Keep in mind that a substantial portion of users now use ad blockers such that a lot of URLs used for analytics like this are blocked.
Consequently, you can't actually expect to capture 100% of these analytics events nor even expect the percentage captured to stay the same over time since the filter lists are very regularly updated and users enable/disable different ad blockers over time.
More broadly speaking, once you have sent a webpage to the user, you should not expect anything from the user's browser. They may or may not allow whatever arbitrary JS you have on the page. They may even intentionally give you bad data (e.g. hijack the payload to give you intentionally malformed data).
edit: even more broadly speaking, there's additional reasons why you can't expect to receive these kinds of callbacks: consider what happens if a user loses connectivity between loading the page and them navigating away (e.g. their phone loses service because they went into an elevator before navigating away)
> Keep in mind that a substantial portion of users now use ad blockers such that a lot of URLs used for analytics like this are blocked.
How sure are we about this? I'm pretty sure it depends on which market specifically you're in, and the data I'm about to show is of course not perfect, but it seems that not so many users actually do use adblockers today. Although I don't know a single developer who doesn't, and in some web applications I'm running, the majority of users do use adblockers as they are focused on developers.
Chrome is assumed to be the most popular browser (by a large margin last time I checked, so I won't bother to check again) and a quick search puts the user base around 2-3 billion users. Searching for "adblock" in the Chrome Web Store (https://chrome.google.com/webstore/search/adblock?hl=en&_cat...) shows that the most popular adblocker has a user base of ~300,000 users.
That makes 0.015% to 0.01% of Chrome users having the "AdBlock" extension installed. Not that substantial.
If someone has some more accurate numbers than my slightly-educated guess, I'd be happy to be proven wrong.
Edit: The above user base of the adblock extension is wrong. As Jabbles pointed out, I was seeing the number of reviews, not number of users.
So instead, the page lists "10,000,000+ users" so we can assume the true number to be above that, but below "100,000,000+ users" users.
That would put the amount of Chrome users using the "AdBlock" extension between 0.3% and 5% more of less. Closer to "substantial", but not sure if it would impact businesses choice regarding ads/tracking or not.
> So instead, the page lists "10,000,000+ users" so we can assume the true number to be above that, but below "100,000,000+ users" users
Can we? I can't seem to find anything that indicates if/when the next number jump is, just a lot of big name extensions at "10,000,000+". Back in 2016 ABP had a post about their extension alone having 100+ million active users https://blog.adblockplus.org/blog/100-million-users-100-mill... and that's ignoring the >50% of Chrome users on mobile which requires non-extension based blocking.
Going for someone else's numbers instead of trying to build my own I'm finding anything from 10% to near 50% with most estimates being in the range of ~25%.
I just assumed that Google has brackets of 10 - 100 - 1000 - 10000 and so on, which led me to the "but below 100,000,000+ users" part. Not sure why they are hiding the true count (maybe they don't have exact numbers themselves), but if there truly is that many users, not sure why they wouldn't show it.
> and that's ignoring the >50% of Chrome users on mobile which requires non-extension based blocking.
That might be true for Chrome users on Android, but Chrome users on iOS (which aren't as many as Android users although), there isn't a choice of any extension nor non-extension based blocking. Firefox on iOS doesn't even allow extensions, and only Safari seems to have ad-blocking. At least last time I checked, might have changed lately.
> You're saying that a significant portion of Chrome + iOS users are A) constantly connected to a VPN and B) that VPN has DNS-based ad-blocking?
No, they simply said this statement:
> but Chrome users on iOS (which aren't as many as Android users although), there isn't a choice of any extension nor non-extension based blocking.
Is factually wrong as there is a choice; namely ad blocking VPN based apps.
Also these apps probably work differently than you're thinking. The "VPN" isn't a VPN in a traditional sense where your traffic goes to a remote server somewhere on the internet. Using VPN transport is just the method of convincing iOS/non-rooted Android to send the traffic to the app, which itself acts as the VPN server. Of course traditional true VPNs with ad filtering are also a thing but less common and more catered towards those already interested in true VPN service in the first place.
All that said iOS is hard to provide numbers showing usage scale being one way or the other as Apple doesn't publish them like other stores. If I had to guess iOS users would probably be the user group with the lowest ad blocking penetration though I wouldn't go as far as to say it's not worth noting. All of these smaller alternatives probably add up to more than the largest "normal" ad blocking method in the long run and ignoring them on an individual basis can significantly skew your overall result.
Ah, ok. Yeah, if we focus on the specific statement of "there isn't a choice for ad-blocking on iOS", then I was wrong, that's true.
I thought the comment was made in the larger context of which I made my initial comment about, namely the "Keep in mind that a substantial portion of users now use ad blockers" statement, but I understand now that devmor in classic HN tradition chose to specifically answer to one part of my comment while ignoring the rest, and not making it clear what they exactly responded to.
My reply was entirely unambiguous, as you only made a single claim in the comment I replied to, which was that Chrome users on iOS do not have the ability to block ads.
But, in classic HN tradition, you choose to put me at fault for your inability to understand how you represented your own train of thought.
I use an adblocker, and lots of filtering lists, but most of the `navigator.sendBeacon` requests I was seeing weren't being blocked. Sometimes they were when the URL matched a pattern, but often they weren't. Which makes sense since they aren't ads and by design have nearly zero effect on the user experience.
I still wanted to block them though... so I started killing all `navigator.sendBeacon` requests by replacing it with a no-op function on page load. [0]
I have the no-op function log the results to console and it's fascinating seeing all the sites attempting to use it.Some pages on Amazon will fire a sendBeacon request every second or so.
That's interesting, I wasn't aware of "navigator.sendBeacon" before.
Question about the user script. Blocking WebSockets I can understand as they can be used for exfiltrating data you don't want them to get a hold of. But why disable WASM? It can't be used for exfiltrating, and disabling it probably gives them a stronger data-point than just leaving it on, for when they are able to exfiltrate data (via CSS HTTP requests for example).
Oh I don't actually disable WASM. Those are just different scripts that can apply to pages when a filter matches. I disable sendBeacon everywhere with `*##+js(disable-sendBeacon.js)` but the others I don't use or only use on a specific site. I believe I added the WASM removal just to test how a particular site's fallback would work when it wasn't present. That said, disabling WASM probably reduces your browser fingerprinting bits. I bet fingerprintjs[0] uses it.
UBO already has a built-in set of powerful scripts[1], but I just wrote my own for fun. I think I could have done this by just using the built-in ones.
edit: This filter does the same thing just using the built in `set` script, but won't log to console:
From tests I've ran, about 8-12% of our visitors have some sort of tracking, analytics, or javascript disabling or blocking. This is in an ecommerce site focused toward non-technical users. I'd expect a tech savy browsing audience to be composed of 20% or more visitors with blocking.
For those wondering --- despite the domain of the site seeming to imply so, this does not use CSS.
On the other hand, the more I read about stuff like this, the more disenchanted I am with the "modern web". When something as seemingly innocent as a link can "stealthily" do something else when it's clicked, but otherwise looks exactly the same as a benign one (and moreover, behaves entirely as expected with JS off), it really brings into question whose interests such features are designed to serve.
Every time I hear some argument against "the modern web", I always try to imagine if you could apply the same argument to anything in computing.
And for this one, you could. Native applications might seem like you'll "submit the form when you click on the submit button, but something else entirely happens" because it's a general computing environment, just like the web.
So in reality, it seems you're just against "modern" computing in general, not specifically the web. Because you can have that behavior anywhere, not just in the web platform.
Take "the modern web" as a cultural descriptor then, not a technical one. There has been a huge shift in the last decade-plus. Software does not serve the user's interest anymore, and it sucks. Yes, this sort of thing has been technically possible across a range of platforms for a while. But the difference is that people weren't doing this kind of garbage before, and now it's everywhere.
Casual gaming is an excellent example of how this has changed. The whole purpose of the software is different. It used to be that you would buy a game—a piece of software purpose-built to entertain you. Now you are no longer buying a game; you are buying a value extraction device that uses a game as bait. Software just isn't built for users anymore.
> It used to be that you would buy a game—a piece of software purpose-built to entertain you. Now you are no longer buying a game; you are buying a value extraction device that uses a game as bait.
This applies to a lot of things besides games nowadays. A lot of software (and certain hardware - "smart" devices, etc) are built/sold at a loss with the primary objective being to generate "engagement" and/or collect personal data. The functionality of the device is purely there as a bait to get the mark to buy/adopt the software or device and would not be there if there was a way to get the marks to "engage" anyway.
I think the OPs point still stands. This has nothing to do with the web, it's the same thing with mobile apps and desktop apps on every platform except open source ones.
Well there is a case to be made that the web should not necessarily be a general computing platform. Or at least that there should be a separate mode in which it assuredly is not because it is a hypertext platform instead. This use case has not disappeared just because the web grew additional capabilities.
But it can feel as if the capability to act as a hypertext platform has disappeared, because you now have to worry about it doing things that are not aligned with this purpose. Remember, there is power in limitations, as type theory teaches us.
And even for use cases where more than simple hypertext is needed, there is still a vast, nuanced chasm between that and full-blown Turing completeness.
You might want to investigate Gemini. It appears to be one response to the case you are presenting. It starts at the protocol level and they are starting to build up an ecosystem of servers and clients which are more hypertext focused (No JS, limitations on content-types, etc...).
I believe the name Gemini was chosen to imply a middle-ground between Gopher and HTTP (Gemini was the NASA project between Mercury and Apollo).
In the end, any hypertext-mode solution is going to need to be client-based, because without robust client protections there's no incentive for a company to not just opt in to app mode.
A limited form of this already exists—noscript. Browse with JS off, but add exceptions for true web apps. It should be possible to expand on this to create a middle ground where certain JS operations are allowed (say, DOM manipulation) but most are not (no network requests).
I'm also against native clients that are inherently user-hostile. Does that mean I'm against modern computing?
I'm also against people working against my interest that only use pen and paper. Perhaps this issue is more about privacy and ethics than some judgement of being for or against some "modern" notion of computing.
Personally I'd prefer platforms that have privacy (and security) guarantees built in. Given the strong conflict of interests at play, I don't think we can expect that from any of the big players (if it's even reasonable at scale).
That's exactly it. The web was supposed to solve a problem of document distribution. Documents are not general computing environments, and that's exactly what you want. I want to read this news article, not run general software on my own system.
The biggest problem with the web is that it has been made into a general computing environment. Instead of creating another separate network - the web for docs, the app web for apps, with different url schemas etc - the web has been co-opted for this second case, thereby making it much less useful/safe for its original purpose.
This is true and in general websockets (well, and webtransport/webrtc etc) are the only reliable way to detect navigation from the backend since none of the methods mentioned in the article work if the user simply closed the tab.
Not always, not necessarily if the tab was in the background when closed (switch then close), not if they force quit (like the other comment I upvoted says), not if chrome updates etc. The other alternatives are opening another type of connection like an RTCPeerConnection to your server and seeing when that closes.
From an honest analytics parsing question, how do you decipher 4 different iOS users on the same device model from a Starbucks or the VPN exit node sharing the same IP from access_log?
From an honest privacy advocate: what makes you feel you have the right to be able to?
Why do you think end-users install things like "uBlock Origin", or why do smartphone manufacturers like Apple introduce features like random MAC address generation when connecting to wireless networks? Why do people use VPNs in the first place?
Because data points are being collected without our consent to profile us, and most of us do not want that.
The type of differentiation you are talking about by definition lacks consent, because if you had consent it would be trivial, you could do it by cookies or other forms of identification that the user consented to.
I'm a huge privacy advocate, so I'm not trying to do anything nefarious. However, I would like to know if my per visitor type numbers are accurate. As a small business, these numbers are useful even without having any desire of removing anonymity. There's a huge difference from wanting to tracking users and just know the correct number of people visiting.
How can you honestly not think that knowing an accurate count of visitors is a useful metric?
When you're dealing with small visitor numbers individual user tracking might seem very important. However, aggregate behavior is more insightful as it also smooths out outliers. Eg. 3% of all iPhone users traffic reach goal X every month; versus, this 1 user that visited the site 25 times in the last six months, 3 times through a VPN, 17 times from public, open access Wi-Fi, 5 times from a different country, reached goal X after spending 27 seconds on page Y.
The first one is directly actionable insight. Increase your reach to iPhone users, as more iPhone traffic leads to bigger conversion numbers. While the later doesn't lead directly to any actionable insight, but a bunch of theory crafting, while stripping away any form of privacy (and being a juicy target for intelligence agencies and hackers).
Now, that is of course my opinion. Having touched projects that had collected both "lightweight" analytics data, and everything the user touches. I'm sure the later could lead to more experimentation, but in the context of that project it amounted to just hoarding.
Instead, for other types of actionable insight I would suggest surveying converted users. Of course there can be selection bias, and unless the UI is done right can be obtrusive UX. This is the exact information more data would help you answer (in theory), but rather than asking the user you're trying to read their minds by tracking everything about them.
Again, I'm not harvesting data. I'm attempting to make the most information from access_log possible. I include not tracking pixels, no 3rd party analytics, no fingerprinting, no anything other than just getting information about what pages were loaded. It would be nice to know that all of the traffic from a specific IP is a prolific user or several users from a VPN/shared access location. I don't care who/what you are.
Everyone jumps to the conclusion that just because someone is parsing a log means <evil> and that is not necessarily always true. Some of us want to respect user privacy but at least have a general idea of the number of people visiting a site.
Look I'm just trying to find the best way to stealthily install cameras in every bedroom of someone's house. It's just so I can track their every movement and sell their intimate details to completely unrelated third parties. They're only going to compile all that data to psychologically abuse those people until they spend money! Is that so wrong‽
Just thinking here. If you did not have SPA, couldn't you just I don't know log when they request those pages? Like, aren't those done with HTTP request anyway... So why the hell you need to do the logging on client side...
Then again that would be fun to send enough nice bogus log information... As clearly that is what they want.
This works as long as the user is navigating around inside your site - but it won't work if the user e.g. navigates to a different domain or closes the browser window.
If you specifically want to track when a user leaves a page, you will miss a lot of events this way.
Of course there is no way to perfectly, reliably capture 100% of the events. Even if browsers had a dedicated API for that, a user could simply kill the process or pull the plug.
However, you can make sure you capture the vast majority of events. Clicking on a link or closing a tab are much more likely events than killing the browser or leaving a tab open for weeks.
(On desktop at least, might be different for mobile. But even there, you might want to track how many pages just stay open forever - which would also require you to track close events.)
What's wrong with doing something like this? If it contains PII, then I agree, the additional hassle of dealing with everything that comes with handling PII (like GDPR) becomes too much, easier to just don't do it. But if it doesn't contain PII, it can be useful to see how many people drop off a form VS submitting it for example.
How many users submitted the form vs how many users reached the form's page won't tell you anything about why they left or how long they struggled before submitting.
A beacon sent for each click on links on the form's page will tell you how many users left for this or that other page, which is very useful to know and optimize by removing the link and/or bringing its contents to the page itself.
A beacon sent for each form submission attempt will tell you how many users make mistakes while filling in the form, how good the error messages are, and whether the users tend to fix their input or leave.
Bonus points for incrementing an "attempt" hidden field on each submit button click so that you can see how many attempts it takes for all fields to be filled correctly.
Tracking what works and what doesn't can drive a lot of UX improvements, for the immediate and measurable benefit of the user.
Yeah, I'm not saying this is a silver-bullet that works in all cases, but some use cases do work better with it. For example, if said form shows one question at a time without any backend requests being done between questions, you could do one last try to log which question the user dropped off at.
How you can tell if the data you're collecting is PII? I guess there are many definitions of PII, but I generally base my own understanding on the GDPR definition:
> ‘Personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.
> How you can tell if the data you're collecting is PII?
No. How can you tell, as a user of any random website, that the script your browser is running as part of that page you've opened isn't shipping PII collected from your usage.
Eeh, not sure that question is relevant to the points of anything described in this comment-chain. For context, here it is again:
> > > > I’ve needed to send off an HTTP request with some data to log when a user does something like navigate to a different page or submit a form.
> > > No need for that. Stop hoarding data!
> > What's wrong with doing something like this? If it contains PII, then I agree, [...]
> How can you tell?
The context is from the perspective of the application developers who wants to log some data (unclear what exactly, hence my comment differentiates between PII or not) when user is leaving. The comment I'm replying to states "stop hoarding data!" but I'm pretty clear that's referring to hoarding PII, not any data. As you're the developer setting up this "send off an HTTP request with some data", it's clear to you if it's PII or not.
Obviously, as a user with JavaScript turned on, visiting a random website, have little to no control over what data exactly is collected and sent. That's basically the point of the web today, where application developers can write arbitrary JS applications that gets executed in the browser sandbox, and hence why it's so popular in the first place.
You can tell by not entering any PII into the site in the first place.
IP is technically PII in some places. Personally I am not worried if a criminal gets "my" IP in the same way that I am not worried if they have my phone number. I would be worried if they had my name address age bank account info etc, but then I don't give that out freely
If you are not worried that a criminal (or anyone) gets your phone number, post it here in reply to this post.
That's kind of my very coarse litmus test for PII: If I'm not willing to post it publicly in a rando internet forum, it's probably PII. There are exceptions obviously, and the inverse is not true: I may be willing to publicly post certain PII.
Will any of these techniques inform the site owners that I close the tab the instant they put up a big “sign up for our mailing list” modal? And maybe that would help train them to not design sites that way?
Maybe that could be one good outcome of such an API.
I think popups on page load are more of a symptom of short-term, myopic thinking than anything else. This type of thinking is strongly encouraged by always trying to live up to quarterly projections - "Did Sales meet their targets?"
Popups exchange long-term trust in your brand for short-term profits. Of course it's the case that if you pop a modal in front of everyone, your conversion stats will go up. But potential life-time customers who have faith in your brand and believe in your mission will lose trust in you quickly and probably never sign up in the first place.
For me, it always comes down to the primary rule of UX: if you wouldn't do it IRL, don't do it online.
You can ask for someone's email if they look like they're interested in something you're selling, but don't ask for it the moment they enter your store!
Long term trust pays the bills quite often, it all depends on what product or service your company is selling. And, yes, I apply this in my own projects, unless I am doing some ugly cash grab project.
Since you were never going to join their mailing list, no, you are simply saving them bandwidth.
What you don't realise is that x number of people join the list and x number of people tolerate being spammed with 'did you know we sell stuff' emails every day for the rest of their lives. x number of those people actually do buy something; likley the thing they intended to buy originally but joined the email list in case a discount code would be the subject of the first 'welcome' email because this is what they have been trained to expect.
All this has been A/B tested and, thus, has been 'proven' to be great business practice.
Those pop-ups are usually shown on "exit intent" which is simply when you move your mouse outside the viewport (i.e. the address bar or hover over another tab).
Have you seen the new variation of this abomination? Now it shows another spam page after the user clicks the back button. There's no "intent" anymore, just a user trying to leave and getting a new spam.
There was a parts supplier site that used to offer a 5% discount in this exit intent handler. (I’m not sure if they still do and I’m only on mobile at the moment.)
I’d happily trigger their exit intent handler and juice their “this feature is a total game-changer for our business!” reporting.
I wasn't commenting on Firefox's decision to not enable the API, I was commenting on how the author appears to consider Firefox to not be very significant.
Though according to caniuse, beacons is fully implemented which has much the same effect from a tracking PoV.
As a side note, I was somehow completely unaware of that feature (and I don't think in a "heard about it and forgot" sort of way). Every day is a school day...
On the mdn page for it they say there are other less legitimate techniques like adding an image which will start loading and delay the page unloading. So if they didn't add beacons it would mean other less performant ways would be (ab)used.
Interesting that commenters here assert "most users don't want to be tracked," whereas in fact most users happily choose Chrome over any privacy-focused platforms.
Firefox is unlucky that its remaining users furiously hate everything tracking-related, and are ready to burn Mozilla to the ground for even tiniest suspicion of any transgression. Therefore, Mozilla can't choose a lesser evil here, because it's still seen as evil.
What use-cases are there for this feature other than tracking users?
Anyway, the best solution is to pass any links through a redirect which is responsible for logging the visit. That's how Google tracks what search results get clicked on. And it doesn't require any JavaScript.
I'm surprised they didn't even mention it as a possibility.
> What use-cases are there for this feature other than tracking users?
Social services where users want to signal if they are online/offline
Users who want to know how much time they've spent on a platform.
Closing down sessions for things that can be expensive to just run "forever". Think VMs and similar that gets started when the user visits the page, that you want to turn off when they leave.
The use cases are many, and there are also many other alternative solutions, this is obviously not the only one. But as always, all of them come with their own tradeoffs, so this technique might be the best for some of them.
You will already need to handle the case when you don't get the last request, because there are more ways the user can just vanish on you: suspending the computer, killing the browser process, crashing the browser, turning off WiFi or going out of range, etc, etc.
The best you can hope for is a "happy path" where you can clear up a little sooner in most cases, but you can't rely on it.
If a user being on a webpage is holding open a resource, that might be an architectural issue.
That definitely is an architectural issue. Unfortunately it is essentially a cache management matter (cache invalidation considers when something becomes useless/wasteful, as well as when it becomes incorrect) which is a hard problem to solve.
There are legitimate circumstances where a user causes a long running prices to start, that it is wasteful to continue if incomplete when they vanish (because the result isn't going to be useful to another user, or even that same user if they return).
While you can't catch everything (the user's machine losing power or all connectivity, etc.) you can catch a deliberate exit. And in the case of a long running process, if the user's exit was accidental it is more likely that they'll be back and having continued the process is useful.
Let us not forget that tracking users is not a single use case.
Closing off cached resources when a user vanishes is a good thing, it saves resources for other users and could, if I may stretch a little, have environmental impact. Noting that sessions tend to end after a particular set of circumstances could mean spoting something in your application that is annoying people, something that particularly in an SPA you might otherwise not easily detect.
Sometimes tracking is legitimately benign. It is only when unnecessary PII is included, and kept to track each specific user over time rather than just over a session, that it gets stalky to the point of begin in my "I won't do that" list (sharing the PII around further gets you on my "you are morally wrong for doing that" list).
> surprised they didn't even mention it as a possibility
The article is focused on detecting when a user leaves. While a fair amount if that will be detectable because they've clicked a link, it doesn't cover the large case set that is closing tabs and windows.
Something I might have to investigate (or search to see if someone else has): do any of these techniques work reliably on controlled OS shutdown.
"Tracking users" has lots of uses. For example, we were trying to do OP on gwern.net for a while, using several of those tricks. It failed miserably and we could never figure out why.
What evil things were we doing? Well, I wanted to know if people were using the links I put inside popups, like to Google Scholar. Was anyone using them? If not, they were just so much clutter and should be removed for the users' benefit. I also wanted to get a list of outbound links by popularity, so I could write summaries/annotations for the most popular unannotated links, and rank dead links by priority for fixing (there are too many unannotated or dead links to 'just fix', so a ranking would've helped a lot).
But the link tracking never worked, so, I couldn't do any of that.
What if they just close their laptop lid, or the browser crashes? You can't reliably detect when a user leaves with this method, so you _cant_ use it for anything critical
sure you can, if you combine it with a timeout and/or a way for users to break a lock (and then of course, blocking the original user's session if he comes back anyway)
at least you don't have to wait for the timeout to expire if the user properly closed the application/website, which happens most of the time
This is an interesting take, I would assume at some point it would end up costing you time, because for all its faults, the modern web has some great tools (apps) that can improve your life in a number of ways. I’m also unsure how they’d earn your trust without giving them that essential unblocking js trust in the first place.
> Access to client side scripts on my machine has to be earned in trust
I agree that it's all about trust. Why would you ever enter information on a website you don't trust? What extra information can be gathered using JS that can't be otherwise? Or what is the exact harm done if they send extra requests to a tracking API?
My point is that once you access a specific website you consent with that website sending HTML/CSS/JS to your computer and executing it. The biggest problem those days is when that website is sending your information to other entities, 3rd parties, for other purposes than improving your experience. I think having "tracking" to detect errors, loading time issues and improving the user experience is perfectly reasonable if implemented in a proper way.
Apart from the JS engine vulnerabilities, what are the privacy benefits of disabling JavaScript? You can still include 3rd party tracking pixels (via CSS or HTML) and share request data server-side with third parties.
With all browser vendors nowadays (minus chrome) trying to perceive themselves as privacy protectors, who even approved and implemented this?
The only good thing coming out of this ping attribute is that it’s a lot easier for plugins to block it rather than intercepting javascript and domains.
What happens if the user has more than one tab/window open an closes one?
Weirdest case I've observed in the wild is a site that works perfectly without referer header, except for logout. As usual for anything requiring referer it fails without a user-readable message without referer. If referer is sent, the logout procedure switches through multiple redirects and some waiting while js is doing something, server backend probably, too.
Some sites make weird assumptions about the network, the browser, and the user.
IE11 is the last browser that can reliably send a request before the tab closes (by using synchrous).
I swear telling the business guys that we had no way to run an action when someone closed the page had them nearly running back to IE. And for that specific functionality, I find it hard to disagree.
In our case, we lock entities when someone starts working on them, but now we have no way to unlock them if they fat-finger the close button, or press one too many backspaces.
How about if someone just forgets the document open on their browser? Or their network connection is down when they close the browser window? You eventually have to somehow deal with documents that are left locked, no matter what (google CAP theorem.)
On a general level, locking is a subpar solution for distributed systems. You should try to build support for automatic resolution of (most) edit conflicts instead, and forego locking altogether. If that's not possible, try to make the locks smart, e.g. so they auto expire unless periodically renewed.
I'm surprised that browsers nowadays include specific API for better user tracking.
At first thought I don't like it.
But at second thought I think that I like it. Issue is, webmasters will still track you, like it or not. But with those dedicated APIs tracking will be less annoying and those who can control their browsers, can disable that kind of tracking more easily (provided that they're even aware of those features).
Anyway I don't like the direction web standards are evolving. Why have so many custom APIs and attributes? There's already fetch priority flag, that should be enough. This is exponential explosion of APIs. Modern API designers don't know about concept of orthogonal APIs (or I don't know something).
Also <a ping attribute seems to track user even if he disabled JavaScript. Bad bad thing.
Oh wait, not on mobile, unless you're willing to deviate from stable releases or download a fork.
I feel tempted to write an addon that will catch tracking like this and just repeat every ping a thousand times across the rest of the day, perhaps with some permutations of the data these sites are trying to collect. If I can't stop you from collecting my data, I'll make my data useless to you instead.
We have attempted to use sendBeacon as a last resort signal for releasing an exclusive lock granted to a user for editing a record. Only one user can be granted this at a time for a given record to avoid contention, but there are so many ways a user might abandon an edit-in-progress in web applications (close browser, inactivity, loss of network or power).
I realize there are a lot of different strategies for addressing this situation, and I'd be curious to hear how others have solved this problem.
In the specific case of using sendBeacon, it is a little disheartening that once a basic programming tool gets abused by the analytics/advertising/tracking behemoths then the ad blockers' only recourse at times is to disable it completely. I completely support the efforts made by the ad blockers, but also find it sad how legitimate uses of certain tools end up getting blocked in the process.
If you haven't accounted for the fact that there is absolutely no way to guarantee the client has just disappeared, all you've don't is build a system on bad assumptions.
A client browser can crash, the computer can lose power, the network can be unplugged, the router can crash, the internet connection can go down.
It doesn't matter why, there are many common reasons why you can't rely on an unlock signal, so must be able to deal with that situation. If you realize that from the beginning and design accordingly, it's usually easier to handle than realizing it later and trying to add special cases to catch it later.
For example, if you know the above is a problem, you might just opt to make a lock for a record the I'd of the locking user and the last lock update time, and update the lock every few seconds during normal operation when locked. If there's a problem, that user can pick up the lock without problem when reconnecting, but if any other user attempts to lock the record and the lock hasn't been updated in a minute or two, then consider it invalid and let the new user lock. Anyone attempting to edit a record with a lock that isn't too old is told it's actively locked and to try back in a few minutes. All of a sudden your lock release problems are automatically cleaned up by normal use, can be easiest found as needed by searching for old timestamps, and the person that has to deal with problems is the person with the behavior/system causing the problem.
There are obviously more complicated (and for some cases better) solutions, but the takeaway is to look at the problem and constraints as a whole and find a solution with the right trade offs given your needs, and not let the constant accretion of small features lead you to a suboptimal solution what doesn't work.
The industry has, for the most part, been migrating to live collaborative edits via CRDTs and the like rather than exclusive access with non-deterministic terminating conditions. You could argue that the whole field of distributed computing is geared toward solving this type of problem.
As others have mentioned, this is very well studied in the field of distributed computing, where servers can acquire a lock and then immediately disconnect due to a power failure.
Other people have recommended CRDTs and Optimistic Concurrency control, which is great if you are designing an app from the ground up. If you have an existing large app that just needs locks, though, I recommend following the Chubby paper:
https://research.google.com/archive/chubby-osdi06.pdf
Section 2.4 Locks addresses how Chubby thinks about locking in a distributed system:
It is costly to introduce sequence numbers into all the interactions in an existing complex system. Instead, Chubby provides a means by which sequence numbers can be introduced into only those interactions that make use of locks. At any time, a lock holder may request a sequencer, an opaque byte-string that describes the state of the lock immediately after acquisition. It contains the name of the lock, the mode in which it was acquired (exclusive or shared), and the lock generation number. The client passes the sequencer to servers (such as file servers) if it expects the operation to be protected by the lock. The recipient server is expected to test whether the sequencer is still valid and has the appropriate mode; if not, it should reject the request. The validity of a sequencer can be checked against the server’s Chubby cache or, if the server does not wish to maintain a session with Chubby, against the most recent sequencer that the server has observed. The sequencer mechanism requires only the addition of a string to affected messages, and is easily explained to our developers.
Although we find sequencers simple to use, important protocols evolve slowly. Chubby therefore provides an imperfect but easier mechanism to reduce the risk of delayed or re-ordered requests to servers that do not sup- port sequencers. If a client releases a lock in the normal way, it is immediately available for other clients to claim, as one would expect. However, if a lock becomes free because the holder has failed or become inaccessible, the lock server will prevent other clients from claiming the lock for a period called the lock-delay. Clients may specify any lock-delay up to some bound, currently one minute; this limit prevents a faulty client from making a lock (and thus some resource) unavailable for an arbitrarily long time. While imperfect, the lock-delay protects unmodified servers and clients from everyday problems caused by message delays and restarts
My first preference would be to avoid it by using optimistic concurrency control rather than locking. Maybe display a hint that someone else is editing but allow the user to ignore it.
> However, this is extremely unreliable. In many situations, especially on mobile, the browser will not fire the unload, beforeunload, or pagehide events.
Man, I had no idea that this stuff could happen. Having a built-in, non-disableable pingback method in the browser engine is scary stuff for privacy-oriented people. I don't know why more people don't know about this. Happily, I found and installed https://github.com/vijithassar/pingkiller to help mitigate the `ping` attribute (in case my ad blocker isn't doing that already).
Interesting. I am curious what browsers were tested in this experiment, and if the different flavors behave differently.
From my casual observation of Firefox (I use the network debugging tools in Firefox frequently) there isn't a column for priority. Firefox also does not show a status of pending, rather it just omits a pending status until a status becomes available.
Navigator.sendBeacon() doesn't reliably follow 30x redirects in my experience. About 30% of the time, for no obvious reason, it stops following redirect chains after hitting the first redirect in the chain, even though it's supposed to follow those for analytics purposes.
before any JS has a chance to run. You can also trap "beforeunload" listeners, or just delete them document.body.onbeforeunload=null document.onbeforeunload=null
Wow there are a lot of new features in web browsers lately just targeting analytics and ads. Makes me wonder what other use cases have beacons as the solution.
Even if you use Amplitude, this could still be helpful information. I’m not sure what kind of APIs Amplitude provides, but we use it at my job. In my work, the details of Amplitude are abstracted away such that this information is still highly relevant.
At a minimum, this kind of information is relevant to the people creating products like Heap or Amplitude.
At my company, the analytics APIs are provided by a platform team.
I think there’s some utility in a company owning an abstraction away from a third party.
Supposing if Amplitude (or Heap) were to ever go under, or if we were to want to change Analytics providers for whatever reason, it would be extremely helpful if the code didn’t depend directly on these third parties.
On a smaller app, I would mostly likely directly use the Heap or Amplitude APIs.
Is this related to the article? How do you track time spend on page for a single page-visit using Heap? Don't they have to use a similar mechanism as described in the article?
> I swear. What happened here? Like why do things feel sluggish than software over 20 years ago? I just can't wrap my mind around it. We have SSDs and infinite CPU and RAM now compared to those days, yet there is always this feeling the computer is doing something more than I asked for behind the scenes. Even on websites, you can feel when you click on a link, it is doing something more. It's a very uncomfortable feeling.
Keep in mind, "free" pairs with greed. The Market even pre-internet gravitated to free. I'm certainly not defending greed, but the general lack of market pushback doesn't discourage it either.
There is no market pushback because free services hide negative externalities. So when users choose something that’s free over something they’d have to pay for, I’d say they’re generally unaware of the negative consequences (either to them or to the rest of society) because by claiming a service is free of charge, the provider is effectively hiding those negative effects, and making their revenue in some opaque way (e.g. advertising)
There will never be market pushback as long as those externalities aren’t priced in. And Imho the only for that to happen is for governments to introduce regulation, e.g. by taxing the externalities so that “free” service providers are forced to be more upfront about the actual cost of their service.
This is why libraries are amazing - they are objectively funded so that “free” really means “so essential it’s funded for you.” In the case of vulnerable populations that are driven to free services (like the socioeconomically disadvantaged or especially kids), it relieves the pressure to engage in selling one’s self to receive some “free” service. This was more widely accepted in the past when services like NPR and PBS were publicly funded. You know, when we cared about education.
First, haven't we learned already that any government regulation always ends up favoring the status quo? FAANG will be able to eat those costs right away and make it impossible for any competitor to rise up
Second, what happened with personal responsibility? We can still choose to patronize companies that do not rely on ads, we can still promote/fund the development of Libre Software that is focused on the users' welfare and not the corporations' bottom line. Most of us here on HN can even help other less tech-savvy people to avoid falling into those traps and educate them about less invasive alternatives.
When you say "the government should do X", you imply that we can not do it ourselves. And we pretty much can.
> First, haven't we learned already that any government regulation always ends up favoring the status quo?
That premise is wrong. Government regulation has lately been mostly done on account of corporations which want to protect their monopolies and strengthen their position, but that doesn't make it inherently so.
If by lately, you mean "basically always", then I'd agree. I'd be hard pressed to think of any regulation that was successfully enacted and led to actual distress and disruption in the big corporations.
> that doesn't make it inherently so
Why would it be different this time? Can you think of any kind of policy that has any slim chance of passing and would get us rid of Big Tech? And by "Big Tech", I mean all of it, not just the ones that you don't like.
I'm not sure anyone wants to get rid of big tech. Just reign it in. And just enforcing anticompetitive regulations help. The GDPR helps. The EU regulations requiring federated messaging help. The laws in favor net neutrality help.
> I'm not sure anyone wants to get rid of big tech.
Yes, I do. The FSF does. The IndieWeb does.
> Just reign it in.
To think that this is possible without any type of damaging side-effect is a huge delusion.
Trusting more power to Big Government to try to control Big Tech is like saying "Look at all the destruction that Godzilla is making, we need to unleash King Kong to fight it".
The only stable solution to avoid global systemic catastrophe is by removing centralized power and redistributing it to local communities.
GDPR does not help, quite the opposite. It gave people some illusion of control but did nothing but scare smaller players into compliance.
Messaging standardization might actually turn out to be good, but only because none of the dominant companies are from Europe.
What are their options for search? I know DDG is an option, but even it seems to rely on Big Tech.
> Trusting more power to Big Government to try to control Big Tech
But it's definitely worked in the past. Government successfully reigned in a ton of industry. Sure, it hasn't reigned in Big Tech, but so much other stuff.
Did it really? To me it looks like the Auto Industry is still pretty much doing whatever they want, Big Oil continues to expand on their emissions, Big Pharma profited quite a bit even despite being partly responsible for an opioid crisis...
They're not doing whatever they want, because then they'd utilize slave labor with no safety regards (and some actually continue to do so too, just not in the developed world - which just proves the point that they'd jump on it as soon as could)
They're however doing whatever they can get away with, which is arguably way too much
The point is not about what the regulation stopped them from doing locally, the point is that no regulation that came into existence ever broke the power structure. It was never a threat to the ones connected to the elites.
Any regulation that does get approve ends up weaponized in favor of the big companies.
To illustrate: look at Dieselgate. If the regulations were actually meant to be serious, any scrappy company from Poland, Portugal or Bulgaria would have been absolutely dismantled out of existence. But VW got what? A symbolic fine, some Casablanca-style reprimands, perhaps a expiatory goat... but they will continue to have the support from the government.
What about tech? What real benefit has GDPR brought to the people? Nothing! It made only the small business owners scared of violations, got them out of running their own sites and into siloed Facebook/Amazon pages, and with their "social Media presence" on Twitter/Instagram. Tell me with a clean face how that "regulation" was in your favor and not of the status quo?
Don't read what is not there. I did not say that all regulations are bad.
With that in mind, please tell me which part of "haven't we learned already that any government regulation always ends up favoring the status quo?" or "regulations only get to be enacted when they don't threaten the status quo" is goalpost-moving...
While you are at it, take your time to think about the question I asked you in the first response. What kind of policy do you believe could have any chance of being enacted and offer a serious change for Big Tech?
> haven't we learned already that any government regulation always ends up favoring the status quo
Not at all. A ton of government regulation is to fix an ongoing problem by changing the status quo. Meatpacking regulations after "The Jungle". The EPA, Clean Air and Clean Water act. Mandatory seat belt laws. The list of "government saw problem, fixed with regulation" is huge.
In particular, with FB/Google, the status quo might crumble without ads. Or maybe they'll go to less targeted ads and only make a ridiculous amount of money instead of an insane amount.
All the examples you brought are from things where the "changes" did not threaten the industries involved or helped consolidate the market into an oligopoly. They pretty much favored the status quo.
You are going at this backwards. Ask yourself why were these requirements established in the first place, and who was in condition to meet them.
Also, do realize that even these requirements never translated into any kind of service guarantee. It does not solve the overall issue.
Case in point: "clean water requirements" in the US did not stop mega corporations from turning bottled water into a multi-billion dollar market, and it only pushed "dirty" manufacturing to China.
Clean water requirements have to do with the delivery of water to my house not bottling it.
>It does not solve the overall issue.
It makes it a whole lot better then it would be otherwise. Power companies can and do get fined for not doing what they should, a power that would be beyond the ability of an individual to do.
Because of things like the USPS damn near anyone in the US can mail something to anyone else for a decent price which is a net positive for society.
The point that you are so unwilling to accept is that regulations only get to be enacted if they don't hurt the corporations.
> Power companies can and do get fined for not doing what they should.
Yet, they still manage to be profitable and in some cases even get government assistance when they fail, when the long-term, "systemically healthy" solution would be to have a framework that allows more diversity in service providers and that does not depend on the survivability of any single entity.
Look at Texas and the winter brownouts. Their grid fails whenever it gets so cold to the point that generating energy is not lucrative. Paying the fines is favoring the status quo.
"Being a net positive for society" is at best an accidental side effect, not the point of any regulation that gets to be enacted. And there are other ways where we can get the societal benefits without giving away power to these corrupt institutions.
>The point that you are so unwilling to accept is that regulations only get to be enacted if they don't hurt the corporations.
My local non-profit power company is a data point against that position. There are many others.
>Look at Texas and the winter brownouts. Their grid fails whenever it gets so cold to the point that generating energy is not lucrative.
The portions of Texas not on the ERCOT grid which are connected to the federally regulated grids preformed much better than the ERCOT grid because they have regulations, with punishments if they don't follow them, the government requires.
>And there are other ways where we can get the societal benefits without giving away power to these corrupt institutions.
> My local non-profit power company is a data point against that position.
Was "your local non-profit" responsible in the elaboration of any of the regulation? Are they in any condition to threaten the status quo? Can they disrupt the market at a global scale or are they just sticking to being a "local, non-profit" entity?
It seems we are talking about two different things. You want to defend regulatory action as a valid mechanism for societal progress. What I am saying is that these mechanisms historically only worked when the status quo could benefit (or at the very least not threatened) from it.
The problem is that I am feeling like I am arguing a strawman (regulations are always bad!) when my point is that calling for regulations for Big Tech will do jack-shit to actually solve any of the issues affecting society, and more likely than not it is just going to help Big Tech cement their dominance.
> Second, what happened with personal responsibility?
This breaks down when some body else's lack of personal responsibility impacts me. For example, a drunk driver colliding head on with me on the highway. In this case, it's everyone else gravitating to "free" services which in turn make them so ubiquitous that it's near impossible to escape. Even though I don't use Gmail, I'm still impacted when all my contacts use it to send me email.
Sure, I guess I could be personally responsible by disowning those contacts, but that's in the extremes.
That's probably an even better example but for some reason that's still a political issue, and I didn't want to get into that. At least when talking about drunk drivers, everyone can agree it's real, bad, and not the victim's fault.
> Even though I don't use Gmail, I'm still impacted when all my contacts use it to send me email.
No, you are not. Even if you wanted to treat it as such, you could drop all incoming email from google, or auto-respond to people saying they need a different email address to reach you.
And if you think that doing that is a bad idea at the individual level, ask yourself why would it be acceptable at the global sphere.
Yes, personal responsibility and the free market have done so well on this subject, how dare we try something else??
/s
Seriously, the free market and personal responsibility have not worked. Let’s try something else. At this point, I’ll take some potential negative externalities over this shitshow.
It worked pretty well for me and anyone else that is willing to understand "There Ain't No Such Thing As A Free Lunch".
Wherever I get to maintain a proper "digital hygiene"*, I don't have any of these issues that people love to complain about. But I would bet that whatever regulation gets to be approved, it would not only be ineffective to solve the issues that affect the majority, it would make it harder for the minority that still manages to get away from them.
* a simple set of rules to live by.
- prefer free-software solutions for all use cases that satisfies your hard requirements, even if they miss on the "nice-to-haves".
- self-host as much as possible: see all services you are paying currently and look for existing open self-hosted alternatives. Get an old computer or laptop and run these. Invite your friends and family. If you are not technical, find someone in your close circle that is and ask if they are interested in doing it, offer to help with the costs.
- If you don't want to self-host, find service providers that offer these open source services.
- use Brave: complain about crypto all you want, it is the only web browser that gives control to the user and that promotes a business model where creators are rewarded directly by the consumers.
- use the received BAT to be as generous as possible with open source developers. 5 bucks a month might not mean much, but if 10% of internet users did that I guarantee we would kill all the app stores and their abusive practices.
- Do not rely on streaming services. I'd rather pay for a private tracker to download what I want than finance Disney/Comcast/HBO/Amazon/Apple to increase their cultural dominance even further
- use alternative frontends whenever you have to access youtube, twitter, medium.
so now you’re creating a bunch of extra work for yourself so you can host a bunch of content that most people won’t see
telling a bunch of software engineers to do things themselves is never going to solve the problem, it’s like telling the pope to go to church
the problem is everything else happening to the average people in the world around you - you’re subject to it whether you like it or not. As long as you live in a society problems that facebook twitter and other social media platforms you dont use are causing are going to be your problems too, no matter how deep you bury your head in niche web browsers and self-hosted blogging platforms.
> everything else happening to the average people in the world around you
Did you read the part where I said "invite your friends and family", or you just jumped to write such a thoughtful response?
My parents don't care about Facebook, Twitter or whatsapp. They care about being able to see and talk with their grandkids. If I tell them that they can do that by using a different app, they will install the app without second thought.
If they want to continue using Facebook/Google, they can. But the important thing to me is that now they are less dependent on Facebook and they have an option.
This solution is one that maybe 1% of the US populace can implement or take advantage of via family.
It's always worth remembering that only 5% of the adult US populace can complete a task like finding and applying for a job using only web technology†. Being able to self host is a skill that maybe 0.1% of the populace can do, being generous.
An important life lesson is knowing that just because you can do something doesn't mean everybody, or even a majority of people can.
What you're proposing won't work for any but the technological elite.
It requires too many technical skills to work.
Alternatively, it requires too much money to hire the technical skills to work.
If it doesn't work for the majority (even a reasonably sized minority) of people, regardless of being borne of the best of intentions, it's not a viable alternative. Period.
What is about Mastodon that requires technical skills that Facebook or Twitter do not? The fact that they are required to know the name of the instance when setting up a client?
Just like they learned (conditioned could be a better word) into putting all their data into their shiny smartphones, people can learn something like "to use this you need your username and the server name, like email addresses". And if you tell me that some people don't even know that and had someone else setting up their facebook for them, why can't this "someone else" set up an ActivityPub client as well?
> Alternatively, it requires too much money to hire the technical skills to work.
I don't think I charged anything from my friends and family that asked to get access to my matrix server. I also don't charge anything from those that got an account on the Jellyfin box I run. I also didn't send an invoice to my wife or parents for helping them setup Element on their phones.
"Ah, but this doesn't scale!"
Sure, if it's just me doing it won't. But there are already other people that learned once and managed to teach others.
> it's not a viable alternative.
Do us both a favor. Instead of making absolute statements based on incomplete information and your prejudices, find a way to prove me wrong.
Get one of your current vices (Twitter? Instagram? TikTok? WhatsApp? iMessage?), and do your best effort to use the open alternatives that exist. For the social networking stuff, you will quickly see that the only "problem" is that the people you are used to seeing are not there. Instead of shrugging your shoulders and going back to the old ways, see how many people you can bring along with you.
I'm not even asking you to delete your current application. I'm just asking you to try to use the open alternative and help as many people as possible to join you. If you find any reasonable justification that prevents you or your peers to adopt the open alternative, then I will believe you.
what i’m saying is that you’re ignoring societal problems by removing yourself from them, and this will not fix anything… and you will still be subject to side-effects as long as you wish to interact with people outside of your parents (ie, society)
I’ve been on my local school board for 20 years and the changes happening due to social media are staggering (for children and adults). My lack of participation hasn’t changed anything. Telling people not to participate will not work because you’re rivaling companies that pay experts tons of money to get people addicted to these things. As individuals we’re massively out-gunned.
I’ve started working with and donating to advocacy groups looking to regulate these companies because I haven’t seen anything else even begin to work.
I'd rather say that I am weakening the grip that some corporations have over society at large, and that the more people did the same, the less of a problem it would be.
I am also saying that there are a good number of people that think this is not a problem, so I don't want to waste my time and energy trying to convince them otherwise.
Understandable, my perspective is that most people simply don’t realize how much of a problem it is, because there are massive amounts of money and expertise keeping them from it.
I think it is more. I see people who make a simple website for a small family guesthouse voluntarily add all kinds of scripts that give them not a lot but send a ton of data to the big players.
Typically the reason is, that they don't know how to do it any other way.
I was paging through a fansite’s concert listings archives this morning trying to find a particular show. Used to be a time when a simple page like this [0] would load just about as fast as you could click the “previous page” link. Now it’s a few seconds each time.
I have some old machines for retro purposes, including some Pentium 2s running Windows 98. Things take longer to load, that's for granted, but once something runs it just feels infinitely more snappy than a modern desktop. This is not rose-tinted glasses misremembering how things were like 20 years ago; this is actually turning that machine on in the current decade and observing how an older version of the same software behaves on that machine vs on a modern Windows 10 machine.
Just for experimental purpose, you can try disabling all UI animation to make ui interactions instant [1], and perhaps disable ALL antivirus and their filesystem filter drivers as they make all disk access slower [2] (including windows defender, you can re-enable it again after you're finished messing around). See if those tweaks can actually make your computer as fast as the old machines.
I did something similar a while ago by explicitly adding a call to disable all theming in an app. That way you can even make the window decorations look like old Win9x borders in Windows 10. Disabling theming makes window creation measurably faster, by a lot. That includes lack of animations for that specific app, of course.
Try to use windows 10 on a laptop with teams and office 365. You will underestand.
20 years ago software was running locally. Now, it must communicate with mothership for every action you make.
Tools running in the browser are slow, because they use the browser to get user input or to display information.
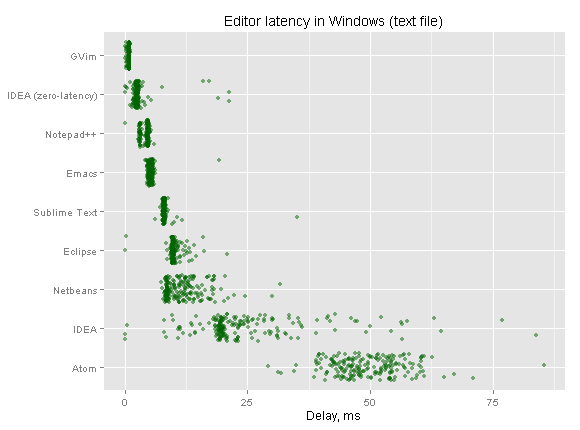
There should definitely be more exploration of latency in the software that we use. Here's a really nice article about it from a while back, about typing in particular: https://pavelfatin.com/typing-with-pleasure/
> These are tests of the latency between a keypress and the display of a character in a terminal
People noticed that the windows built-in terminal app has noticeable latency, and when the WSL1 team implemented their own terminal app, they ended up with much better latency [1]. I wonder if this input lag test was done using the built-in terminal or this WSL1 terminal.
For the time being, there have been no need for updates. Gorhill has t updated it for like a year before he discontinued support. It's not likely to preemptively fork, but probably will once it's needed.
Indeed. People who repeat this absurd meme either have a terrible memory or are just flippantly cynical. Computers 20 years ago were very slow compared to how things are today, this is especially true of professional software like compilers, digital audio workstations, video editing, photo editing, 3d modeling as well as common utility software like file compressors, codec converters, disk searching tools etc, but also gaming, video playback, and don't even get me started on internet speeds. It's just flat wrong.
Try testing startup time (yes it matters) of old software (on current machines) compared to new stuff... even web pages are slower than that most of the time.
Can’t tell if that was sarcasm or not. I still have hardware from the DOS era. For example, Microsoft Works starts up almost instantly. That is definitely not the case with Office 365 in 2022. Latency is far lower back then too. I could go on and on.
They're talking about post start up. Yes, disk speeds are much faster now. Other than startup however, everything feels slower. Heck, now the limit on my speed is often internet, not disk.
To me, the semi-transparent header and border are absolutely unacceptable. Imagine opening a book and 20% of the page are decor, decor with text no less. In clear words: this fucks with my attention, and the reason is that this is design that serves no actual purpose. If you're building a house or a product, anything that's not necessary is detrimental to the users experience, I don't even understand what can be argued about this
> Imagine opening a book and 20% of the page are decor, decor with text no less.
Regularly happens in "book world". Chapter headings are often an entire page, and sometimes even a double spread. The average whitespace around headings on the three closest books at hand were all 1/3rd of the page, making that decor even greater than the 20% you're describing.
House of Leaves is a book like this and the story is not the same without it. The words move down the page in a staircase fashion as Will Navidson is walking down the stairs to his untimely demise, in one example.
I've never seen anyone care about reader mode. Most websites are semi broken in reader mode because reader mode has some weird custom logic to it about what does and what doesn't show up in there. There are no public standards to follow to accomplish what you want.
You can't expect everyone to reverse engineer your browser to make your reader mode experience better. Reader mode is explicitly a client side algorithm, parsing and displaying a document for you, the user. If reader mode doesn't work right for you, you should file an issue with your browser maker. After all, they're the ones that designed the algorithm to partially hide the contents of the web page for you.
For what it's worth, I have no issue viewing the images in Firefox's reader mode.
I can't see any super distracting content on this page anyway. There's a black side bar and the text is almost black on white. Perhaps you're referring to the header, but even that's mostly white and black. There are definitely some places where accessibility can be improved, but this is hardly "not acceptable".
I actually don't think this is about personal preference. If you build/design something with components that serve no functional purpose, the result is just going to be worse. Classic architecture learned this lesson many, many generations ago.
If it is my website and my resources and my words I'll design it in a way that I prefer because it is my creation, my style. If that offends you then find someone to transcribe it for you. Don't look a gift horse in the mouth.
{kind=link}
Consequently, you can't actually expect to capture 100% of these analytics events nor even expect the percentage captured to stay the same over time since the filter lists are very regularly updated and users enable/disable different ad blockers over time.
More broadly speaking, once you have sent a webpage to the user, you should not expect anything from the user's browser. They may or may not allow whatever arbitrary JS you have on the page. They may even intentionally give you bad data (e.g. hijack the payload to give you intentionally malformed data).
edit: even more broadly speaking, there's additional reasons why you can't expect to receive these kinds of callbacks: consider what happens if a user loses connectivity between loading the page and them navigating away (e.g. their phone loses service because they went into an elevator before navigating away)