But, fascinatingly, integration does in fact have a meaning. First, recall from the OP that d/dX List(X) = List(X) * List(X). You punched a hole in a list and you got two lists: the list to the left of the hole and the list to the right of the hole.
Ok, so now define CrazyList(X) to be the anti-derivative of one list: d/dX CrazyList(X) = List(X). Then notice that punching a hole in a cyclic list does not cause it to fall apart into two lists, since the list to the left and to the right are the same list. CrazyList = CyclicList! Aka a ring buffer.
There's a paper on this, apologies I can't find it right now. Maybe Alternkirch or a student of his.
The true extent of this goes far beyond anything I imagined, this is really only the tip of a vast iceberg.
I explored a similar idea once (also implemented in Python, via decorators) to help speed up some neuroscience research that involved a lot of hyperparameter sweeps. It's named after a Borges story about a man cursed to remember everything: https://github.com/taliesinb/funes
Maybe one day we'll have a global version of this, where all non-private computations are cached on a global distributed store somehow via content-based hashing.
Thanks! Indeed, the ultimate (but very ambitious from the point of view of coordination and infrastructure) vision would be to build the "planetary computer" where everyone can contribute and every computation is transparently reproducible. While researching `mandala`, I ran into some ideas along those lines from the folks at Protocol Labs, e.g. https://www.youtube.com/watch?v=PBo1lEZ_Iik, though I'm not aware of the current status.
The end-game is just dissolving any distinction between compile-time and run-time. Other examples of dichotomies that could be partially dissolved by similar kinds of universal acid:
* dynamic typing vs static typing, a continuum that JIT-ing and compiling attack from either end -- in some sense dynamically typed programs are ALSO statically typed -- with all function types are being dependent function types and all value types being sum types. After all, a term of a dependent sum, a dependent pair, is just a boxed value.
* monomorphisation vs polymorphism-via-vtables/interfaces/protocols, which trade roughly speaking instruction cache density for data cache density
* RC vs GC vs heap allocation via compiler-assisted proof of memory ownership relationships of how this is supposed to happen
* privileging the stack and instruction pointer rather than making this kind of transient program state a first-class data structure like any other, to enable implementing your own co-routines and whatever else. an analogous situation: Zig deciding that memory allocation should NOT be so privileged as to be an "invisible facility" one assumes is global.
* privileging pointers themselves as a global type constructor rather than as typeclasses. we could have pointer-using functions that transparently monomorphize in more efficient ways when you happen to know how many items you need and how they can be accessed, owned, allocated, and de-allocated. global heap pointers waste so much space.
Instead, one would have code for which it makes more or less sense to spend time optimizing in ways that privilege memory usage, execution efficiency, instruction density, clarity of denotational semantics, etc, etc, etc.
Currently, we have these weird siloed ways of doing certain kinds of privileging in certain languages with rather arbitrary boundaries for how far you can go. I hope one day we have languages that just dissolve all of this decision making and engineering into universal facilities in which the language can be anything you need it to be -- it's just a neutral substrate for expressing computation and how you want to produce machine artifacts that can be run in various ways.
Presumably a future language like this, if it ever exists, would descend from one of today's proof assistants.
> The end-game is just dissolving any distinction between compile-time and run-time
This was done in the 60s/70s with FORTH and LISP to some degree, with the former being closer to what you're referring to. FORTH programs are typically images of partial applications state that can be thought of as a pile of expanded macros and defined values/constants (though there's virtually no guardrails).
That being said, I largely agree with you on several of these and think would like to take it one step further: I would like a language with 99% bounded execution time and memory usage. The last 1% is to allow for daemon-like processes that handle external events in an "endless" loop and that's it. I don't really care how restricted the language is to achieve that, I'm confident the ergonomics can be made to be pleasant to work with.
> This was done in the 60s/70s with FORTH and LISP to some degree
Around 2000, Chuck Moore dissolved compile-time, run-time and edit-time with ColorForth, and inverted syntax highlighting in the process (programmer uses colors to indicate function).
> The end-game is just dissolving any distinction between compile-time and run-time.
I don't think this is actually desireable. This is what Smalltalk did, and the problem is it's very hard to understand what a program does when any part of it can change at any time. This is problem for both compilers and programmers.
It's better, IMO, to be able to explicitly state the stages of the program, rather than have two (compile-time and run-time) or one (interpreted languages). As a simple example, I want to be able to say "the configuration loads before the main program runs", so that the configuration values can be inlined into the main program as they are constant at that point.
> This is what Smalltalk did, and the problem is it's very hard to understand what a program does when any part of it can change at any time.
I don't think dissolving this difference necessarily results in Smalltalk-like problems. Any kind of principled dissolution of this boundary must ensure the soundness of the static type system, otherwise they're not really static types, so the dynamic part should not violate type guarantees. It could look something like "Type Systems as Macros":
There are pretty important reasons to have this distinction. You want to be able to reason about what code actually gets executed and where. Supply-chain attacks will only get easier if this line gets blurred, and build systems work better when the compile stage is well-defined.
That's not necessarily the only approach though. In a dependently typed language like Agda, there is also no difference between compile-time or runtime computation, not because things can change any time (Agda is compiled to machine code and is purely functional) but because types are first-class citizens, so any compute you expect to be able to run at runtime, you can run at compile time. Of course, this is in practice very problematic since you can make compiler infinitely loop, so Agda deals with that by automatically proving each program will halt (i.e. it's Turing-incomplete). If it's not possible to prove, Agda will reject to compile, or alternatively programmer can use a pragma to force it (in which case programmer can make the compiler run infinitely).
I think part of the purpose of the Agda project is to see how far they can push programs as proofs, which in turn means they care a lot about termination. A language that was aimed more at industrial development would not have this restriction.
No it's not, you can write an extremely large set of programs in non-Turing complete languages. I personally consider Turing completeness a bug, not a feature, it simply means "I cannot prove the halting problem of this language" which blocks tons of useful properties.
You can write useful programs in Agda. I wrote all kinds of programs in Agda including parsers and compilers.
Symbolica.ai | London, Australia | REMOTE, INTERNS, VISA
We're trying to apply the insights of category theory, dependent type theory, and functional programming to deep learning. How do we best equip neural nets with strong inductive biases from these fields to help them reason in a structured way? Our upcoming ICML paper gives some flavor https://arxiv.org/abs/2402.15332 ; you can also watch https://www.youtube.com/watch?v=rie-9AEhYdY&t=387s ; but there is a lot more to say.
If you are fluent in 2 or more of { category theory, Haskell (/Idris/Agda/...), deep learning }, you'll probably have a lot of fun with us!
Hi, I tick the three elements in the set (my last Haskell was a few years ago, though). I opened the link last week and saw some positions in London (and Australia, for that matter) and now there aren't any positions showing there (just a couple ones in California). Is it a glitch, or have you fulfilled all positions outside California already?
How demanding is this for someone self taught CT up until Natural Transformations and dabbles a bit on other more common CT constructions (SCMC Categories & Co), F-Algebras ? I do have quite some experience with Haskell and Theorem Provers and this sounds super fun but also all the fancy keywords scare me as I am not super into ML/DeepLearning nor have a PhD (only a MSc in SWEng). Is there room for learning on the job?
It's a shame that the word categorical has already been applied to deep learning (categorical deep q networks a.k.a. C51, and Rainbow), because yours is arguably a more natural use of the name.
While I applaud the OP's exposition, imagine that instead of having axis names live as single-letter variables within einsum, our arrays themselves had these names attached to their axes?
It's almost like when we moved from writing machine code to structured programming: instead of being content to document that certain registers corresponding to certain semantically meaningful quantities at particular times during program execution, we manipulated only named variables and left compilers to figure out how to allocate these to registers? We're at that point now with array programming.
> imagine that instead of having axis names live as single-letter variables within einsum, our arrays themselves had these names attached to their axes?
I already replied to a couple of other comments with this, but you're exactly describing the Python library Xarray: https://docs.xarray.dev/en/stable/ I've found it to work quite well in practice, and I've gotten a lot of mileage out of it in my work.
Thanks for highlighting XArray in your other comments. Yup, XArray is great. As are Dex and the various libraries for named axis DL programming within PyTorch and Jax. I never said these things don't exist -- I even mention them in the linked blog series!
But I do think it's fair to say they are in their infancy, and there is a missing theoretical framework to explain what is going on.
I anticipate name-free array programming will eventually be considered a historical curiosity for most purposes, and everyone will wonder how we put up without it for so long.
Thanks for pointing that out, and sorry for being redundant. I skimmed the blog but missed that.
Overall, I agree with your larger point. I think this it's a natural progression and pretty analogous to assembly language leading to higher-level languages with a much better developer experience. In that case we went from fixed registers to developer-named variables, and now we can go from fixed numerically-indexed array axes to ones indexed by developer-chosen names.
No worries! Yes, exactly. It's also similar to doing arithmetic with and without units. Sure, you can do arithmetic without units, but when you are actually working with real-world quantities, but you easily get yourself into a muddle. Unit-carrying quantities and algebraic systems built on them prevent you from doing silly things, and in fact guide you to getting what you want.
Yeah, I'm totally with you on the units, too. For me it's even more frustrating, because it's such an obvious and ubiquitous problem, and still relatively unacknowledged. There are third-party solutions (like Pint in Python), but in my experience by default scientific software projects tend to begin with just NumPy basically, and introducing more advanced (IMO) tools like Xarray and Pint is an uphill battle against ingrained habits.
PyTorch also has some support for them, but it's quite incomplete and has many issues so that it is basically unusable. And its future development is also unclear. https://github.com/pytorch/pytorch/issues/60832
Hey there, a bit late but I've read your other comments and I'd like to get in touch. I happen to be very focused on type derivatives, in the context of applying category theory to AI, having just discovered Conor's original papers. Your comment was extremely helpful. Please email me at tali@tali.link if you see this.
That is an excellent explanation full of great intuition building!
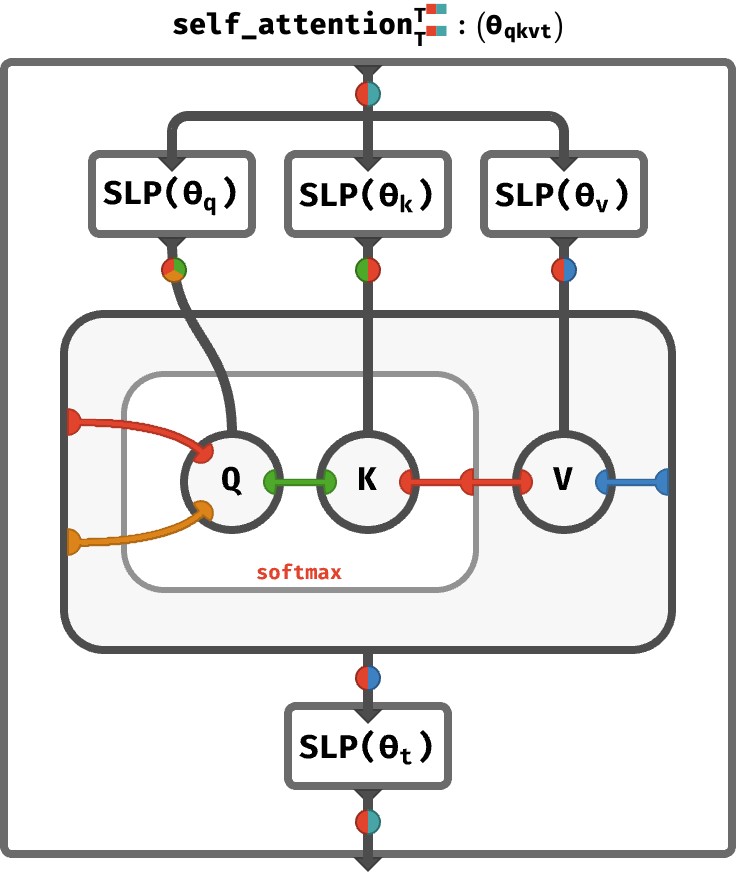
If anyone is interested in a kind of tensor network-y diagrammatic notation for array programs (of which transformers and other deep neural nets are examples), I wrote a post recently that introduces a kind of "colorful" tensor network notation (where the colors correspond to axis names) and then uses it to describe self-attention and transformers. The actual circuitry to compute one round of self-attention is remarkably compact in this notation:
Amazing, but that's a lot of channels for a cheap oscilloscope. I'm curious how he did that, I don't see any wiring. Also, he missed an opportunity to bring in the rudiments of transmission line theory -- a twisted pair is a continuum limit of tiny coupled capacitors. And these same kinds of waves can propagate in the vacuum, which is a kind of universal 3D grid of coupled harmonic oscillators. In which case we call the waves photons!
Recorded seperate samples for each test location, and then wrote visualization software that recombined those recorded traces.
Because there is no real reason for two different runs to be significantly different, (especially if the electronic switch shorts out the source ends of the wires between each test to discharge any capacitance that built up between the wires), the results should not be much different than if using an 80 channel scope.
Except the battery will get run down over time, and won't produce the same voltage at the same speed for the 80th run as it does for the first. You need a benchtop power supply for that.
{kind=link}
But, fascinatingly, integration does in fact have a meaning. First, recall from the OP that d/dX List(X) = List(X) * List(X). You punched a hole in a list and you got two lists: the list to the left of the hole and the list to the right of the hole.
Ok, so now define CrazyList(X) to be the anti-derivative of one list: d/dX CrazyList(X) = List(X). Then notice that punching a hole in a cyclic list does not cause it to fall apart into two lists, since the list to the left and to the right are the same list. CrazyList = CyclicList! Aka a ring buffer.
There's a paper on this, apologies I can't find it right now. Maybe Alternkirch or a student of his.
The true extent of this goes far beyond anything I imagined, this is really only the tip of a vast iceberg.