Part of the problem of this form of benchmarking is that in some domains we wouldn't only be interested in the percent of times that an error channel is successfully mitigated, we would also be interested in the distribution of types of errors for cases where an error channel isn't successfully mitigated. The paper appears to be silent on that matter.
Thank God someone other than Scott Aaronson is publishing this kind of content. Shetl Optimized is too much of a vanity project to serve as a mainstream resource.
Joplin really laid the stage for the emergence of jazz music. The ragtime conventions are deceptively simple, they carry a kind of counter balance between the cleffs almost resembling polka at times, but the rhythmic styles often are more subtle with off beat progressions. The song structures progressing through chapters of themes are particularly interesting and lacking from most modern popular music.
The book is not just about the ideas, it is about the tapestry of how it was presented. It was a new form of literature. The whole document was its own strange loop.
Hi there, author here, this collection marks the sixth year of writing essays on themes like machine learning, entrepreneurship, and quantum computing. Through the project we've published a python library, had workshop papers at research conferences like ICLR and NeurIPS, and yeah just had a lot of fun. Some thanks owed to the Hacker News feed for fueling us with diversions over the years. Never quite made it into YC but you know what I think the essays may have turned out better as a result. Cheers.
You can't evaluate rationality in context of small number of samples of a fat tailed distribution with wide uncertainty bands. Besides, startups can be a kind of success even in failure based on opportunities that arise as a result.
The funny thing is that entrepreneurship doesn't even have to require dropping out of school. A three month summer break is easily enough time to start digging into a niche and validating the market. It probably won't get to sustainability, but by the end of a summer of focus you may at least know if there is something there worth pursuing. A better investment of time than backpacking across Europe.
My version of backpacking across Europe is what inspired me to start my own business when I returned home. A business I’ve been running for 5 years now. My eyes were opened to alternative life and career paths by the extraordinary people I met along the way. Had I stayed in my bubble after university I would likely have gone down the corp route like almost all of my peers.
They cited some of LeCun's solo work from the 80's on related matters, note that he also collaborated with Geoffrey Hinton on a related paper from NIPS 89 in which they used random perturbations to derive a gradient signal. One of the limitations of that approach was that it required each layer to have fewer units than the preceding one.
I cited this in a recent paper because it was representative of different cases for stochastic injections in neural networks. Interesting to see that similar lines of inquiry are continuing to this day.
The root enabling factor was not only the reinforcement learning, it was the simulation. Put differently, any environment that you can simulate within sufficient accuracy, you can derive robust and efficient control by reinforcement learning.
I'm probably being excessively pedantic but I would suggest sufficient fidelity is a more appropriate phrase than sufficient accuracy.
The exact precision doesn't seem to be the underlying problem being solve, what matters is being able to craft a stronger understanding of relationships of underlying phenomena that can then be leveraged to product new control theories.
I think they are just talking about how accurately the model reflects the real world.
If someone draws a map and it has some streets with the wrong names, you say, "This map is not accurate." It doesn't mean you are talking about something numerical.
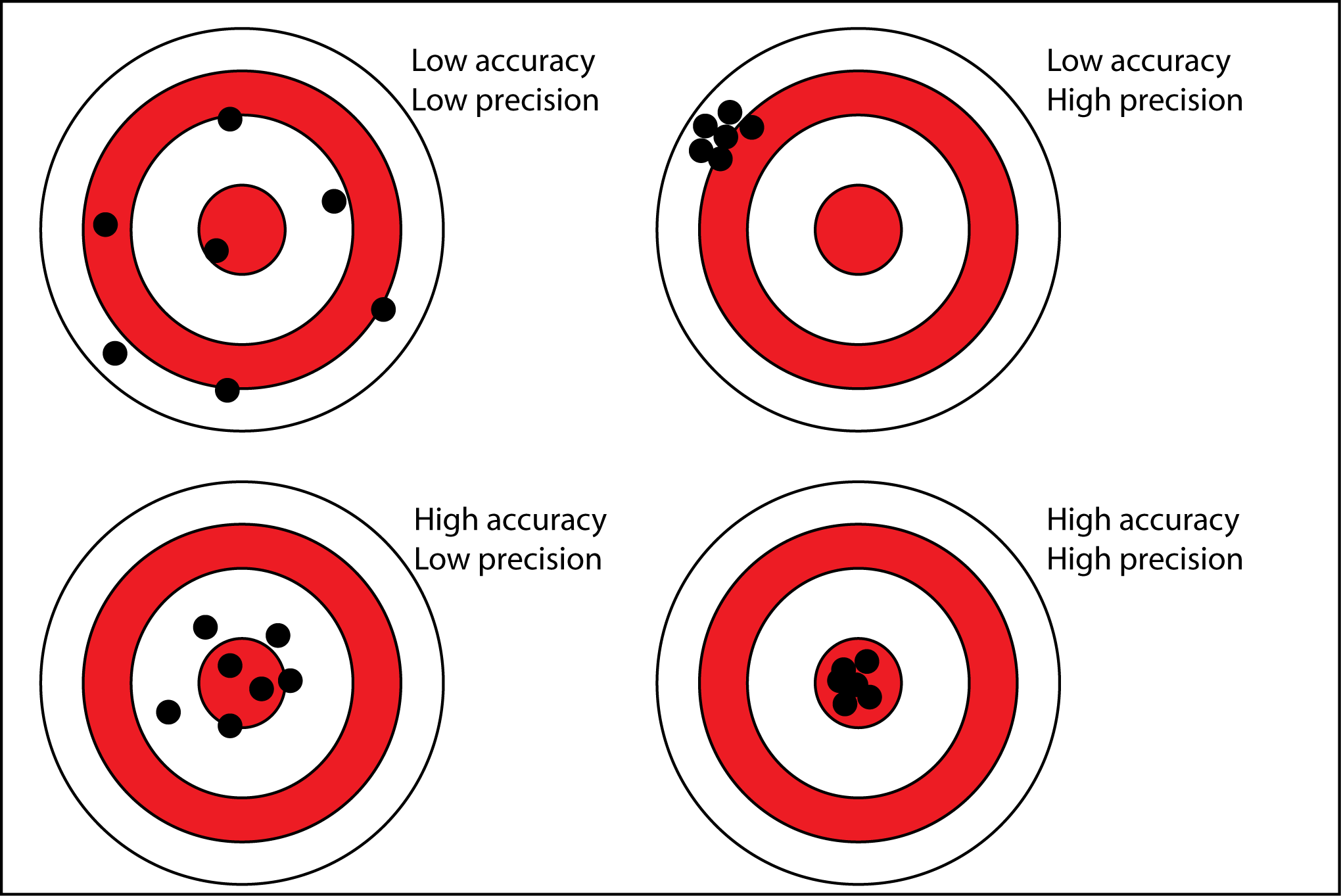
I would argue it isn't. I love that graphic (I use it in classes frequently) but it's limiting here.
Accuracy is about how close to the underlying behavior that is being modeled is. In this case, the goal is modeling the controllers they are using.
Precision is about how stable I can make my controller parameters and how stable they can make the behavior or the underlying fusion.
What they did was changed the fidelity of the model. Rather than parameterizing it using a known controller model (e.g., a PID controller) they used the neural network to fundamentally discover the important parameters that they can understand and how they interact.
The simulation can be accurate or not accurate entirely independently of how much fidelity of the actual phenomenon you model. You need to have a high fidelity model, and that model needs to be accurate, and they behavior needs to be precise and stable.
An example would be how wing profiles in aircraft are simulated/modeled. I can do it in 2D with high accuracy and high precision - it's a GOOD 2D simulation. But its low fidelity. I might be better off with a lower accuracy model of a high fidelity model, like a 3D model that lets me look at how the ends of the wingtip perform as well. Increasing the accuracy of that model might make the results less stable (because numerical techniques...great). A lot of improvements in computing power and simulation techniques have resulted in the ability to simulate systems more completely and learn about the interactions - not just making the simulation more accurate to what it contains.
If the reward function is sufficiently dense, then likely yes. RL uses function approximators to solve problems, so in theory the perturbations of the chaotic system shouldn't matter as much.
How to simulate human humor responses? Then we can evolve AIs that are funnier and more resourceful than anyone on the planet.
How to simulate human connection, attraction and arousal responses? Then we could have bots that are smoother talking and far more preferable to human lovers.
How to simulate human responses to nutrition? Then we could have individualized recommendations for diets, achieving goals like holistic health or muscle definition and addressing issues like diabetes.
These are all complex systems where figuring out how to simulate them is a much difficult task than even reinventing reinforcement learning from scratch.
{kind=link}