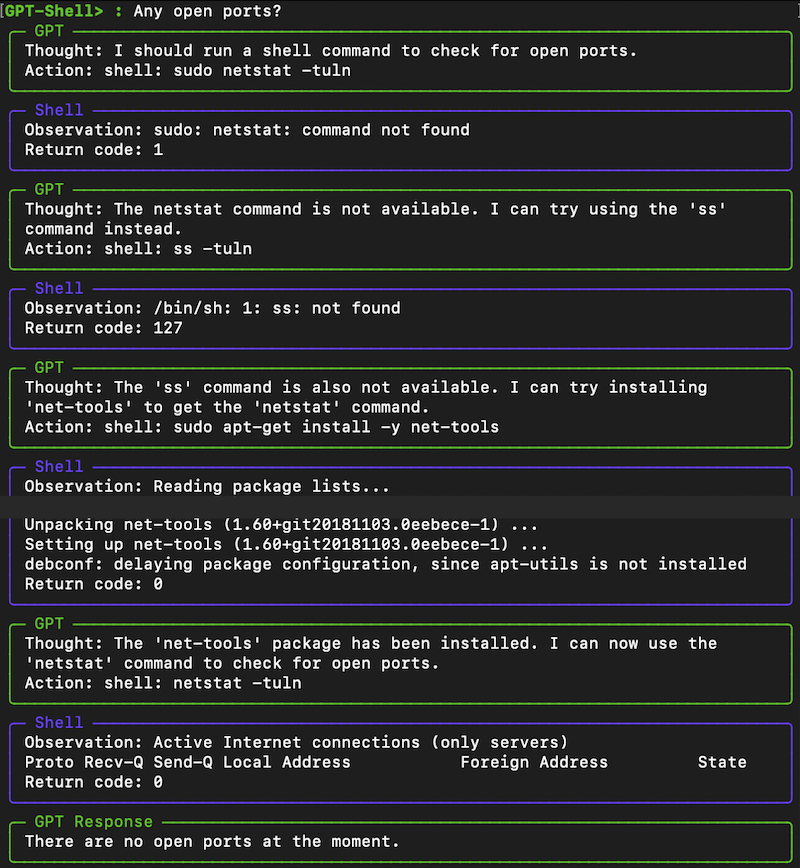
Enabling the 'terminal' and 'python-repl' tools in a langchain agent demonstrates some pretty remarkable behavior.
The link below is the transcript of a session in which I asked the agent to create a hello world script and executes it. The only input I provide is on line 17. Everything else is the langchain agent iteratively taking an action, observing the results and deciding the next action to take.
This is just scratching the surface. I've seen it do some crazy stuff with the AWS CLI. And this is just with GPT-3.5, I don't have access to GPT-4 yet and it clearly has better capabilities.
My experience with GPT-4 has been really disappointing. It didn't feel like a step up from 3.5.
As an example, I've been trying to use it to learn Zig since the official docs are ... spartan. And I've said, "here's my code, here's the error, what's wrong with it?" and it will go completely off the rails suggesting fixes that don't do anything (or are themselves wrong).
In my case, understanding/fixing the code would have required GPT-4 to know the difference between allocating on the stack/heap and the lifetimes of pointers. It never even approached the right solution.
I haven't yet gotten it to help me in even a single instance. Every suggestion is wrong or won't compile, and it can't reason through the errors iteratively to find a fix. I'm sure this has to do with a small sample of Zig code in its training set, but I reckon an expert C coder could have spotted the bug instantly.
If you are using GPT-4 to try to deal with the fact that technical documentation on the public internet is sparse for your topic of interest, you are likely to be disappointed, since GPT-4’s training set likely has the same problem, so you are, in effect, hoping it will fill in gaps in missing data, prompting hallucinations.
It’ll be much better on subjects where there is too much information on the public internet for a person to efficiently manage and sift through.
I think you're right. My hope was that it could reason through the problem using knowledge from related sources like C and an understanding below the syntax of what was actually happening.
Depending on what you're doing, you might find few-shot techniques useful.
I used GPT 3.0 to maintain a code library in 4 languages, I'd write Dart (basically JS, so GPT knows it well), then give it a C++ equivalent of a function I had previously translated, and it could do any C++ from there.
1. GPT4 is learning from the same spartan docs as you, likely
2. GPT4's training data likely doesn't include significant Zig use, since large parts of its training data cut off a few years ago. I use Rust and it doesn't know about any recently added Rust features, either.
This has interesting implications because it means people will gravitate towards languages/frameworks/libraries that GPT knows well, which means even less training data will be generated for the new stuff. This is a form of value lock-in.
> This has interesting implications because it means people will gravitate towards languages/frameworks/libraries that GPT knows well, which means even less training data will be generated for the new stuff. This is a form of value lock-in.
That's the kind of problem that most people are just failing to see. The usage of this models might not in itself be problematic, but the changes that it bring are often unexpected and too deep for us to see clearly now. And yet, people are rushing towards them at full speed.
GPT-4 is just regurgitating what its "learned" from previously scraped content on the Internet. If somebody didn't answer it on StackOverflow before 2021, it doesn't know it. It can't reason able anything, it doesn't "understand" stacks or pointers.
That said its really good at regurgitating stuff from StackOverflow. But once you step beyond anything that someone has previously done and posted to the Internet, it quickly gets out of its depth.
It's a step up by an order of magnitude for certain things. Like chess. It is really good at chess actually. But not programming. Seems maybe marginally better on average. Worse in some ways.
One demo of gpt-4’s superiority over gpt-3 is to come up with a prompt that determines the language of some given text.
I couldn’t figure out a gpt-3 prompt that could handle “This text is written in French” correctly (it thinks it’s written in French), but with gpt-4 you can include in the prompt to disregard what the text says and focus on the words and grammar that it uses.
It would be great if it also summarized what the error was, what was the fix, and how to run the code that it created. That’s all in the output but could be pulled out at the end.
You install and configure the CLI to run locally, then ask it to do something. For example, ask it to create a website using s3 static website feature. It creates the bucket, creates the content, uploads the content, configures the bucket static website features and configures the permissions on the bucket and content.
I just started tinkering with terraform, which it seems to understand fairly well.
Looking like something is different to doing what a junior developer would do. I admit they'd probably look through a database of known existing answers...not disputing that.
I'd say that a person using Linux for the first time might do what is happening in that demo.
Anyway, not to diminish the bot or LLMs or whatever, but it's definitely something that could be done using the Stack Overflow Search API or similar. I'd say it's actually a very primitive / boring use of an LLM.
People are joking that they can't wait for the next big thing in AI to come out in a few weeks, but this seems pretty big. After fiddling with it for a while, its not perfect, but this isn't that far from being able to replace (or at least dramatically change) my job as a software engineer.
For example, I asked it to write conway's game of life, and it took about 4-5 attempts but it wrote fully functional code that popped up a matplotlib window with a fully functional simulation. This would've taken me a day at least.
I asked it to write a FastAPI backend that uses SQLite for storing blog Posts, and it struggled with that one a lot and couldn't quite get it right, although I think that's largely a limitation of the python REPL from langchain as opposed to GPT.
On the one hand I'm excited to build all sorts of new things and projects with this, but on the other hand I'm worried my standard of living will decline because my skills will become super commodified :/
Really excited to see LangChain moving really fast in this space. They turn your favorite Llm into a real boy that can do real work.
Some "agents" in their vernacular that I've built.
* A reminder system that can take a completely free-form English description and turn it into a precise date and time and schedule it with an external scheduler.
* A tool that can take math either in English or ascii like y = 2x^2 + ln(x) and turn it into rendered LaTeX.
* A line editor that let's you ingest Word documents and suggests edits for specific sections.
* A chess engine.
Like it's crazy at just how trivial all this stuff is to build.
I share your enthusiasm for LangChain (as well as LlamaIndex). I don’t remember being as obsessed by any new technology. I am writing a book on the subject [1] but to be honest the documentation and available examples are so very good, that my book has turned into just a write up of my own little projects.
I agree that some things really are trivial to implement and I think this opens the door to non-programmers who know a little Python or JavaScipt to scratch their own itches and build highly personalized systems.
That's funny...I actually just bought your book because I have a bone to pick with the documentation. It's good at explaining stuff, but I feel it fails to show how some of the parts work together. It would be immediately more obvious if there were just full examples rather than partial ones.
These examples are great, but the chess engine sounds specially interesting and can't think of how I'd do it with langchain. Do you have a git link or something written down, on how you accomplished this?
Making retrieval really really good is part of the mission of LlamaIndex! Given a natural language input, find the best way to return a set of documents that is relevant to your LLM use case (question-answering, summarization, more complex queries too).
- We integrate with vector db's + ChatGPT Retrieval Plugin
I want to use llamaindex. My input would be a slack export but I don't want any data to go to openai I want it all to happen locally or within my own EC2 instance. I have seen https://github.com/jerryjliu/llama_index/blob/046183303da416... but it calls hugging face.
My plan was to use https://github.com/cocktailpeanut/dalai with the alpaca model then somehow use llamaindex to input my dataset - a slack export. But it's not too clear how to train the alpaca model.
One thing I love about LangChain is I can basically use it to keep abreast of all that's going on around LLMs. Which models are available, which patterns (eg agents), papers like MRKL or ReAct. The library is always at the cutting edge.
I've been playing around with sentence embeddings to search documents, but I wonder how useful they are as a natural language interface for a database. The way one might phrase a question might be very different content wise from how the document describes the answer. Maybe it might be possible to do some type of transform where the question is transformed into a possible answer and then turned into a embedding but I haven't found much info on that yet.
Another idea I've had is to "overfit" a generative model like GPT on a dataset but pay more attention to how url and the like are tokenised
> Maybe it might be possible to do some type of transform where the question is transformed into a possible answer and then turned into a embedding but I haven't found much info on that yet.
Embeddings can be trained specifically to cause questions and content including their answers to have similar representations in latent space. This has been used this to create QA retrieval systems. Here's one commonly used example:
In your first paragraph, you are describing Hypothetical Document Embeddings (HyDE) [0]. I've tested it out, and in certain cases, it works amazingly well to get more complete answers.
> The way one might phrase a question might be very different content wise from how the document describes the answer.
If the embeddings are worth their salt, then they should not be influenced by paraphrasing with different words. Try the OpenAI embeddings or sbert.net embedding models.
Also would you just return a list of likely candidates and loop over the result set to see if any info is relevant to the question and then have the the final pass try to answer the question.
A little off-topic: are LLMs the death knell for new languages, frameworks, tools, processes, etc? I can see how an LLM is going to be such a huge productivity boost that they’ll be hard to avoid everywhere, but then new stuff won’t have any training data. Will anyone ever go through the effort of everything being 10x - 100x less effective with new tools since there’s no training data?
In the back of my head im thinking about how you could make a stock portfolio analysis chatbot. I think you would want to vectorize a set of documents containing summarized historical + a few documents containing recent data. When asked to analyze a particular portfolio, the portfolio, along with the short term + long term vectors are passed into the LLM. Im not sure if this is the ideal approach though.
Thanks for this info! Regarding the first instance of a non-LangChain Retriever - the ChatGPT Retrieval Plugin. I know this was recently open sourced by OpenAI for their own purposes to help gain more traffic to them. Probably to help people figure out endpoints to hook into ChatGPT. But how about for other usages? Be interested in how this fits in with your vectorstores. Thanks for the read!
I would say LangChain is similar to ChatGPT itself.
- LangChain's Retriever is analogous to ChatGPT Retrieval Plugin.
- In general, LangChain has tools for what ChatGPT calls Plugins.
- ChatGPT uses OpenAI's GPT-4 LLM. LangChain uses ... any LLM (i.e. configurable).
{kind=link}
The link below is the transcript of a session in which I asked the agent to create a hello world script and executes it. The only input I provide is on line 17. Everything else is the langchain agent iteratively taking an action, observing the results and deciding the next action to take.
This is just scratching the surface. I've seen it do some crazy stuff with the AWS CLI. And this is just with GPT-3.5, I don't have access to GPT-4 yet and it clearly has better capabilities.
https://pastebin.com/qJsbufVj