On a side note: A point that many a company ignores when they demand some assurance so their software vendor a) can be held liable b) will hand over the source in case of drama, is to give the source code in Escrow.
The number one error these companies make is to think that source code without a reproducible build environment means anything at all.
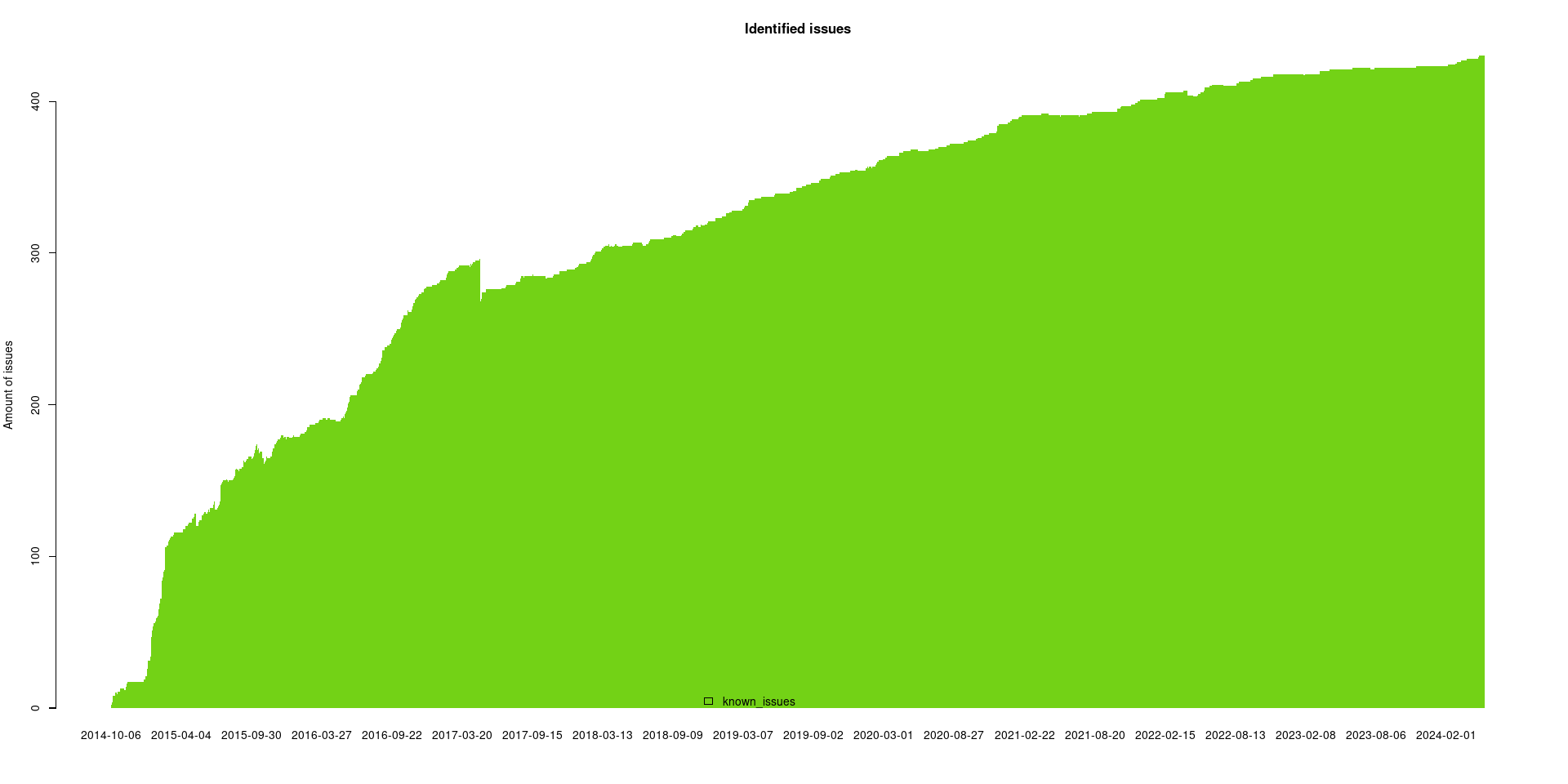
Reproducibility is not easy. I applaud Debian (and in the older days TrueCrypt) for giving this more exposure.
Someplace my company has a closet with a computer containing Windows XP (not sure which service pack, but not the latest), and and old version of visual studio, just in case we need to fix a bug. I know we still have it because the project got resurrected recently and we had to clone the harddrive a few times because nobody could find a copy of that version of visual studio that can be installed. (Microsoft dropped support for whatever version of WinCE with no upgrade path)
It's a term for binaries (usually ELF) being byte-to-byte equal in two
different runs of a compiler. This way you can build a binary package from
source package and if its content is the same, you know what source code was
used to build the package, and then you can e.g. inspect the code for
backdoors or build debug symbols without planning for that beforehand.
Debian seems to only considers a build reproducible if the entire .deb file is byte-for-byte identical, not just the ELF files. A bunch of the packages they're tracking are flagged for documentation files such as PDFs not coming out identical.
It's a good question! It's in fact such a good question that the reproducible builds folks had to draft a solution for it: the SOURCE_DATE_EPOCH specification. Reproducible builds read the timestamp of the last debian/changelog entry (you can imagine the last git commit or something, for non-Debian packages) and pass it through to the build system, so that the "current" time in tarballs etc. is actually the time of the changelog entry.
The "build number" is actually the version, which is determined from debian/changelog. A hash shouldn't change when its input doesn't change. Timestamps can be faked by intercepting system calls.
I'm sure there are many, many more techniques involved in making a build reproducible. Hey, they achieved >90% already!
The best approach that I have found is to use the git commit timestamp (or epoch 1 as a fallback) instead of the current timestamp. After all if the build is reproducible, it doesn't matter when it was built, only what input it was given.
On almost any system, if you use a compiler to build a binary from source code twice in a row, you will get two different binaries. Simple things like using "__DATE__" and "__TIME__" macros in C, or the linker embedding a link timestamp in a executable file header, will trigger this even in the same environment. Moving between machines is even trickier, as __FILE__ and __DIR__ and a ton of other inputs conspire to create changes in the output.
It's hard work to set up a project where you can actually get exactly the same binary over and over again.
I think asking "why is Debian not reproducible" is missing the mark a little - when everything else (Windows, macOS, FreeBSD, etc etc etc) is probably not reproducible, the better question is perhaps "why is Debian trying to be reproducible, and why aren't other projects talking about this just as much" :)
Also some build systems create artifacts as a result of timing-dependent algorithms. Simply put, if two things A and B run simultaneously, and A completes before B, then in some compilers/build systems/etc the result can be different from B completing before A. GHC, as a well-known example, suffers from this problem.
Often, package is built using a certain library version (from a different package), that library is then updated - and the new package cannot build using the new library.
Or... deeper parts of the compiler toolchain change, and the application doesn't re-build without changes.
That has nothing to do with reproducible builds - the issue being solved by reproducible builds is that even in exactly the same environment, running the same build script twice can result in differences in the output.
Surely it can't have "nothing to do" ? Many debian source packages specifies dependencies using >= , something has to account for performing a build using the same minor version of such a dependency.
Yes, but that's a different problem from reproducible builds. The only thing that reproducible builds is solving is ensuring that the same package built with the same dependencies in the same environment results in the same output.
"Second, the set of tools used to perform the build and more generally the build environment should either be recorded or pre-defined"
FWIW, I'm a committer on a Linux distro specifically constructed to guarantee build reproducibility (nixos.org), so I'm pretty sure I know what is generally meant by "reproducible builds" in common industry vernacular. Byte-for-byte is important, but that's hardly the whole picture.
If the dependency is packaged separately, then you typically wouldn't expect minor version changes in the dependency to affect the contents of the package being built. If there are major changes to the header files being exported or if there's static linking involved then changes are to be expected. But if not, you'd expect the changes to show up in the dynamically linked process image, not the on-disk package.
Is Docker (or any other container platform) a facilitator to reproducible builds? Making the environment standard between builds is probably easier in a container.
Docker is part of a broader "reproducible build environment" strategy, but doesn't really help with some of the things that cause problems (timestamps, kernel version, random IDs).
Docker seeks to reproduce a functionally equivalent software environment, motivated by version management concerns. Debian is trying to reproduce bitwise identical build products, motivated by security concerns.
Docker images built with the first-party toolchain aren't reproducible - if you run `docker build ...` on a Dockerfile, then delete the image and rerun it, you'll get a different set of image hashes. This is likely due to timestamp embedding.
There are other toolsets that supposedly create byte-identical Docker images generation (Bazel, some others), but I haven't tried them.
Well, this is Debian - they generally don't maintain the software, they just package it. Small changes can be pushed upstream, but "Here's a brand new build system that we promise is super cool" is generally not a patch that people like taking :)
> Well, this is Debian - they generally don't maintain the software
They definitely maintain software. There is a whole pile of packages that aren't maintained upstream any more that are still maintained in Debian, they write things like manual pages for commands that don't have then, they bash the build scripts into something that works on a whole pile of architectures the author never considers, they manage what is probably the worlds biggest issue track system, and then there is the security team producing patches for versions upstream no longer supports.
But probably it's just your wording. While they do maintain software, they are mostly concerned with packaging existing software, not writing new stuff.
They generally don't maintain the software. Things like manual pages and architecture porting can be pushed upstream, and are fine to maintain as diffs if not; buildsystem changes are usually hard, and maintaining that as a delta makes it hard to incorporate new versions.
(One of the packages I maintain in Debian is apparently dead upstream as of the last year or so, but even so I'm not very interested in becoming the new upstream and adopting big changes like a new build system.)
Based on the experiences of systemd, gtk, and X11 in switching to Meson, I'd think Meson might be the best choice here. While Buck, Bazel, Pants, etc. are designed for large projects, Meson is designed for small-to-medium-size projects and integrates with pkg-config, which in turn should provide simpler integration with distribution package managers. My experiences with Bazel demonstrated that integration with distribution packages can be quite difficult.
Funny that you should mention bazel on the topic of reproducible builds. When I last used it to build TensorFlow, the build was very much not reproducible. I took me three rebuilds with same flags to finally get GPU support compiled in.
Meh, joke sites like this aren't nearly as prominent as sites for apps, I'd really like a .app TLD instead. That said, the distinction between app and service is blurring a lot, so Spotify and VS Code probably both qualify for .app but one also has a web interface. Everything is confusing, let's just stick to .com
The is-foo-bar-yet.com -> NO/YES trope has been off topic on HN for years, mainly because such pages are unsubstantive but also because it's long been a cliché.
If we can find a more substantive page to link to on the same topic, we'll sometimes change the URL. Usually we post a comment explaining that we did so, but it depends who's on duty at the time.
I personally don't think is-foo-bar-yet.com has been played out, nor do I agree with editing cliche links like this. The link is more substantive than you let on.
It is amusing (well, to me) to note that ^lamby here is Chris Lamb, a major contributor to the Debian Reproducible Builds project. If anyone has the social currency to publish a such a capslock "no" and still mean it in a purely informative and constructive way, he probably is towards the top of the list of folks so qualified.
Maybe im missing something but it seems the justification behind this is based on a situation in which source wasnt open. Debian is open so why is reproducibility a priority?
On the contrary. Reproducibility means that given the source you are able to produce the exact same binary, i.e. you can verify that someone didn't modify it before building. When software isn't open, then reproducibility is meaningless, because you don't have the source, so: 1. you can't verify anything (you can't compile anything); 2. assurance of the binary not being modified gives you nothing, since you don't know if there is no malicious code in the original source code.
Not always. TrueCrypt was open source, and yet a huge number of people were worried that the distributed binaries could be backdoor-ed in some way. See this article about someone trying to create a reproducible binary of TrueCrypt.[0]
I know Debian has lofty goals with respect to reproducibility, but on a purely "I hate waiting for builds", getting deterministic object files can prevent spurious linking. For example: change a comment, watch your code link for 10 minutes.
Debian being open only gives you any sort of assurance if you can prove the binary you are using is compiled from that source. Without reproducible builds, you can only (easily) do that if you are building the source yourself (which obviously most people don't).
Reproducibility doesn't really make much sense when the code _isn't_ open - knowing that unknown source code can reliably produce the same output isn't that valuable.
Just to give an example, think about some software you put in a voting machine. Even if the code is open source and given to voters, they need to be able to compile it themselves and compare their compiled version to the one in the voting machine... (well, to be honest, this only makes sense if the voting machine runs the compiled code only and doesn't sneak other stuff in at runtime, but that's another story)
{kind=link}