I was a bit baffled the first time I was introduced to Simulink Coder. I get the value proposition: simulate your model so that you have confidence it's doing the right thing, and then essentially just run that model as code instead of implementing it yourself and possibly introducing mistakes. What I didn't understand, as a software guy, not an engineering guy, was why on earth you'd want a graphical programming language to do that. Surely it would be easier to just write your model in a traditional text-based language. Hell, the same company even makes their own language (MATLAB) that would be perfect for the task.
I did a little digging, and it turns out I had it backwards. It's not that Simulink invented a new graphical programming language to do this stuff. Control systems engineers have been studying and documenting systems using Simulink-style block diagrams since at least the 1960s. Simulink just took something that used to be a paper and chalkboard modeling tool and made it executable on a computer.
Bingo. Additionally, control theory block diagrams are pretty rigorous, with algebraic rules for manipulating them you'll find in a controls textbook. You can pretty much enter a block diagram from Apollo documentation into Simulink and "run" it, in much the same way you could run a spice simulation on a schematic from that era.
Yeah, there's a really interesting phenomenon that I've observed that goes with that. If what you're describing was the main way people used it, I'd be very satisfied with that and have actually been chewing on ways to potentially bring those kinds of concepts into the more "mainstream" programming world (I'm not going to go way off on that tangent right now)
What I've seen many times though in my career that awkwardly spans EE and CS is that people forget that you can still... write equations instead of doing everything in Simulink. As an example I was looking at a simplified model of an aircraft a couple months ago.
One of the things it needed to compute was the density of air at a given altitude. This is a somewhat complicated equation that is a function of altitude, temperature (which can be modelled as a function of altitude), and some other stuff. These are, despite being a bit complicated, straightforward equations. The person who had made this model didn't write the equations, though, they instead made a Simulink sub-model for it with a bunch of addition, multiplication, and division blocks in a ratsnest.
I think the Simulink approach should be used when it brings clarity to the problem, and should be abandoned when it obscures the problem. In this case it took a ton of mental energy to reassemble all of the blocks back into a simple closed-form equation and then further re-arranging to verify that it matched the textbook equation.
I had an intern do something similar with an electromechanical machine. I'd all but written the equations out for him but he found drawing it out in Simulink in the most fundamental, primitive blocks to help him understand what was going on . I don't get it either.
A related phenomenon seems to be people who don't want to "wire up" schematics but attach named nets to every component and then draw boxes around them.
> people who don't want to "wire up" schematics but attach named nets to every component and then draw boxes around them
Lol there are a few things that I am highly intolerant of and this is one of them. The only place where I'm generally ok with that approach is at the input connectors, the microcontroller, and the output connectors. Same philosophy as I said before though: "if it brings clarity draw it as a wired up schematic; if it turns into a ratsnest use net labels to jump somewhere else". Having every component in a separate box with net labels will generally obscure what's going on and just turns it into an easter egg hunt.
Also, part of the style seems to be to contort any actual schematic to fit in the box. I like to ask "if you wouldn't put it on its own page so you could draw it clearly, why did you draw a box around it?".
I don't really get this point of view. Take an I2C bus, for example. Isn't it easier to read the schematic if all the components on the bus have two pins connected to wires labeled 'SDA' and 'SCL'?
Sometimes, and it depends what you're trying to convey.
Take a system with multiple I2C devices - with each device on a different sheet, it becomes difficult to tell that you might have bus contention issues.
> You can just count the number of devices connected to the I2C bus
If everyone working on it has the software, they can count easily and accurately.
When I started and still sometimes today "just counting the number of devices" requires visiting each sheet of the schematic, then hoping you didn't miss one.
> That seems easier than if you had to follow a bunch of tangled lines.
Today's software will let you draw a single bus connection between all bus devices.
> That seems easier than if you had to follow a bunch of tangled lines.
The problem is generally that if you choose to put some things near each other, you're choosing to put other things further away. In many cases the I2C bus itself has little to do with what the I2C devices do, so by drawing a single I2C bus or pair connecting all the devices with splitting them up with a named bet, you're choosing to make those other things harder to show. This may or may not be appropriate for the design.
>If everyone working on it has the software, they can count easily and accurately.
Any IC on the I2C bus will have pins labeled SCL and SDA, so you can easily just go through all the ICs and count how many have those pins. It might be slightly tedious with a paper schematic, but it's hardly impossible. It still strikes me as easier than doing the same thing with unlabeled pins that are connected directly in the schematic to the UC's I2C pins.
>In many cases the I2C bus itself has little to do with what the I2C devices do, so by drawing a single I2C bus or pair connecting all the devices with splitting them up with a named bet, you're choosing to make those other things harder to show.
I don't quite understand what you're saying here. Labelling a pin with SDA or SCL makes it clear that it's connected to the I2C bus. What I'm saying is that I don't see any value in drawing a line connecting the pin to all the other SDA/SCL lines. That's completely independent of how you lay the schematic out or split it into functional blocks.
> It might be slightly tedious with a paper schematic, but it's hardly impossible.
What may only be slightly tedious for you will often be error-prone for someone else.
>I don't see any value in drawing a line connecting the pin to all the other SDA/SCL lines.
The value is that the entire bus is visible at a glance. All conflicts are visible, and contention sources understandable. Though, you can also put this information in a note/table.
>That's completely independent of how you lay the schematic out or split it into functional blocks.
What I mean is that it's often also valuable to split a schematic out along functions rather than busses. If you have an I2C ADC with a bunch of analog stuff connected to it, that might fit its own sheet better. But if your weather station I2C bus has several simple devices like Flash, ALS, humidity sensor, RTC, barometer, and thermometer, placing them together on one sheet may make sense. I just mean tidyness varies with the contents of the room.
I am not really understanding the "at a glance" part. If there are no labels then you have to follow the wires. That seems more difficult, not easier.
You can split out all the components on the I2C bus onto a separate sheet (or not) regardless of whether you label or SDA and SCL lines or connect them with wires.
If the complexity of the attached subsystem is low enough, the wires can be used as a feature not a bug, like a map.
Imagine a home network diagram with a router, switches, and computers. You could draw each on their own sheet with names for each cable, but the purpose of each cable is clear from what it connects.
Yeah, there’s a balance here. There are common nets like SDA, SCL, GND, VCC that make sense to have as global nets. And then there’s actual circuits where it makes more sense (for understandability) to not do it like that.
- The audio jack (line level) could have just sat to the right of the codec and been directly connected to it to make it clear that it’s just a direct output
- the speaker amplifier could be directly connected to the audio jack as well. I spent a lot of time looking around to figure out where it actually connects to; I figured it would have its input connected to the MP3 codec and didn’t realize that it would be connected through the micro switches inside the headphone jack (which makes sense now that I see it)
- the SD card slot could either be connected directly to the codec or could have better names on the nets. When I see MOSI, MISO, and SCK I assume that they’re connected to the main MCU. Even more confusing, there’s an SD-CS that is connected to the MCU but not the rest of the SPI pins
Overall I’d probably give this one a B. It’s by no means the most egregious I’ve seen but it also obscures the signal flow pretty badly.
Other things I would probably consider doing:
- better clustering of pins on the MCU by function. The switch inputs and LED outputs that connect to the rotary encoder are all over the place. Most tools allow you to move the pins on microcontrollers around at will
- the FTDI block could move onto the first page. The DTR pin could use a bit of explanation that it’s tied to the reset circuit. Not their fault in this one but the naming inconsistency between
FTDI-RXI and TRIG4/TXO is confusing until you figure out that the pin is meant to be either a GPIO or a UART pin. The name doesn’t make it clear that it goes to the FTDI chip because it’s inconsistent with the rest of the FTDI-xxx names but that’s because most ECAD programs handle net names poorly anyway
Edit: one more thing that really bugs me about this schematic: the Vbatt net leaving J1. It’s labelled but not with any kind of flag or loose/unterminated line that would indicate that it’s connected to the net leaving U2. And further with that, the fact that VIN on U2 comes only from the FTDI connector on the second page (I think…)
I guess I would see a schematic like this in the context of an EDA tool which would make most of these issues moot. E.g. it is easy to find out what other nodes a specific node connects to. If for some reason you have to work from a paper or PDF schematic then I can see why these things would matter - but hopefully you don’t!
I’m not a very visual thinker, though. If it were up to me schematics would just be written out in some kind of textual representation, but EDA tooling tends to make fiddling around with schematic diagrams the blessed path.
100% I am working with paper schematics. I do a fair bit of field work in dirty environments (agriculture). When something isn’t working I want to be able to trace from the power input to the fuses to the regulators to the control signals to the output connectors. It’s much much easier when that all fits on a sheet of paper or two (or a screen or two) and it clearly flows from left to right.
Ok, fair enough, but you don't have to use a paper schematic for the LilyPad-MP3 thing. The Eagle sch file is here: https://github.com/sparkfun/LilyPad_MP3_Player/blob/master/h... It seems fine to me for schematics to adapt to new media. We don't worry about how easy it is to navigate our source code when it's printed on a teletype.
That's fine if you're the only person that will ever use the schematic. As the kids say, "you do you". But a schematic for a product has a life beyond your desk - it will be used by technicians, test engineers, firmware engineers, sustaining engineers, purchasing, quality, manufacturing (including fab houses and CMs), legal, compliance, the list goes on. Many of those people will not have a schematic capture tool installed on their computer and limited time to learn one - or in some cases, several. You will absolutely have to provide them PDF schematics and you should care if they are clear and follow common conventions. If you're thinking of a schematic as source code, maybe as data entry for layout, you're already making a category error. They are different in kind.
There are in fact ways that electronic media have changed schematic practice - it is extremely unlikely in 2024 that you will have a draftsman or CAD designer drawing your schematic from a sketch, though in some environments you might have a documentation team putting your work into a very strictly defined format, and it is pretty unlikely you will have a large-format plotter readily available. So the norm has shifted to multiple smaller pages, and there's little pain involved in adding another schematic page if you need one for clarity.
Note that sparkfun schematic was drawn for 8.5x11 paper even though the more natural size for full-size monitors is 11x17.
To me it seems like a process failure if people are reading paper (or PDF) schematics in 2024. EDA in general seems to be behind the times compared to software engineering in terms of tooling culture. If you saw a software engineering process that involved people reading print outs of source code you’d just say: “That’s insane! Stop doing that.” You wouldn’t bother to critique the formatting of the print outs.
> Note that sparkfun schematic was drawn for 8.5x11 paper even though the more natural size for full-size monitors is 11x17.
Again a cultural issue. The tools assume by default that you want to produce a sheet of paper.
A schematic is a drawing, not source code. Of course you're going to want to print it out and mark up the paper. You're making a severe category error. There is a visual language for communicating design intent in schematics that is not just formatting, or making things pretty (you can make a "pretty" but unclear schematic) or entering wiring connections into a computer. If you follow it, other engineers will be able to understand your work more quickly and with fewer questions for you. If you don't care, you will look like someone who doesn't care. It is the difference, say, between writing individual words or short declarative sentences as opposed to building complex sentences, paragraphs, a short report, etc.
As documentation, in a production environment, your schematic will have a life beyond your EDA package. I've done sustaining work on designs that have outlasted the design packages they were done with. Without having to open them up, because there were schematics available in standard documentation formats. Eagle - as used in that lilypad design from 2013 - already has a sunset date. It's also a reality that EDA packages have poor backwards compatibility and even worse, their "import" functions rarely work at all well on non-trivial designs. That would be a fair criticism of the industry but for the most part redrawing a schematic and checking it against a netlist is not the end of the world. If you have one.
As an aside, it wouldn't shock me if lawyers print out source code, either. They print out everything else and store it on paper.
Of course a schematic is a drawing, but there is particular need these days for it to be a non-interactive drawing laid out for printing on a sheet of paper. Equally, source code is text, but that doesn’t mean that in 2024 we have to worry about how well suited our source code is for printing on a teletype. I am not saying that no care should be taken when creating schematics, only that the conventions that made sense when schematics were static printed documents will not necessarily make sense now that a schematic is created, viewed and manipulated via an EDA tool. In a similar way, version control, interactive editors and IDE tooling have given rise to rather different coding conventions than the ones that predominated when people entered numbered lines of BASIC, or assembled machine code by hand on sheets of paper.
A move to open EDA formats is indeed long overdue. KiCad is a step in the right direction.
All good points. By the way, yes, if you have one peripheral device on an i2c bus, and your design is small enough that you're drawing the device on the same page as your microcontroller, you should make the connection explicit. My two cents:
- Making the power routing completely implicit is another hallmark of the style and it drives me crazy too. The power, charging, and maybe FTDI boxes should all be together on one page. Now, I might change my mind about this in six months, but I am starting to warm to the idea of drawing a power tree for even pretty simple power schemes like this one. The power tree style in the Arduino documentation is pretty nice
- In the same vein, even modest designs usually benefit from a block diagram up front. You don't need to use hierarchical design functions - just boxes and arrows and text done with the drawing tools of the CAD program
- I like that they actually did put most of the "bookkeeping" connections on the left side of the micro. I'd move the UART pins over to that side too, and the programming port. The programming port belongs with the micro and nowhere else, would you put it on its own page?
- Audio signals flow right to left to down for no particularly good reason except to get all the other boxes to fit on the second page. All the audio could be on its own page
- Similarly, LED signals come in to the rotary encoder on the right and encoder signals come out on the left. Really?
- I like that they grouped the bypass capacitors with the ICs but for these modest numbers of bypass caps I prefer to see them shown connected to the pin pairs they'll be placed by
- OK, not a schematic point and not critical for a hobbyist product but powering the battery charger from USB is a potential issue. Low line by spec on USB is 4V at the connector, and you won't get 4.2V out of that with a linear charge controller. They might also be exceeding maximum effective capacitance on the USB power bus. Again, not critical for a low-volume "maker" product - it will always work except when it doesn't
- No off-page connectors for off-page connections. I like to see the pages called out that an off-page connector connects to, but I admit that's a pain to do by hand
- The pull-ups and pull-downs in the top right hand corner of the second page are typical of the style. Who ever heard of connecting these directly to the pin that needs them? Again, it looks like this was done to fit the subcircuit in the box
> I am starting to warm to the idea of drawing a power tree for even pretty simple power schemes like this one
I'm laughing/crying right now because of a board I had to deal with last week at $JOB. Pretty beefy power distribution board with some... quirks related to load shedding etc. Details don't matter there. I ended up drawing the whole power graph (it's not a tree, there are two independent inputs that go through ideal diode controllers for some of the rails for redundancy). By carefully rearranging the nodes of the graph I managed to get it completely planar (no overlapping edges) except for one spot where a poorly-thought-out connector did require one edge overlap.
Laying that out as a planar graph dramatically simplified routing. It's a technique I hadn't explicitly used before and it sure worked out nicely.
The other technique that comes in handy in that kind of situation, if you have multiple power/voltage/current domains that require spacing or other isolation from each other, or multiple ground references, is an isolation or insulation diagram. I don't have a great example; if you search you'll find a style that will meet medical device requirements and can be adapted for other use.
One cool thing about, for instance, density altitude calculations or runway length calculations, is that you can break the parts of the algorithm down graphically do pilots can trace through datapoints to get an answer without even having a calculator. See many pilot operating handbooks for examples.
I'm hoping at a minimum get my thoughts written out while I'm flying this weekend!
The quick gist is that Jupyter is frustrating for me because it's so easy to end up in a situation where you inadvertently end up with a cell higher up in your document that is using a value computed in a cell further down. It's all just one global namespace.
In the Julia world with Pluto they get around this by restricting what can go into cells a little bit (e.g. you have to do some gymnastics if you're going to try to assign more than one variable in a single cell); by doing it this way they can do much better dependency analysis and determine a valid ordering of your cells. It's just fine to move a bunch of calculation code to the end/appendix of your document and use the values higher up.
The idea I've been chewing on comes somewhat from using Obsidian and their whole infinite canvas idea. It seems like using ideas from Pluto around dependency analysis and being able to also determine whether the contents of a given cell are pure or not (i.e. whether they do IO or other syscalls, or will provide outputs that are solely a function of their inputs) should be able to make it easier to do something... notebook-like that benefits from cached computations while also having arbitrary computation graphs and kind of an infinite canvas of data analysis. Thinking like a circuit simulator, it should be possible to connect a "scope" onto the lines between cells to easily make plots on the fly to visualize what's happening.
Anyway, that's the quick brain dump. It's not well-formed at all yet. And honestly I would be delighted if someone reads this and steals the idea and builds it themselves so that I can just an off-the-shelf tool that doesn't frustrate me as much as Jupyter does :)
it sounds like the ideal solution would be something functional (so you have a computation graph), pure (so you can cache results) and lazy (so order of expressions doesn't matter.) why not Haskell? or even a pure/lazy subset/variant of Julia, if you want to ditch the baggage of Haskell's type bondage?
you could ditch explicit cells entirely, and implement your "scope" by selecting a (sub)expression and spying on the inputs/outputs.
I've thought about that and have written some fun Haskell code in the past but... the other goal is to actually have users :D. I've also considered Lisp, Scheme, and friends to have really easily parseable ASTs.
I jest a bit, but there's a very rich ecosystem of really useful data analysis libraries with Python that do somewhat exist in other ecosystems (R, Julia, etc) but aren't nearly as... I would use the word polish, but a lot of the Python libraries have sharp edges as well. Well trodden might be a better word. My experience with doing heavy data analysis with Python and Julia is that both of them are often going to require some Googling to understand a weird pattern to accomplish something effectively but there's a much higher probability that you're going to find the answer quickly with Python.
I also don't really want to reinvent the universe on the first go.
It has occurred to me that it might be possible to do this in a style similar to org-mode though where it actually doesn't care what the underlying language is and you could just weave a bunch of languages together. Rust code interfacing with some hardware, C++ doing the Kalman filter, Python (via geopandas) doing geospatial computation, and R (via ggplot2) rendering the output. There's a data marshalling issue there of course, which I've also not spent too many cycles thinking about yet :)
Edit: I did copy and paste your comment into my notebook for chewing on while I'm travelling this weekend. Thanks for riffing with me!
The people using matlab are typically experts in things other than programming. Matlab is for people designing antennas or control systems, where the math is more important than the code.
Most definitely, but my point was to my programmer-brain, nearly any text-based modeling language would be better than some sort of awkward graphical diagram. And since the same company makes MATLAB, why not?
It turns out non-programmers actually like graphical tools. Go figure.
I once wrote a linear programming optimal solver for a business problem.
But because it was all equations and logical reasoning, it was hard to understand, and boring to non-enthusiasts.
So my manager had me make a visual simulation instead, which we could then present to his managers.
This isn't as stupid as it sounds - we humans have huge visual processing networks. It makes sense to tap into that when interfacing with other humans.
I think to learn programming or math, you actually end up learning to use this visual wiring to think about written symbols. But this process of rewiring - while valuable - is very hard and slow, and only a tiny fraction of humans have gone through it.
partly as a "this is what we were doing in 1962, you are now as far removed from that demo as that demo was removed from the year 1900 -- do you really feel like you've made the analogous/concomitant progress in programming?" ... and one of his points there was that a lot of programming acts as a "pop music" where you are trying to replicate the latest new sounds and marginally iterate on those, rather than study the classics and the greats and the legacy of awesome things that had been done in the past.
I'm just putting this Alan Kay question (from Stack Overflow) here because of relevance.
In that question, he's considered not with implementation or how good the execution of an idea is (which is certainly one type of progress), but in genuinely new ideas.
I don't think I personally am qualified to say yes or no. There are new data structures since then for example, but those tend to be improvements over existing ideas rather than "fundamental new ideas" which I understand him (perhaps wrongly) to be asking for.
this is awfully manual, does autocad have parametric topology tools ?
programs like houdini are more reactive and mathematical (no need to create width/volume by hand and trim intersections by hand), i think mech engineering tools (memory fail here) have options like this
One thing that I think diagrams are better at than common text-base PLs is that with diagrams (when the blocks are placed nicely) you can _very quickly_ tell what is going into something (both directly and indirectly).
Of course you can abstract away a bit with functions or intermediate values in programming, but at one point if you do that too much you now have a bunch of indirection that harms overall readability.
All a balance of course, but "what takes part in this calculation" often feels more valuable than "what is the calculation itself".
> It turns out non-programmers actually like graphical tools. Go figure.
I'd rather say that visual tools are better abstractions than what text based tools can provide for those specific scenarios. Some problems are easier solved with diagrams.
Programmers just don't like switching between representations - it's the same reason that "printf debugging" will still be widespread after all of us are gone.
Another thing is the ability to actually have a breakpoint in the program. There is a lot of distributed systems (especially embedded ones) where just stoping the program and inspecting the state will cause the rest of the system to enter some kind of failure state.
I use printf debugging locally as well. Interactive debuggers and I just don't get on, and my test cases are built to start fast enough that it works out for me. Usually I have a 'debug_stderr' function of some sort that serialises + writes its argument and then returns it so I can stick it in the middle of expressions.
(I do make sure that anybody learning from me understands that debuggers are not evil, they're just not my thing, and that shouldn't stop everybody else at least trying to learn to use them)
Sure, that's just one use case. And logs can be useful for history as well as current state. But I think it's the mode shift to "do I set a breakpoint here, and then inspect the program state" as opposed to just continuing to sling code to print the state out.
What's funny is that I learned to debug with breakpoints, stepping, and inspectors. I use printf debugging now because the more experience you get, the easier and faster it becomes. There's a point where it's just a faster tool to validate your mental model than watching values churn in memory.
Printf debugging is actually a very primitive case of predicate reasoning. Hopefully in the not too distant future instead of using prints to check our assumptions about the code we will instead statically check them as SMT solvable assertions.
Well, software developers in the embedded field of automotive use Matlab and Simulink quite extensively. I haven't worked with it myself but the "excuse" for using it was that "we have complicated state machines that would be difficult to write directly in C".
You would think about a lot of the things that they do, "how hard can it be?". Take a look at the simplified example statechart here (scroll down) for a power window control and ponder all the ways an embedded programmer could struggle to get the behavior right in plain procedural C code as well as how difficult it would be to get a typical team to document their design intent.
Those do strike me as elucidating the power in suitable contexts very nicely.
For those following along at home, click https://uk.mathworks.com/help/simulink/ug/powerwindow_02.png first and then realise that's a top level chart with per-case sub charts (and then follow buescher's link if you want to see those) ... and that at the very least this is probably the Correct approach to developing and documenting a design for something like that.
You're welcome, and yeah, that is the statechart. It's actually at the low zoomed-in level. That's the controller at the heart of the example. A lot of the diagrams in the article are higher-level, not sub-charts. I am not a 100% advocate for the BDUF-flavored model-driven-design approach in the whole document at that link, though I can understand why some industries would take it.
Remember, too, this is undoubtedly a simplified example. Just off the cuff I'd expect a real-world window motor controller in 2024 to have at least open-loop ramp-up and ramp-down in speed, if not closed-loop speed control. I also would expect there'd be more to their safety requirements.
> A lot of the diagrams in the article are higher-level, not sub-charts.
I must have failed to understand even more things than I thought I did. I'll have to read through again when more awake if I want to fix that, I suspect.
I think if faced with that class of problem (am not automative developer, just spitballing) I would probably try using some sort of (no, not YAML) config format to express the various things.
But that's a 'how my brain works' and I am aware of that - for database designs, I've both ensured there was a reasonable diagram generated when the point of truth was a .sql file, and happily accepted an ERD as the point of truth once I figured out how to get a .sql file out of it to review myself.
I haven't worked in automotive. And I'm not a strong advocate of exhaustive model-driven design like what's shown at that link. But it's worth looking at.
Generally if you have a state machine or state chart with more than a few states, it's worth implementing as a table. The "config format" is then an array in a source file. There is a standard interchange format, scxml, for statechart tooling and libraries, but if you're implementing your state machine directly from a whiteboard drawing, you might not bother with it.
What they didn't tell you is that these state-machines are differential equations as well. Again, the math is more important than the code. If you want to look more into it, just search for state variable control.
Matlab also solves a ton of common engineering problems with efficient BLAS wrappers. And it is (or at least used to be) pretty trivial to drop in a CUDA kernel for hotter code paths.
> Control systems engineers have been studying and documenting systems using Simulink-style block diagrams since at least the 1960s.
It dates to at least the 1940s with signal flow graphs (1) but from what I've heard, Shannon was working on fire control systems for the Navy and his work was classified. Some of that was famously published in A Mathematical Theory of Communication (2) where there are block diagrams for information systems, and Mason worked out Mason's Gain Rule/Formula in the early 1950s.
I would not be surprised if graphical representations date back to the 1920s/30s when abstracting electrical systems into things like circuit diagrams that ignore grounding were pretty common, or even earlier.
I used to work on GE's programmable logic controller product on the realtime OS side. PLCs are primarily programmed in ladder logic (https://en.wikipedia.org/wiki/Ladder_logic) and we had a full graphical UI to do that. IIRC (its been nearly 30 years) we also had a parser that parsed text based ladder logic diagrams to drive the OS tests.
Ladder logic is sort of a similar case right? Supposedly it derives from notation for documenting relay racks in factory automation that could very well date to the 1800s. And it's a pretty brilliant implementation - you don't need a degreed engineer or C programmer to set up fairly sophisticated concurrent system with it.
The idea behind that is neat. And well, the conversion from the ladder diagram to PLC bytecode is intentionally so trivial that it can be done by hand if the ladder diagram is drawn in certain way (which is the way the first PLCs were programmed).
Then there is the reality: every single one of Simatic projects I have seen was done by “PLC programmers” and had this peculiar feature of using the abstractions the wrong way around. Straightforward logic written as Instruction Lists (ie. assembly that produces the bytecode) and things that were straightforward sequential programming built from ridiculously complex schematic diagrams.
Heh. It figures. Sometimes when I see things like that I wonder if it's featherbedding and gatekeeping. If it looks too straightforward, people might not think what you do is very hard. See the schematic discussion elsewhere in this thread for another example
Any Ladder logic editor would have two views: the block view and the text view.
I used to work on Siemens PLCs. I started using only the block view, but over time migrated to only using the text view.
Now, I understand that the text view is basically a kind of Assembler. I liked it because I was able to think and visualize things in my head much better using text. But for simple flows, and people not versed in programming, the only option, really, is the block view.
Thanks for the anecdotal perspective. That's interesting!
As someone who cut their teeth on a graphical language and is a big diagramming person, it's always been curious to me as to why people want to write out stuff in text. It often feels extremely primitive. I've done large codebases in a graphical language before, and it felt so easy to orient myself as to where I was at in the system. In text-based languages, I feel lost in a sea of text that has almost zero differentiating factors.
There are lots of reason for why text is preferable though. I did some work on an drag-and-drop sort of a programming language for a ETL pipeline a while back. The absence of unit test cases makes it very hard to deploy changes without being sure you are not introducing breaking changes. There are other things as well. People tend to make big flow in one canvas. Which makes it very hard to understand.
There are few more things, like wherever a GUI component relevant to a case was missing, the tool provided a way to add a javascript snippet, eventually on some canvases all you see is JS components talking to each other. At that point you are better off writing plain JS code.
This gets to a fairly stark difference in how people model things. It is very common to model things in ways that are close to what is physically being described. Is why circuit simulators often let you show where and how the circuits are connected. Knowing what all can run at the same time is now very clear and knowing what can and cannot be reduced to each other is the same. If they are separate things in the model, then they remain separate.
Contrast this with symbolic code. Especially with the advent of optimizing compilers, you get very little to no reliable intuition on the order things operate. Or, even, how they operate.
Now, this is even crazier when you consider how people used to model things mathematically. It really drives home why people used to be far more interested in polynomials and such. Those were the bread and butter of mathematical modelling for a long time. Nowadays, we have moved far more strongly into a different form of metaphor for our modeling.
>> Simulink is a really nice way to do some control problems in.
Agreed. But it needs to stop there. BTW I never understood why the tool needs to know what processor the code is for. I asked them to provide a C99 target so they don't need to define their own data types in generated code. Does that exist yet? Or do they still define their own UINT_16 types depending on the target?
Dunno and I haven't worked with Simulink since 2019. There is this "type replacement" setting such that you can make Coder spit out "uint16_t" instead, but if I remember correctly, there was bugs such that you still needed to have the manual translation header. Like, some module of Simulink didn't follow the setting. God I don't miss working with Mathworks products.
This is kind of the mixed feeling I have about this blog post. There is a recognition that we need universal tools that are designed with honest intentions to be effective in general problem domains. But determining the boundaries of those domains is ultimately a political exercise and not a technical one.
It becomes presumptive to assume that Lisp is the be all, end all of car networking woes. Even if you accept that a tool to manage and organize computational tasks using a more functional paradigm would be helpful, that doesn't mean that a somewhat archaic, syntactically maligned language is the answer.
ROS tackles this somewhat yeah? But it's still very much a research project, despite its use in some parts of industry. The most significant development for computation in vehicles in recent times is still the automotive Linux efforts, so we are not really even in the ballpark to discuss specific languages.
Without Lisp-like macros, you need preprocessors or code generators. Something like Yacc/Bison is easily done with suitable macros.
In Common Lisp, macros also enable a kind of Aspect Oriented Programming. That's because one can dynamically modify macro expansion using the macroexpand hook. It's a way to modify a code base without changing the source files, which has all sorts of uses.
Gregor Kiczales, the guy behind Aspect Oriented Programming, said something like Common Lisp couldn't attain the level of (aspect oriented) tooling that Java could, because the tools in Common Lisp could not be sure what the Lisp code they were analyzing actually does, but in Java the language is constrained enough that the tools can figure it out. He said this in a MOP retrospective he gave at the Vancouver Lisp User's Group meeting on 28 June 2006 [1]. There's a link to an .ogg file in the link below, and he talks about this at around the 45 minute mark.
> but in Java the language is constrained enough that the tools can figure it out
So, ironically, the AOP tooling both takes advantage of this issue and fixes it in the same stroke. Once you have an AOP-endowed language like AspectJ, tooling can no longer know what code does
The disconnect between what your source file "does" and what it "says" is present in everything above assembly.
Change implementation of `foo(...)` and suddenly dozens of source files (none of which is modified!) which make calls like `foo(x)`, `foo(y)` and `foo(y+1)` change what they "do", all this without changing a single line in these files.
There is still a qualitative difference between reading
x.y = foo(z, t)
reading as "there is a variable labelled x, with a defined type within this scope, that contains a struct member y with a statically-computable offset within x's known memory layout, that will receive a copy of the function foo (which is known at compile time), which is the result of calling foo with a copy of z and t, which are also values with compile-time known types and layouts", even if you as a human may have to look up foo to know what is going on, and the equivalent in Python, which I will break out into a separate paragraph because this is going to get long even though it will still be incomplete:
"there is a reference x to an unknown type, which we will call one of several methods to resolve a field called y, where each of these methods may have been dynamically modified by previous code to not match their source implementation, which may either be a concrete value or a "descriptor", which will will have some method call performed on it (with full OO resolution rules on the method call, including the ability for the class structure to have been dynamically modified by code at run time and also all methods in the class structure to have been dynamically modified, and also the method can do anything a method can do including its own further dynamic modifications to arbitrary other structures, and also the result of running class and method decorators on everything in this hierarchy) with the result of calling foo, a values of unknown type that may be a function, method, or arbitrary values with a __call__ value (which itself may perform arbitrary dynamic operations in the process of returning a callable value), with copies of a reference to the values z and t of unknown type and capability, which will be filled in to foo's argument list in additional possibly complicated manners based on foo's definition and whether it uses args or kwargs, and also all of this code including the very statement under question may not exist in source at all because it may have been 100% dynamically constructed at run time itself."
And I probably missed some things in the Python too, but even so, Python already has numerous "and actually literally arbitrary amounts of code could be running here", and can readily introduce more.
All languages have the issues where you might have to resolve a function call as a human to know what is is doing, but in some languages, you're nearly done after that (C, Go) and in some languages your journey is just beginning (C++, Python).
So Lisp, even with macros, is not that bad. Macros add just one mechanism which you have to know in order to understand a piece of Lisp code from first principles.
The number of other special mechanisms in Lisp is much lower than in Python or C++.
Obviously macros are powerful which is another way to say "footgun". Also it makes the comparison a bit unfair - an out-of-the-box Lisp usually already has many macros which you have to know. They provide some of the stuff which needs to be hard coded into the compilers in languages like C++ and Python.
Agreed in the general sense, which is why I chose Python for my example, for clearer contrast.
I would say there's still a qualitative difference between languages where there is some well-defined, concrete procedure where you can take a line of source code and resolve exactly what it is doing, and a language where said resolution of what it is doing involves arbitrary code execution between the source code and what the code is actually doing. Python is frankly insane in some ways, but you really only need one place where arbitrary code is being invoked, and I mean this in the nicest of ways but Lisp programmers are fully capable of driving a truck through even that one particular hole.
Common Lisp implementations have the same procedure: you do MACROEXPAND or MACROEXPAND-ALL on the code, and boom, there's the code that says exactly what it does.
What you probably mean there is you want some abbreviation or specification for what the code does without having to expand it. It's not clear to me how this could work with all the things (like preprocessors or code generators) that macros can replace. Maybe you want a standardized API where the macro, in addition to computing the expansion, also delivers some sort of specification of what the expansion is doing? Or maybe you just are asking that macros be documented, like any built-in language feature?
Questions like this, I find, are best addressed by drilling down and asking for specifics about what you need.
Wrapping the existing code in hooks of some sort to enable injecting profiling or whatever is really quite nice.
A lot of javascript hot reloading implementations rely on using Babel to do that as part of a build step so they output the wrapped code and your app loads that instead (and it's not that dissimilar to compilers having a debug mode where they output very different code).
I would certainly side-eye you for using the relevant common lisp hooks in production without a very convincing reason, but for many development time tasks it's basically the civilised version of widely used techniques.
A use case is code coverage: you can instrument your code by compiling it in a dynamic environment where the hook causes extra coverage recording code to be inserted. You'd like to be able to do this without changing the source code itself.
One would bind the macroexpand hook variable around the call to COMPILE or COMPILE-FILE for that code. The binding goes away after that. It wouldn't be global at all.
That's a "shallow binding" implementation of dynamic scope which works fine enough; but if you have coroutines and continuations and such, it might not play along. Whichever thread invokes a continuation will see its own current value of the variable.
Under "deep binding", where we have a dynamic environment stack, we can save that stack as part of the context of the coroutine, continuation or whatever else. It requires only one word: a pointer to the top of the dynamic environment. Whenever we restore that pointer value, we have the original environment.
The common definition of “Aspect oriented programming” is more or less “just bolt whatever CLOS method combinators already can do onto another language”. That is powerful concept, but maybe somewhat orthogonal to macros, unless you want to do that with macros, which you certainly can.
That's certainly a form of AOP, but the hook mechanism here would enable arbitrary expansion time code transformations, not just injections at method calls.
> Something like Yacc/Bison is easily done with suitable macros.
Is this true? I may have misunderstood what macros can do in terms of remembering state, while applying. Looking it up again to see what i overlooked...
But it’s the reverse direction that Bison/Yacc does, as it writes code to recognize essentially expanded grammar rules/macros, collapsing existing code into an expandable grammar rule/macro that would correspond.
Um, what? Bison/yacc generate compilable C from a grammar file. A CL macro would expand to Common Lisp starting from a grammar description. It's not the reverse at all.
In my experience (Clojure) macro-heavy libraries tend to be powerful but brittle. A lisp programmer can do things in a library that non-lisp programmers can't realistically attempt (Typed Clojure, for example). But the trade offs are very real though hard to put a finger on.
There are several Clojure libraries that are cool and completely reliant on macros to be implemented. Eventually, good Clojure programmers seem to stop using them because the trade-offs are worse error messages or uncomfortable edge-case behaviours. The base language is just so good that it doesn't really matter, but I've had several experiences where the theoretically-great library had to be abandoned because of how it interacts with debugging tools and techniques.
It isn't the macros fault, they just hint that a programmer is about to do something that, when it fails, fails in a way that is designed in to the system and can't be easily worked around. Macros are basically for creating new syntax constructs - great but when the syntax has bugs, the programmer has a problem. And the community tooling probably won't understand it.
In racket you can define simple macros with define-syntax-rule but in case of an error you get a horrible ininteligible message that shows part of the expanded code.
But the recomendation is tp use syntax-parse that is almost a DSL to write macros, for example you can specify that a part is an identifier like x instead of an arbitrary expresssion like (+ x 1). It takes more time to use syntax-parse, but when someone uses the macro they get a nice error at the expansion time.
(And syntax-parse is implemented in racket using functions and macros. A big part of the racket features are implemented in racket itself.)
> Eventually, good Clojure programmers seem to stop using them because the trade-offs are worse error messages or uncomfortable edge-case behaviours.
I am not so familiar with Clojure, but I am familiar with Scheme. The thing is not, that a good programmer stops using macros completely, but that a good programmer knows, when they have to reach for a macro, in order to make something syntactically nicer. I've done a few examples:
pipeline/threading macro: It needs to be a macro in order to avoid having to write (lambda ...) all the time.
inventing new define forms: To define things on the module or top level without needed set! or similar. I used this to make a (define-route ...) for communicating with the docker engine. define-route would define a procedure whose name depends on for which route it is.
writing a timing macro: This makes for the cleanest syntax, that does not have anything but (time expr1 expr2 expr3 ...).
Perhaps the last example is the least necessary.
Many things can be solved by using higher-order functions instead.
My canonical use-case for macros in Scheme is writing unit tests. If you want to see the unevaluated expression that caused the test failure, you'll need a macro.
Python's pytest framework achieves this without macros. As I understand it, it disassembles the test function bytecode and inspects the AST nodes that have assertions in them.
Inspecting the AST ... That kind of sounds like what macros do. Just that pytest is probably forced to do it in way less elegant ways, due to not having a macro system. I mean, if it has to disassemble things, then it has already lost, basically, considering how much its introspection is lauded sometimes.
1) OMG confusing -> almost never use them
2) OMG exciting -> use them faaar too much
3) Huh. Powerful, but so powerful you should use only when required. Cool.
Quite a few things turn out to be like that skill-progression-wise and at this point I've just accepted it as human nature.
my plan there was to write ferocity0 in Java that is able to stub out the standard library and then write ferocity1 in ferocity0 (and maybe a ferocity2 in ferocity1) so that I don't have to write repetitive code to stub out all the operators, the eight primitive data types, etc. I worked out a way to write out Java code in a form that looks like S-expressions
which bulks up the code even more than ordinary Java so to make up for it I want to use "macros" aggressively which might get the code size reasonable but I'm sure people would struggle to understand it.
I switched to other projects but yesterday I was working on some Java that had a lot of boilerplate and was thinking it ought to be possible to do something with compile time annotations along the lines of
> I want to use "macros" aggressively which might get the code size reasonable but I'm sure people would struggle to understand it.
A long time ago I wrote a macro language for the environment I was working in and had grand plans to simplify the dev process quite a bit.
While it did work from one perspective, I was able to generate code much much faster for the use cases I was targeting. But the downside was that it was too abstract to follow easily.
It required simulating the macro system in the mind when looking at code to figure out whether it was generating an apple or an orange. I realized there is a limit to the usability of extremely generalized abstraction.
EDIT: I just remembered my additional thought back then was that a person that is really an expert in the macro language and the macros created could support+maintain the macro based code generation system.
So the dev wouldn't be expected to be the maintainer of the underlying macro system, they would just be using the systems templates+macros to generate code, which would give them significant power+speed. But it's also then a one-off language that nobody else knows and that the dev can't transfer to next job.
There's also the use of macros for internal stuff, for instance automatic api generation. Obviously this is a thing everywhere, but you can implement all of that inside the library itself rather with a secondary tool.
> A confirmation of Greenspun's Tenth Rule, if you will.
I've always found this rule suspect.
If it were true you'd have had lispers loudly reimplementing well-known, slowly-and-buggy mid-size C programs in common lisp, at roughly the rateand loudness the Rust people reimplement old C programs in Rust.
Did that actually happen?
If not, this has to be the greatest expression of envy in all of programming language lore.
No, it just means you can't avoid the reality and the complexity of the problems you'll be dealing with and you won't be able to tackle them unless you bring in more tools or programming languages, be them visual or special languages invented just for the purpose, or some clever way to use excel sheets and generate code from that, for example.
Or it means that, yes, you can choose the easier language, the more intuitive one instead of the abstract beasts and it all goes well for a while. But eventually you'll have to go past the "they did this and then they did that", past the simple to understand if's and else's of everyday life. Then you'll realize that yes, we need this special extra feature here, this clever way of doing things there and before you know it, you've developed dozens of tools, standards and languages just to make up for the lack of power of your initial language. Or you could have chosen the harder language, harder to learn and wield, that is, and it would have offered you better abstractions, it would have offered you better means to develop your ideas and put them into practice without you needing to invent your own tooling.
That's how I've seen it happen in practice. I've expanded it in this article, but it came the other way round. I had a feeling that all this tooling is actually unnecessary or just the result of having bad tooling to start with. Once I've developed these ideas I've remembered about Greenspun's Tenth Rule that I've read and heard about all these years without quite understanding it 100%. Now I think I do. You have to see it with your own eyes, though. If you read it once and it doesn't make sense, re-reading it probably wouldn't.
I think the article was pretty convincing. Even painfully so as it went through the atrocities people are doing in this particular industry to achieve things that, you're completely right, would be trivial in Lisp.
Unfortunately, most critique you're getting here is coming from people who didn't read the article, as you can see by the lack of comments addressing any specific part of the article.
> as you can see by the lack of comments addressing any specific part of the article
Yes, rightly so! I would have been more than glad to address and discuss any of the points made or tools mentioned in the article but that happiness has been stolen from me by the lack of such comments. You're right.
> I think the article was pretty convincing. Even painfully so as it went through the atrocities people are doing in this particular industry to achieve things that, you're completely right, would be trivial in Lisp.
Yes, some of these tools I've mentioned I've also worked with for years. It has been a few years since I've exited from that industry and now I've tried to bring back the feelings and remember the tools and standards so I've had to do some research. It slowly came back. But I did discover some new tools and languages that I haven't used so the horror was even greater than what I've remembered and then I couldn't stop digging for more. Good observation.
Agree 100%. I have never seen the rule to be true in my 30+ year career. And I routinely work on million+ line C++ applications running large international businesses.
BTW, for anyone interested in learning more about Lisp macros, Paul Graham's book about advanced Lisp programming, On Lisp, covers the topic pretty extensively and it's freely downloadable from his website:
And then LoL: https://letoverlambda.com/
I started to read the book years ago but it was too wild for me. I should give it another try. One of the so many things I have to read.
So how would we go about switching the entire software industry to use LISP more? I've been struggling with this idea for awhile. It seems that the best languages don't get adopted.
The only consistent explanation I've seen that it is about 'easy'. The other languages have tools to make them easy, easy IDE's, the languages 'solve' one 'thing' and using them for that 'one thing' is easier to than building your own in LISP.
You can do anything with LISP, sure, but there is a learning curve, lot of 'ways of thinking' to adopt the brain to in order to solve problems.
Personally, I do wish we could somehow re-vamp the CS Education system to focus on LISP and other ML languages, and train more for the thinking process, not just how to connect up some Java Libraries.
That is, other programming languages have adopted many of the features of Lisp that made Lisp special such as garbage collection (Rustifarians are learning the hard way that garbage collection is the most important feature for building programs out of reusable modules), facile data structures (like the scalar, list, dict trinity), higher order functions, dynamic typing, REPL, etc.
People struggled to specify programming languages up until 1990 or so, some standards were successful such as FORTRAN but COBOL was a hot mess that people filed lawsuits over it, PL/I a failure, etc. C was a clear example of "worse is better" with some kind of topological defect in the design such that there's a circularity in the K&R book that makes it confusing if you read it all the way through. Ada was a heroic attempt to write a great language spec but people didn't want it.
I see the Common Lisp spec as the first modern language spec written by adults which inspired the Java spec and the Python spec and pretty much all languages developed afterwards. Pedants will consistently deny that the spec is influenced by the implementation but that's absolutely silly: modern specifications are successful because somebody thinks through questions like "How do we make a Lisp that's going to perform well on the upcoming generation of 32 bit processors?"
In 1980 you had a choice of Lisp, BASIC, PASCAL, FORTRAN, FORTH, etc. C wound up taking PL/I's place. The gap between (say) Python and Lisp is much smaller than the gap between C and Lisp. I wouldn't feel that I could do the macro-heavy stuff in
Other languages and environments have captured much of what Lisp has offered forever, but not S-expr, and, less so, not macros.
Any argument one has against Lisp is answered by modern implementations. But, specifically, by Clojure. Modern, fast, "works with everything", "lots of libraries", the JVM "lifts all boats", including Clojure.
But despite all that, it's still S-expr based, and its still a niche "geek" language. A popular one, for its space, but niche. It's not mainstream.
Folks have been pivoting away from S-expr all the way back to Dylan.
I'm a Lisp guy, I like Lisp, and by Lisp I mean Common Lisp. But I like CLOS more than macros, specifically mulithmethod dispatch. I'd rather have CLOS in a language than macros.
I don't hate S-expr, but I think their value diminishes rather quickly if you don't have macros. Most languages have structured static data now, which is another plus of S-expr.
I don't use many macros in my Lisp code. Mostly convenience methods (like (with-<some-scope> scope <body>)), things like that). Real obvious boiler plate stuff. Everyone else would just wrap a lambda, but that's not so much the Common Lisp way.
In my Not Lisp work, I don't really miss macros.
Anyway, S-expr hinder adoption. It's had all the time in the world to "break through", and it hasn't. "Wisdom of the crowds" says nay.
What did win is the scalar/list/dict trinity which I first saw clearly articulated in Perl but is core to dynamic langauges like Python and Javascript and in the stdlib and used heavily in almost every static language except for the one that puts the C in Cthulu.
I think you're absolutely right about macros being the main thing that makes s-expressions valuable, but allow me to inject my own opinion to drive it all the way home:
It's not that the homoiconicity of S-expressions makes it easier to write macros. Plenty of infix expression languages have macros that let you manipulate ASTs. We're programmers; mapping from lexical syntax to an AST is not hard for us.
What makes s-expressions so great in macro-heavy code is that the simplicity and regularity of the syntax lets you create DSLs without having to fuss with defining your own syntax extensions or figuring out how to integrate it into the "parent" language in a way that isn't completely terrible.
Racket demonstrates this rather nicely. They've got a fantastic system for creating macros that let you define your own syntax. It really does work well. But I'd generally rather not use it if I don't have to, because if I do then the job instantly gets 10x bigger because now I have to write a parser plus all the extensions to make sure it won't break syntax highlighting, ensure parse errors are indicated nicely in the editor, etc. And also all that work will be tightly coupled to DrRacket; people who prefer a different editor will not get a good editing experience if they use my macro.
I can avoid all of that headache if I just let it be s-expressions from top to bottom.
This is kind of backwards. Languages which imitate everything from the Lisp family except S-exprs and macros are, because of that, other languages. Those that have S-exprs and macros are identified as in the Lisp family.
The appearance of new languages like this has not stopped.
This is kind of a no true Scotsman argument. The point is that most of the key ideas of lisp have been enthusiastically adopted by many very popular languages but lisp itself remains a small niche.
A language that enthusiastically adopts all key ideas is identified as a Lisp.
There aren't "many" popular languages; only a fairly small number. The vast majority of languages are destined for unpopularity, regardless of what they copy from where.
You'll need to say what this "lisp" and the "lisp features" are.
When we go back to the original idea of LISP, we have the following things:
idea -> what follows from those
1) programming with Symbolic Expressions -> support the implementation/implementation of languages
2) "programming with Symbolic Expressions" applied to itself -> Lisp in itself, code as data, macros, self-hosting compiler, Lisp interpreter
3) linked lists and symbols as data structures for Symbolic Expressions
4) a programming system to build algorithms and programs based on the ideas of above -> symbols repository, late binding, recursive functions, symbols with properties, garbage collection, Lisp interpreter using s-expressions, Lisp compiler, reader, printer, read-eval-print-loop, a resident development environment, managed memory, saving/loading heap dumps, dynamic data structures,...
LISP means "List Processor" (not "List Processing"). Which indicates that this is at its core, not a library or an add on.
There aren't that many other languages which are based on these ideas.
We can define three levels of "feature adoption":
* enables a feature (the language provides mechanisms to provide a feature)
* supports a feature (the language actually includes those features, but use is optional)
* requires a feature (the language requires the use of that feature, its not optional for the developer)
If we use a programming system, which requires the four core ideas above (and many of the features that follow from those) and is based on them, it is still very (!) different to what most people use.
Example:
Smalltalk development was started more than a decade after LISP. It adopted a huge amount of features from Lisp: managed memory, resident development environment, garbage collection, late binding, interactive use, runtime evaluation, dumping&loading heaps, etc. etc. For a decade Xerox PARC developed a Smalltalk system and a Lisp system side-by side: Smalltalk 80 systems and Interlisp-D systems were the results.
Still: Smalltalk 80 did not use the first three core ideas from above and replaced them with another core idea: objects+classes communicating via message passing.
Thus mass feature adoption alone does not make Smalltalk fundamentally to be a LISP. Nor does feature adoption make a language popular.
So we can ask use, will those core ideas of Lisp make it very popular? Seems like it did not. Still many of the useful features which were following from it could be replicated/adopted/morphed into other languages.
The original article was probably taking a view that a language&programming system which enables domain specific embedded languages would be "better" than the diverse stack of tools and languages in the automotive domain. Lisp is such a tool for embedded languages (embedded into a hosting language, not in the sense of languages for embedded systems), but that does not make it the best for that domain, which has a lot more requirements than language embedding (like reliability, robustness, etc. ...). In Germany A-SPICE gives a lot of hints what a development process needs to do, to deliver reliable software for the automotive domain. I don't think Lisp would fit well into such a development process.
As much as it sucked, BASIC had an important place as a dynamic language as early as 1963 at Dartmouth. GOTO wasn't all that different from a JMP in assembly.
BASIC was mature as a teaching language that you could run on a minicomputer by the early-1970s (see https://en.wikipedia.org/wiki/RSTS/E) and it came to dominate the market because there were implementations like Tiny BASIC and Microsoft BASIC that would run in machines with 4K of RAM.
There was endless handwringing at the time that we were exposing beginners to a language that would teach them terrible habits but the alternatives weren't great: it was a struggle to fit a PASCAL (or FORTRAN or COBOL or ...) compiler into a 64k address space (often using virtual machine techniques like UCSD Pascal which led to terrible performance) FORTH was a reasonable alternative but never got appeal beyond enthusiasts.
There was a lot of hope among pedagogues that we'd switch to LOGO which was more LISP-like in many ways and you could buy LOGO interpreters for everything from the TI-99/4A and TRS-80 Color Computer to the Apple ][. There was also µLISP which was available on some architectures but again wasn't that popular. For serious coding, assembly language was popular.
In the larger computer space there were a lot of languages like APL and SNOBOL early on that were dynamic too.
I cut my teeth on BBC BASIC with the occasional inline arm2 assembly block on an Acorn Archimedes A310.
It had its limitations, but it damn well worked and you could have total control of the machine if you needed it.
(also the Acorn Archimedes manual was about 40% "how to use the gui" and 60% a complete introduction and reference for BBC BASIC, which definitely helped; I had to buy a book to get an explanation of the ASM side of things but, I mean, fair enough)
Then again the second time I fell in love with a programming language was perl5 so I am perhaps an outlier here.
> C was a clear example of "worse is better" with some kind of topological defect in the design such that there's a circularity in the K&R book that makes it confusing if you read it all the way through.
Whaaaaat???
I read the K&R book (rev 1) all the way through. The only thing I found confusing (without a compiler to experiment wiht) was argc and argv. Other than that, I found it very clear.
>C was a clear example of "worse is better" with some kind of topological defect in the design such that there's a circularity in the K&R book that makes it confusing if you read it all the way through.
Aww you can't just leave us hanging like this. What's the paradox?
I've often thought Sun and Solaris also won, since so much of Linux is open source reimaginings of what Solaris had in the mid-late 90s, essentially a few year head start on Linux (which i used in the early 90s and still do, but along with Solaris back then, and NeXTstep).
20 years back I remember chatting to a sysadmin over beer and the conversation included "Linux mostly does either whatever Solaris does or whatever BSD does, you just have to check which it is before trying to write anything."
(this was not a complaint, we were both veterans of the "How Many UNICES?!?!?!" era)
Imo the issue is undergrad cs programs have an identity crisis.
Are they the entry into the world of computer science. Should they teach set theory, computer organization, language theory, etc.
OR
are they trying to prepare the new wave of workers. Should they teach protocols like http, industry tools like Java and python, and good test practices?
A well rounded engineer should have a grasp on it all, but with only 4 years, what will attract more funding and more students?
I've been advocating for years that CS departments need to bifurcate. Actual CS classes, the theory-heavy kind, need to be reabsorbed into math departments. People who want to study computer science academically would be better served by getting a math degree. The "how to write software" courses need be absorbed into engineering departments, and maybe the extra discipline gains from actual engineers teaching these courses can start turning software engineers from computer programmers with an inflated job title into actual engineers.
Students can then make a choice. Do I get a degree in computer science and be better prepared for academia, essentially being a mathematician who specializes in computation? Or do I get a degree in computer engineering and be better prepared to write reliable software in industry?
Of course this distinction exists today, and some universities do offer separate CS and CE degrees, but in practice it seems more often to be smashed together into a catch-all CS degree that may or may not be more theory or practice focused depending on the program.
First, "computer engineering" is already a name for an established discipline. And regarding academic computer scientists, a significant amount of them are on the "systems" side; it would be inaccurate to call their work a specialization of math.
At my university, "computer science" and "computer engineering" were under different departments, and the latter focused less on algorithms and more on embedded digital hardware.
That's still the case for a lot of CS programs. At least mine is still part of the maths department. We also had a distinction between CS and Software engineering, and even between normal CS and a hybrid program between CS and Software engineering.
Just to add another angle to this: of course you can have CS classes and all that good stuff, but would the businesses only employ these kind of graduates? Or would they spread even thinner to grab market share or increase profits and hire non-experts as a result, for which "easy" and intuitive tools have to be developed and employed? I mean, I see this problem with abstraction, maths, compilers, Lisp, etc, you know, the fundamental stuff. That is, the deeper you go it will become that much harder to find people willing or able to dive deep. So eventually you run out of manpower and that what? Use these "intuitive" tools, probably.
I mean, this is already a thing today. Programmers who can hack together a CRUD app in <insert popular web dev stack> are a dime a dozen. People who know more about compilers than "oh yeah I got a C in that class" are pretty hard to find.
At some point businesses who need "deep experts" have to hire non-experts and invest in training them. This is what I have seen in practice. You don't use the "intuitive" tools, you hire people who are willing to learn and teach them the other tools.
20 years ago I found CS students at my Uni usually didn't know how to do version control, use an issue tracker, etc. Today they all use Github.
Remember computer science professors and grad students get ahead in their careers by writing papers not by writing programs. You do find some great programmers, but you also find a lot of awful code. There was the time that a well-known ML professor emailed me a C program which crashed before it got into main() and it was because the program allocated a 4GB array that it never used. He could get away with it because he had a 64 bit machine but I will still on 32 bits.
Early in grad school for physics I had a job developing Java applets for education and got invited to a CS conference in Syracuse where I did a live demo. None of the computer scientists had a working demo and I was told I was very brave to have one.
When I was a student in Crete, the nearby CSD was a gorgeous example of doing both competently. They had rigorous theory courses (like mandatory DS, Algos, logic, compilers etc) as well as hardcore applied stuff.
Side-knowledge like source control, Unix systems and utilities, editors/IDEs were supposed to be picked by students themselves with the help of lab TAs, because assignments were to be delivered over ssh through specific channels etc. Sometimes, the quirky teacher would not give precise instructions for certain projects, but tell the students to find the documentation in the departmental network directories for the class and decrypt them with their ID numbers. So the students would go on to crawl the unix and windows nodes for the relevant info.
A "good" (7.5+/10) graduate from the CSD of the University of Crete could do rigorous algorithmic analysis, hack system stuff in C and time in Verilog. OOP was hot at the time, so it also meant students were expected to produce significant amounts of code in Java and C++. Specializations abounded: networks and OSs, theory, arithmetic and analysis, hardware (including VLSI etc. at the undergraduate level, with labs). I won't even go into the graduate stuff.
And although this curriculum was quite demanding and onerous (the number of projects in each class was quite crazy), it was just something students dealt with. Heck, this was not even the most famous CS school in Greece: the elite hackers mostly went to the National Technical University of Athens.
I am not sure what the situation is now, but at least at the time, graduates were ready both for academic and serious industry careers. It is a 4 year curriculum, though many if not most students went on for 5 or 6 years. Of course, free.
In my traditional-engineering education, we spent a ton of time on the basic science and theory, with a super broad overview of actual methods used in practice.
The expectation was that you graduate and you're then equipped to go to a company and start learning to be an engineer that does some specific thing, and you're just barely useful enough to justify getting paid.
IMHO, it is University-level vs College (vocational college) difference.
Industry should not require University-level training from workers. Academy should.
Plumber or electrician don't need university degree, only professional training till you design whole sewer system or power grid for city.
So, yes, bifurcate CS to science and trade. And fight requirements for Bachelor/Major degree in jobs offerings.
> Industry should not require University-level training from workers.
> Plumber or electrician don't need university degree, only professional training [...]
Oh come on, this is ridiculous.
Sure you might be able to do good programming without a college degree.
The typical student? I give them very little chance.
Here's what I think you would see:
* Students trapped in small skill-set jobs, struggling to branch out.
* Poor ability to manage complexity. The larger the system, the worse an ad-hoc job is going to be.
* Lack of awareness of how much tools can help. "Make impossible states not representable?" Write a DSL with a type system so another department stops making so many errors?
* Even more incompetence. Had to learn to recognize an O(N^2) algorithm on the job, but you didn't even know what asymptotic complexity was? People are going to end up believing ridiculous cargo cult things like "two nested loops = slow".
* Less rigorous thinking. Do you think they're even going to be able to pick up recursion? Have you watched a beginner try to understand something like mergesort or quicksort? Imagine that they never had a class where they programmed recursively. Is depth first search taught on the job? Sure, but... how deeply.
* Even less innovation. Who is going to be making the decisions about how to manage state? Would you ever see ideas like Effect?
I'm not saying that a university education is a cure-all, or that it is essential to the jobs that many of us do. I AM saying that if you look at the level of complexity of the work we do, it's obvious (to me) that there is something to study and something to gain from the study.
On one end, if you get good fundamentals, you'll understand the practical side too.
On the other end, most of engineering knowledge is from experience.
Switching undergrad courses to be about understanding THE DOM so we can drive browsers to render our printed-paper skeuomorphs isn't going to drive any kind of innovation. It's not going to put you in a good position to generalise to other work.
Furthermore, if you aspire to centering divs and tweaking webpack, you don't need a CS course for that.
Idk if lisp is the perfect language to teach, but the choice in language absolutely flavors a student's understanding of computing, especially early on.
I think “lighter” languages with fewer built in abstractions would allow students to better understand the theoretical backing of what they’re doing.
Like what’s the difference between and class and a closure?
It doesn’t really matter for the practical day to day work, but certainly does to compiler designers and programming language theory folks.
You wouldn’t really get a sense for that in Java or python, but you might in a lisp or maybe js.
> So how would we go about switching the entire software industry to use LISP more?
There are two answers to this, depending on how broadly you interpret the "Lisp" part of the question. The fundamentalist, and worse, answer is simply: you don't. The objections to Lisp are not mere surface-level syntactic quibbles, it's deeper than that. But also, the syntax is a barrier to adoption. Some people think in S-expressions quite naturally, I personally find them pleasant if a bit strange. But the majority simply do not. Let's not downplay the actual success of Common Lisp, Scheme, and particularly Clojure, all of them are actively used. But you've got your work cut out for you trying to get broader adoption for any of those, teams which want to be using them, are.
The better, more liberal answer, is: use Julia! The language is consciously placed in the Lisp family in the broader sense, it resembles Dylan more than any other language. Critically, it has first-class macros, which one might argue are less eloquent than macros in Common Lisp, but which are equally expressive.
It also has multiple dispatch, and is a JIT-compiled LLVM language, meaning that type-stable Julia code is as fast as a dynamic language can be, genuinely competitive with C++ for CPU-bound numeric computation.
Perhaps most important, it's simply a pleasure to work with. The language is typecast into a role in scientific computing, and the library ecosystem does reflect that, but the language itself is well suited to general server-side programming, and library support is a chicken-and-egg thing: if more people start choosing Julia over, say, Go, then it will naturally grow more libraries for those applications over time.
Elixir feels like that as well (in the same broader sense).
Their trick of 'use' being require+import (ala perl) becomes brilliant when you realise import can be a macro, and that's how libraries inject things into your current namespace.
Julia looks beautiful but I keep forgetting to play with it. I'd use the startup time as an excuse, but it really is just 'I keep forgetting' if I'm honest.
* Scheme is just too fragmented and lacking in arguments to seduce the current industry; its macros are unintuitive, continuations are hard to reason with (https://okmij.org/ftp/continuations/against-callcc.html), small stdlib, no concept of static typing, etc...
* CL is old, unfashionable and full of scary warts (function names, eq/eql/equal/equalp, etc...), and its typing story is also pretty janky even if better than the others (no recursive deftype meaning you can't statically type lists/trees, no parametric deftype, the only one you'll get is array). Few people value having such a solid ANSI standard when it doesn't include modern stuff like iterators/extensible sequences, regexps or threads/atomics.
* Clojure is the most likely to succeed, but the word Java scares a lot of people (for both good and bad reasons) in my experience. As does the "FP means immutable data structs" ML cult. And its current state for static typing is pretty dire, from what I understand.
All of these also don't work that well with VSCode and other popular IDEs (unless stuff like Alive and Calva has gotten way better and less dead than I remember, but even then, SLIME isn't the same as LSP). So, basically, that and static typing having a huge mindshare in the programming world.
I agree with your comment for the most part (particularly the IDE situation)
I do want to callout that while Racket started off from Scheme (and still maintains compatibility with a bunch of it), it should be considered a different platform at this point and solves a bunch of the problems you called out with Scheme - macros are apparently much better, continuations are usually delimited, has user-mode threads and generators, so you very rarely need to reach for raw continuations, a very nice concurrency system, large stdlib, and Typed Racket also adds static typing.
The DrRacket/SLIME experience is great for smaller projects. I do agree that the language server needs more love.
However I still think it gets a lot of stuff right, and is much faster than Python/Ruby due to being powered by Chez Scheme.
The link is an argument against call/cc, not continuations themselves.
That entire website is an exploration into the shift/reset paradigm of delimited continuations, and explores in detail why continuations are incredibly useful and powerful idioms to build all sorts of control structures.
Thank you so much for the info! I am mostly interested in CL.
>Few people value having such a solid ANSI standard when it doesn't include modern stuff like iterators/extensible sequences, regexps or threads/atomics.
For everyone: are there plans to include such topics in the Standard, or are there canonical extensions that people are using?
There is little chance the Standard is gonna get updated again, especially since CDR (the Common Lisp Directory Repository) kinda stopped. That said there are a few libraries that are kinda considered to be the default go-tos for various needs:
CL-PPCRE for regular expressions.
Bordeaux-threads for threads.
Alexandria for various miscellaneous stuff.
Trivia for pattern matching.
CFFI for, well, FFI.
And Series for functional iterative sequence-like data structures.
There's also ASDF and UIOP, but I'm not sure whether or not they're part of the Standard.
Too bad cl-ppcre is extremely slow in my experience, but that's what we have.
ASDF and UIOP are the same as the rest, de facto standards, but not ANSI nor CLtL.
Truly, someone could tie himself to SBCL and its extensions and get a much more modern environment, but I think it's worth targeting ECL and CCL in addition.
ASDF is one of the symptoms of what is wrong about CL. You have this thing that is not really sure whether it is image based or source based and has a bunch of global state while reading the source. Solution to that is ASDF, which is a ridiculously hairy and complex thing.
Lisp is too powerful and flexible. That's an advantage and a disadvantage.
On the one hand, you can use that power to write elegant programs with great abstractions.
One the other hand it's really really easy to create unmaintainable messes full of ad-hoc macros that no-one, not even you next month, will be able to understand.
Even if the program is well-written, it can be a really steep learning curve for junior hires unless it's very well documented and there's support from the original writers available.
Compare it to other languages that limit your ability to express yourself while writing code.
The truth is that most programs are not really interesting and having a code base that can be hacked-on easily by any random programmer that you can hire is a really valuable proposition from the business point of view, and using less powerful languages is a good way to prevent non-experts from making a mess.
There was a great episode of Type Theory for All with Conal Elliot as a guest where he decried MITs decision to switch to teaching Python instead of Scheme for introductory programming. He makes a very good case for how CS education should be aiming to pursue the greatest truths and not just equipping people with whatever employers want.
Not calling it LISP would help. And though you get used to it and even kind of appreciate it sometimes, the default behavior of most Common Lisp implementations to SHOUT its symbols at you is rather unfortunate.
Go back to 2005 and look at how 'easy' Python, Perl, PHP, Ruby, JavaScript, C++, and Java were. Look at them today. Why has their popularity hierarchy not remained the same? How about vs. Lisp then and now (or even Clojure later)? You'll find answers that explain Lisp's current popularity (which isn't all that bad) better than anything to do with initial or eventual easiness.
> The only consistent explanation I've seen that it is about 'easy'. The other languages have tools to make them easy, easy IDE's, the languages 'solve' one 'thing' and using them for that 'one thing' is easier to than building your own in LISP.
I have thought something similar, perhaps with a bit more emphasis on network effects and initial luck of popularity, but the same idea. Then about a week ago, I was one of the lucky 10,000[0] that learned about The Lisp Curse[1]. It's as old as the hills, but I hadn't come across anything like it before. I think it better explains the reason "the best languages don't get adopted" than the above.
The TL;DR is with unconstrained coding power comes dispersion. This dilutes solutions across equally optimal candidates instead of consolidation on a single (arbitrary) optimal solution.
I'd say you were unlucky, because it's a rather terrible essay and doesn't actually get the diagnosis correct at all; indeed if some of its claims were true, you'd think they would apply just as well to other more popular languages, or rule out existing Lisp systems comprised of millions of lines of code with large teams. The author never even participated in Lisp, and is ignorant of most of Lisp history. I wish it'd stop being circulated.
> Replacing Lisp's beautiful parentheses with dozens of special tools and languages, none powerful enough to conquer the whole software landscape, leads to fragmentation and extra effort from everyone, vendors and developers alike. The automotive field is a case in point.
This has been a struggle of mine since day one. Coming from the java world with more formats, tools, IDEs everytime people create a problem was absurd. Lisp was all absorbing.. much reuse on all metalevels.. yet sometimes I believe a bit of "organ"ism is useful.
The book Beautiful Racket is the best defense of macros out there, on "show, don't tell" grounds. Also, it's just so well-written and describes such an interesting set of tools that I'd argue it's worth a skim even if you don't intend to learn the language.
Macros allow you to bring highly tailored DSLs into your code base. You can practice language oriented programming.
It's seductive, but there's a steep cost. You bring in a bunch of new notation, which you have to learn and teach and remember. You have to consider all the interactions that happen when you mix notations. You have to implement all the tooling.
Usually what happens is you don't quite remember what things mean after a while, and you have to study it again. You didn't consider all the interactions, so it isn't that well behaved. And you never got around to implement quality tooling - and there's no obvious place to plug that tooling in, either. And then it turns out that the notation wasn't quite right for implementing the changing requirements of the business.
IMO, someone should kill XCP and A2L. They are in effect, a semihosted debugger. I would rather have semihosted gdb and use .elf. The tooling around A2L is horrendous.
I am not a fan of Lisp. However I sure wish all command line tools would use the same Lisp dialect for scripting. Instead of each Linux tool inventing their own awful, badly documented, makes-you-want-to-vomit bad joke of a scripting language.
Macros are more abstract, one meta level up, hence errors are more difficult to relate to code and reason about. They are also more powerful, so errors can have dramatic consequences.
Any kind of code generation setup will have the same characteristics.
Sloppy macros clashing with local names can lead to pretty long debug sessions, but it's the first thing you learn to avoid.
And you're basically inventing your own ad hoc programming language to some extent, the effort spent on error handling tend to not live up to those requirements.
All of that being said, I wouldn't trade them for anything, and I haven't seen any convincing alternatives to Lisp for the full experience.
With care to make the build step "ergonomic", I prefer working with code generation than with macros. Everything about macros is "cleverer" than code generation:
* Implementation of macros require clever algorithms [1] where code generation is mostly straightforward.
* It is harder for IDE's (and most importantly, humans!) to make use of the code because it is not trivial to determine the end result of a macro ("run the code in your head" kind of situation).
There are features that a language can adopt to make it even easier to benefit from code generation, like partial classes [2] and extension methods [3]. Again, these things are a lot more straightforward for both humans and IDEs to understand and work with.
In general, if the macro can't be evaluated to determine its effect, It's not a good macro system. One of the things I like about lisp macros is that you can just apply them to a chunk of code and see what the result would be. Contrast C++ templates, where good luck figuring out either how template application will work or what functions you are actually bind when calling templated code.
When you write macros, you're working one meta level up, since you're writing code that generates code (that generates code etc, but one level higher than usual).
From a user perspective it's different. Macros are more limited; not first class and can't be passed around and called like functions.
If we're talking LISP, I believe "if" is a form, not a macro (because it breaks evaluation rules by only evaluating one branch or the other at runtime depending on the evaluation of the conditional).
In fact, MacCarthy invented a multi-branch conditional construct which in M-expressions looked like
[test1 -> value1; test2 -> value2; T -> default]
The S-expression form was cond:
(cond (test1 value1) (test2 value2) (T default))
The if macro came later, defined in terms of cond.
Macros are no operationally distinguishable from special operators. You know that a form is a macro because there is a binding for the symbol as a macro, and you can ask for the expansion.
Because macros expand to code that may contain special forms that control evaluation, macros thereby exhibit control over evaluation.
It has to be a macro to allow passing the branches as arguments without both being unconditionally evaluated, otherwise you'd have to use lambdas like Smalltalk or lazy eval a la Haskell.
I am not reading 10,000+ words on why macros are good. I know macros are good because smart people tell me they are. There is also plentiful evidence of macros being useful to programmers. Who are you trying to convince here?
I am writing for myself. I've also worked in the automotive industry as a consultant for a few years and I've seen the effects of these extra tools I'm mentioning in the article on me and my colleagues and the industry as a whole. I've gathered all the observations in one place. It has been a nice experience for me writing it, it has cleared up some ideas, brought to life new ones, as it always happens when you think you see something very clearly only to change your opinion and see new angles once you put it in words or once you try to articulate it.
I am glad if it's useful to others as what others write and wrote over the years, including about Lisp, was useful to me. It's just free food, if you will. They've charged nothing for it, even if they worked for years on producing it, I'm grateful for that and now I'm returning the favor. If it's good food or not, I can't say. If you don't like it, leave it to others, no harm in that.
> Replacing Lisp's beautiful parentheses with dozens of special tools and languages, none powerful enough to conquer the whole software landscape, leads to fragmentation and extra effort from everyone, vendors and developers alike. The automotive field is a case in point.
Haskell is a niche language, not widely used in any industry, and it has nothing like the power and tooling of Lisp. What would be its place in this discussion?
Macros are one of the widely touted superpowers of lisp. And yet in Clojure, which is the most widely used dialect in modern use, it is idiomatic to avoid macros as much as possible. None of the claimed advantages really hold up under scrutiny.
"Don't use a macro unless you need to" is good advice, but when you -do- need to, having macros around is lovely.
Yes, you can achieve the same thing by typing out what would've been the expansion yourself, but in cases where macros are a good idea the expansion would've been sufficiently prone to mistakes when tweaking it that maintaining the macro is an improvement.
> it is idiomatic to avoid macros as much as possible.
Of course, don't use a macro if you don't need one. But when you do hit a case where you need one, it's better than using/writing external tooling to solve the problem.
> None of the claimed advantages really hold up under scrutiny.
Same in all lisps. The advantages of having macros vary on a case-by-case basis, but one thing is quite sure: the number of programmers collaborating on a project is inversely proportional to how much you should use macros. For a solo dev, especially when doing science-y stuff, they're invaluable.
That's only true of macros created for the purpose of reducing boilerplate code. However, the best macros actually reduce errors and improve code quality by enforcing invariants more than can be done without macros.
> "I don't think this is truly realized, but all this information written down in word sheets, requirements, knowledge passed on in meetings, little tricks and short hacks solved in video calls, information passed in emails and instant messaging is information that is part of the project, that is put down in some kind of a language, a non-formal one like English or tables or boxes or scribbles or laughs and jokes. The more a project has of these, the harder it is to talk about and verify the actual state of the project as it is obviously impossible to evaluate a non-formal language like you would a formal programming language and thus it becomes that much harder to explore and play with, test and explore the project."
I've thought all this sloppy side information would be a good target for the currently in vogue AI techniques.
That would only mean we'd add even more tools on top of the tools that currently sit themselves on top of C (in this particular case) to fix our 'sloppy' ways, no?
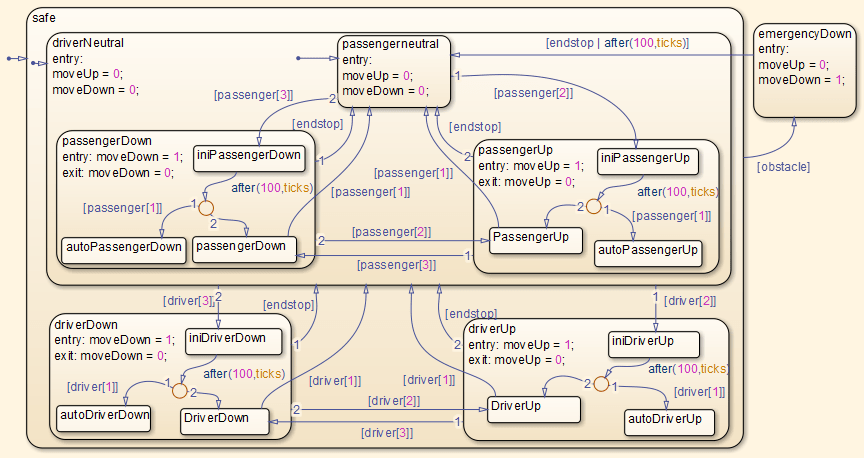{kind=link}
I did a little digging, and it turns out I had it backwards. It's not that Simulink invented a new graphical programming language to do this stuff. Control systems engineers have been studying and documenting systems using Simulink-style block diagrams since at least the 1960s. Simulink just took something that used to be a paper and chalkboard modeling tool and made it executable on a computer.