There are plenty of applications where single-threaded clock speed matters, and Intel still wins by a wide margin there. Cache size is also a factor, and high end Xeon's have more cache than any competing CPU I've seen.
I'm not sure this is the whole story, Intel has twice the L2 cache as AMD but I'm not sure that's enough to make a huge difference.
Epyc 7H12[1]:
- L1: two 32KiB L1 cache per core
- L2: 512KiB L2 cache per core
- L3: 16MiB L3 cache per core, but shared across all cores.
The L1/L2 cache aren't yet publicly available for any Cooper Lake processors, however the previous Cascade Lake architecture provided:
All Xeon Cascade Lakes[2]:
- L1: two 32 KiB L1 cache per core
- L2: 1 MiB L2 cache per core
- L3: 1.375 MiB L3 cache per core (shared across all cores)
Normally I'd expect the upcoming Cooper Lake to surpass AMD in L1, and lead further in L2 cache. However it looks like they're keeping the 1.375MiB L3 cache per core in Cooper Lake, so maybe L1/L2 are also unchanged.
Thanks, I wrote that while burning the midnight oil and didn't double-check the sanity of those numbers. It's too late to edit mine but I hugely appreciate the clarification.
NP. It's still a huge amount of LLC compared to the status quo. Says something about how expensive it really is to ship all that data between the CCXs/CCDs.
You'd need that latency to be significant enough that AMD's >2x core count doesn't still result in it winning by a landslide anyway, and you need L3 usage low enough that it still fits in Intel's relatively tiny L3 size.
There's been very few cloud benchmarks where 1P Epyc Rome hasn't beaten any offering from Intel, including 2P configurations. The L3 cache latency hasn't been a significant enough difference to make up the raw CPU count difference, and where L3 does matter the massive amount of it in Rome tends to still be more significant.
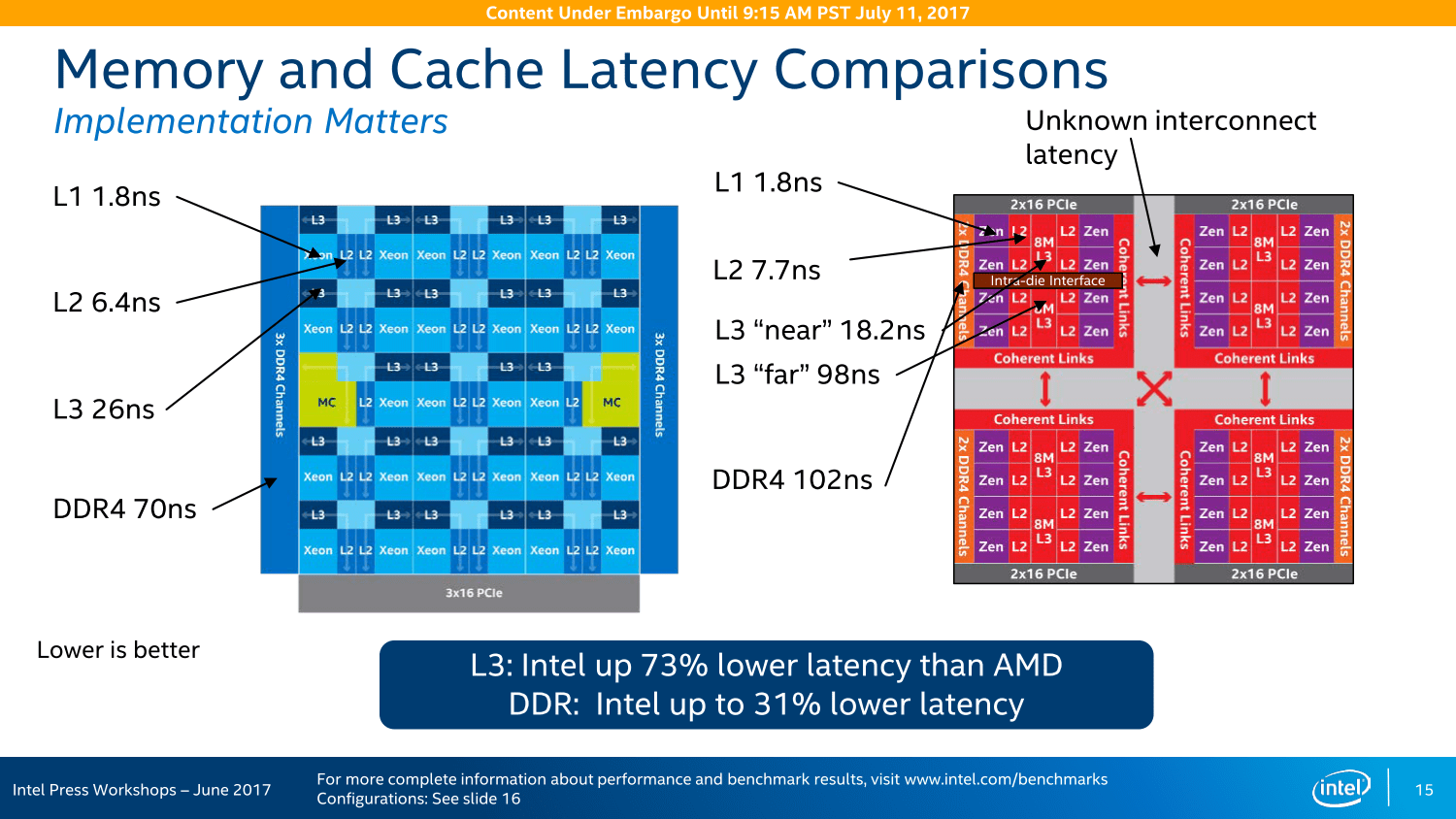
Which is kinda why Intel is just desperately pointing at a latency measurement slide instead of an application benchmark.
Cache per tier matters a lot, total cache does not tell much. L1 is always per core and small, L2 is larger and slower, L3 is shared across many cores and access is really slow compared to L1 and L2. In the end performance per watt for a specific app is what matters, that is the end goal.
Interesting, that's news to me. Guess Intel just has clock speed then. That's why I still pay a premium to run certain jobs on z1d or c5 instances.
As another commenter pointed out, though, not all caches are equal. Unfortunately, I was not able to easily find access speeds for specific processors, so single-threaded benchmarks are the primary quantitative differentiator.
77MB for 56 cores. That's that ploy where they basically glued two sockets together so they could claim a performance per socket advantage even though it draws 400W and that "socket" doesn't even exist (the package has to be soldered to a motherboard).
IIRC the only people who buy those vs. the equivalent dual socket system are people with expensive software which is licensed per socket.
Anecdotal: back then when SETI@home was a thing, I was running it on some servers; a 700 MHz Xeon was a lot faster (>50%, IIRC) than a 933 MHz Pentium 3, Xeon had a lot lower frequency and slower bus (100 vs 133MHz), but the cache was 4 times larger and probably the dataset or most of it was running in cache.
The same happened with the mobile Pentium-M with 1 (Banias) and 2MB (Dothan) cache - you could get the whole lot in cache and it just flew, despite the (relatively) low clock speed. There were people building farms of machines with bare boards on Ikea shelving.
{kind=link}