Careful abusing these tricks. Over 10 years ago I decided to implement an RC4 (arcfour) cypher to generate pseudorandom noise for a test program.
The algorithm looks like (from wikipedia):
i := 0
j := 0
while GeneratingOutput:
i := (i + 1) mod 256
j := (j + S[i]) mod 256
swap values of S[i] and S[j]
K := S[(S[i] + S[j]) mod 256]
output K
endwhile
Being a smartass 1337 coder (and declaring intermediate variables always being a bit of a bother in C89) in my implementation I decided to implement the swap using the xor trick:
s[i] ^= s[j];
s[j] ^= s[i];
s[i] ^= s[j];
I then ran a few basic test vectors, everything seems to work fine.
A little while later I noticed that the output of the cypher was weird, the longer it ran the more zeroes I would get, eventually getting only zeroes.
The keen reader will already have spotted the problem: whenever i and j happen to be equal instead of doing nothing the code sets the entry to 0 (since x ^ x == 0 for any x).
And that's the story of how I never used this trick ever again.
In general it's always better to write clear, concise code and let the compiler optimize it. If it turns that the code is performance critical and the compiler doesn't do a good enough job then you can see if the smart solution is worth it.
And if you fail an interview because the interviewer expected you to know how to find a duplicate in an integer list by using xor then you probably dodged a bullet anyway. What a silly trivia question.
Not the values (the values being equal doesn't break the trick), but the pointers. That is, if you use the XOR trick to swap a value with itself, then it will be set to zero, instead.
At that point it's probably almost always better to just use some temporary space, rather than dealing with all the overhead of a branch (what if it's mispredicted, what about the resources in the branch predictor tied up by this that might cause something else to be mispredicted).
On the other hand there are many situations where you can guarantee that x and y are not the same space in memory (for example because they are local variables). There this trick might still be interesting (for the compiler or assembly programmer)
The xor swap truck is rarely better. It causes pipeline stalls, and so is likely to be significantly slower than the trivial swap. The temporary storage will be in a register, so it's (usually) not causing memory accesses.
Yeah exactly this, it only really makes sense in some very limited situations in embedded software, for example when you might be in an interior handler and have no free registers
On the topic of intermediate variables, when I'm forced to use c89 I'm really shameless about introducing extra code blocks in the middle of other blocks. For example,
{int i; for(i=0; i<N; i++){
/**/
}}
Still bothersome but better than having to declare everything at the top of the function, IMO.
I do something like this in "modern" Java to get for-each with index:
{ int i = -1; for (V v : list) { i++;
// stuff
} }
While declaring i = -1 to start is a little gross, I like that it has some of the same properties as a normal for loop. No effect on parent scope, and all loop-logic is concentrated on the first (textual) line.
As an example, in our C++ codebase at work we always place mutex locks inside their own scope blocks along with the critical sections of code they’re synchronizing. Helps readability and the scope determines when the mutex is released.
Indeed! I somewhat over-use this in Rust to initialize an immutable variable with mutating code.
let var: Vec<u32>; // this one is immutable, will be initialized later
{
let mut var_; // mutable
… // initialize var_ with some mutating code
var = var_; // now move var_ to var, initializing the latter
}
The XOR trick has also the disadvantage of being 3 dependend instructions that can not overlap. The one with a temp variable has only 2 of them dependend and can therefore save one cycle on an OO CPU.
> And that's the story of how I never used this trick ever again.
I agree with your point, and I would go on to say that this is an excellent example of the value of tests. Especially with something so relatively small and self-contained, which makes it easy to test.
I sometimes use your "bug" on purpose in tests, when checking that two values are either both defined or both undefined, but not one defined and one undefined:
$ python
>>> a, b = 1, 2
>>> bool(a) ^ bool(b)
False
>>> a, b = 1, 1
>>> bool(a) ^ bool(b)
False
>>> a, b = None, None
>>> bool(a) ^ bool(b)
False
>>> a, b = None, 1
>>> bool(a) ^ bool(b)
True
(Note: this doesn't work if a value can be 0, because bool(0) is False in Python).
This helps to avoid having to write something like `(a is not None and b is not None) or (a is None and b is None)`.
Lesson for myself: check my working. The test I actually used the XOR in, that I was referring to, uses the first example you wrote - I agree, this is much better. However, I also like your second example, which is arguably clearer. Thanks!
Hah, I wrote that code on the fly and didn't check the aforementioned test implementation, where I had `(a is None) ^ (b is None)` like the other commenter suggested.
I like this as an example of how compilers cause bugs. This code looks reasonable and concise, but it shouldn’t. If you were writing microcode for a non-superscalar processor, you would do two separate memory to register loads and then three xors and then two register to memory stores. But the compiler teaches us to use shorthand and it will fill in the details. In this case the resulting code is ridiculous with loads and stores on each xor because the compiler can’t guarantee that i!=j, and it would normally perform terribly, but we’ve architected CPUs around compilers to use caches that make up for these problems, and they are so prevalent that it’s worth it to dedicate most of the CPU die area to branch prediction based on conventions of the C compiler, and most of the compiler code to conventions of the CPU branch predictor. It’s getting quite ridiculous, and maybe it’s time to move to architectures and languages that make everything explicit.
Edit: also, there is an xchg instruction that you have to pull out of intrinsics to use in C (good luck in most other HLL). It seems like a language should be more about how to use vocabulary than restricting it.
The "std::tie(b, a) = std::make_tuple(a, b)" is an attempt to replicate the Python style in C++... which, I agree, is certainly not clear, and, unlike using the "swap" algorithm, it's also unclear whether it will result in efficient code.
> because the interviewer expected you to know how to find a duplicate in an integer list by using xor
Maybe they expect you to come up with a solution right there. This way they can see that you're curious and trying to solve a problem even if you don't know its solution beforehand. (And by looking at your attempts they your mind is even working in the right direction. They could give you small hints and observe how you process them.)
I never conducted interviews myself, but some years ago my supervisor asked me for advice on interview problems for his interns. He wanted something that will help spot a person inclined to algorithmic thinking, but the job was not 100% algorithmic, he needed programmers. If he asked me the same today, I would have advised him to look at these xor search problems.
> how to find a duplicate in an integer list by using xor
I've never heard of that trick and would never have thought of it on my own. It takes a moment's thought to see why it works, and I like it.
Bit twiddling is a bit like symbolic integration. There isn't a systematic approach, it's just an accumulation of formulae that people have stumbled upon over time. You can buy books of them. (These days, of course, you just use a program that has them all hardcoded into it.)
That suffers from the same problem if a and b are pointers to the same thing (which was the issue in my code, since I indexed the same cell of the array).
Note that the problem is not that a and b have the same value, or even that one of them is 0, it's that a and b alias to the same memory location, effectively being two handles to the same variable.
If you stick to multiplication and addition then the beauty of modular arithmetic ensures that over and underflow are only a problem if your final result under/overflows.
In particular you can solve the problem in this article by just subtracting the numbers from 1+2+...+n-1+n. The remainder will be your missing number (though be careful with the 1+2+...+n-1+n = n(n-1)/2 formula; division by 2 is very much not compatible with arithmetic modulo a power of 2, so divide first then multiply, or keep a running total if you want to be flexible).
Worse. The zero problem does not exist if the two variables are at different memory locations. The overflow problem of this solution always exists. Plus, if a and b are at the same memory location, it suffers from the same zero problem.
You're wrong. Remember that XOR works on individual bits. If what you're saying was true, then swapping bits that are both set to 1 would also fail, which means this algorithm wouldn't work at all.
Edit: Ignore this post, I misread the original post as saying swapping the same values would fail.
They're not saying swapping equal valued variables breaks it. It's when the pointer is the same, using the trick to swap a variable with itself will set the variable to 0.
A fun party trick not mentioned here is reducing storage in a doubly linked-ish list: Normally each node stores 2 pointers: struct Node {void * prev;void * next}
The trick is to use only 1 'pointer', storing prev XOR next: struct Node {void* xored;}
While traversing, you remember not only the current position, but also where you came from. So forward traversal goes: next= current.xored XOR previous. Backwards also works: Node
* previous=(Node * )current.xored XOR (Node * ) next.
The first and last node can use 0 as previous or next node, or you make a circular list. You do have to store a pointer to the first and last node, as usual.
I've never seen this used in the real world, which is probably a good thing. It also plays hell with garbage collectors like Boehm, as they can't derive the 2 used adresses.
I looked up TAOCP (The Art of Computer Programming by Knuth), and (unsurprisingly) this trick is mentioned there, and already by the time of the first edition this trick was folklore, with its origins lost to antiquity: the last exercise in section 2.2.4:
> 18. [25] Devise a way to represent circular lists inside a computer in such a way that the list can be traversed efficiently in both directions, yet only one link field is used per node. [Hint: If we are given two pointers, to two successive nodes x_{i-1} and x_i, it should be possible to locate both x_{i+1} and x_{i-2}.]
Answer (in 1st edition [1968], second printing [1969]):
> 18. Let the link field of node x_i contain LOC{x_{i+1}) ⊕ LOC{x_{i-1}), where "⊕" denotes either subtraction or "exclusive or." Two adjacent list heads are included in the circular list, to help get things started properly. (The origin of this ingenious technique is unknown.)
The "either" is modified to "e.g." in the 2nd edition [1973], and further slightly modified in 3rd edition ([1997], first digital release [December 2013]):
> 18. Let the link field of node x_i contain LOC(x_{i+1}) ⊕ LOC(x_{i−1}), where “⊕” denotes “exclusive or.” Other invertible operations, such as addition or subtraction modulo the pointer field size, could also be used. It is convenient to include two adjacent list heads in the circular list, to help get things started properly. (The origin of this ingenious technique is unknown.)
With modern languages and compilers, even if doing these operations on your language's pointer type is implementation-defined/undefined behaviour as mentioned in some of the other comments, you can still use this trick with your own "pointers" (indexes in an array, as Knuth does in many of his programs: https://en.wikipedia.org/w/index.php?title=Pointer_(computer...), I guess.
Anyway, this gives me another point of appreciation about why the TAOCP series of books were so highly regarded: they were (are) encyclopedic and gathered/organized much of what was known at the time, in a highly compressed way (packed into exercises etc).
The bigger problem with this approach is that you can't remove/erase something from the list just by knowing it's address. This is a key mechanism for most use cases. However, if you're fine with limiting yourself to erasing only during iteration, it's pretty nifty.
I've also done some benchmarks in the past and found it interior iteration performance due to what I'm assuming to be inability to prefetch the next address. However, linked list iteration is already relatively slow so I suppose it's not a big downside.
It's not obvious how prefetching the next address would make things run that much faster - you don't know a given address until you execute the load. That said, there is definitely an extra cycle in your dependency chain to do the XOR, which you might well notice if your linked list is in cache (that extra cycle will show up).
We had a discussion on Twitter about some sort of superfast magic prefetcher that may well have been on the M1 which arguably could shave some cycles off list traversal, and there was a theory that an XOR-list would have been a good negative benchmark to prove/disprove this, but nothing came of it.
The limitation is worse than you say; you can't even navigate from an item just by knowing its address (not just remove/erase something). So any given iterator into this list has to have 2 pointers (say, the item and its predecessor).
It's a weird structure. There's probably almost certainly some peculiar use case for it somewhere, but I've never encountered such a case.
This XOR-list trick was mentioned by Joel Spolsky in "The Duct Tape Programmer" (2009), discussed recently here.
> They have to be good enough programmers to ship code, and we’ll forgive them if they never write a unit test, or if they xor the “next” and “prev” pointers of their linked list into a single DWORD to save 32 bits, because they’re pretty enough, and smart enough, to pull it off.
Single pointer lists using the XOR trick were used, I believe, to implement the XDS Sigma 7 operating system block free list back in the day when memory was not free and core dumps were the primary debug tool. I remember writing a column on the algorithm for Dr. Dobbs Journal back in the 1980s. There are lots of bit twiddling techniques that use XOR. Henry Warren's Hackers Delight is a good reference there. And, of course, Don Knuth's AOCP has lots of information. Volume 4A, available as a fascicle, has a number of XOR algorithms.
To be precise, it's implementation-defined whether it's undefined behavior, prior to C11. You are right that in C11, if uintptr_t is used to store the xored value, behavior is defined.
As mentioned in this article, x ^ x == 0. Fun fact, this is frequently used by compilers as a "cheap" way to zero out a register.
In addition, there are comparatively few cases in programming where we XOR. Sure, it happens in things like games quite a lot, but the main use is actually _cryptography_.
Between these two facts (more like hints really), I managed to reverse engineer the bulk of a piece of malware I was given to analyse in a an internship. I was handed the malware, a copy of IDA Pro, and given a few days to see what I could find. All I could remember when presented with a wall of hex encoded machine code were the hints above. I looked for XORs of different values, assumed it was crypto, and extrapolated from there. Found a routine happening three times in quick succession and guessed it was triple-DES. Then I guessed that writing your own 3DES from scratch was unlikely, so googled for crypto libraries and happened to find one that nearly matched (I think an earlier/unmodified version), and worked my way up tagging the operations until I got to the purpose, exfiltrating various registry keys and browser history to [somewhere].
It was a fun exercise, and therefore these facts will stay with me for far longer than they are accurate I'm sure!
Xor'ing registers isn't a compiler trick or arcane piece of lore, it's the canonical way to zero a register on most architectures. It's the only universally recommended way for both Intel and AMD x86 and x64 processors.
Not necessarily true for most architectures. Many RISC architectures have a "zero" register, so a canonical "move short immediate" instruction could be "OR Rn, R0, #n" ("OR R0 which is always zero with n and store into Rn") or the same with ADD. Then clearing Rn will usually be "OR Rn, R0, R0", "ADD Rn, R0, #0" or something like that.
I should have been clearer, when I say most architectures I mean most x86/x64 architectures not most ISAs. Obviously ISAs with a dedicated zero register don't need the zeroing idioms of x86.
In that case it's all of them. Some might like having both a MOV and a XOR in some special cases (one to avoid partial register stalls and one to avoid partial flags stalls, if I remember correctly) but even in those cases it's usually easy enough to avoid partial register stalls in some other way and just use XOR.
In fact, modern x86 CPUs know that the result of "x XOR x" is independent of x, and use this fact to optimize operations that would otherwise have a dependency.
I'm not sure what you mean by "programmers terminology".
0x31 0xC0 is disassembled to "xor eax, eax".
This is not nitpicking, as there's an important difference. The "xor eax, eax" instruction affects CPU flags [1], while "mov eax, 0" doesn't [2].
> It isn't actually implemented as such
The implementation is independent of the meaning of the instruction set. There are many implementations of x86 instructions with differing levels and kinds of optimization, so we can't make general statements about that.
You make it sound as if there were four Intel/AMD x86/x64 architectures. And well, there aren’t. The vendor split is not a thing, we’re all running the same software on Intel and AMD x86/x64 processors. And you could argue that the x86/x64 split doesn’t really matter for this, since x64 is a superset of x86 and inherits this tradition from the 16-bit and 32-bit eras.
I feel like xor comes up all the time in programming! Perhaps generations that have almost entirely focuses on web front and backends never have use for it, but libraries underneath it all certainly are.
xor reg, reg is indeed the standard way to zero out a register in x86 assembly (it's not just a compiler trick) as it is both shorter and faster than loading the register with zero via a mov.
Apart from that, I'd say that a common use of XOR operations in general are interactions with hardware peripherals where manipulating bit fields are needed.
It's not overhead, it's about dependency breaking. 32-bit xors on a single register are universally recognized as a zeroing idiom, which means the CPU doesn't have to wait for the results of previous operations in order to set the value of the applicable register to zero.
In modern CPUs zero'ing idioms aren't even executed, they only get as far as the register allocater. The register allocater will allocate a zero'd physical register for the architectural register that had the idiom applied to it and the job is done.
It's larger, because it needs to fit a 32bit value of 0 in the instruction, and thus e.g. on x86 needs 5 bytes, whereas xor reg,reg needs 2. As such it was a common code size optimization, which in turn has lead to CPU manufacturers optimizing their CPUs to recognize it and treat it even more efficiently.
IIRC immediate operands have to be the same size as the destination, so to zero a 32-bit register you need a 32-bit constant, and it simply makes the whole instruction larger than a simple xor.
They don’t need to be 0 or 1. We already know that a ^ a = 0, a ^ 0 = a, and a ^ (b ^ c) = (a ^ b) ^ c, so we must have a ^ b = 0 only when a = b. Therefore in the C convention where 0 means false, a ^ b = not (a = b) = (a!=b) (this equality only holds for expressions that are going straight into a Boolean operation (or test in eg an if statement), as a!=b should always evaluate to 0 or 1.
The compiler may use this by xoring a and b and then jumping if the zero flag was set.
> (this equality only holds for expressions that are going straight into a Boolean operation
Right, though that's more commonly turned into just a cmp instruction (a subtraction).
However, if the result is assigned to a variable, on x86 "a != b" would be two or three instructions (possibly clearing a register because setne takes an 8-bit register operand only, and then a cmp/setne pair). Instead the xor would be one instruction, or two if a mov is needed.
"In addition, there are comparatively few cases in programming where we XOR. Sure, it happens in things like games quite a lot, but the main use is actually _cryptography_"
I'd be curious if that's actually true. I know XOR is used for non-cryptographic checksums, parity bits, maintaining key traversal order for associative arrays, overflow detection, etc. Lots of general purpose "stuff" that isn't cryptography.
XOR is used a ton in the theoretical underpinnings of cryptography. It's used in the one time pad which is essentially the "smallest" cryptographic scheme that is perfectly secure (perfectly secure has a mathematical definition in this context, it's not saying there can never be any attacks).
In general the reason why is that if you have two random variables x and y, where x has any distribution (so for example x could even be "attack normandy on june 6" with certainty) and y is uniformly distributed across all n-bit strings (so it could be any string of n zeros and ones with equal probability), then you can show that x ^ y appears as if it is also uniformly distributed across all n-bit strings as well.
Because of this property it's used frequently in many higher order methods as well.
A lot of that sort of thing is abstracted away by common standard libraries. I don't tend to run into a whole lot of XOR on a day-to-day basis, apart from when digging into low-level libraries.
For example, XOR is the most convenient combining function for Zobrist hashes in chess programs. OR/AND would be bad choices: given random input, their output is biased to the values 1 and 0 (respectively).
In human terms, that means XOR of 1, 2, ..., n is:
(if (n is divisible by 2) then n else 0) + (if ((if (n is divisible by 2) then n else n + 1) is divisible by 4) then 1 else 0)
The simplest formula from the OEIS page seems to be
a(4n)=4n,
a(4n+1)=1,
a(4n+2)=4n+3,
a(4n+3)=0.
Once you have the formula in front of you, it’s easy to prove it by induction. A branchless implementation of this function with no multiplies or divides:
It was not super obvious to me, but the actual sequence is https://oeis.org/A003815 which is the absolute value of A077140. The entry for the latter gives another formula for A003815 however, which is distinct from a formula (1+3x-x^2+x^3)*x/(1-x^4)/(1-x^2) given in A003815.
Although: that's not true for arbitrarily sized integers either.
Multiplication in O(1) implies P = NP (which further implies NP = PSPACE): https://cs.stackexchange.com/a/1661/129151
It is the class of functions that have the constant value 0, with a canonical exemplar f(n) = 0 (and despite having tried, I cannot find any other function, up to choice of variable name).
In terms of algorithms, I suspect that no actual algorithm fits into it and as such it is more a curiosity than actually useful.
However, O(0) is not the same as O(1), as we cannot find a constant c such that 0c dominates all possible functions that 1c can dominate.
One of the coolest XOR tricks I've seen is fast encoding of negative integers to positive integers (unsigned) employed by ProtoBufs. It is called ZigZag encoding where negative and positive integers are interleaved such that lower negative values are assigned to lower positive values:
Xor trick may reduce the time/space complexity of a solution but I'd say it definitely increases the cognitive load (maintenance) complexity. Outside of few niche industries/use cases, the increased developer cost will probably outweigh whatever extra hardware you'd need to compensate.
Agreed, the XOR trick is just a clever trick that might be useful in some esoteric niche cases, but otherwise don't bother. GCC will even optimize away the XOR operations when this is used for simple things like ints on amd64. I did a simple compile test, and with -O1 and higher I got identical machine code for the XOR algorithm and the naive swapping version. Without optimization I did get the XOR instructions, but the number of machine instructions was longer than for the naive case, and the number of CPU registers used was the same.
I hope this article takes off so that my company will have to change its initial code screen. We make no use of xor in our rather large codebase (I’ve checked) yet pin a lot on whether an interviewee is aware of this trivia.
I'm not sure what you mean by "every year", but when I screen candidates, yes, I'll ask multiple candidates the same question? It allows me to compare candidates directly without introducing the additional variable of wondering whether one had a harder question, it allows me to gain & retain experience at asking the question in how it is presented, and if the candidate does well, how we proceed to make it more difficult to suss out the candidate's skill.
I do agree with the parent above though that this use of xor is trivia, and not a great interview question.
It just surprises me that they aren't rotated out more frequently (annually?). I can think of a number of arguments for doing so and really only one small one against.
The fact that not rotating questions makes it trivial for someone who’s been through the process to tip off future applicants. Sites like Glassdoor and leetcode already do this, but it’s tempered by the fact that most companies rotate these type of screener questions regularly.
It sounds like some of these questions are bad screeners anyway, but it makes them even worse if half the people going through the process are feigning surprise at the tricky question then quickly developing a “brilliant” solution.
You can actually extend the XOR trick for missing elements to any fixed number!
The standard (non-XOR) low-memory solution calculates the sum of x, x^2, x^3, ..., x^n, which gives enough information to find the missing elements as the roots of an n degree polynomial.
We can just do the same thing in the finite field F_{2^k}, where k is the bitwidth of the integers. Addition in this field corresponds to a bitwise XOR, so the first term gives exactly the 1-missing case!
I don't remember how to actually solve the resulting polynomial over the finite field though.
Ah, XORing is indeed addition in F_{2^k}. It's not addition in Z_{2^k}, though. I was thinking about summation modulo prime number, in this case Z_p = F_p.
Fun XOR trick: using it to move a cursor across the screen without having to keep a buffer of the contents under the cursor (and putting them back).
It didn't always look great, but if you were moving a full-screen crosshair around, it was sufficient. Especially on hardware that was slow to move buffers to and from ram.
Unfortunately, using this pure-math technique was also patented until 2007 [0], much to the surprise of my former employer in 1986. Cadtrak had collected from companies like IBM and NEC and made a nice business as a troll.
Really? Apple ][ vector shapes had a XOR mode built in for non-destructively moving shapes across the screen, often used for cursors, and that was released in 1977.
> There are a whole bunch of popular interview questions
As a very personal strong opinion, this makes me groan.
I'm not concerned If someone happens to know some esoteric trick that they could Google search (Unless of course you're applying for a position at a company that manufactures very low level devices like microcontrollers or embedded systems and questions like this are _actually relevant_).
I'd rather know whether or not they are a pleasant person, are a team player, whether they have leadership aspirations, and take responsibility.
> pleasant person, are a team player, whether they have leadership aspirations, and take responsibility.
I know the above is a popular opinion, but I've worked as a SWE at a company A that had a "technical interview" process and Company B that didn't have a formalized one.
I would much, much prefer to work at company A (pay differences aside) because of the type of person who passes these interviews. It can be quite difficult to determine someone's capability at interview-time. But company B had lots of competency "false positives" (in my view) whereas company A had very few. That's the value of a technical interview.
That said, of course the XOR solution would never be the only one accepted, but it would probably get you brownie points here.
> company B had lots of competency "false positives"
The thing to note is that, in exchange for this, Company A (probably) had a lot false negatives. So it comes down to whether you'd rather missing out on someone that would have been beneficial for the company (false negative) or have to deal with accidentally hiring someone that is not a good choice (false positive). The best choice to make depends a lot on the situation.
Maybe you feel like you are being inclusive and warmhearted for praising soft skill vs 'teh codez skillz', but please also consider that tech and programming jobs is like the last refuge for people with high technical aptitude and perhaps less social soft skills regarding the meta political and expectation games, eg people somewhere on the autism spectrum.
Perhaps such interviews are overused but if the interview is purely soft, and about "sell yourself to me", you will also be biased towards some people.
I mean of course it's important to be able to work together in a pleasant way, but when someone's main strengths are in the technical aspects, they may like to be able to showcase that too. And yes of course in the age of high level frameworks and glued CRUD pruducts, some programming jobs are more social than technical. But not necessarily all.
And I'm seeing lots of this sentiment nowadays on social media, that all "allegedly" merit based nerdy "gatekeeping" is merely about white male privilege and hence not inclusive.
Nobody complains about puzzles in tech interviews. People care about uncreative "did you read this book about interview questions" questions. If you want to test tech knowledge in tech interviews, ask a question that isn't in any book. That takes a lot more skill as an interviewer to pull off, but if you're a hiring manager, surely you can find someone on your team qualified to design a puzzle.
Google's policy is to extensively discuss interview questions internally, and blacklist any that are leaked. They are still complained about near-constantly on any tangentially related HN thread.
The attitude is often quite strange. Like on Twitter I saw a few days ago that many were riled up about the fact that a prof would ask how to solve Ax=b (linear algebra) for a deep learning / computer vision PhD position. People were calling this unnecessary gatekeeping... I'm like that's just a warm-up question to get comfortable... But apparently the loud online hive mind opinion is that all that should count is soft skills and that everyone is equally able. People are even calling out professors on Twitter (who then engage, for some reason) for saying they are looking for "outstanding" PhD candidates. Because this is apparently too exclusionary language, everyone is equally outstanding or something...
To be fair, you would not actually need to know how numpy.linalg.solve works to use pytorch. Solving linear equations is an extremely deep subject on its own, featuring a lot of difficult and sophisticated issues related to numeric stability. Entire books have been written about how to solve Ax=b with awareness of the nature of floating point arithmetic. Machine learning researchers are generally unconcerned with those topics.
As everything in the world of knowledge, this topic too has a fractal nature. There's a difference between what you just said vs "well, optimize it with gradient descent, yoloswag" or "just invert the matrix A". If you say something something pivot selection, Gauss elimination, iterative algorithms, QR, LU factorization, backslash operator, pseudoinverse, under and overdetermined systems and can roughly handwave your way around roughly explaining what these things are about, it's probably already very good for this job. This prof probably wasn't interested in the tiniest of numerical stability details.
Except solving linear functions has a clear role in any field that makes use of linear algebra. Interviews that require memorizing volumes of pointless trivia unrelated to the work at hand are completely different.
Yes, in practice this interview style now achieves exactly the opposite goal that it was created for. That is, originally people wanted to base hiring on general problem solving skill, mapping out a problem domain with relevant questions, proposing solutions, identifying tradeoffs, reacting to a change in problem statement, etc. based on a pure computer science foundation, independent of ever changing software frameworks, libraries, APIs etc. Precisely because memorizing the specific steps of creating a CRUD mobile app in today's workflow is not useful later on. The problem is, Goodhart's law kicked in and performance in such puzzles became the target to optimize for, so it stopped being a good measure, because now people have to explicitly study for it from books and online courses and practice sites and so now it measures more of the effort you're willing to put in to jump hoops instead of actual problem solving aptitude.
An alternative could be to ask about a recent real-world project of the applicant, but that's also easier to rehearse.
> I'm not concerned If someone happens to know some esoteric trick that they could Google search (Unless of course you're applying for a position at a company that manufactures very low level devices like microcontrollers or embedded systems and questions like this are _actually relevant_).
Erasure correction is a very useful trick for data-engineers. I don't think this is a microcontroller trick, as much as a data-resliliency trick.
The XOR-trick is how you implement RAID5 most efficiently. A proper discussion / interview would probably describe the XOR trick, and then see if the engineer is smart enough to understand the difference between erasure and errors.
--------------
With a blog post describing the XOR trick ahead of us: now I ask you (the audience): what is the difference between an erasure and an error? Why can this XOR-trick protect against an erasure, but NOT an error? And how does this relate to RAID5's known failure cases?
But at that point, I'm interviewing for someone who has passed a data communications class.
> However, I don't see how you would know the locations in this problem?
Well, that's just from the blogpost itself:
> Application 2: Finding the Missing Number
> You are given an array A of n - 1 integers which are in the range between 1 and n. All numbers appear exactly once, except one number, which is missing. Find this missing number.
We can "find the missing number", but we don't know where to "put" the missing number. If you want to put the "missing number" back into the sequence, you still need to know the location to put it into from some other mechanism. (Ex: hard drive #5 failed, so you know to put the number into slot#5).
----------------
Application 4 starts to get into "partitioning", which is getting dangerously close to sparse parity-check matrix and LDPC graphs.
Ah, do you mean that solving the problem described in the blog-post helps actually using erasure coding, since it requires knowing which parts are missing?
> But at that point, I'm interviewing for someone who has passed a data communications class.
This is basic data-communications stuff. But there's a reason why data-communications isn't exactly a commonly taught subject: its niche and not really generally applicable IMO.
My main point is that the XOR-trick is a decent data-communications question. But I don't know how generally applicable it is to other programming fields.
> I'm not concerned If someone happens to know some esoteric trick that they could Google search (Unless of course you're applying for a position at a company that manufactures very low level devices like microcontrollers or embedded systems and questions like this are _actually relevant_).
The "XOR trick" actually nearly sank me on an interview once, I'm assuming because the interviewer shared your opinion. One of the questions they asked me to solve was the "n - 1 numbers in a list" question the article talks about - I promptly came up with the XOR solution because I have more background in low-level work than the high-level finance role I was interviewing for. Turns out, they had never seen it before, didn't really understand how/why it worked, and they took a lot of convincing to accept it as correct.
I think I only still got the job was by then proceeding to also solve the problem the "normal" way.
I think it kind of depends on the type of programmer one wants to hire. There are different roles, solving different types of problems.
There are places for people with technical brilliance, there are places for people with social brilliance, with both, and with neither. That's healthy. You want a diverse economy with different types of positions for different types of folks, and vice-versa.
If I ask a half-dozen questions like the xor trick, I'll have a filter for one type of technical background. Whether you know each of them is pretty random, but whether you know none of them or most of them is not.
Being able to interact well with others is part of being a valuable employee. You can be the best engineer in the company, but if nobody wants to work with you, it's going to negatively impact the value you bring to the company.
Because, as you move up the management chain, understanding how people work and how groups of people work becomes more important than technical brilliance. The job of a manager is to create a healthy working environment where people work effectively, and are well-aligned to a common goal.
That's hard.
You don't just practice that by living.
That's made easier by having people lower down who are helping and not hurting.
Nobody wants to see the XOR solutions. These questions are really basic and only filter out the non-programmers. Any decent programmer should be able to solve all of these without a problem.
I wouldn't say "nobody" wants to see the XOR-trick solution.
Its just that those who DO care about it is asking about the general solution: Reed-Solomon codes, or maybe a more modern (harder to understand) variant: like LDPC or Tornado codes.
Anyone who needs to recover *ONE* symbol from a data-stream with noise actually needs to recover two, three... four... symbols in the general case.
One symbol of erasure recovery is the weakest-of-the-weakest of error correction codes. Its even weaker than the single-error-correction / double-error detection Hamming Code (discovered back in 1950s).
XOR-trick is your "basic parity bit", and is the stuff taught to undergrads to wet your appetite for error correction codes (well... erasure correction in this case. Since XOR isn't strong enough to actually correct an error. Only an erasure).
I don't see how the problem corresponds to erasure coding.
Typically in erasure coding you know the locations of the erasures.
Here, you don't know the location.
Maybe you can elaborate on how it relates to erasure coding?
As long as a^1, a^2, a^3... are distinct, then this matrix is invertible (aka: all rows / columns are linearly independent). In a GF(2^8) field, there are 2^8-1 distinct values (the values 0x01 through 0xFF), making a 255x255 matrix. The polynomial "x" (aka: 0x02) is often chosen to be the value of "a", but it can be any primitive element that loops around all 255 non-zero numbers and still work.
This Vandemonde Matrix has a very simple construction, but it is non-systematic (the data is "mangled" in encoded form, so we need to invert the matrix to decode). However, this non-systematic form is easier to see some patterns. Now lets take the 1st column:
1
1
1
1
1
...
Hmmm... look familiar? What happens when we multiply the data vector with this column?? It becomes a bit more obvious:
1
1
1
[d0 d1 d2 d3...] * 1
1
1
1
1
1
Remember, in Reed-Solomon, you perform operations over GF(2^blah). So all multiplications are GF-multiplications. But these are all multiplications by 1, so we can just ignore the complications of GF-multiplication entirely. (Even in GF(): a multiplication by 1 is just the identity).
To finish the matrix-multiply, we add everything together. But we do GF-addition (not regular addition). A GF-addition is also known as XOR. So the ultimate answer is:
d0 XOR d1 XOR d2 ...
Which so happens to be the first parity bit of the non-systematic Reed Solomon code. As such, we've proven the relationship between the "XOR trick" and Reed Solomon (Vandemonde construction).
------------
The hamming-distance between codes is 1. We can correct floor(1/2) errors (aka 0 errors) and 1 erasure. As such, this "all 1s matrix" is a 1-erasure punctured Reed Solomon code.
I'm familiar with some subset of coding and number theory, so you can assume at least some more knowledge (Galois Fields, or basics of RS codes for example).
Small nitpick: The Vandermonde matrix actually isn't square. It's a (k × n) matrix, (where typically k ≠ n). Therefore, it can't be invertible.
I see that many codes contain a parity bit (for example the extended Golay code), however I don't see how the operation of recovering "the missing number" could be implemented in terms of a code and its encoding/decoding algorithms.
It describes a way to recover the missing number by constructing a Vandermonde matrix using the given numbers. This would correspond to constructing a generator matrix of a specific RS code [1].
However, after this I'm not so sure about the relation between encoding/decoding and recovering the missing number.
In the end they also factor a polynomial (that could be something analogous to the error locator polynomial?).
[1]: although I'm not sure if it's strictly an RS code
Note: Backblaze here uses "vertical data" (G * data) instead of what I did earlier "horizontal data" in the form of (data*G). But otherwise, still a good blogpost.
------------
So if you have 5 data + 1 parity, you now have a 5x6 generator matrix, giving you one extra column for erasures.
If one column is erased, you replace the erased column with the parity column, creating a 5x5 matrix.
As long as all columns were linearly independent, the resulting 5x5 matrix remains invertable.
The specific matrix multiplications / inversions / operations are well documented in that blogpost.
-----------
EDIT: Erasure decoding is much easier than error decoding. Error decoding requires figuring out the "locator", and then applying the calculated errors at those locations. Since we already know the locations in an "erasure" situation, we can just manipulate the matrix in an obvious manner.
--------
EDIT2: Ah right, the "systematic form" of the Vandemonde-Reed Solomon construction is to perform Gaussian Elimination on the non-systematic matrix (with the goal of forming an identity-sub-matrix). After gaussian elimination, the "column of ones" (or the simple XOR) disappears. (Erm... row of ones in the Backblaze pictures)
So maybe the Golay code you're thinking of is a better example as a matrix with an explicit parity bit.
I would be interested in a way based on coding theory that solves the problem in the blog-post.
Something of a form similar to this one would be a solution to me:
def find_missing_number(nums: List[int]):
# 1. Define some code C (possibly using nums)
# 2. Encode a message using C (or interpret nums as a word or codeword)
# 3. Do something with the word
# 4. Find the locations of the errors in the word
# 5. The locations of the errors tell us the missing number(s)
The answer on stackoverflow seems to use methods very related to RS decoding, however I can't quite squint enough at it to see, whether it could actually be solved using the exact same methods in RS decoding.
Something in the middle might be useful though. Discussing XOR and it's properties (the first part of the article) with the assumption the interviewee doesn't know them... and then working through what it means you can do with it (the second part) could be a useful exercise. "Given these properties, what can you do with it". To some extent, it still means the person that knows the tricks will do better.. but much less so.
There is a very clever and beautiful algorithm that only uses the xor operation. It's the Luby Transform code, the simplest implementation of a Fountain Code. A Fountain Code lets you transmit a file over an unreliable connection (packets can be unordered, and even lost), with just a unidirectional communication. And this can be done just by xoring a random number of blocks from the file over and over!
My favorite trick is the XOR one time pad. XOR anything (text, images, etc) with a random pad or "key" the same length as the data your are encrypting... and you've got an completely unbreakable cipher.
Just be careful as with any one-time-pad cipher. The key needs to be the same length as the data, generated randomly, and you can only use it once... no key reuse ever.
A = { 1, 2, ... , k, ..., n-1, n}, for 1<=k<=n, and we're given integer n.
sum({1..n}) = n(n-1) / 2
sum(A) = n(n-1) / 2 - k
k = n(n-1) / 2 - sum(A)
Is the interview question looking for a "clever" solution? I'm confused as to why someone would ask this question in an interview? It seems like the more challenging question would be "Find a method of summing a range 1..n in less than O(n) time/space complexity." [edit] I have a dumb. This calculation can happen in O(1). Because of n(n-1)/2, we know the sum of the range, no need to examine each value in the range. [/edit]
Or, even more fun, limit the functions/instructions the interviewee can use (ex, some 4 or 5 instructions of x86/WASM/etc. machine instructions, max 1 or 2 registers, etc.) to complete the task.
What it doesn't click with is GC. Any pointer xor trick will fail when trying to add a GC to the app, because the pointers don't point at the right thing anymore.
Good article, but this interview question is not good.
> How to swap two numbers without using a temporary variable?
I know interviewers expect XOR, but PCs have XCHG instruction.
It’s the same error when they asking to compute number of set bits, expecting “lookup table”. Same error when they ask to find the least/most significant set bit index, expecting some bit tricks. Processors have dedicated instructions to do these things, typically faster than smart-ass manual versions.
Moreover, for simple things like XCHG, BT, BTC, BSWAP compilers are aware and normally produce them from normally-looking i.e. readable code.
Hmm, I would have used + and -, I suppose. The sum of 1..n is (n*(n+1))/2. Subtract from that all numbers in the array and what is left is the missing number.
No, not really, because you just need the lower half bits of the multiplication result, i.e., the size you need for your numbers. You do need to care about overflow: the /2 operation must not remove an upper bit from those lower bits. But you can easily do that before *: either n or n+1 is even. Divide the even number by two, then multiply by the odd one and keep only the lower bits. These lower bits are all you need, because the missing number is representable in it: subtracting may use wrap-around, but still, the remaining bits will be the missing number.
So this is how you’d solve the Fallout 3+ hacking challenges? :)
In practice I cannot think of a time when I was confronted with this particular problem. Usually if I need to find a duplicate I have no guarantees that there isn’t more than one or if there is a duplicate at all. I don’t think I’ve ever had to practically solve the “every number but one” problem. Curious where such problems arise in the wild, except interview puzzles.
I have never gotten the point of this trick. Don't basically all processors have some equivalent of XCHG (swap contents of two registers)? Even the 8086 had it back in 1978. (The z80 doesn't have it, but it is a couple of years older than 8086.)
I tried searching the LLVM source for any mention of the trick, but couldn't find anything. So I can't see it having any relevance to modern CPUs.
Slightly disappointed at the "two missing values" solution:
First: one needs to realize that you can solve the "missing number" problem just as well with sums. So, if you're trying to find the "one missing number" between 1 and n, you simply subtract all values from n*(n+1)/2 (the sum of all said numbers) and you end up with the missing one. (using wrap-around semantics, you don't even need to have more bits of memory than you need for the xor solution!)
Second: A common way to solve a problem with two variables is to build a system of two equations. One can compute, in a single pass, what is "a+b" and "a^b" ; solve the system, and you get both variables with no additional lookups. Now, it's true that if you get a carry from the addition, this problem might not be solvable...but, if you can afford one extra bit for the potential carry, you're all set.
Sums increase in size, however. The nice part of the xor trick is your xor result will be the size of the base of the numbers (64 bits or whatever). If you are reading several tb of 64 bit integers from disk that could get larger than your memory (though unlikely, probably why you see this in kernels where memory might be more of a concern especially with embedded)
Ah, you're right, I didn't think it through. It does feel like there must be a way to play with the bits so that you can retrieve it in a single pass, though - that'd be a much more interesting problem :).
(of course, you can do it with sum + product, but that's going to be fairly expensive for large numbers)
I’m a programmer by trade (and I like to think I’m pretty competent), but self-trained. Algorithms have always been a weakness of mine as a result of a lack of formal training.
While I use XOR for some simple Boolean comparisons out of convenience, the kind of XOR use I see —- especially in crypto libraries has always been very mysterious to me. This article cleared up a lot of that for me.
That being said, I often prefer readability over fancy so I don’t imagine using these tricks regularly but it’s nice to better understand how they work. This article did a great job demistifying this practice.
I've used XOR for undo/redo when I had limited memory in a painting app:
- You have the canvas in state S before you draw on it and the canvas in state T after you draw on it.
- Store (S XOR T). XOR this against T to undo back to S and XOR again to redo back to T.
So if you want to have 10 levels of undo, you only need to store the final state and the 10 XOR diffs that got you there. The diffs will compress well too because most of the pixels on them will be blank (where nothing changed).
All fairly easy to implement too e.g. compared to storing and replaying high-level commands to redo.
I've been asked this question before. I don't remember if I already knew the answer or not. But....
When does this ever come up in the real world.
> You are given an array of n - 1 integers which are in the range between 1 and n. All numbers appear exactly once, except one number, which is missing. Find this missing number.
This has happened to me in real life exactly NEVER!
I think maybe I was asked you have a list of pairs of integers except one number is missing its pair. Again, no idea where I would apply this in a real world situation.
> This has happened to me in real life exactly NEVER!
Do you do something applied like programming? I think problems (and solutions) similar to this one should be easy to find in TCS.
The problem you quote seems valuable to me for its insight, it shows that you can reduce certain search problems to algebraic calculations which are easy to do. I think this is useful concept to understand, and a good mental exercise to try coming up with it yourself (even if you don't apply it directly).
Could it be that even if you're a programmer who will never have to solve exactly this problem, you could still use the intuition you gain from this problem to solve others (or understand existing solutions you need to implement)? Could it be that you indirectly used the knowledge you have of this solution without being aware of it?
I had a case today where I was comparing two sets for equality. If the range of values is large, you could xor everything together as a O(1) space check for likely equality. Result is nonzero -> sets definitely aren’t equal; result is zero -> sets are probably equal, but you’ll need to check again some other way to make sure.
Of course this is absurd if you’re dealing with anything that already fits in ram, but it’s still neat to think about.
I've known of XOR tricks since the 80s, when you would "undraw" a graphic on the screen by redrawing it with XOR. But only recently I learned that the implementation of multiport memory for CPU caches and the likes often uses a design based on multiple storage copies and XOR to get the last valid written result. Amazed that the CPU's cache is doing that kind of trick all the time just during regular code execution.
The article touches on this, since its an important realization. In C, however, if the integers are not unsigned, the add/sub version exhibits UB on overflow, because C unnecessarily ties signed/unsignedness with overflow behavior (UB, two's complement, etc.).
Not that this is important, but could hint why this trick is more often shown with XOR than with add/sub.
This is conceptually almost the same as summing over all entries and comparing to the sum of all numbers in [1, n], except that the latter can be done more efficiently because that sum is simply n*(n+1)/2.
There are in fact legit use cases for XOR to speed things up or make algorithms simpler, but this is not the case here IMHO.
> Arithmetic operators instead of XOR
In that case, It uses Python that supports arbitrary long numbers out of the box so overflow of integers wouldn't be an issue(in Python3 default is arbitrary long integers).
That's one thing missing from BASIC in other programming languages, the SWAP statement: SWAP x y
So few other languages have it, some languages even make it impossible to write a swap function by not supporting pass by reference or pointers. Python has something interesting except it requires typing the name of each variable twice
You are confused about the problem here. It is not that both values are the same, it is you are applying the xor swap using pointers to values, and both pointers point to the same value in memory.
{kind=link}
{kind=link}
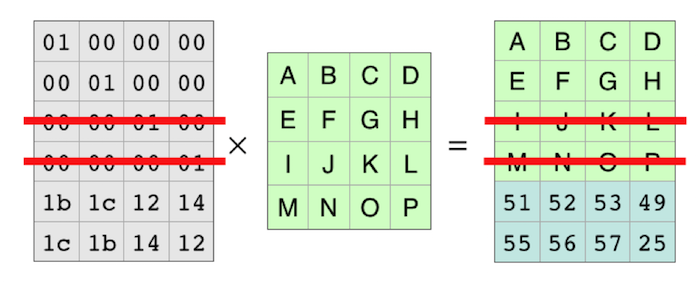
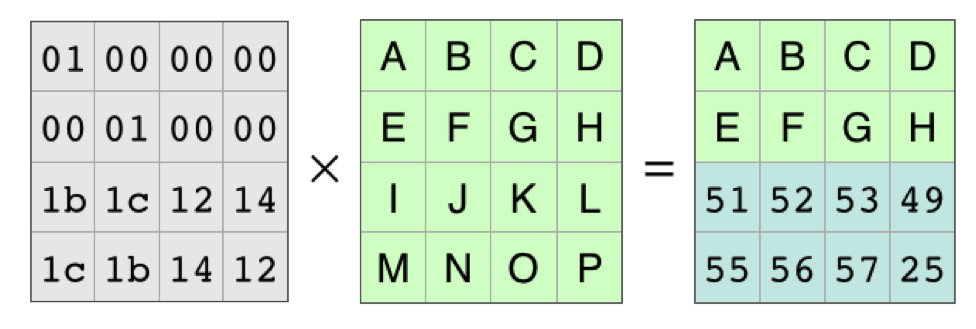
The algorithm looks like (from wikipedia):
Being a smartass 1337 coder (and declaring intermediate variables always being a bit of a bother in C89) in my implementation I decided to implement the swap using the xor trick: I then ran a few basic test vectors, everything seems to work fine.A little while later I noticed that the output of the cypher was weird, the longer it ran the more zeroes I would get, eventually getting only zeroes.
The keen reader will already have spotted the problem: whenever i and j happen to be equal instead of doing nothing the code sets the entry to 0 (since x ^ x == 0 for any x).
And that's the story of how I never used this trick ever again.
In general it's always better to write clear, concise code and let the compiler optimize it. If it turns that the code is performance critical and the compiler doesn't do a good enough job then you can see if the smart solution is worth it.
And if you fail an interview because the interviewer expected you to know how to find a duplicate in an integer list by using xor then you probably dodged a bullet anyway. What a silly trivia question.