Interesting that "broken access controls" made it into the top spot. Not sure if this anecdotal but recently I've seen many "hacks" of apps built with external BaaS & auth providers that rely on some kind of token-based authentication, either via JWT or opaque tokens. What happens is that often the providers offer good support for role-based access control but developers just plain ignore it and e.g. include tokens with global read permissions into the app code, or do not properly restrict the permissions of individual tokens, making it possible to e.g. read the whole database with a normal user token. The researcher collective Zerforschung [1] e.g. has uncovered many such incidents. That might have to do with the fact that in my experience those BaaS frameworks and other low-code tools are mostly used by teams with a strong focus on product and UI/UX, which don't have deep security expertise or the right mindset. I think overall outsourcing of aspects like authentication can be beneficial, but only if teams adopt or retain a healthy security awareness as well.
I worked on an identity provider platform and this was always such a huge problem. Many application developers treat authentication as an all or nothing proposition: either a user is authenticated or they are not, but the reality is that authorization is truly hard part and often completely overlooked. This is especially true in Oauth2/OIDC schemes where JWT bearer tokens are issues. At that point you are delegating token validation and access control out to all clients. Even if you are using opaque tokens to prevent basic token verification issues, you still just end up doing the token validation for the client. They still are responsible for access controls on specific resources.
> the reality is that authorization is truly hard part
Not only is it under often estimated, but in many orgs it's also reduced to a single checkbox item on someone's go-to-market slide. ":thumbsup - we're secure now!". Instead it needs to be a constant part of the culture, in every feature from the first, and ongoing thereafter.
Out of topic, I use oidc provider (keycloak). I fetch the public key from oidc provider then verify the bearer token with it. Then use the permissions field to authorize users based on their permission. Does my approach correct / suffice?
That's the idea of the JWT, no DB query or in this case additional network request needed to authenticate.
Depending on your use case it's worth thinking about the expiration time. I assume that's checked in your client but do you also need to invalidate tokens or downgrade permissions before they expire? In that case you might want to work with smaller expiration times or get a denylist.
In general, yes that is exactly what you are supposed to do. But the really hard part is determining what scopes (which is what I assume you are referring to here as permissions) allow access to which resources/actions.
I'm always wondering what the right approach is when using third party authentication. Use scopes or just store user identifier and permission in your own database.
I have seen the two authorization approaches get co-mingled, which leads to issues.
Also, often scopes are two large.. but that's mostly an implementation choice, like read all, rather than allow access to only a specific item - maybe scopes are just less easy to handle/maintain/define for the average developer.
> I have seen the two authorization approaches get co-mingled, which leads to issues.
Correct, for me this is a must avoid at all costs. I can't imagine how hard / complex it is to manage / audit two authorization system. Unless your application need more detailed permission / smaller scope, example later.
Personally I just use the one that comes from the identity provider. In my case, keycloak's model is sufficient for my use case.
And you're right, scopes are hard and unless it's global scope, you'll need to roll your own. One good example case is github/gitlab. Global scope is the administrator access, and it's easy to set it in identity provider (as "administrator" access maybe).
However for each group / repository level, you'll need to roll your own validation.
EDIT: More often than not, it comes into business domain than technical / programming one. If you're not experienced with the business domain, no wonder you'll find it hard.
> That might have to do with the fact that in my experience those BaaS frameworks and other low-code tools are mostly used by teams with a strong focus on product and UI/UX, which don't have deep security expertise or the right mindset.
I've had the same experience. Often these are teams who experience being asked to think about access controls as a roadblock on their way to product Nirvana. Security quickly becomes something to be avoided, often right up to the point where something goes rather embarrassingly wrong.
I can tell you exactly why this happens in many companies, and it's two part.
1) These teams are usually sponsored and beholden to business instead of IT. Consequently, they care about business needs first, and good coding practices second. You can imagine how that goes, given limited project time.
2) These teams usually have poor relationships with the keepers of the IAM keys. This adversarial relationship generally takes the form of (a) IAM is asked to create an appropriate permission, (b) IAM doesn't think the way things are being done is correct and doesn't want to spend the time to correct them, (c) team just throws up their hands up and asks for a standard (overbroad) permission set.
In many places, it's easier to get an exception and admin permissions than it is to get something more specific created.
The left hand (business) saying "No one will solve this problem for us" and the right hand (IAM / security) saying "You shouldn't have to do this, so we're not going to help you" is the cause of most glaring security holes.
IMO, the rise of microservice, SPA, mobile apps or api based apps also contribute to this. It's far easier (and more easily detected / spotted) to restrict access from monolith, server side rendering based web applications.
It's far easier to enforce information Access control in a services oriented architecture.
In a monolith, a developer doesn't even have to use an access controlled API. They can simply access sensitive data through underlying access mechanisms and return it through an inappropriate endpoint.
Agree, only if you have the proper manpower, good QC and security standard in your company. For those with smaller and inexperienced team, it's easier to do it in server-render based monolith application.
I've seen a fair bit of this with Firebase apps, where devs don't write enough rules, or have collections that mix non-sensitive and sensitive fields. It's tricky, because the whole query-the-database-from-JavaScript model causes your app to fail open. I wrote a tool that acts as a generic Firebase datastore client to help find these sorts of flaws.[1]
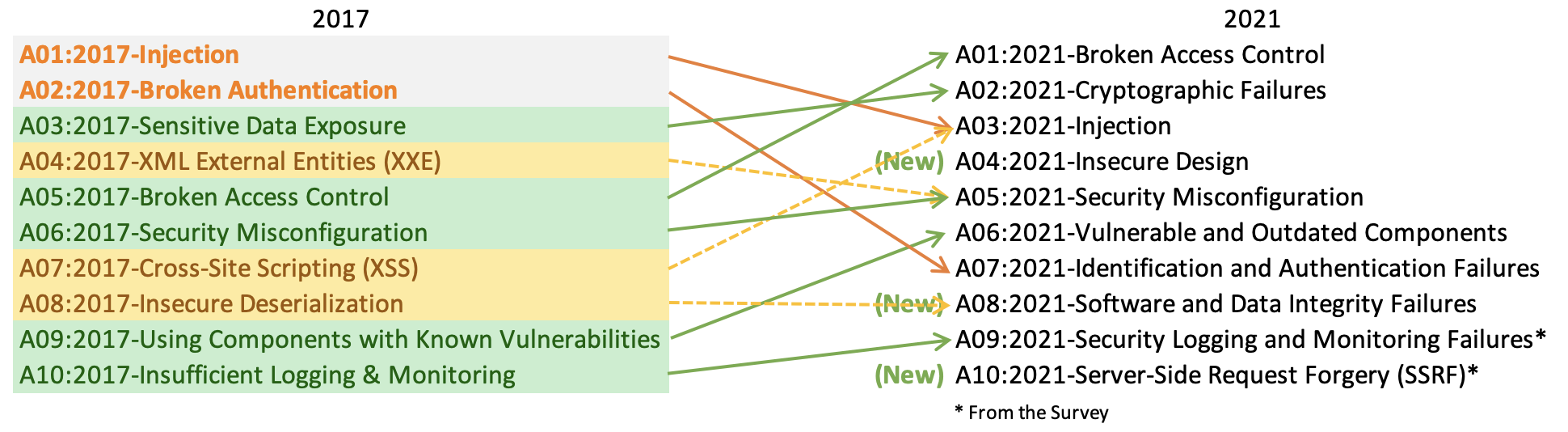
The former category for XML External Entities (XXE) is now part of [Security Misconfiguration].
Insecure Deserialization from 2017 is now a part of [Software and Data Integrity Failures] [...] focusing on making assumptions related to software updates, critical data, and CI/CD pipelines without verifying integrity.
These seem like nonsense statements. XXE's aren't misconfiguration (in any sense that a myriad of other vulnerabilities aren't "misconfigurations" of libraries), and deserialization bugs aren't software update bugs (I don't even know what CI/CD is doing in that description).
The OWASP Top 10 is rapidly losing coherence.
It's important not to take it too seriously. For all the pantomime about survey data, there's not much real rigor to it. It's mostly a motivational document, and a sort of synecdoche for "all of web app security".
The best part of this is the end, where they say "we have no data to support having SSRF on the list, but 'industry people' tell us it's too important not to". Gotta side with the industry people on that one. But maybe you can cram it into "Insecure Design" next year and be rid of it!
Every (software engineering) job I've had has had OWASP trainings, if not explicitly listed knowledge and integration of OWASP principles as a job responsibility for levels above entry. What sort of security principles do you follow?
For the "broken access controls", "cryptographic failures", and "bad design" categories, I've been working on an open source project to help mitigate those.
It's still early and I haven't released it yet, but I have the docs[0] deployed now. If anybody feels like helping us test this early, I'd love some feedback. We're going to be pushing the code live in a week or so. (It's been a lot of building for a while now)
I've been thinking about these problems for a while now (as a security engineer) and it's cool to see that my intuition is roughly in line with what OWASP is seeing these days. It's always hard to know if the problems you see people struggling with are representative of the industry as a whole, or if you're just in tunnel vision.
Note: We're building this as a company so that we can actually afford to continue doing this full time. I'm still learning how to find the line between open source and a viable business model. Any thoughts would be appreciated[1]!
> "To understand how data is encrypted at rest with the LunaSec Tokenizer, you can check out How LunaSec Tokens are encrypted."
It seems to me that all you're doing is providing encryption-at-rest-as-a-service. Why shouldn't your clients simply skip the middle-man and encrypt the data at rest themselves (entirely avoiding the traffic and costs incurred with using your services)?
Moreover, why should clients trust you with their sensitive customer content, encryption not withstanding? What are your encryption-at-rest practices and how can you guarantee they are future-proof?
And finally - your API is going to be a major single-point-of-failure for your clients. If you're down, they're down. How do you intend to mitigate that?
The whole thing is full of really strange and dubious promises, like this one:
> "In the LunaSec Token crypto system, information for looking up a ciphertext and encryption key given a token is deterministically generated using the token itself. A signed S3 URL configured to use AWS's Server Side Encryption is used for when uploading and downloading the ciphertext from S3."
What if an attacker figures out how the decryption key is "deterministically" derived? This attack vector would be devastating for you actually - since you can't just change the derivation algorithm on a whim: you would need to re-encrypt the original customer content AND somehow fix the mappings between the old tokens your client keeps in their database, and the new ones you'd have to generate post changing the algorithm. This is an attack that brings down your whole concept.
Then, there's issues like idempotency. Imagine a user accessing a control panel where they can set their "Display Name" to whatever they like. With your current design, it looks like you'll be generating new records for each such change. Isn't that wasteful? What happens to the old data?
Also, what happens if your clients lose their tokens somehow? Does the data stay in your possession forever?
Lots of big holes in this plot. I suggest you guys to get a serious security audit done as early as possible (by a reputable company) before proceeding with building this product. Some of this just reads like nonsense at the moment. CISOs (your main customers) can smell this stuff from miles away.
Thanks for taking the time to read through this and write some feedback for me. I sincerely appreciate it!
I wrote this post late last night, so pardon the delay with responding. Sleep happens.
> It seems to me that all you're doing is providing encryption-at-rest-as-a-service. Why shouldn't your clients simply skip the middle-man and encrypt the data at rest themselves (entirely avoiding the traffic and costs incurred with using your services)?
There is nothing stopping clients from making that call for themselves. At my previous employers, I've built similar systems multiple times. In those cases though, we had always checked first for any open source solutions. At that time, none of them fit the bill though so we ended up building it in house.
Which leads into your second point about "avoiding traffic and costs". We're making this open source and something that clients can self-host themselves precisely for that reason. Other players in the "Tokenization" market aren't open source or even generally self-hostable. That's one of the key differentiators of what we're building.
> Moreover, why should clients trust you with their sensitive customer content, encryption not withstanding?
Well, they don't have to. It's open source. They can check the code out themselves. And, with way we've designed the system, there is no "single point of failure" that results in leaking all of the data.
> What are your encryption-at-rest practices and how can you guarantee they are future-proof?
The encryption-at-rest uses AES-256-GCM which is implemented by Amazon S3. So, that part of the puzzle is well solved.
The rest of our system uses off-the-shelf crypto hashing (SHA-3). For the key derivation algorithms, we've implemented NIST SP 800-108 [0]. The key derivation is basically a cryptographically secure random number generator using the output of the SHA-3 hash as the seed. We use it to generator multiple random values. I'll expand on this in the docs soon (and you'll be able to read the source code).
We're intentionally not attempting to do anything novel with actual crypto math. We're just using existing, basic primitives and chaining them together (again, in accordance with the NIST paper I linked).
> And finally - your API is going to be a major single-point-of-failure for your clients. If you're down, they're down. How do you intend to mitigate that?
Well, it's open source and self-hosted. That's one of the primary goals for the system in order to _avoid_ this use case. At my previous employers, when we evaluated vendor solutions, those were both blockers to our adoption. Being beholden to a questionable vendor is a crappy situation to be in when you have 5+ 9s to maintain.
A common approach to adding "Tokenization" to apps (used by companies like VeryGoodSecurity) is to introduce an HTTP proxy with request rewriting. They rewrite requests to perform the tokenization/detokenization for you. It's simple to onboard with, but it has a ton of caveats (like them going down and tanking your app).
We've also designed this to "gracefully degrade". The "Secure Components" that live in the browser are individual fields. If LunaSec goes down, then only those inputs break. It's possible that breaks sign-ups and is also crappy, but at least not _everything_ will break all-at-once.
Finally, we've also designed the backend "Tokenizer" service to be effectively stateless. The only "upstream" service that it depends on it Amazon S3. And that's the same as the front-end components. By default, Amazon S3 has 99.99% availability. We have plans to add geo-replication support that would make that 6+ 9s of availability by replicating data.
> What if an attacker figures out how the decryption key is "deterministically" derived?
This is a real attack scenario, and something we've designed around. I'll make sure to write some docs to elaborate on this soon.
TL;DR though: If an attacker is able to leak the "Tokenizer Secret" that is used to "deterministically derive" the encryption key + lookup values, then they will _also_ need to have a copy of every "Token" in order for that to be valuable. And, in addition, they also need access to read the encrypted data too. By itself, being able to derive keys is not enough. You still need the other two pieces (the token and the ciphertext).
> You would need to re-encrypt the original customer content AND somehow fix the mappings between the old tokens your client keeps in their database, and the new ones you'd have to generate post changing the algorithm. This is an attack that brings down your whole concept.
You're right that this is a painful part of the design. The only way to perform a full rotation with a new "key derivation algorithm" is to decrypt with the old key and re-encrypt everything with the new key.
That's the nature of security. There is always going to be some form of tradeoff made.
Fortunately, there is a way to mitigate this: We can use public-key cryptography to one-way encrypt a copy of the token (or the encryption keys, or all of the above). In the event of a "full system compromise", you can use the private key to decrypt all of the data (and then re-encrypt it without rotating the tokens in upstream applications).
For that case, you would need to ensure that the private-key is held in a safe place. In reality, you'd probably want to use something like Shor's algorithm to require multiple parties to collaborate in order to regenerate the key. And you'd want to keep it in an safe deposit box, probably.
> Then, there's issues like idempotency. Imagine a user accessing a control panel where they can set their "Display Name" to whatever they like. With your current design, it looks like you'll be generating new records for each such change. Isn't that wasteful? What happens to the old data?
We did intentionally choose for this to be immutable because allowing mutable values opens up an entirely separate can of worms. Being able to distribute the system becomes a much harder problem, for example, because of possible race conditions and dirty-read problems. Forcing the system to be immutable creates "waste" but it enables scalability. Pick your poison!
For old data, the approach we're using is to "mark" records for deletion and to later run a "garbage collection" job that actually performs the delete. If a customer updated their "Display Name", for example, then the flow would be to generate a new token and then mark the old one for deletion. (And using a "write-ahead-log" to ensure that the process is fault-tolerant.)
> Also, what happens if your clients lose their tokens somehow?
This is again another tradeoff of security. By removing the Tokens from the Tokenizer entirely, you gain security at the expense of additional complexity (or reduced usability). You make it harder for an attacker to steal your data by also requiring them to get their hands on tokens, but you also force yourself to not lose access to your tokens in order to read data. It becomes very important to take backups of your databases and ensuring that those backups can't easily be deleted by an attacker.
This is mitigated with the "token backup vault using public-key" strategy I outlined above. But if you somehow lost those keys, then you'd be in a bad spot. That's the tradeoff of security.
> Does the data stay in your possession forever?
It's self-hosted by default. (Well, technically Amazon S3 stores the data.)
We may eventually have a "SaaS" version of the software, but not right away. When we do get there, we'll likely continue relying on S3 for data storage (and we can easily configure that to be a client-owned S3 bucket).
> I suggest you guys to get a serious security audit done as early as possible (by a reputable company) before proceeding with building this product.
It's on the roadmap to get an independent security review. At this point in time, we're relying on our shared expertise as Security Engineers to make design decisions. We spent many months arguing about the exact way to build a secure system before we even started writing code. Of course, we can still make mistakes.
We have some docs on "Vulnerabilities and Mitigations" in the current docs[1]. We need to do a better job of explaining this though. That's where getting feedback like yours really helps us though -- it's impossible for us to improve otherwise!
> Some of this just reads like nonsense at the moment.
That's on me to get better at. Writing docs is hard!
Thanks again for taking the time to read the docs and for the very in-depth feedback. I hope this comment helps answer some of the questions.
We've spent a ton of time trying to address possible problems with the systems. The hardest part for us is to convey that properly in docs and to help build trust with users by you. But, that's just going to take time and effort. There is no magic bullet except to keep iterating. :)
We have a few different strategies for this. You can read through the "levels" here[0]. (We need to expand on this doc still)
Level 1: There are no grants.
Level 2: Access requires a "shared secret" in order to authenticate to the Tokenizer. If you have the secret, get API access to the Tokenizer, and you have a copy of a token, then you can create a grant. In order to use the grant, you also need a valid session for the front-end, but if you have RCE on the back-end then you can get this pretty easily.
Level 3: Creating grants also requires presenting a JWT that's signed by an upstream "Auth Provider" that also proxies traffic. This JWT is only able to create grants that are scoped to a specific session (which is identified using a "session id" inside of the JWT).
You can still create a grant every token you have access to, but you need to get a valid session to do so. In this design, the proxy strips the cookies from the request and only forwards the JWT, which adds another step to the attack (you have to be able to login to on a browser).
This requires that you put your "Root of Trust" into your authentication provider, so you would want to "split" out your authentication/session creation into another service. We have an example app + tutorial explaining this that we'll publish soon.
Level 4: You write a separate function,called a "Secure Authorizer", that accepts a session JWT and a Token in order to "authorize" that a grant can be created for a given user.
This function is deployed in a hardened container and is difficult to attack (a network restricted Lambda).
By adding this layer, you now require that an attacker is able to generate sessions for any user that they want to leak data from. Or you require them to attack the "Secure Authorizer". It's a much more painful attack for an attacker to pull off once you've integrated all of these layers.
Does that answer your question? I'll make sure go add this explanation into that levels page.
New to the list is Server-Side Request Forgery (SSRF), where you trick the remote server to fetch a sensitive URL on an attackers behalf (eg, internal service or cloud metadata URL from the context of an internal server), a language-agnostic defense is using something like Stripe's Smokescreen [1] which acts as a SOCKS proxy your app connects to when requesting URLs that should be quarantine'd, and it does the enforcement of access to internal/external IPs or not.
This hit home for me. On a recent penetration test (via an external auditor), an app I'm responsible for was found to have a pretty bad SSRF vulnerability via a server-side PDF rendering component.
Luckily it was a bit obscure to find, had never been exploited, and we patched it within a few hours, but it was the most significant vulnerability found in anything I've been involved in.
Not come across Smokescreen (very cool) but this would have been one of a number of additional measures we could have put in place to avoid our vulnerability. I'm going to seriously consider using something like that going forward for all outbound server initiated requests.
SSRFs are great fun and used on pentests a lot. One of my favourites was where you could hit the cloud metadata service from an application and potentially get credentials back.
We put together an HTTPS MITM proxy so we can log and filter also HTTP methods and URLs (or even content) for egress access from our infrastructure. An HTTP connect proxy only sees host names and the IPs they resolve to.
It not easy to prevent data exfiltration if you allow connections to, say, S3 and the attacker can just send arbitrary data to their personal bucket.
We built something similar at both Uber and Snap. Thanks for sharing this link to an open source equivalent! I wish it had existed a few years ago when I had looked. Oh well!
> "We built something similar at both Uber and Snap. Thanks for sharing this link to an open source equivalent! I wish it had existed a few years ago when I had looked. Oh well!"
Why not just use a firewall? The technology has been around since the 80s?
If you're running on AWS (EC2, Lambda, ECS, EKS, etc), for example, you can query `http://169.254.169.254/latest/meta-data/` and it'll return a valid AWS access token. (That's how attaching IAM permissions to an EC2 box works.)
That's being replaced with v2[0] but, at the time when I was building these SSRF proxies, that didn't exist.
Beyond that case, it's also pretty common to have sidecar processes running on the same machine in modern Kubernetes deployments. Having an additional firewall proxy is too expensive for certain high performance environments, so it's commonly assumed that traffic to sidecars is trusted. (Mutual TLS is being used more frequently now, but that's non-trivial to deploy because key management is a PITA)
Interesting, it's worth noting that the scheme can sometimes also be used to cause SSRF to a different protocol which might not use http, like ftp or gopher, s3,...
SSRF are fun, sometimes the leak credentials directly also - when server is based on a trusted subsystem the auth headers might leak outside.
The problem described here is solved by using a firewall, where certain machines/processes are either allowed or disallowed to communicate with other machines/processes based on a set of rules. What else is there to it?
As a practical example, your service may receive a URL from the user to load as input, and you want it to not load the local cloud metadata endpoint (that holds the EC2 instance profile access token, for example), but at the same time, other parts of your code still need to access that endpoint to get the latest credentials.
The point is being able to place a particular (but not all) HTTP(s) requests in a sandbox when you don’t want to allow it “privileged” access to endpoints.
If you simply firewall the metadata end point (or other microservice your app needs) then none of your app code that needs it will work either.
> "If you simply firewall the metadata end point (or other microservice your app needs) then none of your app code that needs it will work either."
Just use a local on-box proxy with a firewall (or a dedicated virtual NIC with a firewall, doesn't matter, it's practically the same thing). Have your specific part of the code issue calls that pass through that specific proxy (or the virtual NIC). Apply whatever firewall rules you need.
This solution involves literally zero lines of in-house code to keep and maintain. It builds on the same industry-standard tools we've developed for the last 40 years. Provides all the flexibility and visibility you'll ever need. It's modular, and can extend to accommodate new requirements as they come.
But I guess it just doesn't look as fancy on your CV though.
Network firewalls don't usually work well as a strong control in this scenario, because if the application is hosted in AWS (or GCP, Azure, etc.) then IP addresses of the systems the app is connecting to are constantly changing, can number in the hundreds or thousands, and can often be anywhere in the address space (whether that's private or the public blocks allocated to the provider), so you pretty much need an allow-all rule to all of the subnets that an attacker would care about anyway, because trying to maintain a list of specific IPs is impractical.
There are use cases for network firewalls in cloud environments,but this isn't one of them.
Some interesting changes in the Top 10 this time around and in general, I think they're good changes.
It does suffer a little bit though from some of the entries being quite wide ranging and non-specific, which I think could leave people scratching their heads about exactly what's involved.
I'm glad to see that monitoring and logging is still included as, in many years as a web app pentester, it was really common to see no application level detection and response to security attacks.
Speaking of non-specific, what exactly is A04:2021-Insecure Design supposed to be? That category sounds almost circular in its reasoning: Your software isn't secure because... it's design is insecure?
This is what the submission says about "Insecure Design"
> A04:2021-Insecure Design is a new category for 2021, with a focus on risks related to design flaws. If we genuinely want to "move left" as an industry, it calls for more use of threat modeling, secure design patterns and principles, and reference architectures.
Seems pretty clear it's about upfront security thinking, planning and education. Of course all of these items in the list are gonna be general as they are categories, not specific line items.
I interpreted that one (perhaps too charitably) as being about business logic flaws, design decisions that are inherently dangerous, that sort of thing.
i.e. most of the other things on the list are issues that were introduced unintentionally, and this one is about decisions made by designers and developers that were themselves the problem.
Yup this is what I read, and covers a lot of security reviews I have come across, where someone requests some functioanlity, such as password recovery, or some promotional code, and someone else discovers how it can be exploited.
1. Providing a permission based check to prevent a user from accessing a specific UI page but then failing to secure the back-end API endpoint that supports the UI.
A developer implementing a user story reads the following acceptance criteria, "User without permission X cannot see page Y." and proceeds to prevent the UI page Y from rendering if the user doesn't have permission X. They completely ignore securing the back-end API endpoint as that's not a requirement. Now you have a back-end API endpoint that isn't doing any permission checks and anyone can call it even if they don't have permission X.
2. Allowing different values to be used when checking authorization and subsequently persisting data.
The application logic is written to check that the user has access to the order identified in the URL (144). But the payload has a different order id (555). The application allows the item to be added to the order but in this case the order being altered is order number 555 and not the order that the user originally had the ability to add items to, 144.
yeah that's the kind of entry I'm thinking about. I'm hopeful that in the full version they'll explain more detail but it will need that explanation to make it meaningful.
The homepage does a very poor job of giving any context, so for those who (like me) who have no clue what they're looking at: This list represents a broad consensus about the most critical security risks to web applications. See https://owasp.org/www-project-top-ten/ for more details (OWASP = "Open Web Application Security Project").
Just to give some more context; this is a list that has been updated every 2-4 years since around 2004 or so. A lot of orgs treat it as the minimum a developer needs to know in terms of security, so it's time well spent looking through it (IMO)
"The Open Web Application Security Project® (OWASP) is a nonprofit foundation that works to improve the security of software. Through community-led open-source software projects, hundreds of local chapters worldwide, tens of thousands of members, and leading educational and training conferences, the OWASP Foundation is the source for developers and technologists to secure the web."
About the OWASP Top 10
"The OWASP Top 10 is a book/referential document outlining the 10 most critical security concerns for web application security. The report is put together by a team of security experts from all over the world and the data comes from a number of organisations and is then analysed."
Seems pretty spot on to me. And OWASP should be very well known by anyone working in the web field.
I'm not sure server-side request forgery needs to be its own category where request forgery covers things from all sides.
Server-side attacks are more common as systems get more complex and have many moving parts that need be able to trust each other (in microservice architectures for instance), but failing to account for forgery at all levels is more a security-in-depth failure (fitting in the new very vague “insecure design” category?).
Unless I'm misunderstanding what is being meant here, which is far from impossible!
I mentally bucket Server-side request forgery separately from Client-side request forgery because of who it impacts.
- With SSRF, I'm tricking your server-side system into requesting and returning to me something it shouldn't (local/intranet files, local/intranet network responses, the EC2 instance metadata endpoint). As a developer, SSRF can leak my app/infra/data/secrets to an outside attacker
- With CSRF, I'm tricking a legit user into performing an authenticated action an existing application allows. Much closer to automated click-jacking.
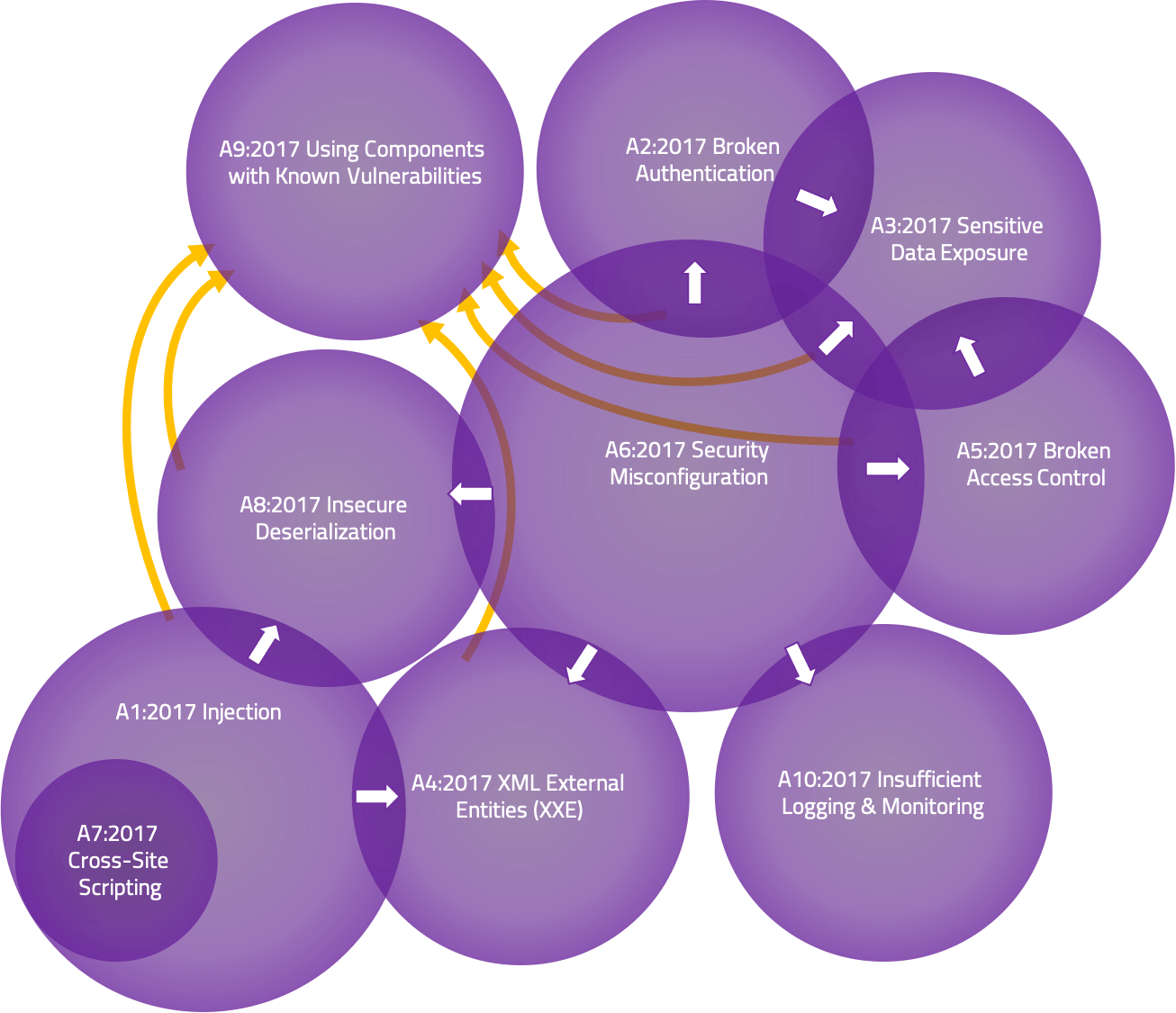
Notice the Venn Diagram at the bottom of the page. If you were going to put money in a security solution you would do your best work if you made sure your security related configurations were correct and remained in place. (Least privilege configuration and Change Control). It affects every other category except injection and known vulnerabilities. So then you would make sure you had good life cycle management and patch management to address the issues with software vulnerabilities and then make sure you use Prepared Statements (with Parameterized Queries) or properly constructed Stored Procedures. This is where your focus and money should go before you start doing anything else.
Seems like this is still a draft and release will be later this month. Still specially design and CI/CD seem good points to include from security professional's perspective.
I'm honestly happy I see "Insecure Design" into the list. With all the buzzwordy Agileness people often forget that (at least) high level design is important and brings a lot of value if done early on.
I wonder which one the "REST endpoint just JSON serializes and spits out the whole database row" problem falls under now? I previously thought sensitive data exposure included this case.
Wow! Great job! Readability is extremely important! By making it easier to see what the current major threats are will make us more focused and secure in the long run!
Authentication and Broken Access Controls are two separate categories. I would have put authentication as a subset of Broken Access Controls. At saas pass we see authentication and mfa as a subset of identity and access management and the access controls.
{kind=link}
{kind=link}
[1] https://twitter.com/zerforschung