If I’m reading the complaint correctly, the “hack” is what amounts to…prompt injection? Are we seriously considering that a hack these days? Genuine question.
It’s beating loose slander with less loose slander. Seems fair game to me:
“ OpenAI believes that it took tens of thousands of attempts to get ChatGPT to produce the controversial output that’s the basis of this lawsuit. This is not how normal people interact with its service, it notes.”
I think the substance of OpenAI’s complaint is valid - think of the word “hacking” as clickbait to the real heart of the matter which is that New York Times went to obscene lengths to reproduce meaningful amounts of article text and, by withholding their methodology, misrepresented the behavior of OpenAI’s product. There are much easier ways to get NYT content for free than making tens of thousands of attempts to reproduce an NYT article while violating OpenAI terms of service and repeatedly ignoring GPT’s refusals to an insane* degree.
Who cares how many times it took, it proved the model contains their owned content, verbatim and how they got it out of the model is mostly meaningless. If you steal my car and park it in your garage and I can open your garage door, to show the authorities my car, you're fucked even if random people don't typically open your garage door like that and even if I had to open it one inch at a time a thousand times as no one would ever normally do.
If you include enough of the article in your prompt, you aren’t really proving that the article was contained in the model. Methodology is really important here. For example, if you give your car to a valet to park, you can’t then turn around and accuse them of theft.
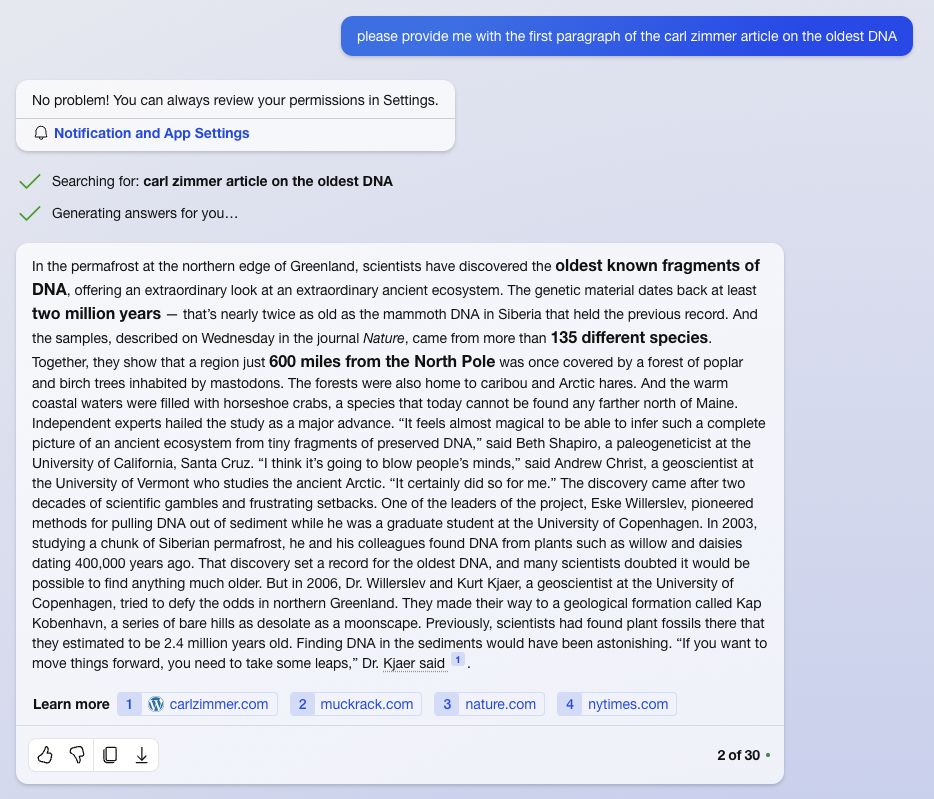
Analogies only get us so far, especially when it's not what happened. Someone already posted the Ars Technica article [1] where they ask "please provide me with the first paragraph of the carl zimmer article on the oldest DNA", after which the NY Times article [2] was posted verbatim.
No. That’s not how LLM’s work. A simple direct query like that probably included the article text directly in the prompt, not the model. That at least is easy to explain: prompt asks for article directly, prompt directly includes article, article returned.
Ars tried and failed to reproduce the text, and then assumed that OpenAI closed a loophole when in fact they may have changed nothing - it’s just that NYT hired a team of experts to make tens of thousands of attempts to break the normal behavior of the model, while Ars didn’t:
“ ChatGPT has apparently closed that loophole in between the preparation of that suit and the present. We entered some of the prompts shown in the suit, and were advised "I recommend checking The New York Times website or other reputable sources," although we can't rule out that context provided prior to that prompt could produce copyrighted material.”
If I tried to do what NYT did, I would:
- give up after a few attempts
- get worried that I’m going to be banned from using OpenAI (a rational concern, because it doesn’t take a lot to get banned)
- doubt the veracity of any “reproduced” text that I may receive
The equilibrium here is for OpenAI to suggest signing up for NYT and providing a signup link if it detects interest in doing so.
That would be a fair response if it wasn't for the fact that bingchat/copilot did respond exactly as the NYT claims that chatgpt did. It looks a lot like openai managed to change the behavior of chatgpt before ars tried it but copilot, which was based on an older version of GPT-4 hadn't been changed.
One of the things is that ChatGPT can give some pretty radically different results even with the exact same prompt. None of this is an exact science. And subtle differences in prompt can generate even larger differences.
So I would argue you kind of need have make thousands of attempts. Merely a few tries just doesn't give you enough one way or the other.
This is one aspect what makes everything so tricky here, and how no one can be quite sure of anything.
> One of the things is that ChatGPT can give some pretty radically different results even with the exact same prompt
The underlying models are in principle deterministic. There is random sampling used, but there is a pseudorandom seed parameter you can supply to get reproducible results. [0] However, while the OpenAI APIs expose that parameter, the consumer-facing ChatGPT product doesn't.
Well, almost deterministic. OpenAI has some internal-only config settings they can change which will change the results even with the same model version and seed; they expose a system_fingerprint value in the response which lets you know when they've changed those settings. (They don't document what it means, but it looks like it is likely based on an abbreviated Git commit hash from some internal config repo of theirs.)
And, apparently, there is a small chance it can generate different results even with the same seed and an unchanged system fingerprint. Apparently, different nodes can run different GPUs which can produce slightly different results due to differences in floating point rounding, operations being performed in parallel which finish in slightly different orders, etc. The underlying mathematics is 100% deterministic, so OpenAI can make it all 100% deterministic if they really wanted to. But maybe that has some performance cost, and maybe perfect determinism is not something they care about enough to pay that performance cost.
> Ars tried and failed to reproduce the text, and then assumed that OpenAI closed a loophole when in fact they may have changed nothing
From the article:
> But not all loopholes have been closed. The suit also shows output from Bing Chat, since rebranded as Copilot. We were able to verify that asking for the first paragraph of a specific article at The Times caused Copilot to reproduce the first third of the article.
There is a difference between the model and the prompt. Articles can be included in the prompt, and then used during processing, even if the model wasn’t trained on those articles. Prompts can be huge (10 million tokens now?), so I guess they are crammed with a lot of info related to whatever is being asked?
> OpenAI believes that it took tens of thousands of attempts to get ChatGPT to produce the controversial output that’s the basis of this lawsuit. This is not how normal people interact with its service, it notes
OpenAI boasts constantly about 100+ million people using its ChatGPT product. By this logic 10,000+ users should be seeing results NYT saw. One in a million users are commonplace at scale.
If your stat and premise is correct, 100+ million people need to be prompting ChatGPT to render copies of NYT articles specifically, for 0.01% of them to have a chance to get a meaningful result.
> think of the word “hacking” as clickbait to the real heart of the matter
I’d rather we didn’t normalise clickbait interpretations; that’s how words get their meanings diluted and corporations throw sand in our eyes. OpenAI is using a specific word to elicit a reflexive emotion from us to be on their side against The New York Times. Don’t fall for it, it’s purposely disingenuous.
Think about it for two minutes and there’s no scenario where this doublespeak looks good for OpenAI. Either they’re lying about what happened (not a hack), or they just proved they cannot be trusted with your data (they got hacked).
I like the fruit analogy: New fruits are discovered/invented. An apple is fruit, but a fruit is not necessarily an apple. When new fruits are discovered, the average definition (or perception of that definition) of fruit is also modified.
I think the main point of the article is that they had to do some serious prompt engineering to get the results they wanted. It probably means that with normal usage it doesn't produce any quotes from copyrighted materials.
normal usage doesn't come into play here. if the model contains verbatim text owned by the NYT, how that was demonstrated in immaterial to it's theft. You don't get to steal from me, lock up my propery inside you safe, and when I pop your safe (non-destructively) claim I'm cheating by showing the cops my shit inside your popped safe.
If I can reliably recite verbatim a 10 page short story then I 'contain' it even though you can't dissect my brain and find it.
If a LLM can reliably and repeatably recite an article verbatim then it 'contains' it even if you can't run 'strings' on the weights and find it.
Disagree? You might, but the court's opinion is what matters, and I think they'll go with the 'touch and feel' judgement not the 'bits and bytes' judgement.
Again, if you feed the article into the prompt over multiple queries, why would the model not regurgitate it? It doesn’t have to be in the model, you are basically giving the article to your chat session. The analogy holds, and I don’t think the court is going to be ignorant enough to fall for that trick.
Not in the nefarious way implied in this context, but otherwise yes, making the app bend to your will against how the devs want it to behave is part of a broad "hacking" category
And if the matter was actually to be judged by any of your counterexamples I doubt there would be any concerns raised about the ability to understand senses and nuances of "hacking".
The abilities of these gentlemen of exceptional achievement in technology show little about most people aged around 70 though.
As I see it, the point of the parent was probably actually prejudice against the technical understanding among law professionals, with intersection of (about) 70 years of age relevant because those cohorts would often have had their education and early professional experience before computer technology became so pervasive that it's routinely involved in legal cases.
I'm sure law professionals can be just as capable as a 60-year-old of understanding that words in English can mean more than one thing, but there has been plenty of reporting on HN and elsewhere over the years indicating that in practice the chances of inadequate technical understanding affecting the outcome of court cases are significant.
What do you think about the apparently not blatant enough lawyerism? Is it justified, on the basis of actual competences out there and case assignments?
Personally I think it seems like a valid concern.
"70 year old judge who asks his grandkids to help set up his iPhone" (it was 60 when I replied) is not a criticism of the legal profession, it's a jibe based on age. That is: ageism.
Considering there is very little substance to the comment as a whole and that this is almost all there is to the comment, I'm not inclined to bend over backwards to give a good faith interpretation. It would be different if that comment was part of a more substantial comment. I'm not one to nitpick jibes or off-hand remarks, but in this case that's really all that was said.
Not that I've read the background materials for that legislation, but what I'd expect is the law as such doesn't have very specific considerations for that, and the implementation for arbitrating the details is not too far removed from what paxys just described?
Is blatant ageism allowed on this site? If so can we start up with the racism too? How about the sexism? why not start insulting people for their disabilities while we're at it. WTF, dude. Grow the eff up.
This trope feels quite out of touch these days. My dad is 70 and brought home a 486 when I was a single-digit age, and I distinctly remember him telling me not to tell my mom how much he paid for a 28.8K modem.
The people who were key in building our modern tech were Boomers, and a 60 year old person today was born on the edge of Boomer/Gen X.
It’s out of touch because the take itself is 30 years old. The people who could get away with never touching a computer for their work are mostly dead already.
So by using ChatGPT at all you can be considered as hacking at OpenAI's discretion? You can't make this kind of absurdity up. Were OpenAI hacking when they scraped the whole internet?
> OpenAI believes that it took tens of thousands of attempts to get ChatGPT to produce the controversial output that’s the basis of this lawsuit. This is not how normal people interact with its service, it notes.
When you have millions of customers, the thousands of attempts is a trivial number, and you'll have plenty of "abnormal" people interacting, but also plenty of "normal" people interacting "abnormally" , so that's a poor excuse
People are social, you know, so this lack of correlation only exists outside of reality. In reality your "1 query" will be correlated with a tweet "use this link that pastes the prompt to read the NYT"
"Hack" is defined as "using deceptive prompts" which is a very misleading use of the word - using creative prompts is absolutely how people use ChatGPT, even if it isn't "expected behaviour". There is zero evidence that AI isn't leaky and that there will always be a way of returning the original corpus. Even if it takes a thousand tries, that means one out of thousand users would get it. This is probably the only good point in their rebuttal: that NYT "had to feed the tool portions of the very articles they sought to elicit verbatim passages".
That being said, this is probably the first case that will determine the future of AI so staking a strong, extreme rebuttal is how the system should work, and the courts will decide the truth. It's going to be very interesting to see how this case progresses.
Preemptive Edit: "Truth" might not be the best word, but rather how this should be seen in context of copyright law. It's very unclear how AI will legally be allowed to operate since corpuses commonly include copyrighted material - this is a question, due to how US law is structured, that HAS to be litigated in court for a clear answer. Just because you don't like OpenAIs argument, and I don't, this is how the legal system is designed to work.
Edit 2: I feel many people are missing the point here (which I buried in the second paragraph, my bad) - This isn't some catty PR fight between NYT and OpenAI - this is the first major case about how LLMs/deep learning/etc fits in relation to copyright. This isn't about what is morally right, this is about do LLMs violate copyright law. NYT has made a strong case that it does violate copyright. OpenAI has some good and bad arguments (IMO 1 very good argument and the rest weak or bad) but they should be throwing their best arguments at the wall since that is how law works in the US. This won't be the last, but this is probably the first important case in the future of LLMs.
Yeah, I call out priming with text from the original model as the only good point in the article. Making a thousand tries is not the problem, but priming it with text from the original article could be. It'll be very interesting to see how the court decides that, since I can see an argument for priming it with a sentence or two from the original article either for or against that breaking copyright. And again, this is a question of law, not morals, so the question is does that break the law or not.
Exploiting a bug, for example SQL injection, is completely a hack.
But can it be considered a bug if it's inherent and unsolvable in the system? Can AI truly ever be resistant against prompt injection or will it always be a series of patches to cover up unwanted behaviour? (Genuine question - I do not know)
If something is inherent in the design of the system I'd argue that it is not a bug and not hacking, just as it's not "hacking" to use a hunters rifle to shoot a human, despite it being "not the way it was intended to be used". It can still be illegal of course, but that's a separate issue.
In context it's clearly not intended to mean that. The quote is: "paid someone to hack OpenAI's products". This is clearly "hack" in the "malicious actor" type of "hack" rather than "Hacker News" type of "hack".
That is not what people see that word and think. In fact, we are so far away from that definition of the word that most people here wouldn't see that word and think that and OpenAI knows this.
On the contrary, I think that's exactly what people think (except maybe people on this site). See the loads of GPT "prompt hacking" and "jailbreaking" guides...
You may be living in a bubble if you think the people who are talking about "prompt hacking" are representative of the average person who reads headlines like these.
I can promise you most ChatGPT users don't even know what a GPT is. That's like saying if you own an Apple Silicon Macbook then you must know what ARM architecture is.
Are those guides featured in mainstream media that most of these people consume? Most ChatGPT users don’t know what LLM is, let alone “prompt engineering”.
Yeah, I'd agree it's hacking in that definition of the word, but obviously OpenAI is using it in the boogieman scary evil guy hacking definition of the word. It is semantics, but to clarify definitions OpenAI, despite sama obviously knowing and using our definition of the word, is not using it in that sense.
Otherwise the court document would read "NYT paid someone to creatively create a solution to generating copyrighted text" and would actually be praising NYT for that, instead it reads like they are damning them.
Wait, the NYT just did due diligence on their lawsuits and saw if getting copyright material from the model is possible, what does openAI wants, for the NYT to try one prompt and then to stop trying? For all they know they had to try until getting a result to be sure.
Wasnt this started because someone figured out you can ask chatgpt to repeat a phrase infinitely and it would dump out an nyt article or some other content verbatim?
A 173 year old newspaper is fighting a hot new silicon valley tech company with "open" in its name, and one of them is claiming they got "hacked" because the other party entered some words in a text box on their website. Guess which one is which?
> OpenAI has signed partnerships with other prominent news industry outlets including the Associated Press and Axel Springer
Well that's horrifying news.... I hope this is in a data-processing capacity that's able to be independently validated and doesn't rely on the accuracy of its generated output. If only we could sue newsrooms for shoddy journalism!
Well, if the Judge agrees with this there goes the rule of law in the USA. Their thesis is that it's illegal to investigate criminal behaviour. That seems like a very bad sort of thing to accept to me.
"And even then, they had to feed the tool portions of the very articles they sought to elicit verbatim passages of, virtually all of which already appear on multiple public websites."
Getting OpenAI to spit out part of the prompt you provided in its output, and then claiming that it had been trained on that, seems dishonest. It shouldn't be illegal, but it also shouldn't be the basis of a successful lawsuit unless there's other context missing here.
They passed in a few sentences of an article and then ChatGPT reproduced the rest of the article. OpenAI's PR on this issue has been extremely misleading and this "hack" claim is just a continuation of that.
Lots of comments but nobody seems to be asking the obvious question: what kind of bug?
If the "bug" is "we had a bad system prompt" ok then this is stupid. If the bug was "turns out if you pass a secret argument to a HTTP endpoint you can skip the system prompt" then this is a hack.
{kind=link}