" Make the most powerful flops-per-watt machine. SUCCESS!"
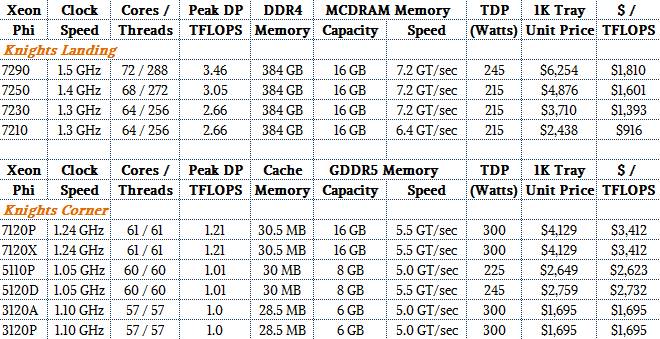
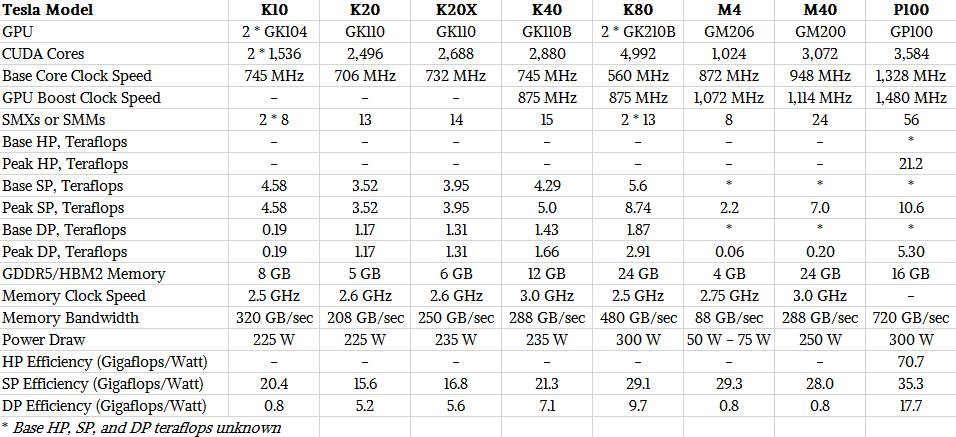
Hum not at all... Larrabee gets destroyed by the competition in terms of flops-per-watt. Knights Corner is rated 8 GFLOPS/W at the device level (2440 GFLOPS at 300 W). For comparison Nvidia Tesla P100 rates 4× better: 32 GFLOPS/W (9519 GFLOPS at 300 W) and AMD Pro Duo rates ~6× better: 47 GFLOPS/W (16384 GFLOPS at 350 W although in the real-world it probably often hits thermal limits and throttles itself, so real-world perf is probably closer to 30-40 GFLOPS/W).
Also, if Intel wants to make Larrabee gain mindshare and marketshare, they need to sell sub-$400 Larrabee PCIe cards. Right now, everybody and their mother can buy a totally decent $200 AMD or Nvidia GPU and try their hands at GPGPU development. And if they need more performance, they can upgrade to a multiple high-end cards, and their code almost runs as is. But because Larrabee's cheapest model (3120A/P) starts at $1695 (http://www.intc.com/priceList.cfm), it completely prices it out of many potential customers (think students learning GPGPU, etc).
Larrabee gets destroyed by the competition in terms of flops-per-watt
While I expect the graphics cards to have the edge in performance per watt for brute-force math, I'm surprised that the current GPU's would have that large of an advantage. Are you sure you are comparing the same size "flops" for each?
And while it's in keeping with the article, I don't think lumping all the generations together as "Larrabee" makes sense when comparing system performance. While availability is still minimal, Knights Landing is definitely the current generation (developer machines are shipping), and as you'd expect from a long-awaited update at a smaller process size, efficiency is a lot better than older generations.
2016 Tesla P100: 5.30 DP TFLOP using 300W == 18 DP GFLOPS/W.
I don't know if these numbers are particularly accurate (I think actual KNL numbers for the developer machines are still under NDA), but I think the real world performance gap will be something more like this than one approach "destroying" the other. If you are making full use of every cycle, the GPU's will win by a bit. If your problem requires significant branching, Phi won't be hurt quite as badly.
Also, if Intel wants to make Larrabee gain mindshare and marketshare, they need to sell sub-$400 Larrabee PCIe cards.
The interesting move Intel is making is to concentrate initially on KNL as heart of the machine rather than as an add-in card. This gets you direct access to 384GB of DDR4 RAM, which opens up some problems that current graphics cards are not well suited for. I think this plays better to their strengths: if your problem is embarrassingly parallel with moderate memory requirements, modern graphics cards are a better fit. But if you need more RAM, or your parallelism requires medium-strength independent cores, Phi might be a better choice.
But because Larrabee's cheapest model (3120A/P) starts at $1695
While it's true that Intel's list pricing shows they aren't targeting home use at this point, List Price may not be the best comparison. For a while last year, 31S1P's were available at blow out prices that beat all the graphic cards. In packs of 10, they were available at $125 each: http://www.colfax-intl.com/nd/xeonphi/31s1p-promo.aspx.
Would love to kick tires of one of those Knight's Landing cards.
It might be possible to pull off similar tricks as on normal Intel Xeons. I wonder what kind of memory controller it got. Does it for example have hardware swizzling and texture samplers accessible?
But we use exclusively Nvidia for our number crunching product. And since the relevant code is implemented in CUDA, we have an Nvidia platform lock-in. Other options are not even on the table, and will not be.
Intel would be very smart to offer a migration path from CUDA code.
You are right I shouldn't lump all generations together as "Larrabee". I didn't realize the definitive specs of Knights Landing came out (2 months ago?). KL does improve a lot over KC, and now almost matches current GPUs:
KC: 8 GFLOPS/W at the device level (Xeon Phi 7120: 2440 GFLOPS at 300 W).
KL: 28 GFLOPS/W at the device level (Xeon Phi 7290: 6912 GFLOPS at 245 W).
Compare this to 32-47 GFLOPS/W at the device level for current-generation AMD and Nvidia GPUs.
{kind=link}
{kind=link}
Hum not at all... Larrabee gets destroyed by the competition in terms of flops-per-watt. Knights Corner is rated 8 GFLOPS/W at the device level (2440 GFLOPS at 300 W). For comparison Nvidia Tesla P100 rates 4× better: 32 GFLOPS/W (9519 GFLOPS at 300 W) and AMD Pro Duo rates ~6× better: 47 GFLOPS/W (16384 GFLOPS at 350 W although in the real-world it probably often hits thermal limits and throttles itself, so real-world perf is probably closer to 30-40 GFLOPS/W).
Also, if Intel wants to make Larrabee gain mindshare and marketshare, they need to sell sub-$400 Larrabee PCIe cards. Right now, everybody and their mother can buy a totally decent $200 AMD or Nvidia GPU and try their hands at GPGPU development. And if they need more performance, they can upgrade to a multiple high-end cards, and their code almost runs as is. But because Larrabee's cheapest model (3120A/P) starts at $1695 (http://www.intc.com/priceList.cfm), it completely prices it out of many potential customers (think students learning GPGPU, etc).