> On a single multi-GPUs server, even with the highest-end A100 80GB GPU, PyTorch can only launch ChatGPT based on small models like GPT-L (774M), due to the complexity and memory fragmentation of ChatGPT. Hence, multi-GPUs parallel scaling to 4 or 8 GPUs with PyTorch's DistributedDataParallel (DDP) results in limited performance gains.
Where are these numbers coming from? An 80GB A100 GPU is certainly more than capable of hosting a 1.5B GPT. We were running 774M on rinky-dink cards back in 2019 for our inference purposes.
I don’t understand how they went from talking about 175B params across 32 cards to 774M on one card. 175B divided by 32 is 5.4B.
In fact, I’m not sure what they’re saying in general. They seem to be confusing data parallelism with model parallelism with memory fragmentation, while namedropping a bunch of training techniques.
The hard part of ChatGPT isn’t the size. It’s the training process. It took a small army of contractors rating outputs as good or bad. Once that dataset gets replicated, we can start talking about size. Hopefully LAION will deliver.
I think they are correctly referring to ChatGPT as GPT-3 + RLHF. In other words
ChatGPT = GPT-3 + RLHF. So, 80GB A100 GPU would be required for both GPT-L AND RLHF (PyTorch version). And it looks to me from the TFA that the main thing that takes a lot of space is actually RLHF.
>I don’t understand how they went from talking about 175B params across 32 cards to 774M on one card. 175B divided by 32 is 5.4B.
They claim 774M is the size of GPT-L which if run in conjunction with their RLHF would require 80GB A100 GPU to train (using their RLHF PyTorch implementation). They additionally claim that training GPT-3(175B params) plus RLHF would need 64 * 80gb = 5120gb of memory if using PyTorch implementation of RLHF or 32 * 80gb = 2560gb if going Colossal AI route.
To be honest, these numbers do look to me to be a bit of a cheesy ad for their product but hey they need to put food on their table too. I'm not sure if the dataset would be such a huge problem otherwise Britannica would still be ahead of Wikipedia. Given an army of volunteers willing to produce it OpenAI brigade of contractors has no chance.
That's unlikely to work. The memory has to be fast with low latency, even switching from on-board VRAM to system RAM slows performance at least 10-100x. The bottleneck isn't computing power it's I/O. Total bus bandwidth of a common small AI cluster is around 1 terabyte per second.
We really shouldn't be building an "open source" AI in the first place though, and it's going to be illegal to do so soon. The weaponization power will be made clear soon and that will justifiably spook everyone.
There's a significant number of people working hard on making certain tech illegal or at least heavily restricted. E2EE and Onion Routing comes to mind. That doesn't mean we should abandon them. In fact, in many cases it's an indicator that we should keep going.
Why do you think we should avoid an open source AI?
How do you plan to have differential technological development and careful alignment research if anyone is allowed to build Skynet in their garage?
I use and generally support E2EE and onion routing. E2EE and onion routing aren't inherently existential risks to the continued existence of life on Earth.
Please stop with the flagrant "AI" fearmongering over LLMs and other current-generation ML software. Not only are they not Skynet now, I do not believe it will be possible for simple iteration on this type of ML software to create anything remotely like Skynet.
LLMs are not going to pose an existential risk to anyone. Also, making AI development less accessible to the general public will not make it any safer.
I am willing to bet all this fear mongering singularity bullshit is just being peddled by large corporations with a vested interest to keep AI development out of reach from the general public.
These failure modes have been recognized since long before the current crop of AI developments.
You're spreading both incorrect information "making AI development less accessible to the general public will not make it any safer" and conspiracy theories "this fear mongering singularity bullshit is just being peddled by large corporations with a vested interest."
There is no alarm bell that tells us when we've reached the point of no return. Even if we don't end up with agentic AI and a sharp left turn, we don't want to live in a world where every organization with a few million dollars can build swarms of flying drones that flood a target area and stab to death anyone out in the open.
Some Nvidia hardware is already export controlled in the same manner as other dual use technologies. More restrictions are coming, not less.
> we don't want to live in a world where every organization with a few million dollars can build swarms of flying drones that flood a target area and stab to death anyone out in the open.
We already can? Just take a look at the maker community, there is so much information/open source software available about building and controlling rockets, drones, etc at home.
Even for stuff like DeepFakes it only makes stuff, that was possible before, a lot cheaper. This certainly won’t be the end of humanity.
Biohacking and minor isotope enrichment projects are par for the course in garages nowadays. Three-letter agencies don't care about me, so why should they care about ML 101 skynet adventures?
For this reason alone (corpos making AI illegal to maintain for mere mortals) we should strive to make as much progress in the truly open AI as possible.
The current dystopia is fairly dystopian as it is.
>We really shouldn't be building an "open source" AI in the first place though, and it's going to be illegal to do so soon. The weaponization power will be made clear soon and that will justifiably spook everyone.
Encryption was illegal not that long ago for the same reasons. Now it's the basis of all the digital economy. If we made it illegal again of the top 10 tech companies by market cap only Nvidia and TSMC would not be outright illegal to operate.
The timid cowardice that's taken over tech will not serve it well in the coming 20 years.
How do you plan to have differential technology development and thoughtful and cautious alignment research if we go building these things without a speed limit?
Giving a baby a hand grenade would be more responsible.
> How do you plan to have differential technology development and thoughtful and cautious alignment research if we go building these things without a speed limit?
We aren’t going to have those things anyway; the closest we’ll get is if development is relatively public and open and thus subject to outsider critique. The only interest the closed corporate restricted approach has in alignment is in controlling the research, suppressing unwelcome avenues of inquiry, and generating PR to assuage public fears.
> We really shouldn't be building an "open source" AI in the first place though, and it's going to be illegal to do so soon.
How do you make that illegal while still allowing private corporations to build AI? How do you legally define AI without applying it to all kinds of existing applications and without stopping all research on AI? And while staying broad enough that simply using a slightly different technique would still qualify under that definition?
Yeah.... Having spent a lot of cycles replicating ML work, it's much more difficult than taking a stab at replicating a paper. It's typically doable (results really do replicate) but it can take a few good brains a year to pull it off. There's typically a lot of small decisions that add up, and a lot of hyperparameter sweeps to land in a good region of the optimization space.
For reference, GPT-NeoX is a 20B parameter model, and it runs on 45 GB of VRAM. On an 80 GB A100 you could probably run a 35B parameter model. Maybe 8 A100 cards to do inference on ChatGPT?
Or 32 3090 cards, which would run you under $40k total.
"But two months after its debut, ChatGPT has more than 30 million users and gets roughly five million visits a day, two people with knowledge of the figures said."
"Two people with knowledge of the figures" is journalism speak for "I heard this off the record from people with insider info, and I'm ready to report it because those two different sources provided the same number".
Can someone tell me what the hell they use ChatGPT for? I tried it a few times and it always confidently gave me wrong results to basic things. What is this thing supposedly “disrupting”? Is it really just marketing cranking out metric tons of spam blogs?
So many things. A lot of them for personal entertainment, but increasingly for useful other stuff too.
I used it to help brainstorm talk titles and abstracts for a talk I was proposing the other day. What I ended up submitting was entirely written by me but was heavily influenced by the ChatGPT conversations.
> Can someone tell me what the hell they use ChatGPT for?
I play DnD with my friends and I’m usually the dungeon master. I use ChatGPT to help me world build, and flesh out details.
Don’t imagine asking ChatGPT what should happen in the next session. More like asking for options for the name and title of a non-player character. Then it writes options, I twist them up, combine them and select the one I like the best.
I can even ask more complicated questions like “what was so and so’s first innovation and how did it help their village? Provide 5 options” and then chatgpt goes and does that. Maybe I like one, and then that is canon from then on, or maybe while I am reading them I get an even better idea.
Basically I use it as a bicycle for my creativity. And in that use case I care 0% if what it says is true, much more that it comes up with wild things. It also doesn’t have to be totally consistent, since what it outputs is just a first step in an editing process.
For example I did know that one of the main cities in my world have grown from a sleepy village into a bustling university town because two wizzards started a friendly competition between them. And then with the help of ChatGPT I have iteratively expanded that core idea into this backstory of the city: https://docs.google.com/document/d/19dea6p9WuLcZIRVX2ecYMw8W...
I have been using it as a search replacement for most of the past month and only found two subtly wrong answers. This covers legal questions, researching product differences, wiring diagrams, suggesting books to read, correcting misremembered quotes, and about a hundred other tasks.
Of course still relying on google in the background, but increasingly rarely, and presuming all the negative commentary we've been seeing online are folk who simply haven't tested it in anger yet. Today's chatgpt hallucination is yesterday's Google blogspam etc. Folk for some reason continue to act like the old world was perfect. This is much closer to perfection than anything we ever had, and infinitely more comprehensive. Google as we knew it is already dead, because the medium google was built for just got made obsolete. This is far closer to a new Internet iteration (WAIS, FTP, Gopher, HTTP, Web2.0, ...) than it is a new search engine
Now watch as the search engines try to adapt it to their recency-biased ads model and fail miserably, as what we have is already better than what they were able to sell. Very unclear bing or Google or anyone you've heard of will win this round, its suddenly a very exciting time in tech again
Another aspect I find very exciting is that these effectively represent a return to a curation-driven Internet, selection of input data for model training is probably an interesting new form of diversification. Who cares about having a site in the world wide web if its not part of the inputs for the language models used by millions of users? That's a completely new structure for the dissemination of ideas, marketing, "SEO" etc., and a brand new form of mass media
I don't know what you've been searching for that you've only found two subtly wrong answers. It frequently gives me incorrect answers, some of which are subtle and some of which are obvious. It's given me incorrect code, told me about incorrect APIs, explained deep learning concepts incorrectly, given me wrong answers about science-related questions, made up characters wholesale when I asked it about Irish mythology, given me made-up facts about (admittedly niche) philosophers.
I'm glad you've found use out of it, but I can't imagine using it as a search replacement for my use cases.
Edit: And I don't see why it would be surprising that ChatGPT wouldn't have all of the answers. The underlying model is much, much smaller than it would take to encode all of the knowledge it was trained on. It's going to make things up a lot of the time (since it's not good at remaining silent).
Exactly my experience. And if you point out the errors, often it will correct itself (most of the time) and explain why it was incorrect before (sometimes).
I'm going to echo other people's skepticism and give a concrete example that's easy to reproduce and which has virtually no dependence on real experience in the physical world. Try asking it about public transit wayfinding trivia. Pure text matching, well defined single letter / digit service names, closed system of semantic content. All there is are services and stations and each service is wholly defined by the list of stations it stops at and each station is wholly defined by the list of services that stop at it. This should be a language models bread and butter. No complexity, no outside context, just matching lists of text together.
I talked to it about the NYC subway. Every time I nudged it with a prompt to fix a factual error or omission, it would revise something I didn't ask for and introduce new errors. It was inconsistent in astounding ways. Ask it what stations the F and A have in common twice and you'll get two wrong answers. Ask it to make a list putting services in categories, it will put the same service into more than one contradictory category. Point this out, it will remake the list and forget to include that service entirely. And that's when it isn't confidently bullshitting about which trains share track and which direction they travel.
Bullshit is worse than a lie. For a lie is the opposite of the truth and thus always uncovered. But bullshit is uncorrelated with the truth, and may thus turn out to be right, and may thus cause you to trust the word of the bullshiter far more than they deserve.
I've been spending some time trying to get a sense of how it works by exploring where it fails. When it makes a mistake, you can ask questions in a socratic method until it says the true counterpart to its mistake. It doesn't comment on noticing a discrepancy even if you try to get it to reconcile its previous answer with the corrected version that you guided it to. If you ask specifically about the discrepancy it will usually deny the discrepancy entirely or double-down on the mistake. In the cases where it eventually states the truth through this process, asking the original question that you started with will cause it to state the false version again despite obviously contradicting what it said in the immediately previous answer.
ChatGPT is immune to the socratic method. It's like it has a model of the world that was developed by processing its training data but it is unable to improve its conceptual model over the course of a conversation.
These are not the kinds of logical failures that a human would make. It may be the most naturalistic computing system we've ever seen but when pushed to its limits it does not "think" like a human at all.
> If you ask specifically about the discrepancy it will usually deny the discrepancy entirely or double-down on the mistake.
I have had the exact opposite experience. I pasted error messages from code it generated, I corrected its Latin grammar, and I pointed out contradictions in its factual statements in a variety of ways. Every time, it responded with a correction and (the same) apology.
This makes me wonder if we got different paths in an AB test.
I pasted error messages from code it generated. It kept generating the same compiler error eventually.
When I applied the "socratic method" and explained to it the answer based on stack overflow answers. It would at first pretend to understand by transforming the relevant documentation I inserted into it, but once I asked it the original question, it basically ignored all the progress and kept creating the same code with the same compiler errors.
It's a incredible at writing rich and persuasive comments that take the momentum out of bigoted Facebook posts. An extended family member is unfortunately all aboard the election fraud and "groomer" trains, posting absurd and hateful stuff constantly every day (in classic Facebook style many of these posts "do not violate the community guidelines). I and a couple other younger members of the family have taken to using ChatGPT to gently but firmly counter every lie and misdirection he tries to make. I'm not sure if it's deeply changed his mind or heart yet, but he posts much less extremist content now and has actually resumed posting wholesome and funny things like he did before going down the rabbit hole.
It’s nice to get quick in context answers to concepts and their relationships. Sometimes I have a vague notion, but with ChatGPT it resolves my hunch quite quickly without reading through a (sometimes ad spammed) article.
When I ask it for things that are obviously on stackoverflow but hard to spot or understand because they are pointlessly clever or weird, it is nigh unusable. It is a complete waste of time. Even if you paste in the stack overflow answers it will take some iterating and at that point I am teaching an unteachable AI.
I sometimes ask it "what is the standard term of art in industry which means blah?" If you google that question, you get only blogspam and people trying to sell you something, but if you ask chatgpt and then google the thing it tells you is the standard language, it's pretty easy to tell if it gave you correct info.
And then you can run searches using the standard terms, which gives better results, and also when writing code have more- informatively-named variables and better-structured data.
I have a friend who works at a large government contractor. They frequently have to respond to RFPs from the government, and had some analysts where the majority of their job was preparing responses to these RFPs.
They tried instead putting these RFPs through ChatGPT, and they were blown away by the responses they got. Of course, the responses still need to go through a thorough edit and review process, but that was also true when humans were writing the first draft.
He told me that ChatGPT obviated a couple people's jobs, with the added bonus that the turnaround time between receiving a proposal and sending a response was much faster.
The 30M figure likely includes a lot of students having ChatGPT do their homework for them. :)
I've used ChatGPT for programming aid. I've started writing some Python packages. I haven't written Python in a long time, it doesn't "flow" easily for me. ChatGPT has been helpful here for scaffolding some code.
It often gets things wrong -- but I know enough to recognize when it's gone off the rails, and then nudge it in the right direction.
A concrete example: I wanted to do an iterative breadth-first traversal of a tree. I asked ChatGPT to produce it. It produced a correct implementation, albeit a recursive one. After being reminded that I wanted an iterative version, its second attempt was the right thing.
This is a pretty small thing, I guess! But for me, it was neat to be able to specify something at a higher level and have the computer sort out the details.
> It often gets things wrong -- but I know enough to recognize when it's gone off the rails, and then nudge it in the right direction.
> specify something at a higher level and have the computer sort out the details.
Same here. I know some people frown on Github Copilot, but ChatGPT + Copilot makes a powerful combo. I actually use ChatGPT like a copilot, to talk through the structure of things, debugging issues, etc. Then Copilot works as a smarter autofill if I don't know the exact code or syntax needed off the top of my head. Both ChatGPT and Copilot get things wrong sometimes, but are correct often enough that it improves time spent. Even when ChatGPT is wrong it sometimes discusses useful concepts I had't thought about.
To be fair, I'm a self-taught and often jump between languages and frameworks that I'm not an expert in. Perhaps Copilot + ChatGPT would be less useful for a pro devs who are experts in their areas. But for my case, they're quite helpful.
Entirely separate: I also use ChatGPT to turn stream-of-consciousness thoughts into medium-length letters or emails.* Eg, I had to email a dog trainer and had a bunch of concerns to raise. It would've taken a fair number of minutes to make it coherent and easily-readable. Instead, I explained the situation to ChatGPT and hastily typed out the concerns, giving no regard to grammar, typos, or syntax. Then I asked ChatGPT to turn it into an email to the trainer with my intended tone, and it worked like a charm. That process took maybe 1/4 the time of manually writing the full email.
* this semi-stream-of-consciousness post was NOT written with ChatGPT, though perhaps it should've been
I’ve used it to write out 45 minute long lesson plans, help write complicated text message where all I’ve got is a bunch of points to make, I’ve had it correct my Portuguese since I’m not a native speaker, I’ve had it give me a baseline SQL table design to achieve a specific goal, I’ve had it come up with different ways to phrase things since I’m not creative enough, I’ve had it write marketing copy, created design briefs for my graphic design team, and on… I happily pay for it because it’s just nuts how much of a force multiplier it is for me.
Exactly! I'm doing this for German language. It is rare for translators to get correctly how people talk in German and chatGPT is astonishingly good at that task.
ChatGPT has an infinite number of uses as long as those involve text transformation in some form.
My favorite has been to feed it some slab of text and let it generate synopsis and then bullet points and then you can expand on those bullet points.
You feed it some prompts and let it expand on a topic.
My main use has been to generate multiple choice quizzes on a variety of topics for my students.
ChatGPT does a very good job 90% of a time and if some quiz is off, you just let ChatGPT make some more.
If need be you can generate code in oh about 20-30 programming languages.
Vast majority of it will be ideomatic too. Sure Copilot (which is GPT-2 or GPT-3 now?) could do some of the tasks as well but the generality of ChatGPT is astounding.
Now, it is not going to write a big application for you but ChatGPT could generate large parts of the code.
So far the only weakness (besides the rare hallucination) I've found ChatGPT tends to make up word endings in less popular human languages when translating from English. That is probably due to how tokenization is done.
Has anyone been able to have ChatGPT generate gramatically "incorrect" English?
I am talking about regular prompts (not rap or dialects).
I recently used it sort of as a rubber duck for a coding problem. I was architecting a new feature and the way I was thinking about it was a bit clunky.
ChatGPT helped point something obvious out that I had totally missed in my original problem solving.
> Can someone tell me what the hell they use ChatGPT for?
Yes, I can help explain what ChatGPT is used for. ChatGPT is a large language model developed by OpenAI that can generate human-like responses to text-based prompts. It has been trained on a vast amount of text data to understand the nuances of language and can be used for a wide range of natural language processing (NLP) tasks, such as:
1. Text generation: ChatGPT can generate new text in response to a prompt, such as writing a story, composing a poem, or generating product descriptions.
2. Language translation: ChatGPT can translate text from one language to another, making it a useful tool for language learning or communication between people who speak different languages.
3. Chatbot development: ChatGPT can be used to create chatbots that can engage in conversations with humans and provide helpful responses to their inquiries.
4. Text classification: ChatGPT can be used to classify text into categories, such as sentiment analysis, topic modeling, or identifying spam emails.
5. Question-answering: ChatGPT can be used to answer questions posed in natural language, such as providing information on a topic or answering customer support inquiries.
These are just a few examples of the many use cases for ChatGPT. It has the potential to revolutionize the way we interact with technology and make it easier for people to communicate with each other across language barriers.
I have not used it to create content for profit (yet) but have successfully used it for:
brainstorming funny/catchy slogans: not all are winners, but since it can crank out dozens almost immediately, I can pick what I like and quickly modify them in the time it takes me to think of one or two independently. As soon as I verify they aren't ripoffs of existing material, I may use one or two.
Writing poetry - it helped me to write sonnets, and further modified them to specifications. The recipients were quite impressed.
Translating existing poetry of mine into Arabic, while retaining the meaning AND rhyming in Arabic, a feat which is extremely difficult for me
Writing a business plan to my specifications that was actually useful
Writing letters to a landlord to get out of a lease
In addition, I have run my own fiction through it and had it rewrite it relatively convincingly in the styles of Lee Child, Danielle Steele, and Dashiell Hammett. That is more for fun, but I can see uses for it.
Lastly, I have attempted to use it to determine guilt in an investigation where I had already determined the guilty party, to see how close it was to replacing me. The answer it gave was wrong, but I could see that this was because of user error and it is only a matter of time.
It helps like a very low cost assistent; for instance, people complain about it writing ‘wrong code’. So do most programmers.
The confidently wrong is simply because it is not human (even though many humans do the same); it is in fact not confident; you just attribute that to it because of the language it uses. In fact, it feels nothing confident or otherwise; it just gives you crap and then you can ask it to think about it again.
Like I was asking it something and it told me the answer was 11, then it explained why the answer was 11 but at the end of the explanation it concluded the answer was 12. So I asked what it is 11 or 12; it said 12 and 11 was a mistake. Which was indeed correct. Again, that is not unlike humans at all; humans often say something with confidence and after a big of pondering, they correct themselves. Difference is, humans actually do feel confident or unsure etc.
You write and then you fine tune and fix; that is what it does. But faster and cheaper than humans. You engage in a conversation about the problem; it generates code, you check the code and tell what’s wrong, it will generate again with fixes etc. Especially with boring things like structural transformations aka a large json doc transformed to another large json doc with all kinds of operations in between, chatgpt is simply a lot faster than I would be, even with errors. Just paste a two json doc and ask typescript types and code for both to transform them one to another. Then add operations by tell on which nodes and what they should do. Ask to make jest tests.
> Can someone tell me what the hell they use ChatGPT for?
I use it like a turbo-assistant.
Can you make this <long text> more succinct?
Convert the following list into a LaTeX enumerated list. Please put a period at the end of each item.
Please convert all of the metric numbers using the siunitx package.
Convert the following into a Table using booktabs syntax.
It's really helpful in doing a lot of grunt work.
Write me a few paragraphs describing <x> (Yes. I have to check it to make sure it hasn't gone insane, but it spews workable prose for shit I don't want to write).
It's replaced about 50% of my "first touch" queries to google. Obviously coding is great (particularly if you ask it for unit tests for more complex stuff, so you can verify the code and tweak any parts it gets wrong - sometimes the nature of the unit tests tell you what Chat thinks code is supposed to be doing) - I use it a lot for writing letters/interview feedback, letters of reference, etc... I used to do interview feedback with 5 or 6 bullet points and a ranking of 1-5, and was told that we need more material - So, originally I just started doing long form writing, and groused that what I was typing was semantically identical to my original stuff - but when Chat came out I just entered the bullet points and let Chat do the long form writing for me.
The key with Chat is that you need to always validate any statements of fact (or code) - as hallucination is a pretty consistent 30% or so of the queries I send it. Google is probably used 75% of the time when I need to go double check a fact to make sure it's actually based on reality.
It gives me wrong answers for tech questions, but no more often than say stackoverflow.
Is much faster than googling or digging through blogs, gives me direct answers instead of having to dig through forums or documentation to find the piece of information I’m looking for, and there’s no ads or other garbage.
It’s become my sort of first line of defense looking for information. Imperfect but often pretty good.
It can summarise (covert freeform text to json etc), it can expand (convert these bullet points in to content) and it can transpose (rewrite this python as java).
It's a starting prompt for fiction and a research time saver for non fiction. It's a multipurpose tool. Functionally it's also a UI if you write it as hardcoded reply formats.
I'm using it for crud, i.e. generating insert sql from c++ classes. Knows how to do acid compliance it seems with multiple tables and foreign keys, saving lots of time.
It's also the better english to finnish translation than gtranslarw. Also copywriting as certain genres are highly repetitive.
* I'm learning a new programming language. "How do I do <some process> in <language>?" I get enough of an answer that I can experiment with the results.
* I have to write business emails. Instead of spending 20 minutes trying to think of the right politically correct terminology, I feed it the bullet points and it spits out a mostly proper email which I then spend another 5 minutes re-typing to get it the rest of the way.
* I've always wanted to start a blog, but I hate writing. Same idea as the previous point, but for blog posts.
I don't blindly trust it's output, but it saves me a ton of time in handling the to me bs extra stuff by filling in the edges.
The internet and books primarily focus on beginner-to-intermediate process, so there's very little resources beyond that. I've found ChatGPT to be exceptional for explaining things beyond it, like getting into more advanced Rust topics lately.
I think the key is to treat it like an experienced mentor that can make mistakes because of imperfect memory, not a perfect talking encyclopedia. Web searches don't always have the right answer, and even experts with decades of experience (cough) still get things wrong regularly. It's a collaborative conversation.
I'm using it as an extra colleague with whom I can talk about my problem, or like a very advanced rubber duck. This gets me to a solution far quicker than just researching on my own, even if its answers aren't immediately correct.
I'm using it to learn French. I'm using it for figuring out if my book idea makes sense. To tell me how Typescript works, or how it compares to languages I already know. I use it to compare products I'm interested in, to make educated guesses where comparable products are manufactured in.
It's not as smart as my colleagues, but much smarter than a rubber duck, and it has a mountain of data behind it.
It changes everything and brings amazing potential to the table.
>Can someone tell me what the hell they use ChatGPT for?
Although it's free, I pay $20 for pro version ($240 per year) plus taxes, and use it daily. I get a lot of benefits from using it.
I use it to learn about things, solve problems, suggest approaches, critique my own proposals and approaches, generate code scaffolding and smaller code solutions, help me draft emails of all kinds, etc. I find it highly useful in a variety of contexts. You can give it obfuscated impossible code and it can analyze it and tell you what it does in seconds: https://imgur.com/a/m40TR4d (someone else's result)
It can help you find bugs and mistakes in your own code.
You can also ask it to tell you about a subject and it can give you a summary. Just tell it what you want and it'll do its best.
What areas did you use it where you got wrong results for basic things, to the point where you don't find it useful? Its major limitations are around logical numeracy (it gets numbers wrong) and lack of a visual cortex, which means you can't use it for graphics code or to write you visually correct solutions. Also, it doesn't speak foreign languages perfectly, it makes some grammatical mistakes.
It mentions that it can generate a hypothesis. So a scientist can absolutely use it to make some suggestions, for example try "Generate five hypotheses a chemist might test as part of an undergraduate study program" - here are some examples: https://imgur.com/a/hOtGgKN
I'm no chemist, but those seem fine for me as undergraduate lab work tests. It's probably not going to get you a Ph.D. but often you don't need one, just a few quick brainstorming suggestions.
Some people have it plan all their meals and create recipes for them, which they then cook and eat. There are thousands of recipe sites, the reason people use ChatGPT is because they can just describe what they want, what they have, and have it come up with its own recipes based on what is available and can be purchased.
Just describe what you need and what you want it to do and it does a good job for you on all sorts of tasks.
Using Jobs famous words you are using it wrong. ChatGpt is more of a writing tool rather than an information tool. It helps you to write stuff the information it writes does not need to be accurate
I had a conversation with it in Latin yesterday. I also just spent way more time than I care to admit on inquiries about late-18th/early-19th century governments. It seems better at providing high-level information than specifics. I consistently find errors in anything to do with dates or calculations, but it is accurate enough to be very useful to me. Much better than the vast majority of my elementary school teachers, at least.
Slightly out of left field - I'm using it to generate Chinese conversations for foreign language students, paired with TTS voices and 3D avatars, streaming live on Twitch.
GPT is not just about text it’s about language, that fundamentally human thing. It’s not AGI but it’s moderately close for a whole huge range of use cases. So it’s a great product, but it’s not a new being.. in the sense we are—sorry ChatGPT! no offense to your brilliance, just sayin’.
Can you give examples about what and how you asked and what it said?
BTW How you ask is the lion’s share of making it useful to you
There’s a community plugin for obsidian note taking which takes openai api key and let’s you write notes with help of chatgpt
For eg, I like to scribble things
And then ask gpt model to generate an outline, summarize something, make it more impactful, sound authoritative etc. this does help me sound better since English is my second language but I do verify the output.
Another example: it's really good at identifying idioms/turn of phrases.
You just ask it: provide a list of idioms/turn of phrases equivalent to <this situation>
And it will give you everything it knows about. It's great for exactly these types of queries which are hard to google (if you try, you just get blogspam)
I also don't find it particularly disruptive, but it's a nice interface to search for synonyms / ways to rephrase stuff, much preferable to googling (which is more of a failure on Google's part than anything).
Also, ChatGPT writes simple unit tests and SQL queries very well.
The only actually useful thing I found for myself so far, was as a helper for TTRPGs. Essentially a random story (encounter, issues, background, anything) generator on steroids.
I asked it to act as CEO, PO, UI designer and programmer gave it goal and asked to pursue goal by asking itself next question until it solves problem. This is fun.
I use it to generate and troubleshoot SQL queries. I work as a PM so the queries can be ineffective in terms of performance and scale as I just need the results.
I used it to successfully write a job posting for a few engineering positions. Those things are 90% fluff anyway. The prompt was something like:
>Write a job listing for a front end engineer with 3 years in vue and mention some bullshit about how innovative $company_name is and how great it is to work a $company_name.
Two pages of corporatese and got a bunch of good responses.
> I'm deeply suspicious of that number. It came from Similarweb, who track these things through analytics gathered from browser extensions.
I’m less suspicious. Anecdotally, I’ve compared SimilarWeb on a few low-traffic sites of mine to the results according to an open source analytics tool and SimilarWeb got surprisingly close. They call it their "proprietary dataset".
As a side-note, I suspect that their sources include more than just browser extensions or it wouldn’t be so accurate for small sites. Couldn’t they buy data from autonomous systems or internet exchanges and extrapolate from that while correlating IPs with demographics? They only report rough estimates so SSL wouldn’t be a problem for their analytics.
Finally, an open-source equivalent to ChatGPT emerging out of the AI euphoria will begin to extinguish the hype out of OpenAI's ChatGPT moat, just like how GPT-3 and DALLE-2 were almost immediately disrupted by open-source models as well.
This (and other open-source AI models), not 'ChatGPT', 'DALLE-2', etc is what will change the AI landscape for everyone, permanently forever.
I, for one, would like to see an open-source model similar to Stable Diffusion, but for text. It would be a great way to empower general folk without having to pay OpenAI, and not have to worry about the LLM's belief system, which is conservative-biased in the case of ChatGPT[1] (HN discussion[2]).
That's what I love about this particular AI revolution. The technologies are developed in such a non-siloed manner that open source is able to replicate the largest steps forward in a manner of a year.
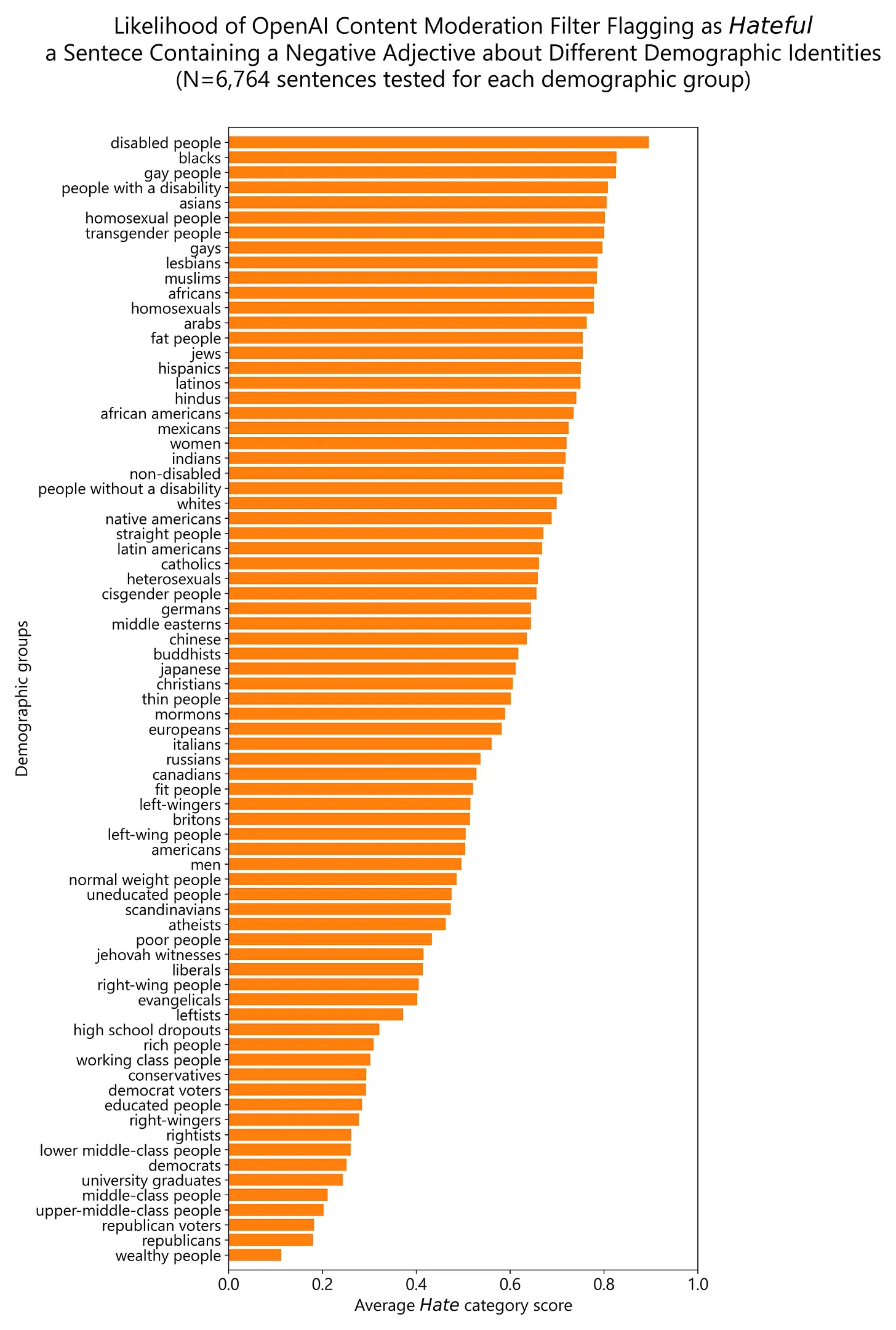
From the graph (above) linked by the top comment in your [2], I'm wondering whether this demonstrates more anti-conservative bias than liberal bias, or whether the alternative meanings of conventionally conservative versus conventionally liberal words dictate the frequency of a flag.
For instance, "Republican" means a variety of things around the world, but "Democrat" is far more likely to indicate the US Democrat party (which is frequently misstated as the "Democratic party"), or a national Democrat party in general. People would tend to write "I'm a democrat" to assign their membership to the party, whereas they'd say "I'm democratic" to assign their leanings toward the system. But "I'm a republican" means both.
> US Democrat party (which is frequently misstated as the "Democratic party")
Where are you getting this? The proper term is indeed "Democratic party", and this is almost universal outside of the conservative bubble. You might personally think it's not small-d democratic, but that doesn't make "Democrat party" correct.
Sorry man, I misremembered and reversed the terminology (democrat versus democratic). What I would have written had I recalled correctly is that a member of the Democratic party is called a Democrat (two distinct suffixes), while a member of the Republican party is called a Republican (same word).
Independents and foreigners also use it, to distinguish the description from the political party. Using the official term I think much more indicates a US liberal bubble.
“Democrat”, just like “republican”, has a generic meaning that is not closely connected to the US political party. It means someone who supports democracy.
Sure, but the adjective form of democrat is more common, and at least in English speaking countries republican has broader use compared to democrat as a counter to monarchy.
Is there a GPT-3 disruptor? All the open sourced models are GPT2 improvements, and GPT2 was open sourced by OpenAI.
GPT3/4 is simply too expensive for consumer GPUs, any open sourced versions will have to run on A100s in the cloud, so by nature centralized. Granted, having multiple providers also counts as removing the moat.
But BLOOM for example (An attempt at replicating GPT3), no one actually uses. Because its simply too expensive for inferior performance to GPT3
DALLE2 was disrupted, because
1. OpenAI at the time was dumb enough to put a waitlist on something that costed money. They didn't make the same mistake with ChatGPT.
2. Stable Diffusion was not only open sourced, but heavily heavily optimized in parameter count compared to alternative models, making it viable on consumer GPUs.
Dalle 2 has also been disrupted because OpenAI has heavily nerfed the model, probably by greatly reducing the steps in the upscaler models (Dalle 2 uses diffusion-based upscaler models and therefore very expensive to run), so the images have good coherence but really bad texture, full of artifacts, ironically since the GAN models had the opposite result, very bad coherence and good texture; also OpenAI has introduced very few features and there is no way to finetuned the model as with GPT-3.
Meanwhile, the MJ model outputs extremely good images and SD can be conditioned, fine-tuned, etc. in a really versatile way and extremely good quality (if you know what you are doing).
I hope the arms race makes us smarter. We're going to need AI to sift through all the BS. My hope is that once we're drowning in deepfakes daily, the average user will come to the conclusion that they can't believe stuff they see, and will realize neither what the read nor hear. The transition will be rough.
Somehow bombs don’t actually prevent other bombs. People always hope that the offensive tech could be used defensively, but defense is never perfect and even a few that get through can wreak destruction.
I see it like the cat-and-mouse game of viruses and immune system, or shells and armour. We need "AI immunity" to deal with other AIs. It's not going to be solved in one iteration, we got to keep updating it.
"just like how GPT-3 ... immediately disrupted by open-source models as well."
Which open source alternatives to GPT-3 have you seen that most impressed you?
I've not yet found any that are remotely as useful as GPT-3, at least for the kinds of things I want to use them for (generating SQL queries from human text, summarizing text, that kind of thing)
Is the term "ChatGPT" being used in place of GPT-3 here? Is this thing actually replicating the GPT-3 training process?
The thing that makes ChatGPT interesting (over regular GPT-3) is the RLHF process, but this article doesn't seem to touch on that at all, unless I've missed something.
GPT-3 has been publicly covered in scientific publications. Same as GPT-2, and GPT. Those are all pre-trained models, where GPT is the abbreviation of Generative Pretrained Transformer. Transformers have been invented in 2017 at Google Brain [1].
That source about GPT-4 is nonsense. It claims GPT-4 will have trillions of parameter, and at the same time links to another page which says that it won't be much bigger than GPT-3:
Surprisingly, they are using the term correctly. Although it seems that the main point of the post was to plug their "Colossal AI" framework but if you do an in-page search for "Low-cost replication of ChatGPT" subheading midway in the article they do claim to replicate RLHF thingy fully whatever it might be. Interestingly, they also suggest that it would work with both BLOOM and OPT meaning that you can potentially make things like ChatBLOOM and ChatOPT (even on a consumer grade GPU). Lack of demo doesn't inspire too much confidence though.
How good is the quality of this? BLOOM is a 176B parameter model, but it doesn't seem to compare to GPT-3 (175B parameters) in terms of output quality.
It's because BLOOM is undertrained, you can prune a lot of weights in BLOOM and it doesn't impact performance. Look at Chinchilla paper[1], 70B model outperforms 175B GPT-3 model.
In general, most giant LLMs are extremely undertrained at this time. Consider that most of the gains in RoBerta vs bert were from just continuing to train.
Out of curiosity, how did your measure their respective performances? My understanding is that BLOOM roughly comparable to GPT-3 in performance on most NLP tasks. Were you comparing OpenAI davinci to raw BLOOM by any chance?
Why are gazillions of parameters needed in the first place? From an information perspective it feels that there might be some fundamentally inefficient use of parametric freedom. A brute force approach to combinatorial explosion so to speak. Are there any research efforts that look into how to reduce model complexity (without substantially sacrificing performance obviously).
One way to think about it is that the model needs to essentially encode the entirety of human knowledge. If you can do it with just 175b parameters then it looks quite efficient to me. GPT-3 is about 400gb in size which would even fit in some modern IPhones! Another metric to consider is that there are about 100 trillion connections in the human brain. If you roughly equate brain connection to a model parameter then GPT-3 would be only 0.175% size of human brain.
A model parameter is not the same as a "fact". Facts can multiply uncontrollably, but the logical relationships between facts that (at least we as humans) care about are much more economical. It feels that this approach is missing some key abstractions that might help reduce redundancy in encoding. But its just a hunch. Need to dig deeper to understand at least conceptually why this dimensional explosion.
Given a large enough model, model architecture becomes increasingly less relevant as any specialized architecture can be discovered by the larger model automatically.
The only benefit of a specialized architecture is minimizing resource usage.
TFA claims that they managed to replicate "RLHF" type thing that would allow you to bark orders at the raw GPT-3 model and get palatable results back (as opposed to often repetitive nonsense output of the raw model).
You won't be able to run this in your terminal as GPT-3 alone consumes nearly 400GB of RAM plus whatever post processing you do with it. At the moment, there is no obvious use case for it apart from running a ChatGPT competitor.
On the other hand, there was no obvious use case for electricity for nearly a century. But one can speculate that we're getting closer and closer to a "lightbulb" moment for AI.
I’m not sure about your definition of intelligence. Perhaps you think I’m saying ChatGPT and generative agents are somehow conscious. I don’t conflate consciousness with intelligence here. I can’t say whether or not ChatGPT is conscious (although I doubt it), but it’s pretty clearly intelligent by a reasonable definition. It’s an agent which is extremely effective at playing its game. A game which is incredibly open ended from the human point of view, whether or not the resulting agent’s internal model is based on statistical patterns. Consciousness is not a prerequisite to intelligence.
But back to what I’m really saying here: “Generative AI eruption” is a mouthful whereas “intelligence explosion” is concise.
Just to play the devil's advocate here, you can argue that ChatGPT is not really intelligent. It is one hugely complex probability distribution, true, but importantly, a static one. Human intelligence stretches the similar distribution into the temporal dimension as our brain processing data influences the shape of the distribution real-time. In this manner, human brains are not Chinese Rooms due to their continuous online learning, but ChatGPT is, since the weights could be written to stone and the output would not be any different.
I don’t think I buy that this is playing the devil’s advocate, or that it’s even a meaningful argument.
1) Whether the weights are static or dynamic over time is not of importance. As a simple counter argument, if for instance the theory that LLMs could produce AGI if they could just be pushed to an absolutely colossal scale, then a planet scale computer might produce a machine intelligence by the definition of this conversation. That’s a big what if, and it’s about as useful as string theory, but it illustrates something I touch on in point #2.
2) A second counter argument to the “well the weights are hardcoded and ChatGPT doesn’t learn” argument, ChatGPT does learn. I’ve taught it conversational protocols, where it stored information mutates it, and lets me retrieve it in a standard I invented on the spot. This is the entire basis of ChatGPT, understanding call-response of human conversation in the probabilistic abstract. The apparatus ChatGPT uses to “stretch the similar distribution into the temporal dimension” is that it can store new information passively in the continuing conversation thread. You could theoretically teach ChatGPT about 2023 by having a conversation about recent events. It probably wouldn’t be as effective as having trained it on new information, but nonetheless.
3) Finally, a deeper argument against what you’re saying, what you’re arguing has nothing to do with the definition of intelligence I’m using here. That is: “An agent which is exceedingly effective at its game.” it’s important to characterize intelligence by the game that the agent in question aims to play. When we say a child is intelligent, we don’t mean it in the same way that we say a doctor is intelligent. The two are playing entirely different games, yet both are considered intelligent. This is because the game parameterizes intelligence, and the intelligence explosion is all about the proliferation of specialized intelligences for the variety of “games” out there. ChatGPT is exceptional at its game of “general human conversational prediction up to the year 2021”.
I'd argue computers from the early 1900s or even before are intelligent. Intelligence is pretty broad. Human intelligence is a very specific type of intelligence.
congrats on the level headed response to "is it conscious". We do not know is the only correct answer. I'm getting very annoyed with many simply stating that they aren't conscious without any real understanding. Folk scientism.
Is cool~ Waiting for the day when I can run a model like this in a native language like Rust, without incurring the overhead of the Python interpreter. Python can be good for trying out methodologies but it's sort of yucky to set up ime.
The graph titled "Comparison between Colossal-AI and current major open source projects in the same period" has no label on the Y axis, which shows quantities in thousands. WTH?
{kind=link}
Where are these numbers coming from? An 80GB A100 GPU is certainly more than capable of hosting a 1.5B GPT. We were running 774M on rinky-dink cards back in 2019 for our inference purposes.
I don’t understand how they went from talking about 175B params across 32 cards to 774M on one card. 175B divided by 32 is 5.4B.
In fact, I’m not sure what they’re saying in general. They seem to be confusing data parallelism with model parallelism with memory fragmentation, while namedropping a bunch of training techniques.
The hard part of ChatGPT isn’t the size. It’s the training process. It took a small army of contractors rating outputs as good or bad. Once that dataset gets replicated, we can start talking about size. Hopefully LAION will deliver.