Does it matter? I mean, come on guys, let's be reasonable. Mankind needs to stop getting so upset about generic language that is male. Unlike other languages, English doesn't have good neutral pronouns that are used colloquially. Know what I mean man?
back before 2000, it really was important to know file formats. we didn't use libraries. we looked up the formats in books and implemented fresh code every time. I prided myself on having memorized most of the .wav header, enough that i didn't need a reference. Then, I learned .fig. Then, I worked on understanding .jpg.
Nowadays, with widespread APIs, the file formats' significance is almost irrelevant! In theory, only a single person in the world needs to know any file format. Everyone else can use a library they've written.
There are different tasks, not everywhere the libraries could be applicable - because of different constraints, like, memory consumption, performance, etc.
For example, For many years I developed and maintained several libraries for high performance media type detection - libraries aren't applicable there. Similarly is for Dara extraction - sometimes you need to have tradeoffs between performance and other parameters, while libraries are optimized for average case.
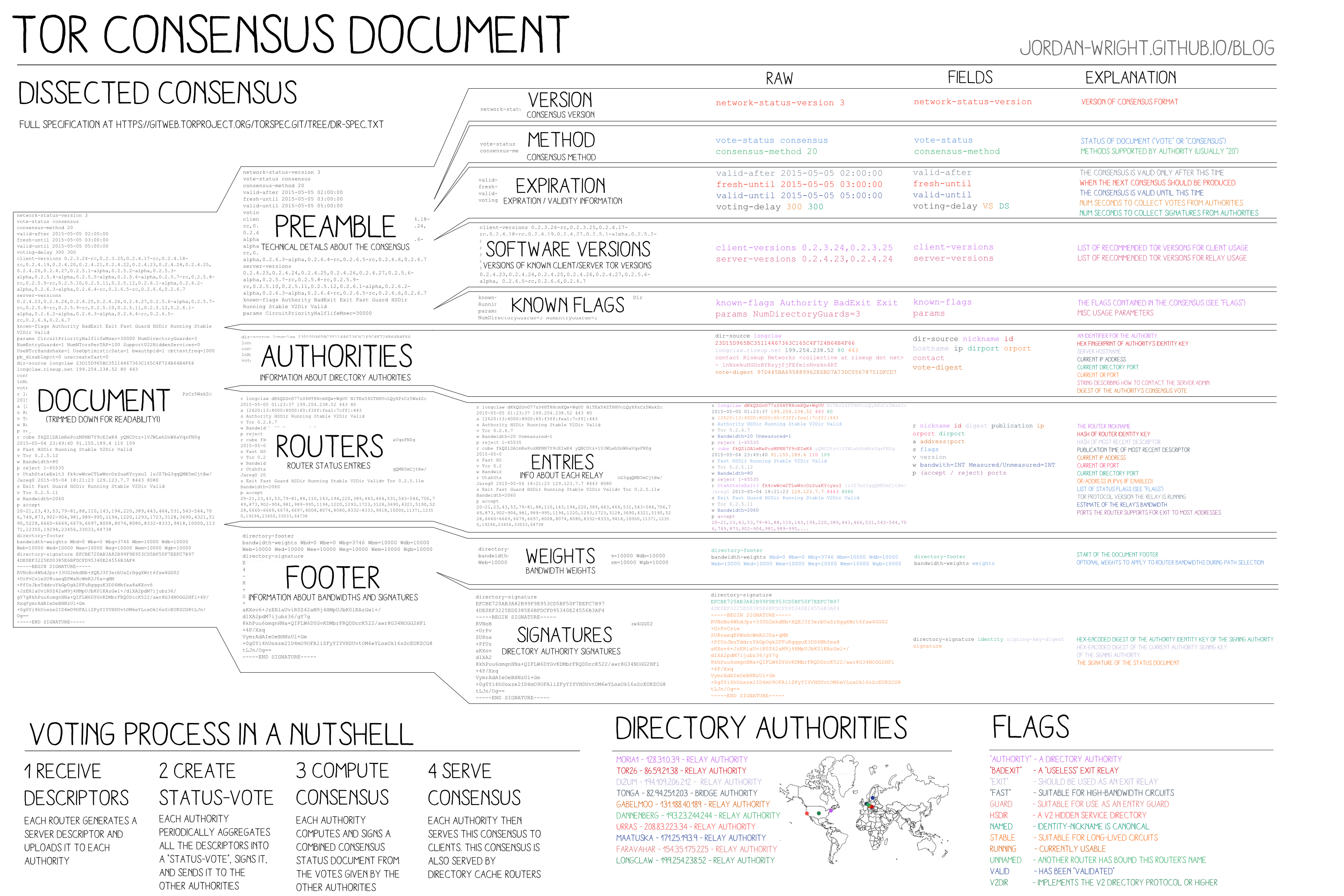
I'm constantly surprised by how often I still need to look up file formats, and having a resource like this is a great starting point.
Some examples from my recent experience for which using a library would be overkill / more effort: examining a .bmp file to figure out why the alpha channel got dropped during resizing; extracting meta-data (top-left pixel alpha value) from a .png file; fixing a failed library-call attempt to change the aspect ratio of an image; working out the version of an ancient document file so I could find an application to read it.
We shouldn't become so dependent on libraries that this kind of simple manipulation forces us to install huge libraries and learn complex APIs for simple tasks, or else we collapse hopelessly into despair. Especially when a simple Python script and a one-page file description can allow us to do the job in a few seconds.
If only that were true. Yet as far as I can determine there is no available Java library which allows for full reading and writing of the JPEG/EXIF file format. There are a number of Java libraries which allow for reading and encoding JPEG image data but none of them offer complete support for the metadata.
The JPEG/EXIF format itself is a mess, just a completely horrible design. It's one of those old-school file formats like MS Word .doc which isn't so much of a "format" as modern programmers commonly understand the term but more like a straight dump of memory chunks into a file. That's not so bad if you're programming in C but surprisingly difficult in higher-level safe languages like Java.
It was surprising to me how few unique implementations there are of JPEG at all. Dig deep enough into most open source image libraries for almost any language, and eventually you'll find IJG libjpeg or one of its descendants.
I think you missed the point. First, we should have learned by now that using an unsafe language like C to read data from an untrusted source directly into memory is really stupid. Just look at the security vulnerabilities that have been found in applications like ImageMagick.
Second, the JPEG/EXIF format is just needlessly complex regardless of language. Instead of marking metadata locations using something sensible like delimiters it's essentially a whole file system within the file with directories and directory entries. The values of some directory entries aren't storied there directly but instead pointed to by a byte offset value. So if you want to insert another entry you have to recalculate all the offsets! Even using C it's easy to screw that up and corrupt the whole file.
In all reality, it was originally named after Shockwave Flash, but the extension meaning was retcon'd to Small Web Format to avoid confusion with Shockwave.
{kind=link}
{kind=link}
{kind=link}
If he runs out of file formats, he could move on to protocols...