I've worked at 20 people companies and 2000 people companies, and can never recommend building a CMS. There are so many out there, and the one you build will just have a different limitation to the one you buy.
I second that. Any CMS-like system that you attempt to build with some customization will fail to implement some core elements of a CMS that you can adopt - be it versioning, publishing, workflows, etc.
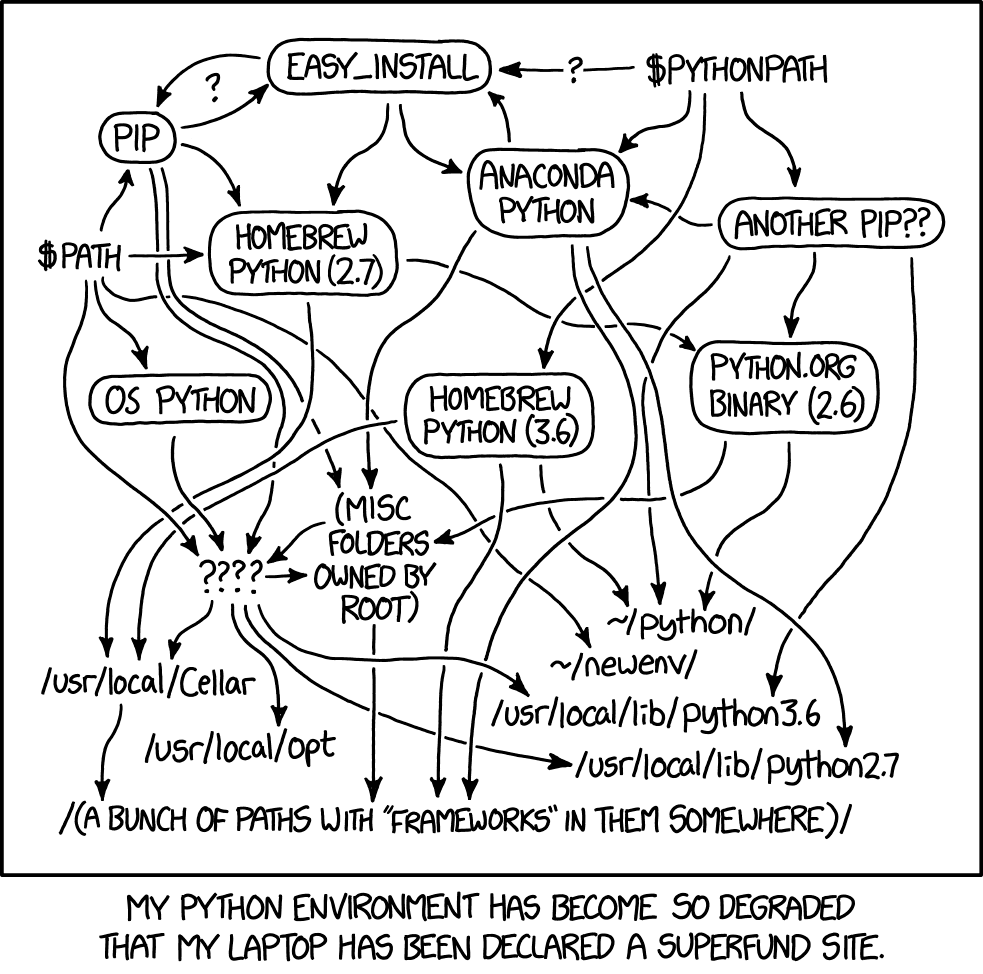
This comment section itself clearly shows how crazy dependency and environment management is in Python. In this thread alone, we've received instructions to...
- poetry
- "Just pin the dependencies and use Docker"
- pip freeze
- Vendoring in dependency code
- pipreqs
- virtualenv
This is simply a mess and it's handled much better in other languages. I manage a small agency team and there are some weeks where I feel like we need a full-time devops person to just help resolve environment issues with Python projects around the team.
Keep in mind that Python is 31 year old (it's even older than Java) it was created around the same time as world wide web. So it started when no one even knew they would need dependency management and evolved over time from people posting packages on their home pages, to a central website to what we now call PyPI. Similarly the tooling and way of packaging the code evolved.
What you described are multiple tools that also target different areas:
> - poetry
from what you listed this seems like the only tool that actually takes care of dependency management
> - "Just pin the dependencies and use Docker"
this is standard fallback for all languages when people are lazy and don't want to figure out how to handle the dependencies
> - pip freeze
all this does it just lists currently installed packages in a form that can be automatically read by pip
> - Vendoring in dependency code
this again is just a way that applies to all languages, and it is still necessary even if there's a robust dependency management as there are some cases where bundling everything together is preferred
> - pipreqs
this is just a tool that scans your code and tells you what dependencies you are using. You are really lost if you need a tool to tell you what packages is your application is using, but I suppose it can be useful for one offs if you inherit some python code that wasn't using any dependence management.
> - virtualenv
this is just a method to have dependencies installed locally in project directory instead per system. This was created especially for development (although it can be used for deployment as well) as people started working on multiple services with different dependencies. It's now included in python so it's more like a feature of the language.
Being 31 years old doesn't preclude having a decent, official and reproducible way of installing packages in 2022. That's just a bad excuse to justify subpar package managers and terrible governance around this problem.
Package management is pretty much a solved problem, no matter how old is your language. It smells to an outsider like me like a lot of bike-shedding and not enough pragmatism is going on in Python land over this issue. Has a new BDFL stepped up after Guido left?
But Python has a decent and a reproducible way of installing packages. The problem python has is that things evolved over time, so you can find on the net plenty of outdated information. There is also a lot of blogs and articles with bad practices, most written by people that got something working.
I think also a lot of issues with packaging is ironically because of PyPA that supposed to work on a standard, but in reality instead of embracing and promoting something that works they just pushes half-assed solutions because author is one of the members. Kind of like they were pushing failed Pipenv "for humans". Seems like Poetry is generally popular and devs are happy with it, so of course PyPA started pushing their own Hatch project, because python packaging was finally getting too straight forward.
I think Python would benefit as a whole if PyPA was just dissolved.
Poetry has been the one I've settled on as well. It "Just Works™" for everything I've used it for thus far, and it's even been easy to convert older methods I've tried to the Poetry way of doing things.
I do see that in their repo[1] they use a non standard way to build the package. They use Bazel, but that's Google for you. They never do things everyone else is doing. I'm not sure why this is Python problem rather than package problem.
They have tons of open issues around building: [2]
Yup. Java is 27 years and has a splendid package management system (Maven Central) which is so well designed that you can use it from two different tools that are extremely different (Maven and Gradle).
This really isn't a good argument though: it's an extra, extremely specific use case for assignment that looks visually very similar.
And worse, effects code maintainability - if you need that assignment higher up, you're now editing the if statement, adding an assignment, plus whatever your interstitial code is.
Python doesn't have block scoping so the argument for it is weak.
It's not for extremely specific use-case, unless you consider using variables as a condition of an if statement or loop extremely specific.
> And worse, effects code maintainability - if you need that assignment higher up, you're now editing the if statement, adding an assignment, plus whatever your interstitial code is.
How is that different than variables declared without the walrus operator? If you declare a variable with the walrus operator and decide to move its declaration you can still continue to reference that variable in the same spot, just like any other variable. Do you have an example you can share to demonstrate this? I'm not sure I understand what you mean.
> Python doesn't have block scoping so the argument for it is weak.
The walrus operator another way to define variables, not change how they behave. It's just another addition to the "pythonic" way of coding. It's helped me to write more concise and even clearer code. I suggest reading the Effective Python link I provided for some examples of how you can benefit from it.
# some other code
if determined_value := some_function_call():
do_action(determined_value)
and then I change it to this:
# some other code
determined_value = some_function_call()
logger.info("Determined value was %s", determined_value)
validate(determined_value)
if determined_value:
do_action(determined_value)
and determined_value is a reasonably expensive operation (at the very least I would never want to redundantly do it twice) - then in this case my diff for this looks like:
--- <unnamed>
+++ <unnamed>
@@ -1,5 +1,8 @@
-
# some other code
-if determined_value := some_function_call():
+determined_value = some_function_call()
+logger.info("Determined value was %s", determined_value)
+validate(determined_value)
+
+if determined_value:
do_action(determined_value)
whereas if I wrote it without walrus originally:
--- <unnamed>
+++ <unnamed>
@@ -1,5 +1,8 @@
# some other code
determined_value = some_function_call()
+logger.info("Determined value was %s", determined_value)
+validate(determined_value)
+
if determined_value:
do_action(determined_value)
then the diff is easier to read, and the intent is clearer because diff can simply infer that what's happening is the semantic addition of two lines.
Code is read more then it's written, and changed more then originally created, and making the change case clearer makes sense.
Your issue is with the readability of the diff? That is so trivial. You're trying to find anything to complain about at this point. How about just look at the code? You should be doing that anyway.
Diffs are the predominant way people relate to code changes via PRs. It is standard practice to restructure patch sets to produce a set of easy to read to changes which explain what is happening - what "was" and what "will be".
An example where I have wanted this many times before it existed is in something like:
while (n := s.read(buffer)) != 0:
#do something with first n bytes of buffer
Without the walrus operator you either have to duplicate the read operation before the loop and at the end of the loop, or use while True with a break if n is zero. Both of which are ugly IMO.
I used to think this and rage at the current state of Python dependency management. Then I just buckled down and learned the various tools. It's honestly fine.
> all this does it just lists currently installed packages in a form that can be automatically read by pip
Are you referring to version specifiers[1] being optional or is there something more to versions that I don't understand? PEP 440 is a wall of text, maybe I should get around to reading it sometime.
This whole chain started with someone pointing out the author doesn't seem to realize you can pin versions[1]. I'm just confused how people seemed to end up questioning what pip freeze does.
I tried to say that from mentioned tools only poetry can be called as a dependency management.
The other tools are used for different purposes, but perhaps could be used as a piece of package management in some way. The mentioned docker and vendoring is irrelevant to Python and it even applies to Go.
Sometimes I feel people are using Python very differently than me. I just use pip freeze and virtualenv (these are Python basics, not some exotic tools) and I feel it works great.
Granted, you don't get a nice executable, but it's still miles ahead of C++ (people literally put their code into header files so you don't have to link to a library), and even modern languages like rust (stuff is always broken, or I have some incompatible version, even when it builds it doesn't work)
By the way if you're a Python user, Nim is worth checking out. It's compiled, fast and very low fuss kind of language that looks a lot like Python.
> and even modern languages like rust (stuff is always broken, or I have some incompatible version, even when it builds it doesn't work)
Been working on and off with Rust for the last 3 years, never happened to me once -- with the exception of the Tokio async runtime that has breaking changes between versions. Everything else always worked on the first try (checked with tests, too).
Comparing Python with C++ doesn't make do argument any favours, and neither does stretching a single Rust accident to mean the ecosystem is bad.
This is consistent with my experience. Semantic versioning is very very widely used in the Rust ecosystem, so you're not looking at breaking changes unless you select a different major version (or different minor version, for 0.x crates) - which you have to do manually, cargo will only automatically update dependencies to versions which semver specifies should be compatible.
For crates that don't follow semver (which I'm fairly certain I've encountered zero times) you can pin a specific exact version.
When I was a Python dev, I never saw that happen in ten years or so of work. Pip freeze and virtualenv just worked for me.
I will say, though, that this only accounts for times where you’re not upgrading dependencies. Where I’ve always run into issues in Python was when I decided to upgrade a dependency and eventually trigger some impossible mess.
Piptools [1] resolves this by having a requirements.in file where you specify your top level dependencies, doing the lookup and merging of dependency versions and then generating a requirements.txt lock file. Honestly it’s the easiest and least complex of Python’s dependency tools that just gets out of your way instead of mandating a totally separate workflow a la Poetry.
It's really not. I've had a much, much worse experience with Python than Elixir / Go / Node for various reasons: lots of different tools rather than one blessed solution, people pinning specific versions in requirements (2.1.2) rather than ranges (~> 2.1), dependency resolution never finishing, pip-tools being broken 4 times by new pip releases throughout a project (I kept track)...
In Elixir I can do `mix hex.outdated` in any project, no matter who wrote it, and it'll tell me very quickly what's safe to update and link to a diff of all the code changes. It's night and day.
Thankfully, it's getting gradually better with poetry, but it's still quite clunky compared to what you get elsewhere. I noticed lately for instance that the silent flag is broken, and there's apparently no way to prevent it from spamming 10k lines of progress bars in the CI logs. There's an issue on Github, lost in a sea of 916 other open issues...
As soon as you take 2 dependencies in any language, there's a chance you will not be able to upgrade both of them to latest versions because somewhere in the two dependency subgraphs there is a conflict. There's no magic to avoid this, though tooling can help find potentially working versions (at least by declaration). It's often the case that you don't encounter conflicts in Python or other languages, but I don't imagine that Go is immune.
I've used npm but an not familiar with these kinds of details of it. There would seem to be some potential putfalls, such as two libraries accessing a single system resource (a config file, a system socket, etc.). I will take a look into this though. Thanks.
npm works around some problems like this with a concept of "peer dependencies" which are dependencies that can only be depended on once. The typical dependency, though, is scoped to the package that requires it.
Rust can include different versions of the same library (crate) in a single project just fine. As long as those are private dependencies, no conflicts would happen. A conflict would happen only if two libraries pass around values of a shared type, but each wanted a different version of the crate that defines the type.
I have rarely encountered issues in rust. Most rust crates stick to semver so you know when there will be a breaking change. My rust experience with Cargo can only be described as problem free(though I only develop for x86 linux).
As for pip freeze and virtualenv things start to fall apart especially quickly when you require various C/C++ dependencies (which in various parts of the ecosystem is a lot) as well as different python versions (if you are supporting any kind of legacy software). This is also assuming other people working on the same project have the same python yadda yadda the list goes on, its not great.
> pip freeze and virtualenv things start to fall apart especially quickly when you require various C/C++ dependencies
Yes 100 times. That can be incredibly frustrating. During the last year I've used a large (and rapidly evolving) C++ project (with many foss C/C++ dependencies) with Python bindings. We've collectively wasted sooo many hours on dependency issues in the team.
Long compilation times contribute considerably to slow down the feedback loop when debugging the issues.
Wat? What dependencies? I have right now 100 separate Python projects which each have their own venv, their own isolated dependencies, and their own isolated copy of Python itself and my code dir doesn’t even crack top 10 hard drive space.
No, saying "one common library is big" isn't a good way to show that "Python dependencies are big", which is what the initial claim was. Most libraries are tiny, and there's a very big one because it does many things. If Tensorflow were in JS it wouldn't be any smaller.
Yup. PyEnv for installing various versions. /path/to/pyenv/version/bin/python -m venv venv. Activate the venv (I made "av" and "dv" aliases in my .zshrc). Done, proceed as usual.
You can get that by bundling up your venv. When you install a package is a venv it installs it into that venv rather than the system. As far as the venv is concerned it is the system Python. Unfortunately passing around a venv can be problematic, say between Mac and Linux or between different architectures when binaries are involved.
Sounds like someone has never been asked to clone and run software targeting Python 3.x when their system-installed Python is 3.y and the two are incompatible.
Sounds like someone is making assumptions on the way I work :) As a matter of fact I have and the solution is pyenv. Node has a similar utility called n.
Now try installing tensorflow. Treat yourself to ice cream if you get it to install without having to reinstall Linux and without borking the active project you're on.
And unless things have gotten a lot better in the 2 years since I last did `pip install numpy` on ARM, prepare for a very long wait because you'll be building it from source.
The major issues you'll see involve library version mismatches. It's a very good idea to use venv with these tools since there are often mismatches between projects.
Tensorflow sometimes is pinned to Nvidia drivers, and protobuf. And I think it has to be system level unless you reaaaaally want to fiddle with the internals.
The core problem with Python dependencies is denial. There are tons of people who make excuses for a system that is so bad Randall Munroe declared his dependencies a “superfund site” years ago. In a good ecosystem, that comic would have prompted change. Instead, it just prompted a lot of “works for me comments”. Monads are just monoids in the category of endofunctors, and C just requires you to free memory at the right time. Python dependencies just work as long as you do a thing I’ve never seen my colleagues do at any job I’ve worked at.
That's half of why from 2017 to 2021 I had a yearly "uninstall Anaconda and start fresh" routine. The other half is because I'd eventually corrupt my environments and have no choice but to start over.
Are you using conda-forge? Solving from over 6TBs of packages can take quite a while. Conda-forge builds everything. This isn't a criticism, but because of that the number of packages is massive.
"You can't use the big channel with all the packages because it has all the packages" isn't an exoneration, it's an indictment.
To answer your question: yes, we were using conda-forge, and then when it stopped building we moved to a mix of conda and a critical subchannel, and then a major GIS library broke on conda and stayed that way for months so we threw in the towel and just used pip + a few touch-up scripts. Now that everyone else has followed suit, pip is the place where things "just work" so now we just use pip, no touchups required.
Is it a mess? Yes. But, is the problem to be solved perhaps much simpler "in other languages"? Do you interface with C++ libraries, system-managed dependencies, and perhaps your GPU in these other languages? Or are all your dependencies purely coded in these other languages, making everything simpler?
Of course the answer to these questions could be anything but to me it feels like attacks on Python's package management are usually cheap shots on a much much more complicated problem domain than the "complainers" are typically aware of.
Or the "complainers" work with Rust and Elixir and giggle at Python's last-century dependency-management woes, while they run a command or two and can upgrade and/or pin their dependencies and put that in version control and have builds identical [to those on their dev machines] in their CI/CD environment.
¯\_(ツ)_/¯
Your comment hints that you are feeling personally attacked when Python is criticized. Friendly unsolicited advice: don't do that, it's not healthy for you.
Python is a relic. Its popularity and integration with super-strong C/C++ libraries has been carrying it for at least the last 5 years, if not 10. There's no mystery: it's a network effect. Quality is irrelevant when something is popular.
And yes I used Python. Hated it every time. I guess I have to thank Python for learning bash scripting well. I still ended up wasting less time.
It's a bit ironic to pick someone's up on "taking things personally upon criticism", then proceeding to display a deep, manichean, unfounded hatered for a language that, despite its numerous flaws, remains a popular and useful tool.
Hanging people upon dawn was popular as well; people even got their kids for the event and it was happening regularly. Popularity says nothing about quality or even viability.
Use Python if it's useful for you, obviously. To me though the writing is on the wall -- it's on its loooong and painful (due to people being in denial) way out.
EDIT: I don't "hate"; it was a figure of speech. Our work has no place for such emotions. I simply get "sick of" (read: become weary of) something being preached as good when it clearly is not, at least in purely technical terms. And the "hate" is not at all unfounded. Choosing to ignore what doesn't conform to your view is not an argument.
> Your comment hints that you are feeling personally attacked when Python is criticized.
I am not feeling personally attacked (I am not married to Python), I am mostly just tired of reading the same unproductive type of complaints over and over again. This attitude is not unique to Python's situation, but actually is typical to our industry. It makes me want to find a different job, on some days.
The community is trying to improve the situation but there is no way to erase Python's history. So it's always going to continue to look messy if you keep looking back. The complaint is unproductive, or in other words, not constructive.
I can agree with your comment. What's missing is the possibility to, you know, just jump ship.
You might not be married to Python but it sure looks that way for many others. I switched main languages no less than 4 times in my career and each time it was an objective improvement.
The thing that kind of makes me look down on other programmers is them refusing to move on.
For nuance and to address your point, I have worked with PHP for about six years, .NET for five, C++ for two, and Python for seven.
I still dabble in all of them. Who knows when I will move on to the next. Rust looks nice. I tried go.
But they do not yet provide any of the tools/libraries I need for my work. That's how I've always selected my programming language.
So I would first need to invent the universe before I can create valuable things. Instead I will just wait until their ecosystems mature a little more.
I will end the discussion here though. Thanks for the response!
Yes. In elixir, you can install GPU stuff (Nx) with very few problems. Some people have built some really cool tools like burrito, which cross-compile and bundles up the VMs to other architectures. Even before that it's been pretty common to cross-compile from x86 to an arm raspberry pi image in the form of Nerves.
As a rule elixir devs don't do system level dependencies, probably because of lessons learned from the hell scape that is python (and Ruby)
Yesterday I onboarded a coworker onto the elixir project, he instinctively put it into a docker container. I laughed and just told him to run it bare (he runs macos, I run Linux). There were 0 problems out of the box except I forgot the npm incantations to load up the frontend libraries.
2) not that I can find for that specific task but the typical strategy is to download (or compile) a binary, drop it into a {project-dependency}[0]-local "private assets" directory, and call out the binary. This is for example how I embed zig pl into elixir (see "zigler") without system-level dependencies. Setting this up is about 40 lines of code.
3) wx is preferred in the ecosystem over qt, but this (and openssl) are the two biggies in terms of "needs system deps", though it's possible to run without wx.
For native graphics, elixir is treading towards glfw, which doesn't have widgets, but from what I hear there are very few if any gotchas in terms of using it.
I bring up cross-compilation, because burrito allows you to cross-compile natively implemented code, e.g. bcrypt that's in a library. So libraries that need c-FFI typically don't ship binaries, they compile at build time. Burrito binds "the correct" architecture into the c-flags and enables you to cross compile c-FFI stuff, so you don't have a system level dependency.
[0] not that this has happened, but two dependencies in the same project could download different versions of the same binary and not collide with each other.
Its not a mess, people just make it a mess because of the lack of understanding around it, and getting lazy with using a combination of pip install, apt install, and whatever else. Also, the problem is compounded by people using Mac to develop, which have a different way of handling system wide python installs from brew, and then trying to port that to Linux.
Even using conda to manage reqs is an absolute nightmare. Did a subreq get updated? Did the author of the library pin that subreq? No? Have fun hunting down which library needs to be downgraded manually
I used a couple of tricks to solve this. First, make cond env export a build step and environment.yml an artifact so you've got a nice summary of what got installed. Second, nightly builds so you aren't surprised by random package upgrade errors the next time you commit code to your project.
This has indeed been eye opening. We got bit by a dependency problem in which TensorFlow started pulling in an incompatible version of protobuf. After reading these comments, I don't think that pip freeze is quite what we want, but poetry sounds promising. We have a relatively small set of core dependencies, and a bunch of transitive dependencies that just need to work, and which we sometimes need to update for security fixes.
Why do you think that `pip freeze` wouldn't be what you want? (I once had the exact same issue with TF and protobuf and specifying the exact protobuf version I wanted solved it.)
When I tried learning Python, this mess is what turned me off so badly. Python is the first language I ever came across where I felt like Docker was necessary just to keep the mess in a sandbox.
Coming to that from hearing stories that there was supposed to be one way to do everything disenchanted me quickly.
Every article I found suggested different versions of Python, like Anaconda. They all suggested different virtual environments too. Rarely was an explanation given. At the time, the mix of Python 2 vs Python 3 was a mess.
The code itself was okay, but everything around it was a train wreck compared to every other language I’d been using (Go, Java, Ruby, Elixir, even Perl).
I attempted to get into it based on good things I’d heard online, but in the end it just wasn’t my cup of tea.
> This is simply a mess and it's handled much better in other languages.
I don't agree.
The problem is simply that Python encompasses a MUCH larger space with "package management" than most languages. It also has been around long enough to generate fairly deep dependency chains.
As a counterexample, try using rust-analyzer or rust-skia on a Beaglebone Black. Good luck. Whereas, my Python stuff runs flawlessly.
What many newer languages do is precompile the happy paths(x86, x86-64, and arm64) and then hang you out to dry if that's not what you are on.
I agree that it is handled better in many other languages. However, Go has some weird thing with imports going on. When I tried to learn it I just could not import a function from another file. Some env variable making the program not find the path. Many stackoverflow/reddit threads condecendenly pointed to some setup guide in official docs which did not fix or explain the situation.
After an few hours or so of not making much progress in AOC day 1 I just gave up and never continued learning Go.
It's not crazy at all. You use requirements.txt to keep a track of the dependencies needed for development, and you put the dependencies needed to build and install a package into setup.py where the packaging script can get it.
These are two different things, because they do two different jobs.
Granted, I'm more of a hobbiest than a dev, but I think this is part of the problem that virtualenvs are supposed to help solve. One project (virtualenv) can have numpy==3.2, and another can have numpy==3.1. Maybe I'm naive, but it seems like having a one project with multiple versions of numpy being imported/called at various times would be asking for trouble.
The thing you can’t do is solve for this situation.
A depends on B, C
B depends on D==1.24
C depends on D==2.02
There should in an super ideal world be no problem with this. You would just have a “linker” that inserts itself in the module loader that presents different module objects when deps ask for “D” but it hasn’t happened yet.
Foo Fighters have always meant a lot to me and I am a huge fan of Taylor Hawkins. I’ve been overloaded at work the past few weeks running my company, and have been heavily enjoying Taylor’s side albums these last few weeks.
A friend sent me this poem to help cope with this news, entitled “Encounter”…
—
We were riding through frozen fields in a wagon at dawn.
A red wing rose in the darkness.
And suddenly a hare ran across the road.
One of us pointed to it with his hand.
That was long ago. Today neither of them is alive,
Not the hare, nor the man who made the gesture.
O my love, where are they, where are they going
The flash of a hand, streak of movement, rustle of pebbles.
I ask not out of sorrow, but in wonder.
Personally I'd like it a lot. I think applications half of the screen can make sense. It'd be great to use to place things off screen that I may not need to use actively like Chrome devtools.
Accessibility is an issue though. If i could three finger scroll context horizontally that would be nice.
But isn't having things positioned half-off the screen one of the traditional overlapping-window manager patterns that tiling window managers are meant to avoid?
Someone should make a compiler that converts inline styles to Tailwind so then you don't have to learn Tailwind but can still use Tailwind.
For example it can convert `<div style="background-color: white">` to `<div class="bg-white">`. Perfect! (Yes, "bg-white" is the Tailwind way to make the background color white.)
Assuming the content is gzipped when transferred (a good assumption), the non-Tailwind version's payload is smaller because there are no separate CSS definitions.
Your statement is true in the general sense (a page can easily load unused CSS with other CSS/styling approaches) but I don't think it's correct to say that using Tailwind results in smaller payloads vs. using style attributes.
Noticed that keyboard navigation (tabbing, focus order, focus rings, etc.) didn't work on this site. Maybe I'm being pedantic but a baseline for good UX should be accessibility.
Often, it's not the developers that are at fault. Middle managers, cross-functional people, etc. ask developers to cram garbage into otherwise would-be lean pages. Developers often have no authority to push back, and stakeholders often don't fully understand "why" the garbage they're asking developers to insert into pages is detrimental to the user experience.
With AMP, the little badge (the verification), serves as a constraint for developers, but mostly for business stakeholders. The conversation of "I can't do that, because it's simply not compatible with AMP" is way easier than "I can't do that, because it will make the page slow".
I keep seeing articles like this pop up. During one of the first coronavirus press conferences, the White House invited CEOs from Walmart, Target, CVS, etc. – presumably to show strength of the private sector.
On the flip side, why can't we enlist money and resources from the private sector to quickly fix some of these supply issues? For example:
- Convert car factories to produce masks and ventilators.
- Convert construction companies to build makeshift hospitals. (Or use hotels.)
- Use tech companies to improve national information access with regards to CV19 testing and track and help patients using their software on their phones to help with contact tracing.
I realize that it's not as simple as pressing a button and instantly converting a factory that makes Teslas into one that makes masks. I also realize there are potential privacy concerns with nationalized information tracking.
But, we're about to enter an unprecedented public health crisis. We have resources that can lessen the impact if we just align and get behind this direction.
I can't help but think we could do more and not just wait for the shortage to happen, and for the curve to spike.
We stockpile enough nukes to basically destroy the whole Earth (exaggeration but you get the idea), but we can't stockpile some ventilators and face masks in case of a pandemic? You can't fight a pandemic with diplomacy. At least you can fight a foreign enemy with that.
Turns out N95 masks are quite high-tech, and even China is having trouble scaling up its production. They're made of a material, meltblown fabric, which only a limited number of factories are capable of producing.
IDK. I get that it's a hard problem, but it's a solvable one. It's not like it's some equation or law of science that needs to be discovered. It can be solved with money and effort. :\ I get the economics don't work out in normal times for a reserve like this, but that's exactly what an insurance policy (i.e. a federal reserve of medical supplies) is for.
It's just like nukes. We have a stockpile of them that are maintained... nukes are very hard to produce... etc. etc.
The only real facility for high volume production in the US is 3M in Minnesota, I believe. Current estimates place supply chain matching demand in 80-90 days (though I don't know if that's domestic or worldwide).
The problem is harder if we demand flexible fabric. That isn't how gas masks are done. With a canister filter, all sorts of options become possible. We could use sintered glass, ceramic, or metal. We might be able to use aerogel, diatomaceous earth, or metal foam. We could even go electronic, with a UV light.
Filters with greater air flow resistance can be used if we add a blower. Remember that the virus can enter via eyes. Eyes need protection. Eyes also need air, and it can't be humid or the protection will fog up. For this too, a blower would help.
You need the tools, but you don't have them. So you need the tools that make the tools. But you don't have those either. So you have two layers of tools you need to make from basic tools. Then you need supply chains for all the inputs. It's not as easy as waving a magic wand. But I do suspect that if we had started in January something could have been done.
> we're about to enter an unprecedented public health crisis.
this is where you lose me... it’s not unprecedented, quite the opposite. Throughout all human history this has been common. Recently (since WWII), we’ve been able to limit the lethality of most diseases and/or reduce transmissions.
But this should have been prepared for. They (the government) even had a playbook for it, they had evidence it could even be from this family of viruses.
This is a massive mistake by hundreds of our leaders.
While it's obviously not unpredictable, it was a widespread failure, across a range of political systems - EU, China, and US. We've seen success at scale in SK, which is a smaller, homogenous, high-conformity democracy.
In theory, a free-market democracy would solve the misallocations caused by these blunders more efficiently than the other systems. But the US doesn't have a free-market healthcare system -- or even a free-market mask manufacturing system. As this thread indicates, we're about to see a lot of people die from red tape in Western countries.
I understand. But, it's about keeping a reserve. On one hand, it's wasteful. On the other hand, a maintained reserve can save lives. This is a problem that can be solved with money.
Planet Money did a great episode recently on how the US government is currently paying for a year-round supply of chicken eggs to produce vaccine for a pandemic flu. (https://www.npr.org/transcripts/812943907).
I understand this situation is different from eggs, as an egg not used for a vaccine can be converted to feed, but in the end it's all about money. It's like an insurance policy. I pay for auto insurance but don't use it until I really need it.
> But in a subsequent tweet on Wednesday evening, Trump indicated that even though he invoked the act, he is in no rush to use it.
> "I only signed the Defense Production Act to combat the Chinese Virus should we need to invoke it in a worst- case scenario in the future," he said. "Hopefully there will be no need, but we are all in this TOGETHER!"
{kind=link}