than where you expect, namely the working copy (that being left untouched). This is a purposeless complication. Now you have a "git diff" which looks like the change is being added rather than subtracted (because that's actually the delta from the index to the unmodified working copy), and a "git diff --cached" which is exactly its opposite (because it's a delta from HEAD to the index).
There has to be a concept of modified state which extends to "this new file is scheduled for addition" or "this file is scheduled for deletion". That's all the "index" you need. Other than that, there should only be the working tree, and whatever is in HEAD.
Git has the tools that let you make multiple commits and squash them together into one, so the index is completely redundant from that point of view. Instead of
hack file
git add file
hack file
git add file # squash into previous index entry
you can easily do
hack file
git commit file # pretend the index doesn't even exist
hack file
git commit file
and then do an interactive rebase where you squash those commits together.
This is actually cleaner because you're not doing "squash as you go" into the staging area, but making actual commits where the changes are tracked and separated. Maybe you will end up not wanting to squash them into a single change!
I.e. since commits can be amended, cherry picked and squashed to your heart's content, there is no need for the software to support workflow involving a staging area where you prepare the perfect commit. It is superfluous.
The index smells like a left over from some early prototyped version of the software, before the full concept was hammered out, which was then difficult to remove (or it never occurred to anyone).
Ugh, this is terrible, the index is git's best feature. I kind of see where you're coming from with the idea of squashing together commits before pushing but it seems like a lot of awkwardness and overhead for the really basic use case of committing a bunch of files without doing it all in one command. Maybe it's just my OCD tendencies but I actually do spend time crafting the perfect commit, picking only the hunks/lines that matter and all that.
I think if people are taught git focusing on the index/staging area, it makes a lot more sense and you have much fewer problems.
You can pick out the hunks and lines that matter using "git commit --patch". This does the "git add --patch" and "git commit" in one step, so you never see any index.
Face it, the git index is an exaust manifold bolted on to a bicycle. This can be proven. Any argument you make for how the git index is useful is easily knocked down with a counterargument which shows how it it is redundant, because existing mechanisms uniformly handle that case.
Moreover, the index can be shown to complicate git. For instance when viewing differences with "git diff" you have: index to working ("git diff"), HEAD to index ("git diff --cached") or HEAD to working ("git diff HEAD"). This cruft all goes away if there is no index: you can just have "git diff" for the usual case of "show me what's different between the branch and working copy", like in virtually every other revision control system on the planet.
> I think if people are taught git focusing on the index/staging area, it makes a lot more sense and you have much fewer problems.
Absolutely no disagreement there. The index is there (complaining won't make it go away), and you have to know about it, otherwise you will not understand what is going on in some situations. People learning git must learn about the index upfront and know things such as "git diff" diffing against the index, or that the successful parts of a merge are in the index whereas the conflicts are unstaged and things of that sort.
Git is one of those things where it pays off immensely to understand the underlying object model.
Learn about commit objects, tree objects, and file blobs. Then learn about the staging area.
There are some things layered on top of or next to this (such as stashing, pull and push), but understanding this small core is sufficient for everything else. I've worked on large problems and juggled many branches, and I've never had any problems.
Git gets the core concepts of distributed version control right, and this is the reason why it has won. Over time, everybody will be exposed to those core concepts, and the age of cutting and pasting command line recipes from the web will be over.
Once I read that git's core model is a DAC abs everything is just a label to nodes on the graph, I haven't had any issues using git. Before that, it was a bit of a mystery.
> computer science degree and years of experience to even begin to understand Git, for one thing.
Unless you're programming, in which case you should be able to understand git well enough, there are plenty of tools which completely abstract away the CLI interface (GitHub's is great).
So, "when I need something easier to use" would be your primary use case for this? Which would mean that for someone that knows git reasonably well already, they would have no use case for this software? After all, learning a wholly new tool is harder than using a tool you already know.
Most version control systems today are multi-user, multi-file, and multi-fork oriented. These are all good features and properties to have, but they neglect the need to maintain simple single-file documents, such as HOWTOs and FAQs, much like the very file you are reading now. There is even a good use-case for small programs and scripts. Do you presently keep your ~/bin contents under version control? If not, consider using SRC for them."
OK, but I don't see how git having those capabilities makes it inappropriate for cases where you don't need them.
I guess I can appreciate the single-file revision control thing, since that is something git doesn't do well. But, I am usually OK with a whole directory being under revision control.
All the other stuff is irrelevant, I'm pretty sure. Don't want branches and tags (I guess that's what "multi-fork" is referring to)? Don't use'em. Don't want multi-user? Doesn't matter, git doesn't lock files, and the user never needs to think about users if they are the only contributor to the repository.
The point is managing single files, not directories. Want to version control your ~/.bashrc, for example? Or a single document? You can do that without having to move the file into its own directory in some hackish way.
I don't get how git (or any proper multi-file dvcs) falls behind facilitating the purpose ESR is shooting at. You can use "git log <file>" to track changes of <file>.
It's like Gmail drafts. While it's delivered to you as an email stashing feature, I realized that it's the best cloud-based (offline-synced, omnipresent) note application. It can do that even if "note" is not in its name. We can be creative about using the tools at our disposal.
Besides (back to the original problem), it can be handy sometimes that you have a tool that can operate over the whole range of managed files, even if they are logically unrelated.
I don't know about this tool, but git does not make it easy to move files from one repository to another, for instance, and maintain that file's history.
Heck, I'd like to be able to e-mail a single file to someone, and have the file keep its revision history. File-based revision histories, as opposed to repository-based, have a whole host of advantages that come from flexibility.
git also has good support for explicit cutting down the repo to a subset of its files, or merging back changes of a partial repo to the common one, see filter-branch and subtree commands.
Here's a very obvious use-case: You have a single file with many historical changes. That file moves to a new directory that is not a subdirectory of its current directory.
In git, the file vanishes from the repo and can't be tracked easily anymore. You lose all of its past history if you put it into a new repo. In SRC the history moves with the file.
I'm not saying that any of the stuff suggested can't be done with git. The point is that this is not the use case git was designed for, so it doesn't accommodate it easily -- you must write all the exceptions and special cases into your repository, which is cumbersome.
What if you'd like to track files at your filesystem root? /.git would be a tad complicated, since you'd need fairly complicated .gitignore rules, right? You wouldn't want "git status" or "git diff" to read your entire filesystem, including all mounted devices.
"git status" recurses only into those dirs where there is managed content. "git diff" restricts its operation to managed files.
That said, if you are into managing particular files and not a file tree, most likely you'd consider all info about other files than the chosen ones to be noise, which can be expressed in .gitignore in a very succinct way: '*'.
I can see the need for a VCS that doesn't grab the whole directory but is file based.
But this "SRC is built on top of RCS" doesn't sound like the best idea. RCS has been historically more errorprone than SCCS, probably because it doesn't use a checksum in its history file. So you never know if there has been a corruption or not.
Even though he mentioned SCCS "SCCS died off due to its proprietary nature", he doesn't seem to be aware that the Solaris version of SCCS got open sourced:
http://sccs.sourceforge.net/
You're kinda missing the point: this project is designed around a single user maintaining a linear history for a single file. Using it for a project would be a weird impedance mismatch.
That's not to say I find SRC compelling... in the slightest. Just that you'd never use SRC to track a project.
You're right, I was mostly just being snarky - but, that said, the source of SRC (sigh - what a terrible name, as others have said) is, in fact, just one Python file, so I suppose you could arguably use SRC for it.
Hah. I just looked at the src (heh) - you're right, one file. I take back my argument.
If esr wants to fetishize a time when Real Programmers took patches over nntp and applied them in rcs, then by god he should go all in and self host the thing!
At the very least I would have liked to see some kind of minimal global index of changes. With single-file vcs, you may have a large tree littered with .src files, and you have to walk to the whole tree just to find all your revision controlled files. By [also] storing them in a global index you could simply list all revision controlled files, then perform operations on them all or on parts of them, without having to 'find' each time. That could default to $HOME/.srcidx so you never have to initialize some root tree or track an environment variable.
In quilt, your revision history is a "stack" of patches which is applied to the tree. You can push and pop up and down the stack, and revise the patches (for instance, to migrate them to a different version of the tree, or just to make them more perfect).
Quilt is good for managing patches - as in applying or removing them if you know they do apply. But from what I experienced, doing anything else with it is a world of pain. You actually need to say which file are you going to change before changing it! Handling git merges/rebases seems to be a walk in the park compared to fixing quilt patches that don't apply anymore.
I wouldn't say it's useful for individual files either...
I've been using git for years at this point, so I'm glad to leverage my existing skill. It also ties into my existing setup for SSH, so that I can push and pull changes from a central server. I like this because I regularly work on two different desktops, a laptop, and a few other machines.
Yeah, I unsubscribed from his blog "Armed and Dangerous." He thinks he thinks he is smarter and more knowledgable about general topics than he really is.
It should be named "Just Enough Knowledge to be Dangerous."
Logic only gets you so far when your base of knowledge is very limited in a subject.
There's nothing un-nice about that article. It's a reasoned argument. You may disagree with its conclusion, and you can write your own refutation of it. But it has nothing to do with ESR's niceness.
This is the Internet in 2014. We don't refute controversial arguments, we scream "wow, just wow, hate speech, what a bigot", publicly shame and defame their character and derail their careers. We're enlightened now.
The comments section provides some very decent counterarguments which ESR seems to skip over. I have to say, I'm a bit surprised. I'd read his writings on open source and I thought they were always interesting if not fully convincing, but I never knew this side of him and I'm not too impressed.
I agree with the sentiment, but I think that attempting to refute an argument and being personally disgusted by people who make a particular argument, not doing business with them, and advising others not to do business with them are not mutually exclusive choices.
You don't want to tip into the "people hating me because of something I said is an abridgement of my god-given right to free-speech" crowd. You have to be responsible for both what you say, and also for how people interpret what you say in order to be an effective communicator.
After reading, I'm not sure what to think. I do not have the subject matter familiarity necessary to take a position on his claims, nor does he cite anything other than personal experience and his own research.
If his historical claims with regard to homosexuality are correct, then I can say with great certainty that his other claim as to how these facts will be interpreted in the modern climate is distressingly right.
Worth noting that he takes no position on the rights of homosexual couples. The only value judgement made therein is that (assuming the information used to reach this conclusion is correct) that historically, homosexuality been associated with some pretty ugly and downright evil things.
If they're not correct, then this amounts to a very, very disgusting and ugly smear piece worthy of groups like the infamous Westboro church.
So now I wonder.. which is it?
If it weren't for the Eich/Mozilla thing from a few months ago, I'd have looked at these claims a lot less skeptically coming from a technologist who's intimately familiar with logic, and who would necessarily place facts above all else when it comes to arguing a point. That's not a thing I can do anymore, especially considering the tendency of actual bigots to couch their own personal prejudices in superficially-correct-sounding scientific language.
The only analysis I'll give for it is that I was also disturbed by the idea of Eich being forced out, but would never donate a penny to organizations fighting marriage equality; two wrongs can't make a right.
OK I give up.
I find his thoughts on race to be alarming, too.
It's hard for me to reconcile the idea that ESR's beliefs are germane and troubling with the principle of tolerance for other people's beliefs. But: I think there's something substantively and intrinsically disturbing about the specific things ESR says. I don't think I'd have trouble being friends with someone who opposed marriage equality. But I do have trouble with what ESR says about LGBT people. It might be the whole package of positions that ESR takes, not just about LGBT issues but about race, politics, &c.
I have friends with very conservative beliefs (though none, to my knowledge, have ever argued that homosexuality is inextricably bound with pederasty). But none of them have a cohesive worldview in which their own attributes just happen to define the ideal human, compared against which all nonconformant humans are inferior. ESR, on the other hand...
ESR's general observation that the ancients often saw homosexual as being about dominance is probably correct. However, the framing makes it sound like this is specific to homosexual relationships. In fact ancient cultures often saw ALL male sexual relationships as being about dominance. Of course they didn't really need to spend a lot of time discussing who was being dominated in a heterosexual relationship: it was always the woman in pretty much all pre-modern civilizations.
This makes his second point about a supposed biological predisposition towards domination sex really apply to all men. If gay men are struggling with this "biological headwind" then so are straight men.
> The only value judgement made therein is that (assuming the information used to reach this conclusion is correct) that historically, homosexuality been associated with some pretty ugly and downright evil things.
> If they're not correct, then this amounts to a very, very disgusting and ugly smear piece worthy of groups like the infamous Westboro church.
> So now I wonder.. which is it?
Well, that's tricky. Most of the historical associations he makes are roughly correct as stated, but what is misleading is the implicit claim that underlines the whole piece -- that equivalent historical associations don't exist to each of those for heterosexuality, which they do -- romantic heterosexuality only became a cultural norm (rather than something portrayed as exceptional, often dangerous, and very frequently as a source of deviance from cultural norms relating to the family) in the Western world only fairly recently historically. The "massive reinvention" of (male) homosexuality that ESR refers to is real, but its part and parcel of a broader reinvention of sexuality in general from a very similar starting point and in a very similar direction.
Because (and here I make the first and only value claim in this essay) whatever one’s opinion of homophilic homosexuals might be, the behaviors associated with the pederastic/dominating classical style are entangled with abuse and degradation in a way that can only be described as evil. Modern homosexuals deserve praise for their attempt to get shut of them.
If you disagree with the reasoning prior to that or that his facts are wrong (which is entirely possible), then yeah, he's full of shit. That said, he does compliment "modern homosexuals" in contrast to what he claims came before.
It's uncomfortable reading, but I don't exactly see him advocating dragging anyone behind a truck.
What you're quoting is a trope whose malignancy might be more obvious in a racial context: "The good black people deserve praise for their attempt to get shut of them".
Not only does he compare them, he contrasts that societal relationship over time. Doing so doesn't make him a degenerate. A windbag, sure, or a liar, but degenerate is a particular term.
Do you disagree with his premises or his facts, or just his conclusions?
For example, I think he's wrong because he doesn't cite sources for his assertions about the demographics of various types of porn or sources for his claims of historical homosexuality/pedophilia. But that's a straight matter of "Where did you get this idea from?".
You know, the world does not consists of two opposing positions, like republicans or democrats. There could actually be other positions than those two you pointed out. One for example that this is Hacker News and not Huffington Post.
Your comment about "support him by using his software" is just silly.
Lots of creators in this world have had less than flattering opinions in different topics, but does not take away what they produced.
I can still enjoy Wagner regardless of his views on the jews. I don't have to reformat all my ReiserFS based hard drives after Reiser murdered his wife. And The Pianist by Roman Polanski is an absolute masterpiece, even though Polanski raped that poor girl.
So I evaluate SRC based on merits, not the creators.
In general, I agree. The question is whether you're helping promote the "bad parts" by promoting the good ones. I mean, why are we reading and discussing ERS's views on Catholic priests if not because many people like his software?
But by your definition you are already promoting other peoples opinions by using their stuff. It is unavoidable.
The only difference is that you don't care about those opinions because either you don't know about them or you don't think it is important. But they still exist.
People can have different political, religious, etc. views than you, but why should that influence whether you use his software or not?
Do you check the political views of all authors of each software before you decide to use it?
What if those views (or your own) change over time and you disagree with them?
(ESR aside) Why not? If I believe that someone's exposed views are harmful, doesn't it make sense to avoid increasing his/her overall influence?
I mean, the fact that we're discussing ESR's views on pedophilia shows that his influence in an unrelated area (software) increases the exposure of those views. If he was just a nobody like me, would we be discussing his blog post on Catholic priests? Not likely.
Do you check the political views of all authors of each software before you decide to use it?
I sure don't, but why does that mean one should actively ignore gained knowledge?
Maybe we respond more to the milieu of a comment more than its actual content. Personally I like conspiracy theories about topical things. I never believe them but they make me chuckle to see the world from a weird point of view. But some people are going to find such theories to be horribly offensive (like Buzz Aldrin about moon fakery). We all have the capacity to wrongly analyse something we don't understand and have no stake in. A lot of people don't know what it is like to be attracted to their own gender and come out with things that are not just offensive but blatantly silly. The rest of us no better.
First of all it would take too much time to find out all the authors of all the software that I routinely use, and then keep up with what their current views are on various topics.
But I think the main reason is that most software has more than one author, and it would be unfair to judge the usefulness of that software based on the (non-technical) views of just one of its authors.
Your reasoning would apply only for single-author software, and TBH I would consider those pet-projects anyway, and I don't think the original author would care much whether you use it or not.
Edit: about gained knowledge:
I think you could apply this if you compare multiple competing solutions, one deciding factor could be the author's thoughts on various topics.
Just like how a company's attitude towards various topics might be influencing your purchasing decision: for example
Nvidia doesn't support open-source drivers, hence I don't buy Nvidia when choosing a graphics card.
But again for me those are all technical reasons, I wouldn't factor an author's/company's political views into that decision, unless it was something really horrible.
Your reasoning would apply only for single-author software
But doesn't that fit SRC itself?
But again for me those are all technical reasons, I wouldn't factor an author's/company's political views into that decision, unless it was something really horrible.
Ah! But then you're not arguing whether it makes sense to factor the political views in the decision - what you're actually arguing is that ESR's views are not really horrible.
But since pothibo supposedly considers them really horrible, it makes sense that (s)he would factor in those views, no?
Maybe, although I don't think I made technical decisions based on unrelated events.
The closest that comes to mind is as described here: https://news.ycombinator.com/item?id=8602582
I did use ReiserFS in the past, and I did switch to something else but the reason was purely technical: XFS became quite good on a HDD, an ext4 very nice on an SSD, and also there didn't seem to be much development done upstream once the original author was gone.
Why not respond to bigotry with love, instead of hating back? This is not some zero-sum game. If anyone needs a little bit of success in life, it's a bigot.
This is not some mundane left wing vs right wing discussion. It's a guy who believes that homosexuals should be taken on the same level as pedophiles. The line between saying this and saying homosexuals should go to prison is thin at best.
Maybe people are downvoting you because you're showing an incapability to distinguish between someone's expressed beliefs and their personal character?
Eric Raymond, everybody:
"Nor is it any good thing that “youths” now behave as though they think they’re operating with a kind of immunity. We saw this in Ferguson, when Michael Brown apparently believed he could could beat up a Pakistani shopkeeper and then assault a cop without fearing consequences. (“What are you going to do, shoot me?” he sneered, just before he was shot) As he found out, eventually that shit’ll get you killed; it would have been much better for everybody if he hadn’t been encouraged to believe that his skin color gave him a free pass."
"
It’s not clear to me that this kind of indulgence is any better – even for blacks themselves – than the old racist arrangement in which blacks “knew their place” and were systematically cowed into submission to the law. After all – if it needs pointing out again – the victims of black crime and trash culture are mainly other blacks. Press silence is empowering thugs."
My sister is a psychiatrist and has the same opinion on the subject.
There's nothing wrong with postulating and analysing it, even if the views are perhaps unpopular. Nothing should be beyond discussion even if it's uncomfortable for some people. Without making a judgement (I have no opinion on this myself), all arguments need contrast.
My sister is a domestic violence legal clinic attorney and doesn't. I guess we're at an impasse.
We are of course in the weeds here. The question was, "does Raymond still think the way he did in that post from 2002?" The evidence seems dispositive: yes.
"So, why do we not treat self-reported transsexuals as insane and in need of treatment for a delusional disorder? I can anticipate a lot of possible replies; the trouble is that all of them apply just as well (or just as poorly) to the case of BIID or delusional paranoia."
ESR is a blowhard conservative, but he does tend to at least have nuance in his position, which you seem to be ignoring.
This is a hostile environment, nobody can have a rational conversation about this without burning a lot karma (of which you have more to spare).
Nobody here except those that have those experiences has anything useful to say about non-cis gender identity. Possibly also psychiatrists/psychologists not married to a particular ideology on the topic. From my admittedly few conversations with transgendered people, it's complicated and there are no easy answers to what precisely it is.
Part of the problem is you're using "delusional" stigmatically, which damns you and poisons the conversation.
Let's assume you mean "fair" in the sense of "reasonable", not "equitable here".
Let's assume you mean "delusional" to mean "maintaining beliefs not supported by evidence and refusing to change said beliefs once presented with evidence". I'm going to leave off a stronger clause that would include non-falsifiable beliefs, because that way lies all manner of distraction.
Let's also assume that you mean "gender identity issues" to comprise a spectrum, ranging from "I am trapped in a body which feels wrong, I must take drastic action" all the way to "I tend to think more similarly to members of the opposite sex." Note that this range is supplied only by way of example: human gender and sexuality, as well as subjective experience of same, is wide and varied and I will not claim authority on what is and is not a valid experience there (as coolsunglasses has rightly pointed out).
With that understanding in place:
Is it fair to consider everyone with gender identity issues as delusional? Hell no--such issues may manifest with a completely normal and sane person, no delusions required.
Is it fair to consider everyone with gender identity issues as perhaps being delusional? Yes, but only insofar as they may exist in the subset of (delusional && GII) instead of merely (GII). It's the "perhaps" or "may" that turns it into a logically reasonable statement. Whether it's a likely membership is something else entirely, and I suspect that that likelihood is quite low--I don't think that possessing GII correlates strongly with delusional thinking.
Your statement of the question made it very easy to answer in a way that looks bad unless a lot of specific context is brought in--context which you did not supply.
~
At any rate, ESR's statement there was not posing the same question you were: he was asking first "Why do we not treat these as mental health issues?" (a stronger statement than your "might simply be delusional") and "Why do the (predicted) explanations for why we do not also hold up for, say, paranoid delusions?".
For the record, he screwed up by not enumerating the expected explanations. He also screwed up by not explaining how he might consider the application of one of the explanations to paranoid delusions.
I disagree that we ought treat the transgendered as insane, but he didn't make that claim: he simply asked a question. If you read it rhetorically, then I can see your grievance; that said, I think it was meant in earnest.
You're applying a lot of charity to what Raymond wrote, which is a good thing; unfortunately having a full context for all of ESRs positions on a variety of issues has burned away most of the charity I could apply to him.
Like I said: there's a pattern to Raymond's public policy writing: people who look and act and think the way Raymond does are valorized, and people who don't are stigmatized. In isolation any of his beliefs might be defensible (as you're trying to do with this particular one), but taken as a whole, it's hard to believe that the problem is "everyone besides Raymond", rather than just Raymond.
> ESR, is, if nothing else, the champion of his own relevance
What an apt description. I never have had much confidence in the coding that ESR has done. Just look at fetchmail and how that one has lost uncountable mails because of poor design.
Although he seems to think highly of his coding skills but I always had the impression that he's one of those hackers that really just hack together solutions. If a problem comes up there's always a fix to be committed. I wouldn't want such a programmer on my team.
But he's always been good with words and as an OSS lobbyist he was a well needed figure that put the software first and not politics as RMS did.
{kind=link}
Unfortunately, I think the implementation leaves a lot to be desired. For one, not including the committer is an important flaw. If you're only managing your own system's configuration, it makes sense, but surely ESR realizes that UNIX-based OSes are multiuser systems, often administrated by teams of people. Being able to track whodunnit is definitely an important part of the equation. (It'd be incredibly clever if it signed the log with the user's public key too, but that might be asking a lot.)
Needing something like SRC to track changes to a simple README or HOWTO? My local bin dir? Ehh not so much. Especially if it's a software project? No, that definitely should live in the VCS with the code, so that those who touch the code will also touch the documentation. It says a lot about src that it doesn't even live in a src repository.