66 threads per core looks more like a barrel processor than anything else. We shouldn’t expect those threads to be very fast, but we can assume that, if the processor has enough work, it should be able to be doing something useful most of the time (rather than waiting for memory).
I don’t know if Intel has the appetite to attempt another barrel processor.
The primary weakness of barrel processors is human; only a handful of people grok how to design codes that really exploit their potential. They look deceptively familiar at a code level, because normal code will run okay, but won’t perform well unless you do things that look extremely odd to someone that has only written code for CPUs. It is a weird type of architecture to design data structures and algorithms for and there isn’t a lot of literature on algorithm design for barrel processors.
I love barrel processors and have designed codes for a few different such architectures, starting with the old Tera systems, and became quite good at it. In the hands of someone that knows what they are doing I believe they can be more computationally efficient than just about any other architecture given a similar silicon budget for general purpose computing. However, the reality is that writing efficient code for a barrel processor requires carrying a much more complex model in your head than the equivalent code on a CPU; the economics favors architectures like CPUs where an average engineer can deliver adequate efficiency. At this point, I’ve given up on the idea that I’ll ever see a mainstream barrel processor, despite their strengths from a pure computational efficiency standpoint.
With the advent of GPU coding and the number of people exposed to it there is a chance that enough people are willing and able to try unfamiliar architectures if it gives them an advantage that this just might be viable now.
Much closer communication lines between the two, thread level guarantees that would be hard to match otherwise. A barrel processor will 'hit' the threads far more frequently on tasks that would be hard to adapt to a GPU (so for instance, more branching).
Though CPU/GPU combinations are slowly moving in that direction anyway. Incidentally, if this sort of thing really interests you: when I was playing around with machine learning my trick to see how efficiently my code was using the GPU was really simple: first I ran a graphics benchmark that maxed out the GPU and measured power consumption. Then I did the same for just the CPU. Afterwards while running my own code I'd compare the ratio between my own code's power draw with the maximum obtained during the benchmarks, this gave a pretty good indication of whether or not I had made some large mistake and showed a nice and steady increase with every optimization step.
Could you not also see an impact to run times? If algorithm A draws 100W and runs in 10 seconds, and algo B draws 200W… shouldn’t it be very much sub 10 seconds to warrant being called a better algorithm?
Not really, it's an apples-to-oranges comparison. If you ran the same distributed algorithm on a single core you wouldn't see the same speed improvements. These chips are ridiculously efficient because they need far fewer gates to accomplish the same purpose if you have programmed to them specifically. Just like you couldn't simulate a GPU for the same power budget on a CPU. The loss of generality is more than made up for by the increase in efficiency. This is very similar in that respect, but with the caveat that a GPU is even more specialized and so even more efficient.
Imagine what kind of performance you could get out of hardware that is task specific. That's why for instance crypto mining went through a very rapid set of iterations: CPU->GPU->ASIC in a matter of a few years with an extremely brief blip of programmable hardware somewhere in there as well (FPGA based miners, approximately 2013).
Any loss of generality will result in efficiency and vice versa, the question is whether or not it is economically feasible and there are different points on that line that have resulted in marketable (and profitable) products. But there are also plenty of wrecks.
1. Thread Switching:
• Hardware Mechanisms: Specific circuitry used for rapid thread context switching.
• Context Preservation: How the state of a thread is saved/restored during switches.
• Overhead: The time and resources required for a thread switch.
2. Memory Latency and Hiding:
• Prefetching Strategies: Techniques to load data before it’s actually needed.
• Cache Optimization: Adjusting cache behavior for optimal thread performance.
• Memory Access Patterns: Sequences that reduce wait times and contention.
3. Parallelism:
• Dependency Analysis: Identifying dependencies that might hinder parallel execution.
• Fine vs. Coarse Parallelism: Granularity of tasks that can be parallelized.
• Task Partitioning: Dividing tasks effectively among available threads.
4. Multithreading Models:
• Static vs. Dynamic Multithreading: Predetermined vs. on-the-fly thread allocation.
• Simultaneous Multithreading (SMT): Running multiple threads on one core.
• Hardware Threads vs. Software Threads: Distinguishing threads at the CPU vs. OS level.
5. Data Structures:
• Lock-free Data Structures: Structures designed for concurrent access without locks.
• Thread-local Storage: Memory that’s specific to a thread.
• Efficient Queue Designs: Optimizing data structures like queues for thread communication.
6. Synchronization Mechanisms:
• Barrier Synchronization: Ensuring threads reach a point before proceeding.
• Atomic Operations: Operations that complete without interruption.
• Locks: Techniques to avoid common pitfalls like deadlocks and contention.
7. Stall Causes and Mitigation:
• Instruction Dependencies: Managing data and control dependencies.
• IO-bound vs. CPU-bound: Balancing IO and CPU workloads.
• Handling Page Faults: Strategies for minimal disruption during memory page issues.
8. Instruction Pipelining:
• Pipeline Hazards: Situations that can disrupt the smooth flow in a pipeline.
• Out-of-Order Execution: Executing instructions out of their original order for efficiency.
• Branch Prediction: Guessing the outcome of conditional operations to prepare.
There are some of the complications related to barrel processing
people aren't really doing GPU coding; they're calling CUDA libraries. As with other Intel projects this needs dev support to survive and Intel has not been good at providing it. Consider the fate of the Xeon Phi and Omnipath.
I don't think I have a broad enough perspective of the industry to assess that. In my corner of the world (scientific computing) it's probably three quarters simple use of accelerators and one quarter actual architecture based on the GPU itself.
There's two single threaded cores, but the four multithreaded cores are indeed Tera-style barrel processors. The Tera paper is even cited directly in the PIUMA white paper: https://arxiv.org/abs/2010.06277
What are the kinds of challenges to write things efficiently?
From skimming Wikipedia, it looks like a big challenge is cache pollution. Is it possible that the hit to cache locality is what inhibits uptake? After all, most threads in the OS are sitting idle doing nothing, which means you’re penalized for any “hot code” that’s largely serial (ie typically you have a small number of “hot” applications unless your problem is embarrassingly parallel)
> What are the kinds of challenges to write things efficiently?
The challenge is mostly that you have to create enough fine-grained parallelism and that per thread performance is relatively low. Amdahl's law is in full effect here, a sequential part is going to bite you hard. That's why each die on this chip has two sequential-performance cores.
The graph problems this processor is designed to handle have plenty of parallelism and most of the time those threads will be waiting for (uncached) 8B DRAM accesses.
> From skimming Wikipedia, it looks like a big challenge is cache pollution
This processor has tiny caches and the programmer decides which accesses are cached. In practice, you cache the thread's stack and do all the large graph accesses un-cached, letting the barrel processor hide the latency. There are very fast scratchpads on this thing for when you do need to exploit locality.
In some aspects, yes. Arguably, it's much harder to max GPUs because they have the added difficulty of scheduling and executing by blocks of threads. If not all N threads in a block have their input data ready or are branching differently, you are idling some execution units.
It is not hard at all to fully utilize a GPU with a problem that maps well onto that type of architecture. It's impossible to fully utilize a GPU with a problem that does not.
A barrel processor would make branching more efficient than on a GPU, at the cost of throughput. The set of problems that are economically interesting and that would strongly profit from that is rather small, hence these processors remain niche. Conversely, the incentive to have problems that map well to a GPU is higher, because they are cheap and ubiquitous.
> The primary weakness of barrel processors is human; only a handful of people grok how to design codes that really exploit their potential. They look deceptively familiar at a code level, because normal code will run okay, but won’t perform well unless you do things that look extremely odd to someone that has only written code for CPUs.
Nowadays, apps that run straight on baremetal servers are the exception instead of the norm. Some cloud applications favour tech stacks based on high level languages designed to run single-threaded processes on interpreters that abstract all basic data structures, and their bottleneck is IO throughput instead of CPU.
Even if this processor is not ideal for all applications, it might just be the ideal tool for cloud applications that need to handle tons of connections and stay idling while waiting for IO operations to go through.
The new Mojo programming language is attempting to deal with such issues by raising the level of abstraction. The compiler and runtime environment are supposed to automatically optimize for major changes in hardware architecture. In practice through I don't know how well that could work for barrel processors.
If Intel was very bullish on AI, they might be tempted to design arbitrarily complicated architectures and just trust that GPT-6 will be able to write code for it.
This was a bet that completely failed for Itanium, but maybe this time...
Is GPT-6 the proverbial magic wand that makes all your dreams come true? Because you just hand waved away all the complexity just by name dropping it. Let's get back to Earth for one second...
Well... This is a research project, and they aren't betting the farm on it. It's not even x86-compatible.
And then, it'd require a lot of software rewriting, because we are not used to write for hundreds of threads for context switching is a very expensive operation on modern CPUs. On this CPU a context switch is fast and happens on any operation that makes the CPU wait for memory access, therefore, thinking in terms of hundreds of threads pays off. But, again, this will need some clever OS designs to hide everything under an API existing programs can recognize.
It may even be that nothing comes out of it except another lesson on how not to build a computer.
Why do we need x86 compatibility? x86 chips are already fast.
Existing programs don't need to see these things at all, they can just act like microservices, and we could load them with an image and call them as black boxes.
I would think a lot more work would be done by various accelerator cards by now.
They probably aren't insanely bullish. GPT is a revolution but it's a revolution because it can do "easy" general tasks for the first time, which makes it the first actually useful general purpose AI.
But it still can't really design things. It's probably about as far away from being able to design a complex CPU architecture as GPT-4 is from Eliza.
What do you really mean by "really" in that sentence?
In any case, the claim you responeded to was not that the chips would be designed from the ground up by AI, only that AI will enable us to run code on top of chips that are even more complex than current chips.
The Nvidia toolkit you linked is for place & route, which is a much easier task than designing the actual architecture and microarchitecture. It's similar to laying out a PCB.
The Google research you linked is using AI to make better decisions about when to apply optimisations. For example when do you inline a function? Which register do you spill? Again this is a very simple (conceptually) low level task. Nothing like writing a compiler for example.
> What do you really mean by "really" in that sentence?
I mean successfully create complex new designs from scratch.
I really wouldn't say it's an easier task at all. It's so intense it's essentially impossible for a human to do from scratch. But it is "just" an optimization problem which is different from designing an architecture.
And a bet they didn't even know they made for iAPX 432. The ADA compiler was awful optimization-wise, but that came out in an external research paper too late to save it.
They have been so careful not to leak anything that there is very little interest on it. I completely forgot about them and, if they never launch, I doubt anyone would notice.
In a way, yes - it's no different from scalar CPUs from back when they didn't need to wait for memory. GPUs are specifically designed to operate on vectors.
64 of the 66 treads are slow threads where each group of 16 threads shares one set of execution units and all 64 threads share a scratchpad memory and the caches.
This part of each core is very similar to the existing GPUs.
What is different in this experimental Intel CPU and unlike in any previous GPU or CPU, is that each core, besides the GPU-like part, also includes 2 very fast threads, with out-of-order execution and a much higher clock frequency than the slow threads. Each of the 2 fast threads has its own non-shared execution units.
Separately, the 2 fast threads and the 64 slow threads are very similar with older CPUs or GPUs, but their combination into a single core with shared scratchpad memory and cache memories is novel.
> Separately, the 2 fast threads and the 64 slow threads are very similar with older CPUs or GPUs, but their combination into a single core with shared scratchpad memory and cache memories is novel.
Getting some Cell[1] vibes from that, except in reverse I guess.
I'm far from a CPU or architecture expert but the way you describe it this CPU reminds me a bit of the Cell from IBM, Sony, and Toshiba. Though, I don't remember if the SPEs had any sort of shared memory in the Cell.
While there are some similarities with the Sony Cell, the differences are very significant.
The PPE of the Cell was a rather weak CPU, meant for control functions, not for computational tasks.
Here the 2 fast threads are clearly meant to execute all the tasks that cannot be parallelized, so they are very fast, according to Intel they are eight time faster than the slow threads, so the 2 fast threads concentrate 20% of the processing capability of a core, with only 80% provided by the other 64 threads.
It can be assumed that the power consumption of the 2 fast threads is much higher than that of the slow threads. It is likely that the 2 fast threads consume alone about the same power as all the other 64 threads, so they will be used at full-speed only for non-parallelizable tasks.
The second big difference was that in the Cell the communication between the PPE and the many SPEs was awkward, while here it is trivial, as all the threads of a core share the cache memories and the scratchpad memory.
The SPEs only had individual scratchpad memory that was divorced the traditional memory hierarchy. You needed to explicitly transfer memory in and out.
I think generally the threads are spending a lot of time waiting on memory. It can take >100 cycles to get something from ram so you could have all your threads try to read a pointer and still have computation to spare until the first read comes back from memory.
It could be that eg 97% of your threads are looking things up in big hashtables (eg computing a big join for a database query) or binary-searching big arrays, rather than ‘some I/O task’
Let's say that I can get something from RAM in 100 cycles. But if I have 60 threads all trying to do something with RAM, I can't do 60 RAM accesses in that 100 cycles, can I? Somebody's going to have to wait, aren't they?
this would work really well with rambus style async memory if it every got out from under the giant pile of patents
the 'plus' side here is that that condition gets handled gracefully, but yes, certainly you can end up in a situation where memory transactions per second is the bottleneck.
its likely more advtangeous to have a lot of memory controllers and ddr interfaces here than a lot of banks on the same bus. but that's a real cost and pin issue.
the mta 'solved' this by fully dissociating the memory from the cpu with a fabric
I’m not exactly sure what you mean. RAM allows multiple reads to be in flight at once but I guess won’t be clocked as fast as the cpu. So you’ll have to do some computation in some threads instead of reads. Peak performance will have a mix of some threads waiting on ram and others doing actual work.
> But that can't be disk I/O, so that would leave networking?
Networking is a huge part of cloud applications, and network connections take orders of magnitude longer to go through than disk access.
There are components of any cloud architecture which are dedicated exclusively to handling networking. Reverse proxies, ingress controllers, API gateways, message broker handlers, etc etc etc. Even function-as-a-service tasks heavily favour listening and reacting to network calls.
I dare say that pure horsepower servers are no longer driving demand for servers. The ability to shove as many processes and threads on a single CPU is by far the thing that cloud providers and on prem companies seek.
Following the history here, DARPA also funded work in ~2005 on a project Monarch, that I saw presented at a Google tech talk back then. I believe it refers to the "butterfly" architectures of very scalable interconnects of lightweight processing units
Haven't seen the ISA, but it's not insane to imagine one where explicit data cache manipulation instructions are a requirement (that a memory access outside a cache would fault). I think it's even helpful to make those operations explicit when you are writing high-performance code. On a processor like this, any operation to load a cache that's not already loaded should trigger a switch to the next runnable thread (which also become entities exposed to the ISA).
Also, I'm not even sure it'd be too painful to program (in assembly, at least). It'd be perhaps inconvenient to derive those ops from C code, but Rust, with its explicit ownership, may have a better hand here.
I don’t think it necessarily implies a barrel processor. More like a higher count for SMT which could be due to the higher CPU performance relative to the CPU <> memory bandwidth. While the slow fetches occur, the system could execute more instructions for other threads in parallel.
Very badly, this is the polar opposite design of a GPU.
It does share the latency-hiding-by-parallelism design, but GPUs do that scheduling on a pretty coarse granularity (viz. warp). The barrel processors on this thing round-robin through each instruction.
GPUs are designed for dense compute: lots of predictable data accesses and control flow, high arithmetic intensity FLOPS.
In contrast, this is designed for lots of data-dependent unpredictable accesses at the 4-8B granularity with little to no FLOPS.
To me it looks like the opposite, the processor being very fast, and exporting itself as 66 threads to not spend virtually all its time waiting for external circuits.
IIRC it was targeted at database workloads, and the pitch was the same: if the core is usually twiddling its thumbs waiting on RAM, it might as well work on another thread in the meantime.
And I guess IBM and Zen4C kinda fufill this demand, but more SMT16 cloud instances explicity targeted at these low IPC loads would be neat.
They seem to be suggesting if you amortize the die cost and speed consequences of electrical to optical, you can then get pretty much distance-independent speeds (obviously not, but lets limit ourselves to the distance of chip carriers inside a single chassis) interconnect at good rates in optical, with low interference and free routing within the bend radius of the light guides.
Maybe I misread it. Maybe the optical component is for something else like die stacking so you get grids of chips on a super carrier, with optical interconnect.
If not for Intel's 10nm debacle, Apple probably wouldn't have left. All of Apple's early-2010s hardware designs were predicated on Intel's three-years-out promises of thermal+power efficiency for 10nm, that just never materialized.
I hard disagree. The chassis and cooler designs of the old intel based macs sandbagged the performance a great deal. They were already building a narrative to their investors and consumers that a jump to in house chip design was necessary. You can see this sandbagging in the old intel chassis Apple Silicon MBP where their performance is markedly worse than the ones in the newer chassis.
That doesn’t make sense: everyone else got hit by Intel’s failure to deliver, too. Even if you assume Apple had some 4-D chess plan where making their own products worse was needed to justify a huge gamble, it’s not like Dell or HP were in on it. Slapping a monster heat sink and fan on can help with performance but then you’re paying with weight, battery life, and purchase price.
I think a more parsimonious explanation is the accepted one: Intel was floundering for ages, Apple’s phone CPUs were booming, and a company which had suffered a lot due to supplier issues in the PowerPC era decided that they couldn’t afford to let another company have that much control over their product line. It wasn’t just things like the CPUs failing further behind but also the various chipset restrictions and inability to customize things. Apple puts a ton of hardware in to support things like security or various popular tasks (image & video processing, ML, etc.) and now that’s an internal conversation, and the net result is cheaper, cooler, and a unique selling point for them.
I was thinking of that as cheaper but there’s also a strategic aspect: Apple is comfortable making challenging long-term plans, and if one of those required them to run the Mac division at low profitability for a couple of years they’d do it far more readily than even a core supplier like Intel.
Apple doesnt manufacture their own chips or assemble their own devices. They are certainly paying the profit margins of TSMC, Foxconn, and many other suppliers.
That seems a bit pedantic, practically every HN reader will know that Apple doesn't literally mine every chunk of silicon and aluminum out of the ground themselves, so by default they, or the end customer, are paying the profit margins of thousands of intermediary companies.
I doubt it was intentional, but you're very right that the old laptops had terrible thermal design.
Under load, my M1 laptop can pull similar wattage to my old Intel MacBook Pro while staying virtually silent. Meanwhile the old Intel MacBook Pro sounds like a jet engine.
The m1/m2 chips are generally stupid effecient compared to Intel chips (or even amd/arm/etc)... Are you sure the power draw is comparable? Apple is quite well known for kneecapping hardware with terrible thermal solutions and I don't think there are any breakthroughs in the modern chassis.
I couldn't find good data on the older mbpros, but the m1 max mbpro used 1/3 the power vs an 11th gen Intel laptop to get almost identical scores in cinebench r23.
> Apple is quite well known for kneecapping hardware with terrible thermal solutions
But that was my entire point (root thread comment.)
It's not that Apple was taking existing Intel CPUs and designing bad thermal solutions around them. It's that Apple was designing hardware first, three years in advance of production; showing that hardware design and its thermal envelope to Intel; and then asking Intel to align their own mobile CPU roadmap, to produce mobile chips for Apple that would work well within said thermal envelope.
And then Intel was coming back 2.5 years later, at hardware integration time, with... basically their desktop chips but with more sleep states. No efficiency cores, no lower base-clocks, no power-draw-lowering IP cores (e.g. acceleration of video-codecs), no anything that we today would expect "a good mobile CPU" to be based around. Not even in the Atom.
Apple already knew exactly what they wanted in a mobile CPU — they built them themselves, for their phones. They likely tried to tell Intel at various points exactly what features of their iPhone SoCs they wanted Intel to "borrow" into the mobile chips they were making. But Intel just couldn't do it — at least, not at the time. (It took Intel until 2022 to put out a CPU with E-cores.)
the whole premise of this thread is that this reputation isnt fully justified, and thats one I agree with.
Intel for the last 10 years has been saying “if your CPU isn't 100c then theres performance on the table”.
They also drastically underplayed TDP compared to, say, AMD, by taking the average TDP with frequency scaling taken into consideration.
I can easily see Intel marketing to Apple that their CPUs would be fine with 10w of cooling with Intel knowing that that they wont perform as well, and Apple thinking that there will be a generational improvement on thermal efficiency.
>Under load, my M1 laptop can pull similar wattage to my old Intel MacBook Pro while staying virtually silent. Meanwhile the old Intel MacBook Pro sounds like a jet engine.
On a 15/16" Intel MBP, the CPU alone can draw up to 100w. No Apple Silicon except an M Ultra can draw that much power.
There is no chance your M1 laptop can draw even close to it. M1 maxes out at around 10w. M1 Max maxes out at around 40w.
Being generous and saying TDP is actually the consumption; most Intel Mac's actually shipping with "configurable power down" specced chips ranging from 23W (like the i5 5257U) to 47W (like the i7 4870HQ); (NOTE: newer chips like the i9 9980HK actually have a lower TDP at 45w)
of course TDP isn't actually a measure of power consumption, but M2 Max has a TDP of 79W which is considerably more than the "high end" Intel CPU's; at least in terms of what Intel markets.
Keep in mind that Intel might ship a 23w chip but laptop makers can choose to boost it to whatever it wants. For example, a 23w Intel chip is often boosted to 35w+ because laptop makers want to win benchmarks. In addition, Intel's TDP is quite useless because they added PL1 and PL2 boosts.
Apple always shipped their chips with "configurable power down" when it was available, which isn't available on higher specced chips like the i7/i9 - though they didn't disable boost clocks as far as I know.
The major pains for Apple was when the thermal situation was so bad that CPUs were performing below base clock. -- at that point i7's were outperforming i9's because they were underclocking themselves due to thermal exhaustion; which feels too weird to be true.
That's not Apple. That's Intel. Intel's 14nm chips were so hot and bad that they had to be underclocked. Every laptop maker had to underclock Intel laptop chips - even today. The chips can only maintain peak performance for seconds.
> You can see this sandbagging in the old intel chassis Apple Silicon MBP where their performance is markedly worse than the ones in the newer chassis.
And you can compare both of those and Intels newer chips to Apples ARM offerings.
I dunno, they could have gone to AMD who is on TSMC and have lots of design wins in other proprietary machines where the manufacturer has a lot of say in tweaking the chip (=game consoles).
I think Apple really wanted to unify the Mac and iOS platforms and it would have happened regardless.
If Intel didn't have those problems, Intel would still be ahead of TSMC, and the M1 might have well be behind the equivalent Intel product in terms of performance and efficiency. It is hard to justify a switch to your inhouse architecture under these conditions.
Apple had been doing their own mobile processors for a decade. It was matter of time before they vertically integrated the desktop. They definitely did not leave Intel over the process tech.
Apple has been investing directly in mobile processors since they bought a stake in ARM for the Newton. Then later they heavily invested in PortalPlayer, the designer of the iPod SoCs.
Their strategy for desktop and mobile processors has been different since the 90s and they only consolidated because it made sense to ditch their partners in the desktop space.
> Apple has been investing directly in mobile processors since they bought a stake in ARM for the Newton. Then later they heavily invested in PortalPlayer, the designer of the iPod SoCs.
Not this heavily. They bought an entire CPU design and implementation team (PA Semi).
I mean, they purchased 47% of ARM in the 90s. That's while defining the mobile space in the first place, and it being much more of a gamble than now. Heavy first line investment to create mobile niches has empirically been their strategy for decades.
Apple invested in them for a chip for Newton, not for the ARM architecture in particular. Apple was creating their own PowerPC architcture around this time, and they sold their share of ARM when they gave up on Newton.
The PA Semi purchase and redirection of their team from PowerPC to ARM was completely different and obviously signaled they were all in on ARM, like their earlier ARM/Newton stuff did not.
Let's not forget Intel had issues with atom soc chips dying like crazy due to power-on-hours in things like Cisco routers, Nas and other devices around this era too. I think that had a big ripple effect on them to play a cog in their machine around 2018 or so.
Yes 10nm+++++ was a big problem, too.
Apple was also busy going independent and I think their path is to merge iOS with MacOX someday here so it makes sense to dump x86 in favor of higher control and profit margins.
Right. It made no sense for Apple to have complete control over most of their devices, with custom innovations moving between them, and still remain dependent on Intel for one class of devices.
Intel downsides for Apple:
1. No reliable control of schedule, specs, CPU, GPU, DPU core counts, high/low power core ratios, energy envelopes.
2. No ability to embed special Apple designed blocks (Secure Enclave, Video processing, whatever, ...)
3. Intel still hasn't moved to on-chip RAM, shared across all core-types. (As far as I know?)
4. The need to negotiate Intel chip supplies, complicated by Intel's plans for other partner's needs.
5. An inability to differentiate Mac's basic computing capabilities from every other PC that continues to use Intel.
6. Intel requiring Apple to support a second instruction architecture, and a more complex stack of software development tools.
Apple solved 1000 problems when they ditched Intel.
Ah yes. The CPU and RAM are mounted tightly together in a system on a chip (SOC) package, so that all RAM is shared by CPU, GPU, DPU/Neural and processor cache.
I can't seem to find any Intel chips that are packaged with unified RAM like that.
Apple switching to ARM also cost some time. It took like 2 years before you could run Docker on M1. Lots of people delayed their purchases until their apps could run
TSMC processes are easier to use and there's a whole IP ecosystem around them that doesn't exist for Intel's in-house processes. I can easily imagine a research project preferring to use TSMC.
Many intel products that aren't strategically tied to their process nodes use TSMC for this reason. You can buy a lot of stuff off-the-shelf and integration is a lot quicker.
Pretty much everything that isn't a logic CPU is a 2nd class citizen at Intel fabs. It explains why a lot of oddball stuff like this is TSMC. Example: Silicon Photonics itself is being done in Albuquerque, which was a dead/dying site.
They've used them for maybe 15 years for their non-PC processors, guys.
If you search Google with the time filter between 2001 and 2010 you'll find news on it.
There must be some reason HN users don't know very much about semiconductors. Probably principally a software audience? Probably the highest confidence:commentary_quality ratio on this site.
nvidia and amd have already signed contracts to use Intel's fab service (angstrom-class) so it's not unfathomable to consider. AMD did the same when they dropped global foundries and it could be argued that this was the main reason for their jump ahead vs intel.
They're all using ASML lithography machines anyway, so who's feeding the wafers into the machine is kind of inconsequential.
This seems more like a proof-of-concept CPU rather than a marketable product, highly specialized, problems and workloads that it solves yet to be found.
I anticipate that photonics will be introduced to general-purpose computing in the years to come, even if only to get a handle on the rising excess heat problems. Most notable is the 10 -> 7 nm process.
Sun did something similar many years ago, but they abandoned it in later UltraSPARC CPUs. Was it that the threads were starved? Did they find that less cores but faster was better? I can't find out much detail about it.
Perhaps HN user bcantrill will give us the inside scoop :-)
I used them in the heyday. There were workloads where they were fantastic, but anything that needed good single-core performance suffered. It also often required much more tuning of parameters to perform, or recompilation, etc. For me, it also coincided with lots more need to use SSL, which had been optimized well for x86 but not Sparc. So now you were dealing with more complexity via SSL offload cards, or reverse proxies. Basically, just too fussy to make them work well outside a few niche areas.
Maybe not a big factor, but it also was bothersome for sysadmins because much of the work we had to do was serial, single core, etc. Meaning it showed it's worst side to the group that usually signed the vendor checks.
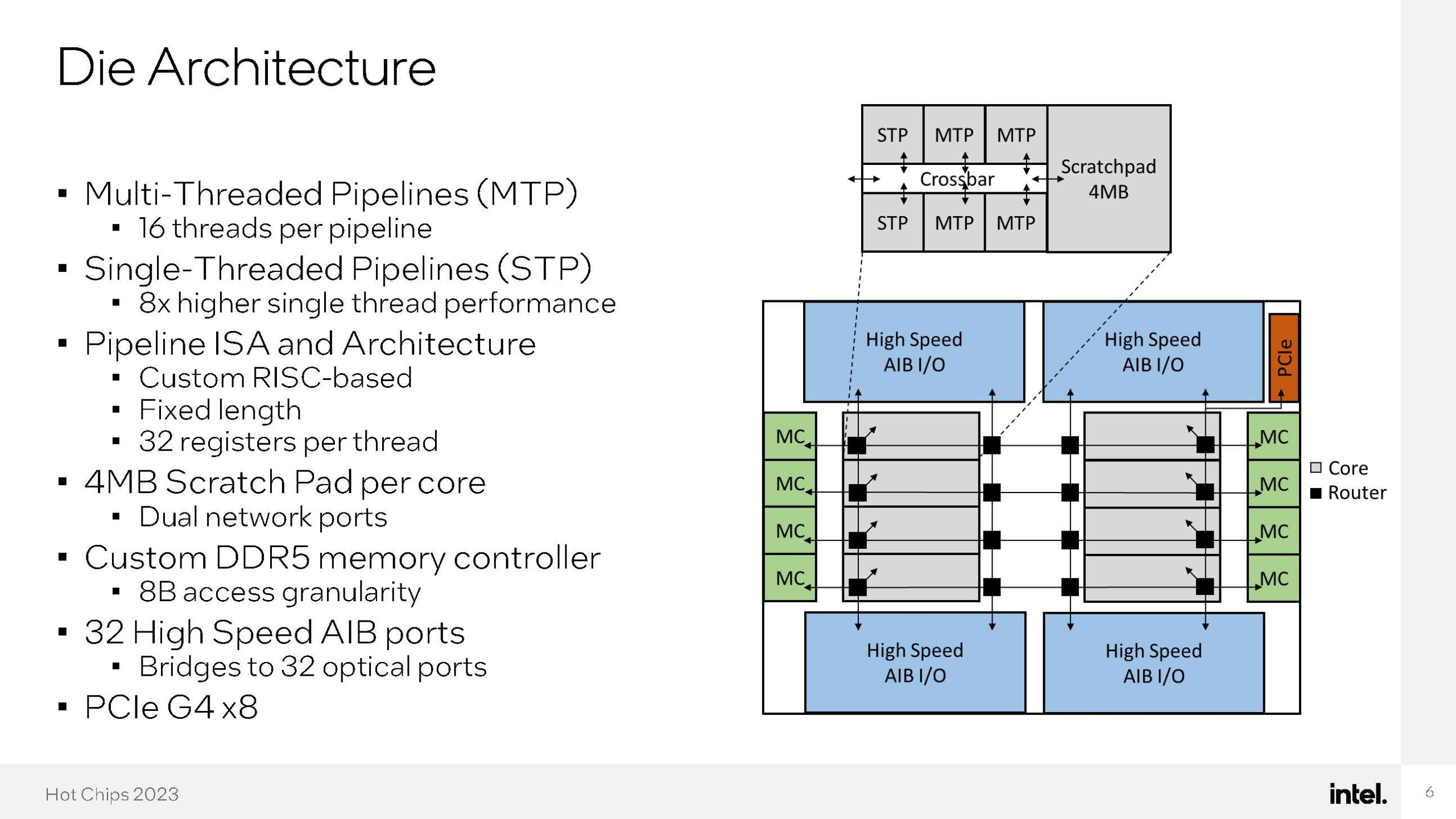
Here is an interesting one. Intel has a 66-thread-per-core processor with 8 cores in a socket (528 threads?) The cache apparently is not well used due to the workload. This is a RISC ISA not x86.
where 2 is number of slow threads, like current CPU,
and 64 are more like GPU threads.
This architecture could be next step in GPU integration. Hope they manage to write efficient implementation for standard math libs. It could be faster than separate CPU+GPU in one package.
The diagram shows 8 gray boxes (in 2 columns of 4). Each gray box is a core.
Above that is a detailed view of what each core looks like. There's a middle section labeled "Crossbar", and above that are 3 boxes labeled STP, MTP, and MTP. Below that are another 3 identical boxes. So each core has 4x MTPs and 2x STP.
What are those? The text of the same slide says MTP is "Multi-Threaded Pipelines" with "16 threads per pipeline" and STP is "Single-Threaded Pipelines" with (self-evidently) 1 thread per pipeline.
So, why do they consider that 1 core? Isn't that more like a "compute complex" of multiple cores, as seen on zen 2, but with different core architectures attached instead of 4 cores of the same design?
I'd be inclined to call them multiple cores myself, but if they all share the same pipe to main memory that would be a plausible reason to call them all the same core.
Maybe 2 higher-powered primary threads + 64 aux threads or something. I don't know how that makes sense as part of a single core but I don't have a better guess.
That's what it is, as shown on slide 6 (Die Architecture). Personally I would call this 16 big cores and 32 throughput cores but for some reason Intel is calling it 8 cores.
in this kind of architecture, its generally more fruitful to leave the asynchrony to the hardware. the tera mta, which other people have mentioned has/had hardware synchronization in the memory system to effect this.
there were no interrupts, just a thread waiting for someone to wake it up.
Not on-chip no, it's still DDR5 DIMMs. What is cool about is that it is using custom DIMMs and memory controllers to do 8B-granularity accesses. Plus, each core has its own MC, as you can see on the die shot. If each MC manages 4GB of DRAM, that would explain the 32GB per chip.
Your regular DRAM memory controller will use the 64B bus to pull in a single 64B line of memory. In your modern x86 systems, that's equal to a cache line.
If you are only accessing a single 4B or 8B element of that cache line >80% of the time, as shown on the slides, you are wasting 7/8th of all memory bandwidth with irrelevant data. If you were to use that 64B memory bus to access 8x different 8B memory locations, you get a large boost to your effective bandwidth.
There are some other explainers out there that go into more detail, but Nvidia is also doing this with Grace Hopper (I think?), and Apple with their M-series chips.
Update: It looks like it's just DDR5 ("custom DDR5-4400 DRAM") in this case.
Just a shout-out to the STH team (hey Patrick) who have been live blogging literally every presentation and announcement from hot chips. I've been reading up on next gen xeons and google's TPU datacenter architecture all day.
Thanks. We will have more in a bit, and may not get to all of them. I was talking to lots of folks that came to say hi today. Trying to get at least a good portion of these done this week.
Thank you for your service. Between your coverage and Dr. Ian Cutress', we can pick up on announcements from events like Hot Chips with a lot more clarity than the PR speak the companies themselves put out.
Very interesting to see the adoption of fiber optic in chips (PIC, photonics in chip/photonic integrated circuit) from so many big players and newcomers.
In this case photonics is used to transport data from one place to another. An electrical bit is converted to a photonic bit, moves across the chip, and then is converted back to an electrical bit. I'm not aware of any even vaguely practical photonic logic gates that would start to allow us to do computation in light.
It really seems like Intel is designing this chip to support a very specific workload, when it would have been a better use of everyone's time and money to just rewrite the workload to work well on normal chips...
Graph workloads can work well on normal chips but you really have to know what you are doing. Clever algorithms that demonstrated graphs workloads could be efficiently run on CPUs was a major contributor to the demise of barrel processing research, since a lot of the interest in those architectures was for the purposes of efficient graph analysis. Given the option, economics heavily favors commodity silicon.
Citation needed. Huge sparse graphs can be processed fairly efficiently on both CPU's and GPU's, but the code has to be written with the architecture in mind.
I have no expertise in this area, but I think the presentation explains the issue quite well. The workloads they consider have a large number of indirection and poor memory locality, so a lot of memory operations have to wait for cache misses, but you have to do the same thing a lot of times independently with different data.
Normal multithreading is not a solution because it is not granular enough, you can not context switch in the middle of each memory access to run a different thread while waiting for the memory access to complete. You could manually unroll loops and instead of only following one path through the graph you could follow several paths at the same time by interleaving their operations. While this will be able to hide the waiting times because you can continue working on other paths, it will make your code more complex and increase register pressure as you still have the same number of registers but are operating on multiple independent paths. Letting the hardware interleave many parallel paths will keep your code simpler and as each thread has its own registers also not increase register pressure.
The solution is SIMD with a queue of 'to be processed' nodes, and a SIMD program that grabs 32 nodes at once from the queue, processes them all in parallel, and adds any new nodes to process to the end of the queue. There is then plenty of parallelism, great branch predictor behaviour, and the length of the queue ensures that blocking on memory reads pretty much never happens.
Downside: Your business logic of what to do with every node needs to be written in SIMD intrinsics. But that has to be cheaper to do than asking Intel to design a new CPU for you.
Does this actually help? I don't know much about microarchitectural details, so I may be completely wrong. Let's take a simple example, I have some nodes and want to load a field and then do some calculations with the value. I load the pointers of 32 nodes into a SIMD register and issue a gather instruction, I get 32 cache misses. Now it seems to me there is nothing I can do but wait. I can not put this work item back into the queue in the middle of a memory access but even if I could, the overhead seems completely prohibitive to get things out and put them back into queues every other instruction or so.
But with hundreds of hardware threads I could just continue executing some other thread that already got his pointer dereferenced. SIMD is great when you can issue loads and they all get satisfied with the same cache line, but if you have to gather data, then values will arrive one after another and you can not do any dependent work until the last one arrived. I guess the whole point is that all the threads can be at slightly different execution points, while some are waiting for reads to complete others can continue working after their read completed without having to wait for an entire group of reads to complete.
This is also why hyperthreading yields a benefit for sparse/graph workloads. I was getting good results on the KNL Xeon Phi with its four hyperthreads.
But you easily hit the 'outstanding loads' limit if your hyperthreads all do gather instructions every 4-8 instructions. The architecture needs to balanced around it.
Those nodes in the queue have to come from somewhere and that is where the inefficiency lies.
If you use SIMD gather instructions to fetch all the children of a node, that is still going to be very inefficient on e.g. a Xeon. Each of those gather loads are likely to hit different cache lines, which are accessed only once and waste 7/8th of the memory bandwidth pulling them in. SIMD is also not going to help if you are memory bandwidth or latency bound, we're talking ~0.1 ops/byte here.
Founding fathers aside, if you're not connected to the internet or even wider LAN, but on some private lab running specific workloads, you don't need security from malicious side-loaded apps.
Pretty snarky comment in my opinion. From my understanding, OpenBSDs main reason for not supporting things (apart from the obvious lack of resources) is that they are not free (require blobs etc.).
Security concerns are typically solved in software by them as long as they can get access to the hardware in a free (as in freedom) way.
I actually applaud them for their hard stance and am happy that we have this end of the spectrum as well as the Linux end (pragmatic, just get devices to work somehow, willing to accept some non-freedom). It's certainly not the easiest path to follow.
> Pretty snarky comment in my opinion. From my understanding, OpenBSDs main reason for not supporting things (apart from the obvious lack of resources) is that they are not free (require blobs etc.).
Your comment reads as someone who doesn’t really interact with the OpenBSD ecosystem very much.
I’m pretty sure the commenter you’re replying to was referring to the fact that hyperthreading is disable by default on OpenBSD systems out of caution: https://news.ycombinator.com/item?id=17350278
And as for their attitude toward firmware blobs, while they ideally prefer them to be free, they only require them to be redistributable; this is a less hard stance than GNU. Plenty of OpenBSD drivers require proprietary blobs to function.
I mean, considering Intel has had one of the least performant SMT designs in history, easily being trounced by both SPARC and POWER, you'd probably still get 70% of the chips' total performance with them disabled.
Now, when they disable Zen SMT, then there might be a decent talking point.
Interesting question. I don't believe that neither Intel nor AMD have actually found a way to make SMT completely safe against Microarchitectural Data Sampling attacks, so maybe it's not actually possible?
If you only care about security, then I think OpenBSDs approach is currently the best, but it also seems like they got lucky a few times, like with Zenbleed, where they for unknown reason never really adopted the AVX to the same extend as Linux or Windows.
I mean, physically speaking, unless you are deliberately going fully Procrustean on your computations, there's no way to really avoid those types of micro-architectural side-channel disclosures. It's a trade-off. Either you get the computation result faster (but you have side-effects that can be measured as an alternate form of info disclosure), or you trade some minimum possible execution time to gain fewer side-channels through which unintended disclosure can happen.
{kind=link}