It's not that CO2 isn't valuable on its own, but that other carbon-containing molecules are even more valuable (especially when factoring in transportation costs). This helps prove out the technoeconomics of carbon capture.
Plus, if we wind down oil extraction, we'll need new processes to produce all the precursors we use for plastics. A cheap pathway to ethylene from captured CO2 and water would be huge.
How close to zero? 1 MWh at 100% efficiency is enough to convert 180 kg of CO2 to ethylene (note this only produces 51 kg ethylene). Annual excess carbon emissions are 36.8 trillion kg of CO2. At a cost of $0.10 per MWh, which is about 3-4 orders of magnitude lower than it currently is, that's still $20 Billion per year. A cheaper pathway is still going to save an incredible amount of money even if solar power got ridiculously cheap.
The energy costs are only part of the equation, though. Especially if your plan is to use excess renewable energy, the cost of your plant is a much bigger concern, because you can't run it all the time.
But that point drives right into this one: compressed CO2 is valuable. So the value of your carbon capture process is already very substantial after you've extracted the CO2 from the atmosphere. I mean I have a cylinder of CO2 under my kitchen counter right now for this reason.
So the question is, is this so valuable that it outweighs just selling that CO2 once you've pulled it out of the atmosphere?
A good work truck is one you don't mind getting scratched and dented. Hard to replicate that with any brand new vehicle, especially one with a $60k starting price.
That said, I think the Lightning serves certain roles really well. They're great for the forest service, for municipalities, utilities, etc. If they were actually cheaper than the ICE version I think they'd gain a lot of adoption for those kinds of fleets.
Since they're quite a bit more expensive, though, buyers have to make the case that they're worth it. Pretty tough proposition unless you're trying to sneak under an emissions budget.
I've been wondering the same thing. Unfortunately, I've found that GPT-4o is much less good at OpenSCAD than it is at Python.
It feels totally untrained on the step-by-step logic you need to build things in a programatic way. This is likely a problem with not having enough training data.
That said, the bigger problem is that OpenSCAD is easy for things which are tractable to being described mathematically, and that the boundary for what can be described is one's fluency with mathematics --- once one gets beyond those things which can be described by rectangles, cylinders, and spheres, it gets quite difficult, and getting elements aligned often requires trigonometry (I have one backburner project which needs for me to get up-to-speed on conic sections).
There are some folks who are able to write code to generate point clouds or polygons which describe surfaces (see recent discussions on the OpenSCAD mailing list), but not many, and there isn't much such code, and when it does exist, it tends to be quite special purpose and hard to apply to different shapes.
It would help if there was a Bézier curve primitive in OpenSCAD, or better some support for a NURBS surface as a core primitive so folks wouldn't constantly be rolling their own options.
Well, there's a lot less OpenSCAD on GitHub than Python. At first glance maybe a few orders of magnitude less.
But the bigger problem is (probably) not the lack of code, but the lack of good tutorials and well-documented libraries. And since there's no package manager (https://github.com/openscad/openscad/issues/3479) there's still no agreed-upon way to reuse code between projects.
All this is conjecture, of course. LLMs are mysterious beasts.
OpenSCAD is frequently written on the same level as M4 macro language, or assembly code with no comments. If you're bad at mental arithmetic and bad at keeping track complicated internal state, like LLMs are, you will have a bad time.
Look at the one linked below, for instance. This is from the official OpenSCAD repo, examples folder. There is no way for even an experienced programmer to understand and successfully modify that code without sitting down with a pencil and paper and doing arithmetic and geometry for half an hour.
The low amount of training data is definitely one issue, but I also think back to the SCAD I've written and it's not got very much in the way of English prompt-friendly text in it to "guide" the LLM towards using it.
Arguably, this might mean I don't comment the code "enough", but in other languages, the variable names and overall structure seem to carry a lot of that for the human programmer and also in a way that guides an LLM towards effectively using it. I don't know much about how LLM's work internally either, but I picked a random SCAD file of mine and I don't know how it'd be found to create a PCB spacer with generous clearance for an M3 screw.
$fn = 90;
outer = 4.5 + 1.6;
inner = 4.5;
h = 13.5;
//round = true;
//square = true;
hex = true;
if (square)
difference() {
cube(size = [outer, outer, h]);
translate([(outer-inner)/2, (outer-inner)/2,-0.05]) cube(size = [inner, inner, h+1]);
}
if (round)
translate([0,15,0])
difference() {
cylinder(d = outer, h = h);
translate([0,0,-0.05]) cylinder(d = inner, h = h+1);
}
if (hex) translate([0,30,0])
difference() {
cylinder(d = outer*1.25, h = h, $fn=6);
translate([0,0,-0.05]) cylinder(d = inner*1.25, h = h+1, $fn=6);
}
I have a regular Bolt, and it's just the best car... so easy to drive, and efficient enough that miles are basically free. I'd never go back to an ICE car, even with all the issues around public charging.
Yes. We're entering a new era of web applications, whether we want to or not. Companies used to be able to gate their data behind UIs, because the search results had more value than the raw data.
Things are starting to flip. Increasingly, people would rather have access to the raw dataset to pipe into an LLM. The question, as always, is how to control this access and charge people accordingly.
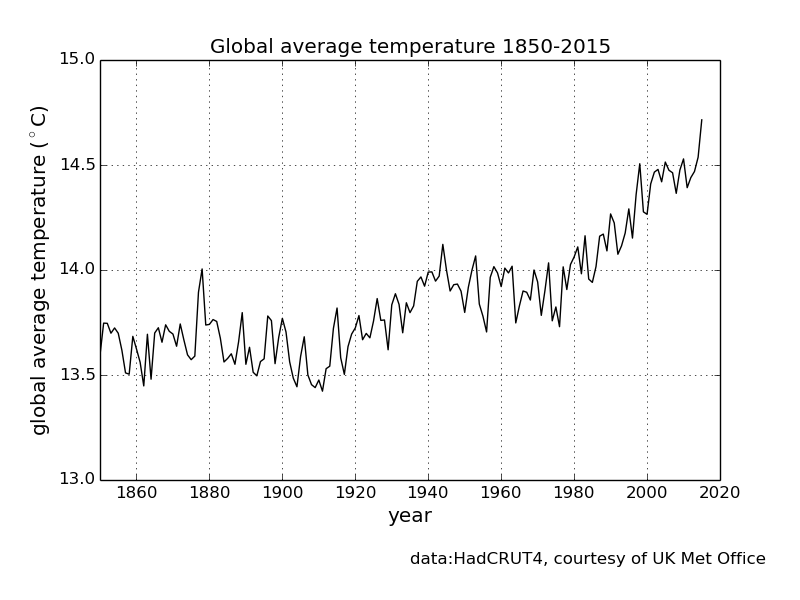
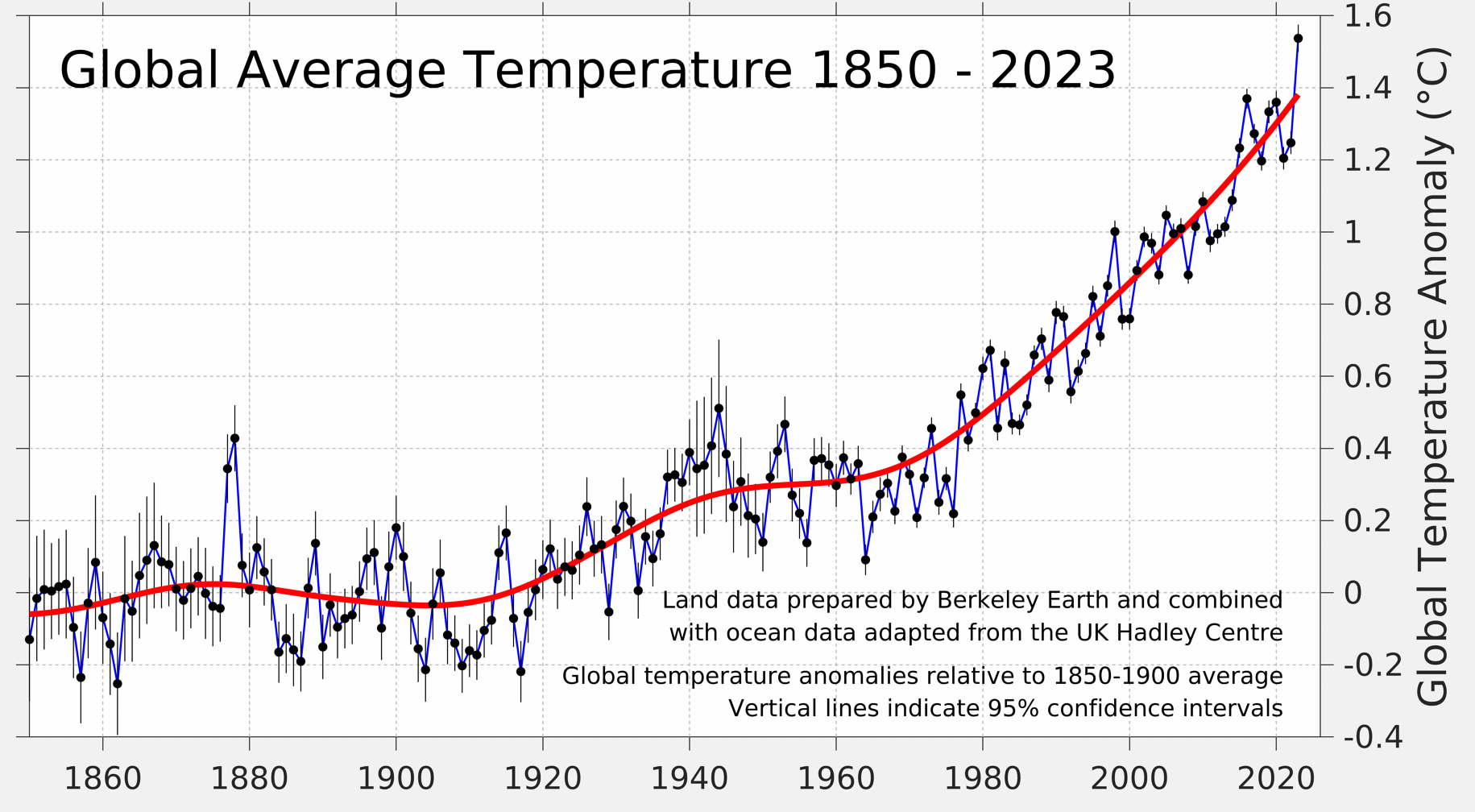
> measurable linear temperature increases starting in the 1880s instead of the 1940s
Could you cite your sources on this one? Every graph I can find shows the linear increases starting in about 1920 (plus or minus a bit, depending on how you squint your eyes), and correlating very neatly with atmospheric CO2 concentrations.
The lake next door to my house has had ice-in ice-out dates measured by the local university using the same procedure for the past 170 years. Lake ice is an extremely good way to determine average temperature for a season, of course, as it's just a big mass that gets cold and warms up again.
When you plot my lake, it's a solidly linear trend of fewer days of ice coverage ever since they began measuring it.
The neat atmospheric CO2 correlation is presumably the same thing that has caused that same correlation to exist in pre-historic times: CO2 has been a correlated trailing indicator of global temperature through the entirety of Earth's history.
If there has been a long-term global trend for Earth temperatures, like my little (not so little actually) lake seems to indicate, some of the assumptions that establish CO2 radiative forcing as a cause rather than an effect go out the window entirely.
But don't take my word for it. Read this Nature paper, and add in the postulate that global temperature since the 1860s is some linear trend similar to my lake's temperature, and watch what comes out:
I can be of no help to anyone who only reads the first sentence of a paper and stops, especially when I asked him to read the whole thing. Also anyone with minimal necessary background on temperature proxies for 1850-1890, or a good background on the temperature proxies or models that generate the links you have provided, will immediately see the comedy in "my little lake." But if you want to polemics rather than breadcrumbs from me, you are interacting with the wrong person.
To put it very simply: our evidence for a high feedback factor for added CO2 in the atmosphere and evidence for the forcing effect is entirely dependent on the assumption that temperature was not increasing much before 1940s.
I'll take it a step further and say that every industry is depressing when it comes to computers at scale.
Rather than build efficient, robust, fault-tolerant, deterministic systems built for correctness, we somehow manage to do the exact opposite. We have zettabytes and exaflops at our fingertips, and yet, we somehow keep making things slower. Our user interfaces are noisier than ever, and our helpdesks are less helpful than they used to be.
I am drifting towards hating to turn on my computer in the morning. The whole day is like pissing into the wind, trying to find workaround of annoyances or even malfunctions, getting rid of obstructive noise from all direction, my productivity using modern computer systems is diminishing compared to where it was just mere 10-15 years ago (still better than 25 years ago not only becuase of experience but also the access of information on demand). Very depressing. I should have became a farmer perhaps.
If it's released high enough above the rain cycle in the stratosphere, it stays there reflecting sunlight for 1-2 years, and produce little or no acid rain.
The US currently has gasoline at 10% ethanol back when we thought biofuel was good against climate change. It isn’t, but now we can’t undo it because important voting blocs and donors depend on the subsidy. The same would happen with an sulfur mandate.
There is almost certainly a point where the costs of massive planet-scale intervention outweigh the costs of doing nothing. I'm not sure exactly where that point lies, but I'd guess it's somewhere between Solar Radiation Management (SRM) and glacial geoengineering projects like the one in this article.
The question in my mind is not whether or not to fund these efforts (we will need to), but how to fund them quickly enough.
There aren't many investment vehicles that are truly global in scope. We've seen individual nations do incredible things when they stand to benefit. The Delta Works project in the Netherlands comes to mind, as does the Three Gorges Dam in China.
But how do we source capital when the whole planet stands to benefit? Especially when many nations either don't have the money and/or the political will. The scale of the problem far outstrips what charity or nonprofits can provide, and private companies can only do so much without a functional market.
I don't mean to suggest that this is an intractable problem. It really isn't-- There have been some really interesting financial innovations already. But we need way more attention on this stuff from the investment class. The bankers, fund managers, and policymakers that work in global development need to get creative, and fast.
There is always the tradeoff between fighting the nature and adapting to it.
SRM and glacial are bullshit, they first won't ever be able to attain enough finanicing to make them convincing to whoever wants to be convinced that "Something Is Done", is from engineering perspective pointless, and all in all resources are better be spent on like, stopping people being killed than on some shit that everyone pretends to care about so that they don't need to care about real issues. Like energy grid instability, Saudis being all butthurt, Iran going batshit crazy, Israel going to hell, Syria already there. And not to mention Ukraine.
Here the estimate for solar radiation management injecting aerosols in the stratosphere is estimated at $18B/year per degree Celsius. For the whole planet. Seems to me pretty cheap, even a private initiative can finance that.
You might just be using the node-fetch example as a stand-in to make your point about esm/cjs, but the fetch api is built in to Node (since v16.15) and is no longer even considered experimental as of Node 21+.
{kind=link}
{kind=link}
{kind=link}
Plus, if we wind down oil extraction, we'll need new processes to produce all the precursors we use for plastics. A cheap pathway to ethylene from captured CO2 and water would be huge.
reply