Author uses Nagios at Etsy, with 10,000 checks (mostly in the 2 minute range), and it seems to work well for them with some minor tweaking. They have a plugin that provides a REST API. And he thinks the rest of the complaints are about backend stuff that he doesn't deal with much or at all (configs, wire formats, et al.)
He considers Nagios to be simpler than the proposed Sensu, and prefers "Unix style" applications rather than monolithic ones, where Nagios is certainly on the simpler side.
So he will continue using Nagios because it works well for his use, and good luck making something better.
> So he will continue using Nagios because it works well for his use, and good luck making something better.
Ops guy here. If something better than Nagios/Zabbix came along, ops people would use it. Nagios gets used because 1) people know it and 2) its pretty easy to setup.
Is it going to scale to Netflix or AWS scale organizations? Probably not. But at that scale, I presume you have buckets of money to throw at problems (i.e. build a custom monitoring platform).
That's like saying 'If something better tha PHP came along, programmers would use it'. Something better did come along, but that doesn't change the fact that PHP is still popular.
The first bulletin point: “Doesn’t scale at all.” I wonder how much traffic is sending to his blog right now. Just in 1 hour we DDoS-ed his blog with HNers visiting his blog.
I'm going to buy pg and company a beer and get code integrated into HackerNews that turns all submitted links into Coral cache links. Its 2014 and the Slashdot effect is alive and well :(
That's actually a great idea! :) Haven't actually thought of that. Two things in mind: rewrite links but provides copy-paste for the original link (think about XSS from clicking a link on tweet and people want to look at the link before clicking it) and (2) HN's rewrite/shortened link must do dynamic cache url retrieval; not static. I think Google's cache link is different as cache is updated.
My colo server died earlier today (completely unrelated to this) and didn't come back up because GRUB hadn't reinstalled properly on a replaced software RAID disk.
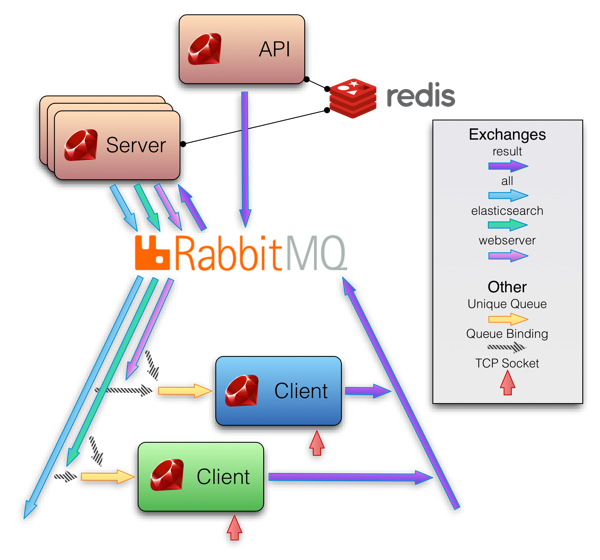
> ...just the architectural diagram of how it works scares the shit out of me. When you need 7 arrow colours to describe where data is going in a monitoring system, I’m starting to fear it slightly.
This strikes me as a pretty lazy argument. Admittedly, that diagram is not the best. But that you can separate the components of Sensu isn't a bug, it's a feature. No one says you have to do it this way. In fact, you can exactly replicate the architecture of Nagios by having a single server. The point is you have choices, choices which are dependent not on the monitoring software (which is very lightweight by design in the case of Sensu), but on the other open source software it relies on (Redis, RMQ).
So I would argue that the "server instance" scope is way too broad a category to measure complexity. If you attempted to diagram the workflow Nagios uses (ignoring for a moment what server instance each component is on), you would come up with something equally bad (if not worse). That's if you even understood anything at all about how Nagios works to know what to diagram.
So let's replace one crude measure with another. The Sensu core repo is ~3MB total. Nagios core is about 10x that (30MB). NRPE is about 1MB all by itself. Mod_gearman (to pick out an add-on) comes in at a whopping 6MB. Suffice it to say, but for something that's basically a glorified exit code validator, this seems like a lot of complexity. Sure, Nagios has a lot of features that Sensu doesn't have, and that accounts for some of this. But there's a lot to be said for modular systems vs. monolithic ones.
{kind=link}
{kind=link}
In response (obviously) to http://www.slideshare.net/superdupersheep/stop-using-nagios-... (also available through HN).
Author uses Nagios at Etsy, with 10,000 checks (mostly in the 2 minute range), and it seems to work well for them with some minor tweaking. They have a plugin that provides a REST API. And he thinks the rest of the complaints are about backend stuff that he doesn't deal with much or at all (configs, wire formats, et al.)
He considers Nagios to be simpler than the proposed Sensu, and prefers "Unix style" applications rather than monolithic ones, where Nagios is certainly on the simpler side.
So he will continue using Nagios because it works well for his use, and good luck making something better.