I think it'll be a good thing when people stop worrying about process node technology and start worrying about performance and power usage.
Intel's 14nm chips are already competitive with AMD's (TSMC's, really) 7nm chips. The i7-11700 or whatever the newest one coming out soon is called, is going to be pretty much exactly on parity with AMD's Ryzen 5000 series.
So if node shrinkage is such a dramatic increase in performance and power usage, then when Intel unfucks themselves and refines their 10nm node and 7nm node and whatever-node after that, they'll clearly be more performant than AMD... and Apple's M1.
Process technology is holding Intel back. They fix that, they get scary again.
Since AMD has introduced its first 7 nm chip, Intel's 14-nm chips have never been competitive.
Intel's 14-nm process has only 1 advantage over any other process node, including Intel's own 10 nm: the highest achievable clock frequency, of up to 5.3 GHz.
This advantage is very important for games, but not for most other purposes.
Since the first 7-nm chip of AMD, their CPUs consume much less power at a given clock frequency than Intel's 14 nm.
Because of this, whenever more cores are active, so that the clock frequency is limited by the total power consumption, the clock frequency of the AMD CPUs is higher than of any Intel CPU with the same number of active cores, which lead to AMD winning any multi-threaded benchmark even with Zen 2, when they still did not have the advantage of a higher IPC than Intel, like they have with Zen 3.
With the latest Intel's 10 nm process variant, Intel has about the same power consumption at a given frequency and the same maximum clock frequency as the TSMC 7 nm proces.
So Intel should have been able to compete now with AMD, except that they still appear to have huge difficulties in making larger chips in sufficient quantities, so they are forced to use workarounds, like the launch of the Tiger Lake H35 series of laptop CPUs with smaller dies, to have something to sell until they will be able to produce the larger 8-core Tiger Lake H CPUs.
"This advantage is very important for games, but not for most other purposes."
I disagree. The majority of desktop applications are only lightly threaded e.g. Adobe products, office suites, Electron apps, anything mostly written before 2008.
Save for heavy lifting in Adobe products those other apps don't meaningfully benefit from higher clock speeds as their operations aren't CPU bound. The high speed Intel chips see an advantage when there's a single CPU bound process maxing out a core. Office and Slack don't tend to do that (well maybe Slack...). Also if you've got multiple processes running full tilt Intel's clock speed advantage goes away because the chip clocks down so as to not melt.
So with a heavy desktop workload with multiple processes or threads the Intel chips aren't doing any better than AMD. It's only in the single heavy worker process situation where Intel's got the advantage and that advantage is only tens of percentage points better than AMD.
So Intel's maximum clock speed isn't the huge advantage it might seem.
You are right that those applications benefit from a higher single-thread performance.
Nevertheless, unlike in competitive games, the few percents of extra clock frequency that Intel previously had in Comet Lake versus Zen 2 and which Intel probably will have again in Rocket Lake versus Zen 3, are not noticeable in office applications or Web browsing, so they are not a reason to choose one vendor or the other.
>Intel's 14nm chips are already competitive with AMD's (TSMC's, really) 7nm chips.
The only metric that Intel's 14nm is better than TSMC's 7nm is clock speed ceiling. Other than that there is nothing competitive from an Intel 14nm chip compares to AMD ( TSMC ) 7nm chip from a processing perspective.
And that is not a fault of TSMC or AMD. They just decide not to pursuit that route.
> I think it'll be a good thing when people stop worrying about process node technology and start worrying about performance and power usage.
I think it's more that people attribute too much significance to process node technology when trying to understand why performance & power are what they are.
For single-core performance the gains from a node shrink are in the low teen percentage increases. Power improvements at the same performance are a bit better, but still not as drastic as people tend to treat it as.
10-20 years ago just having a better process node was a massive deal. These days it's overwhelmingly CPU design & architecture that dictate things like single-core performance. We've been "stuck" at the 3-5ghz range for something like half a decade now and TSMC has worse performance here than Intel's existing 14nm. Still hasn't been a single TSMC 7nm or 5nm part that hits that magical 5ghz mark reliably enough for marketing, for example. And that's all process node performance is - clock speed. M1 only runs at 3.2ghz - you could build that on Intel's 32nm without any issues. Power consumption would be a lot worse, but you could have had "M1-like" single-core performance way back in 2011 if you had a time machine to take back all the single-core CPU design lessons & improvements, that is.
While you are right that due to their design CPUs like Apple M1 can reach the same single-thread performance as Intel/AMD at a much lower clock frequency and such a clock frequency could be reached much earlier, e.g. already Intel Nehalem in 2009 reached 3.3 GHz as turbo, while Sandy Bridge in 2011 had 3.4 GHz as base clock frequency, it would have been impossible to make a CPU like Apple M1 in any earlier technology, not even in Intel's 14 nm.
To achieve its very high IPC, M1 multiplies a lot of internal resources and also uses very large caches. All those require a huge number of transistors.
Implementing an M1-like design in an earlier technology would have required a very large area, resulting in a price so large and also in a power consumption so large that such a design would have been infeasible.
However, you are partially right in the sense that Intel clearly was overconfident due to their clock frequency advantage and they have decided on a roadmap to increase the IPC of their CPUs in the series Skylake => Ice Lake => Alder Lake that was much less ambitious than it should have been.
While Tiger Lake and Ice Lake have about the same IPC, Alder Lake is expected to bring a similar increase like from Skylake to Ice Lake.
Maybe that will be competitive with Zen 4, but it is certain that the IPC of Alder Lake will still be lower than the IPC of Apple M1, so Intel will continue to be able to match the Apple performance only at higher clock frequencies, which cause a higher power consumption.
> To achieve its very high IPC, M1 multiplies a lot of internal resources and also uses very large caches. All those require a huge number of transistors.
Yes & no. Most of the M1 die isn't spent on CPU, it's spent things like GPU, neural net, and SLC cache. A "basic" dual-core CPU-only M1 would be very manufacturable back in 2011 or so. After all, Intel at some point decided to spend a whole lot of transistors adding a GPU to every single CPU regardless of worth, there were transistors to spare.
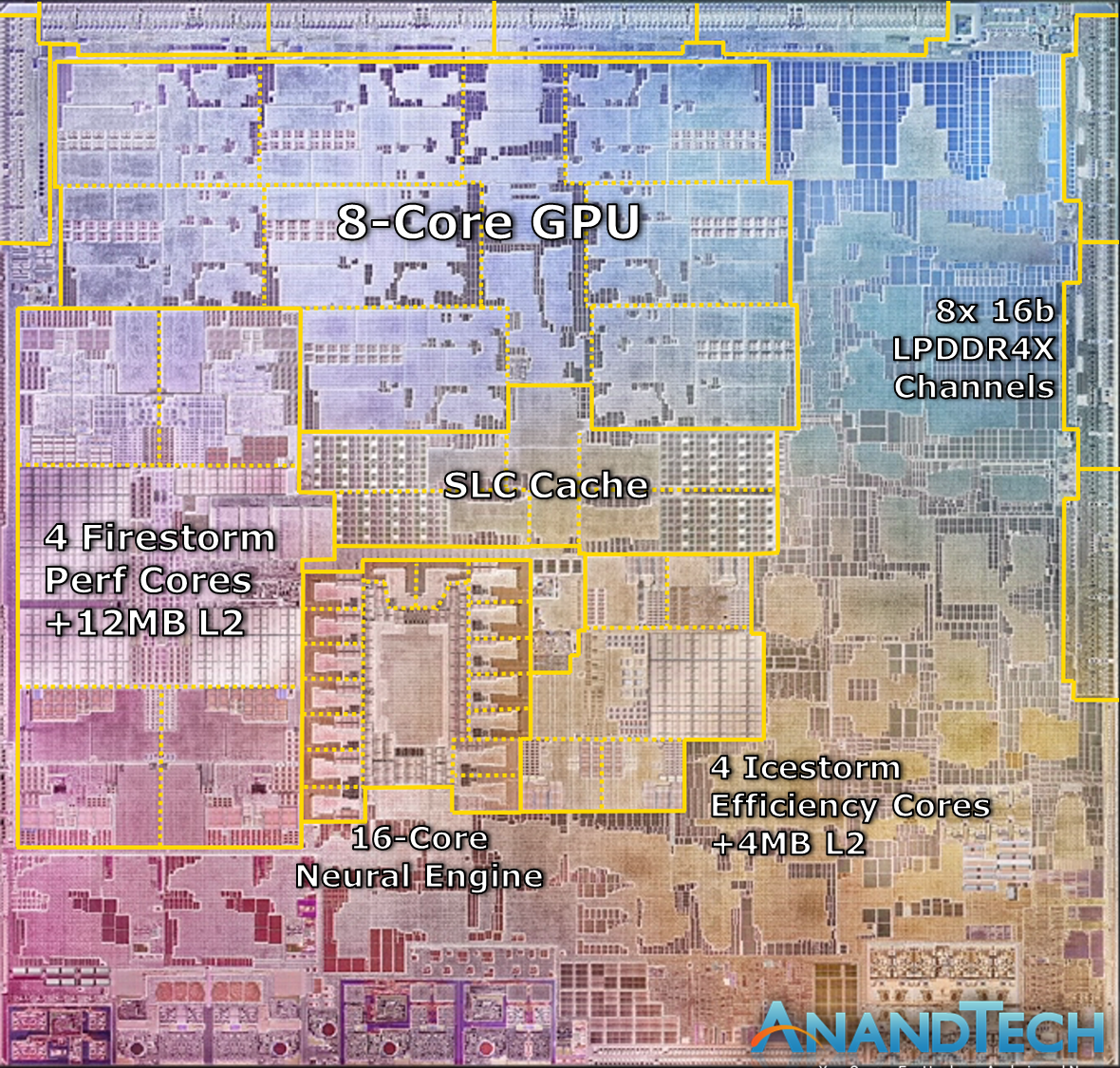
Where are you getting your M1 CPU + memory controller is about a third of the M1 die from? Looking at this die shot + annotation: https://images.anandtech.com/doci/16226/M1.png The firestorm cores + 12MB cache is far less than 1/3rd the die, and the memory controller doesn't look particularly large.
The M1 total is 16B transistors. A 2700K on Intel's 32nm was 1.1B transistors. You're "only" talking something like ~4x the size necessary if that. Of course the 2700K already has a memory controller on it, so you really just need the firestorm cores part of the M1. Which is a _lot_ less than 1/3rd of the die size.
But lets say you're right and it is 1/3rd. That means you need ~5B transistors. Nvidia was doing 7B transistors on TSMC's 28nm in 2013 on consumer parts (GTX 780)
A very large part of the die is not labelled and it must include some blocks that cannot be omitted from the CPU, e.g. the PCIe controller and various parts from the memory controller, e.g. buffers and prefetchers.
The area labelled for the memory channels seems to contain just the physical interfaces for the memory, that is why it is small. The complete memory controller must include parts of the unlabelled area.
Even if the CPU part of M1 would be smaller, e.g. just a quarter, that would be 30 square mm. In the 32 nm technology that would likely need much more than 1000 square mm, i.e. it would be impossible to be manufactured.
The number of transistors claimed for various CPUs or GPUs is mostly meaningless and usually very far from the truth anyway.
The only thing that matters for estimating the costs and the scaling to other processes is the area occupied on the die, which is determined by much more factors than the number of transistors used, even if that would have been reported accurately. (The transistors are not identical, they can have very different sizes and the area of various parts of a CPU may be determined more by the number of interconnections than by the number of transistors.)
> that would be 30 square mm. In the 32 nm technology that would likely need much more than 1000 square mm,
Where are you getting that scaling from? Intel's 32nm is reported at 7.5Mtr/mm2 while TSMC's 5NM is 171Mtr/mm2. 30 sqmm of TSMC 5nm in 32nm would therefore be around 660 sqmm. That's definitely on the large side, but yet again chips nearly that large were manufactured & sold in consumer products.
> A very large part of the die is not labelled and it must include some blocks that cannot be omitted from the CPU, e.g. the PCIe controller and various parts from the memory controller, e.g. buffers and prefetchers.
You need those things to have a functional modern SoC, but you don't need as much or of the same thing to have just a desktop CPU without an iGPU, nor to have just the raw compute performance of the M1. It'll be a heck of a lot harder to feed it on dual-channel DDR3, for sure, but all those canned benchmarks that fit in cache would still be just as fast.
{kind=link}
Intel's 14nm chips are already competitive with AMD's (TSMC's, really) 7nm chips. The i7-11700 or whatever the newest one coming out soon is called, is going to be pretty much exactly on parity with AMD's Ryzen 5000 series.
So if node shrinkage is such a dramatic increase in performance and power usage, then when Intel unfucks themselves and refines their 10nm node and 7nm node and whatever-node after that, they'll clearly be more performant than AMD... and Apple's M1.
Process technology is holding Intel back. They fix that, they get scary again.