> It’s hard to believe that as of 2016, the best method for offline storage in a web app was localStorage
IndexedDB has been around and usable for long enough that I used it on projects >3 years ago, with a fallback to localStorage just in case (looking at you, IE9). Apache Cordova even gave a nice little abstraction over sqlite so that using IndexedDB + phonegap was seamless and gave even more storage (IIRC). It was a pretty solid success for the data-heavy project I was on at the time. Load times the second time around were slashed to almost nothing. The app logic just needed to retrieve anything new since <latest timestamp> from the back end and update the UI.
Our experience was pretty great, though. I definitely highly recommend implementing some sort of domain-specific data caching layer with IndexedDB if you have the chance and if you're moving enough data to justify it. Just make sure you think through the update logic (e.g. use timestamps or log-structured data), and handle merge conflicts appropriately if necessary (i.e. if your app can be used offline).
There are plenty of great wrappers out there that simplify most use cases, too. We ended up going with localForage [1] to simplify refactoring away from localStorage.
What I would really like to see would be Realm in the browser. My experience using it (for mobile development) has been so much better than what I went through with IndexedDB as web developer that it is not even funny.
Now that Realm is entirely open source it could even be a real possibility to have support for it build into web browsers.
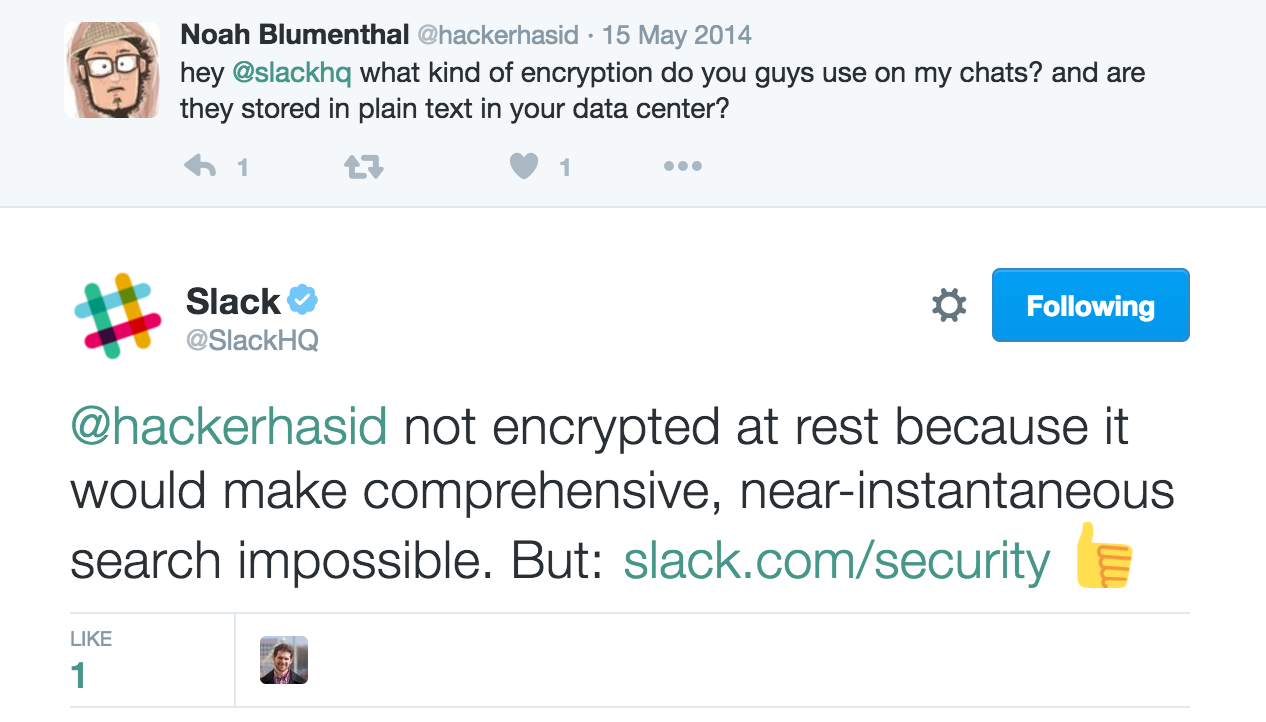
Maybe it is a poor example, but I don't understand how IndexedDB and WebCrypto have anything to do with a distributed chat system like Slack.
For a system where I can join a channel at any time and see what's been said in the past, the information has to live on their servers and be readable. Even more so if you want to be able to search for something someone said across your entire Slack account. You aren't going to have all of that data local to your machine and browser.
They don't want to send down the entire message history every time you switch to a particular conversation window, they want to be able to store as much of that locally as is possible/sensible so that the user doesn't have to wait for a network round trip and it still mostly works offline. They would like to store these messages in IndexedDB but they would like to encrypt them first.
HTTP caches are great for their intended use case, but when used like this they have a lot of limitations.
You can't rely on them existing, having space, or keeping your data for any real amount of time. You can't process the data before it hits the cache, you can't clear them easily, and they are iffy at best when offline.
Yes, but a cache with zero reliability isn't very useful.
If I do an expensive operation, then need to use its result later, I can't rely on the HTTP cache as the browser may never have cached it in the first place, or may have evicted it by the time I go to use it. So using that unreliable cache can actually make things worse in the sense of more data usage, more power usage, more battery usage, and more memory usage.
For a real world example, say I wanted to pre-fetch a bunch of data on page-load, then in a later page I want to use the cache to be able to quickly get that information and use it without any latency. If I had some control over the HTTP cache, I could do this.
But as it stands right now, I can try to make a GET request on the page load, but when the user clicks the button to see the result on a later page, it's a crapshoot on whether or not the HTTP cache will still have it, leading to the user having to wait sometimes, and not other times, duplicated requests, and a lot more data usage.
With localstorage, IndexedDB, WebSQL, etc... I have that control. I can know that the information is going to stay there until I need it so I don't need to worry about my caching making things worse.
* I don't understand how IndexedDB and WebCrypto have anything to do with a distributed chat system like Slack*
Uh, what? The OP didn't mention Slack at all. I mean, you could make this kind of...comment on anything: "What does X have to do with Y?" (In this case, X=(WebCrypto & IndexedDB) and Y=(Slack)). But it's not very useful.
Yes, you're right. I missed it. I guess he's making a point about wanting his own chat history searchable on his client, and yet opaque to the server-side Slack operators. I agree it's not a great application, though.
For everybody starting to use indexedDB I recommend to take a look at Dexie.js (http://dexie.org/) for a minimalistic wrapper which might save you from a lot of pain as working directly with indexedDB is no fun imho.
Another protip: localForage [1] makes it fairly easy to drop in IndexedDB if you're used to the localStorage interface. The only drawback is that you have to refactor into using promises, since IndexedDB is async.
I'm a big fan of localForage. It handles the fallbacks on various devices. There's a few things it doesn't do super-well (multiple get/set operations in a batch, notably), but it's a great polyfill, especially if you don't want to mess around with the intricacies of indexedDB.
+1 to that. In fact, it's a bad idea to not to use a wrapper. I started out thinking I didn't need it but found that I was implementing parts of Dexie (poorly). It's also very well documented.
This still doesn't explain how large scale search indexing could take place effectively... the data still needs to float upstream un-encrypted, processed and indexed.
Somehow offloading full-text indexing to the client, uploading encrypted indexes to the server and then elegantly combining those indexes across users to display a unified search would be arduous and I don't see anyone doing it.
Also, IndexedDB has been around for years and still suffers from a variety of cross-browser inconsistencies that make it a little painful to work with.
How on earth is SlackHQ's response reasonable? Let me count the ways it's not.
There are plenty of database systems (MySQL enterprise, Postgres, Oracle, SQL Server) that support encrypted data-at-rest and there are even more ways to run a DBMS on top of encrypted disks and volumes (dm-crypt, Bitlocker).
Running in the cloud? Amazon AWS provides EBS encryption (and likely more) and Microsoft Azure provides data at rest encryption for all storage types (tables, queues, page and block (disk) blobs) and transparent encryption for Azure SQL Database.
Want more control over the encryption in the cloud? Amazon and Azure both provide HSMs, called CloudHSM and Azure Key Vault, respectively. Azure supports additional encryption at the VM level integrating with Bitlocker and/or DM-Crypt.
There's really no excuse for not having figured out data encryption for customer data and secrets at this point.
Edit: It appears Slack has since updated their security docs and they now use encryption at rest. Good! It's inexplicable to me that anyone would believe that a database index would be incompatible with encryption.
I don't understand how any encryption like this helps, unless it's end-to-end. When somebody breaks in, they just get the encryption keys as well, no? Can anyone point out what am I missing here? Thank you.
When "somebody" breaks in, what level of access do they have? In a larger business, access should be compartmentalized and enforced not just with policies but with encryption where possible.
Virtual machine or cloud service administrators shouldn't have the ability to read customer data, they should just see binary blobs.
A devops/sysadmin employee might have access to the machines running the database, but even if they log in they shouldn't necessarily have read access to the database files, and even if they should, again, customer data should be encrypted blobs to them.
This means that even if you phish the CEO of the company, you still have to obtain additional access to read customer data. If using AWS or Azure encryption properly, it may even require obtaining credentials for multiple users.
This isn't even the full extent of the encryption possible, keys can be placed in silos per tenant, and decrypted only once a user logs in. Then even if you are a developer, you wouldn't have access without intercepting client communications.
Haven't read through the WebCrypto standard, but it's hard to create a real barrier between a server process and a client process on the web. In essence, any good crypto UI would have to happen outside of the client process, so that the server cannot intercept your input. (This is my objection to well-meaning companies that say "Hey, we can't even read your stuff, it's encrypted on the client" because, if you have auto-update, or if you ccan inject code into the client, that privacy guarantee can be revoked at any time.)
> if you have auto-update, or if you can inject code into the client, that privacy guarantee can be revoked at any time
Anytime you use software built by someone other than you, any guarantee can be revoked at any time - the distributor can put whatever they want into the software! When a distributor makes claims about the privacy/security of a product, at some point you either trust them and take them at their word, or you don't - in which case, it doesn't matter what they say.
Unless the product is open-source and self-hosted, that is.
If the binary you are using is signed, and the signature is well-known via a side channel, you can at least make sure you're running the same binary.
If the binary was built from a known source, and the build is reproducible, you can even be sure that the binary really represent the code in question; bugging a compiler so that it injects a malicious payload and keeps a crypto signature the same is a bit hard. (But the whole "trusting trust" chain applies.)
I'm with you there - I was more talking about the trust that needs to exist that the (official) binary distributor really is following through on their claims about privacy or security.
Having a local storage of this type is half the problem. The other half is syncing the data between different browsers and keeping it backed up. Imagine if all your mail, years and years of it, lived in IndexDB inside your browser on your one device.
I think browsers should implement a standard way to sync local storage, identity information (think private keys instead of passwords), cookies, etc. across all the browsers you use. Oh and obviously it should all be encrypted at rest and you get to choose which service you use to sync the data, so you can avoid the less trusted ones. What kind of utopia would this be?
The sad thing is, there was this idea for WebSQL ages ago and it would have solved this problem AND made database-backed apps easy to write, plus firefox and chrome already use sqlite internally so you could reuse that as the engine. Apparently it wasn't hip enough for the NoSQL folks though.
Actually, the issue (as I understand it) was that a web standard requires at least three different implementations (otherwise, it's less of a standard and more of a plugin). Chrome basically exposed SQLite to web apps, which meant other browsers would have needed to reimplement SQLite in order for WebSQL to become a standard. That said, I do wish they had gone the SQL route vs NoSQL.
It was originally implemented in WebKit, rather than Chrome (heck, it predates Chrome being public). As far as I'm aware, there were lots of politics behind closed doors (i.e., inside the companies involved) that resulted in there being no attempt to even specify a dialect of SQL (whether it were SQLite or otherwise), hence the inevitable failure of any SQL-based standard. Something not-SQL was the best that could get standardised, sadly.
Assuming you are storing only encrypted data on the server and cannot read it without the user's password, what happens if the user loses their password? Are they just left with a bunch of unreadable data that came from the server?
Doesn't this approach also make it difficult to share information between other users?
Having offline-first, client side encrypted apps seem to have a lot more problems than just "you know who" spying on you.
The big use case for this would be for workplace use, not for social / community use. In that case, since it's the company's account system (whether it's actual SSO, or just access to the email account where password resets go) that authoritatively identifies users, it's reasonable for the company's IT department to have a way to issue replacement keys that can also decrypt the data.
Encrypting data client-side doesn't make it difficult to share information between other users of the same system: all you do at the protocol level is send them a message with the data, or perhaps with a key for decrypting a stored file. It's really just a matter of UI to make it smooth. If anything, it makes it slightly easier because you can use any transport mechanism you like for sending the ciphertext; you're no longer obligated to route everything through HTTPS connections to a single server. So, for instance, you can throw encrypted uploaded files in an S3 bucket, and maintain availability for existing data even if the service provider is having an outage, because users can access and decrypt that data using their client.
It does make it more difficult to share it outside the system (to people without accounts) without storing it decrypted.
re: "But if the server could read your data, then practically any engineer of the company could read your data [...]"
A caveat: this tends to be true of startups. If you don't know who you're dealing with, it's probably a safe assumption to make. But larger companies often have internal permissions in place to prevent any engineer from reading user data.
Hey, I'm kind of a novice to web dev (especially when it comes to security) so could somebody please explain why you can't implement end-to-end encryption and search capability ?
You can only search data if you can read it, so it needs to be unencrypted. With end-to-end, this means only the data you have locally, so you can only do local searches. In the Slack example, (I assume) Slack uses their servers to pre-fetch search results for a faster experience.
A question - does it matter for webcrypto API's trustability to have window.crypto be redefinable to anything a piece of JavaScript code desires? (Ex: extensions)
I find it hard to make any claims about safe local encryption using webcrypto API if, post encryption, a new extension can be installed that will sniff the keys as you decrypt to access your data.
In the browser, extensions can be thought of as programs with root permissions in many cases. They can do anything to the page. But this isn't new to the web, your kernel can be "changed" if you give something permission to change it and that kernel can sniff your keys as well.
There's definitely a "societal" issue around how much power extensions have, but I don't think it's any different than most "platforms" in that if you give something root, it can do anything.
At this point, my browser's (Chrome's) URL bar reads "Secure | https://news.ycombinator.com/....". I have quite a few extensions loaded including ad blockers. Is the "Secure" statement trustable? Should window.crypto be trustable in the same way? ... as a guarantee provided by the browser in spite of extensions? Is that even possible?
Well it's secure in that the connection between you and ycombinator is secure.
But any of your extensions that have permission to modify the page, can be modifying it in any way shape or form.
So they could be rewriting my comment, they could be calling out to external servers sending all the contents of your page, they could be recording every keystroke on that page, and more.
So no, you can't trust that "Secure" statement absolutely.
And while the browser could make window.crypto immutable or "un modifiable", it would be a false sense of security as an extension could just get the result from the page when it's put into the DOM.
This article is a very long write about nothing. Throws up topics and questions, and provides no explaination or answer.
An example of medium click bait that leads to medium's eventual demise. Being a platform for badly written PR bullshit will not work out for medium imho.
So after a bunch of work is done, I can have search on Slack like I have now. I understand it's better to have my chats encrypted at rest, but I wonder how many users are interested enough in that to make this change happen.
Everybody who exchange somehow sensitive info in Slack from their laptops and phones? Because these devices can be stolen.
OTOH such people should use a full-disk encryption on laptops anyway. With phones, it's a bit more tricky, especially if an external SD card is used, but solutions still exist, AFAIK.
WebCrypto is security theater. The server could just swap the JS for a version that decrypts your secrets client-side and uploads the plaintext (or just uploads the key) to the server. Next time you hit the page your secrets are compromised.
Also, if you use "50% of the user’s disk space" you can go fuck yourself.
How is that any worse if you stick with CryptoJS, where you get the entire implementation from the server anyway? Or any other application you download that uses crypto and has an update mechanism for that matter?
CryptoJS is security theater, too. Doing crypto in JavaScript in a browser is never secure.
An application with a silent update mechanism has the same problem. An update mechanism that tells you its happening and waits for your approval does not.
Becomes more difficult to say. I would suggest that it is, yes. However, the tradeoff is more difficult to make, you have to decide if you trust Google not to push a sour update (but consider that it might be compelled to by a state actor). Also note that Chrome might have different secrets to share in the first place, it could just break future SSL connections or share saved passwords or something.
Personally, running Chromium on Linux, I don't get automatic updates and go through the usual process of signed updates from package maintainers only when I approve them.
{kind=link}
IndexedDB has been around and usable for long enough that I used it on projects >3 years ago, with a fallback to localStorage just in case (looking at you, IE9). Apache Cordova even gave a nice little abstraction over sqlite so that using IndexedDB + phonegap was seamless and gave even more storage (IIRC). It was a pretty solid success for the data-heavy project I was on at the time. Load times the second time around were slashed to almost nothing. The app logic just needed to retrieve anything new since <latest timestamp> from the back end and update the UI.
Our experience was pretty great, though. I definitely highly recommend implementing some sort of domain-specific data caching layer with IndexedDB if you have the chance and if you're moving enough data to justify it. Just make sure you think through the update logic (e.g. use timestamps or log-structured data), and handle merge conflicts appropriately if necessary (i.e. if your app can be used offline).
There are plenty of great wrappers out there that simplify most use cases, too. We ended up going with localForage [1] to simplify refactoring away from localStorage.
[1] https://github.com/localForage/localForage